Introduction
In this article, I will explain how to use the OPA language Rego to create naming rules for S3 bucket names. I recently encountered this task at work and thought it might be a useful feature to add or could inspire the creation of other features.
Goal of the task
The goal of this task is to have a S3 bucket naming rule and let remind people what specific naming structure they should follow, such as including a prefix or suffix.
Example:
Let's say you want to have a bucket naming rule such as adding bucket as a prefix and an environment as a suffix.
Such as:
bucket-example-development
bucket-example-staging
bucket-example-production
resource "aws_s3_bucket" "example" {
bucket = "bucket-test-development"
tags = {
Name = "My bucket"
Environment = "Development"
}
}
To enforce this naming rule, we need to notify developers who are creating S3 buckets. If the environment is not correctly specified or the prefix is incorrect, we can send a warning as a comment on the PR using GitHub Actions, Terraform, and OPA Rego.
Github Actions Workflow structure
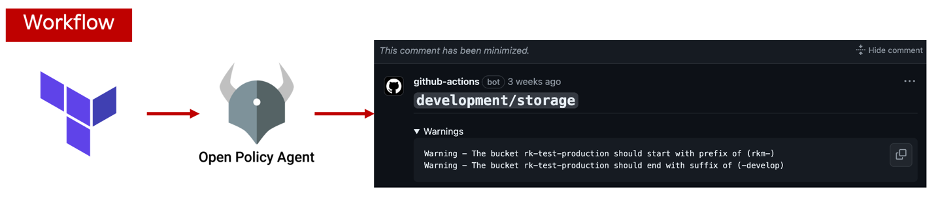
The approach I took was as follows:
- Derive the bucket and environment name from the Terraform plan.
- Process the plan data to filter only the necessary information into a temporary JSON file.
- Create a rule with OPA (Rego) and feed it the necessary data from the Terraform plan.
- Notify on the PR if it violates the rule.
With these steps, it became possible to check whether the S3 bucket name violates our naming rule.
Preparing data with Terraform plan
For the first step, we need to derive the data of the created bucket. To do this, we will utilize Terraform Plan and convert the output into a readable JSON file to use as our data.
- name: Terraform Plan
run: |
terraform plan -out=output.tfplan -no-color
terraform show -json output.tfplan | jq '[.resource_changes[] | select(.change.actions | index("no-op") | not)] | map(select(.type == "aws_s3_bucket")) | map({type: .type, bucket: .change.after.bucket, env: .change.after.tags.Env})' > s3_data.json
With the above code, you will receive only the created or changed bucket data, as shown below. By checking the type, we can ensure that we are receiving only S3 bucket data. Using the bucket and environment data, we can enforce the desired naming rule.
[
{
"type": "aws_s3_bucket",
"bucket": "bucket-test-development",
"env": "Development"
}
]
Note:
When creating the workflow to terraform plan, and convert it to -json file to use it on the next step I faced a problem of having invalid format. After investigating, i found that terraform wrapper on default was adding extraneous junk on the json, making it invalid format.
If you face any invalid format problem, do the below on the terraform setup.
- name: terraform setup
uses: hashicorp/setup-terraform@v1
with:
terraform_version: 1.9.5
terraform_wrapper: false
Make sure to include the below line in your workflow, as it is.
terraform_wrapper: false
Creating rule on name using OPA Rego
Rego, the policy language used by Open Policy Agent (OPA), works in a synchronous manner, evaluating rules based on logical conditions and dependencies.
In the main.rego code below, you can see that there are two rules: warn_suffix for checking the suffix and warn_prefix for checking the prefix.
If all of the conditions in the warn_prefix rule are met, the rule will generate a warning message.
package main
import rego.v1
config := {
"allowed_suffixes": {
"development": "-development",
"production": "-production",
"staging": "-staging",
},
"prefix": "bucket-"
}
# Validate the bucket name
warn_prefix contains msg if {
input.type == "aws_s3_bucket"
bucket_name := input.bucket
bucket_name != null
not startswith(bucket_name, config.prefix)
msg := sprintf("The bucket %v should start with prefix of (%v)", [bucket_name, config.prefix])
}
warn_suffix contains msg if {
input.type == "aws_s3_bucket"
bucket_name := input.bucket
bucket_name != null
environment := input.env
suffix := config.allowed_suffixes[environment]
not endswith(bucket_name, suffix)
msg := sprintf("The bucket %v should end with suffix of (%v)", [bucket_name, suffix])
}
When you are creating the main.rego, you can also create a unittest.rego to verify your main.rego from time to time.
The example provided showcases both valid and invalid cases.
test_valid_bucket_names1 if {`
` valid_case := {`
"bucket": "bucket1-example-development",
"type": "aws_s3_bucket",
"env": "development"
}
not main.warn_prefix["The bucket bucket1-example-development should start with prefix of (bucket-)"] with input as valid_case
}
test_invalid_bucket_names1 if {
valid_case := {
"bucket": "bucket-test-production",
"type": "aws_s3_bucket",
"env": "development"
}
main.warn_prefix["The bucket bucket-test-production should start with suffix of (-development)"] with input as valid_case
}
You can add more options, such as checking for both incorrect prefixes and suffixes.
Additionally, if you want to use main.rego in your unit tests or in your workflow:
- name: Conftest UnitTest
run: conftest verify -p $PATH
- name: Conftest check
run: conftest test s3_data.json --policy $PATH --output json > conftest_output.json
Sending notification on Pull Request
Since you can now derive data from the Terraform plan, create an OPA Rego rule, and check the data against the Rego rule, you may also want to send a warning message to the Pull Request to notify the PR creator.
To do this:
- name: Send notification
uses: actions/github-script@v7
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
with:
script: |
const fs = require('fs');
const conftestOutput = JSON.parse(fs.readFileSync('conftest_output.json', 'utf8'));
let messages = conftestOutput.flatMap(result => result.warnings?.map(warning => warning.msg) || []);
if (messages.length > 0) {
const warnings = `<details><summary>Warnings</summary>\n\n\`\`\`\nWarning - ${messages.join('\nWarning - ')}\n\`\`\`\n</details>\n`;
const output = `${warnings}`;
github.rest.issues.createComment({
issue_number: context.issue.number,
owner: context.repo.owner,
repo: context.repo.repo,
body: output
});
}
Recommendations
- When you create a Rego script, make sure to follow the original documentation. It gets updated quite often and can be written in different formats based on the versions.
https://www.openpolicyagent.org/docs/latest/policy-language/ - Create a large number of unit tests considering multiple possible options.
- Test both valid and invalid cases in unittest.rego.
Conclusion
With the above approach, you can successfully notify the PR creator about the naming rules they should follow when they create a PR.
OPA Rego is not only limited to this but can also do much more, such as:
- Enforcing security policies
- Validating configuration files
- Controlling access to resources
- Ensuring compliance with regulatory requirements
- Enforcing best practices in infrastructure as code