論文読み
Image-to-Image Translation with Conditional Adversarial Networks [Phillip Isola+ CVPR17]
https://arxiv.org/abs/1611.07004
Introduction

コンピュータビジョンにおける多くの問題は、入力画像に対応する出力画像に変換する問題と考えることが出来る。十分な学習データが与えられたときに、あるシーン(RGB画像、エッジマップ、セマンティックラベル等)の表現を別のシーンの表現に変換するタスクをautomatic image-to-image translationと定義する。これらの課題は画素から画素を予測するという設定は同じであるのにも関わらず、それぞれ独立した別のアルゴリズムを用いてきた。本論文の目標はこれらすべての問題に対する共通のフレームワークを開発することである。
コンピュータビジョンではCNNが様々な画像予測問題の解決に貢献している。CNNでは損失関数を最小化するように自動的に学習が行われるのにもかかわらず、CNNに我々が望むことを実行させるために必要な損失関数を考えることは一般的に専門家の知識が必要であり、効果的な損失の設計に労力がとられているのが現状である。(もし愚直にCNNの予測ピクセルとGTのピクセルのユークリッド距離を最小化するように学習するとぼやけた結果を出力する傾向がある。)
「出力を本物と区別できないようにする」のような高度な目標を設定し、その目標を満たすのに適した損失関数を自動的に学習できれば非常に望ましい。近年提案されたGANはこれを実現したものである。ぼやけた画像は明らかに偽物に見えるため、許容されない。GANはデータに対応した損失を学習するため、従来は全く異なる種類の損失関数を必要としていた様々なタスクに適用が出来る。
本論文ではconditional GAN(cGAN)を用いた変換を検討する。GANがデータの生成モデルを学習するように、cGANでは条件付きの生成モデルを学習する。cGANはimage-to-image変換タスク(入力画像を条件として、それに対応する出力を生成する)に適している。GANに関する研究は多くされているが、先行研究では特定の使用用途のみに焦点を当てたものがほとんどで、画像間変換の汎用的な解決策としてどの程度有効なのかは不明であった。本論文では様々な問題に対してcGANが妥当な結果を出すことを示す。
Related work
Structured losses for image modeling
画像間の変換問題は、しばしばピクセル単位の分類・回帰として定式化される。しかしピクセル単位の定式化は、出力空間を「非構造的」に扱っていると考えられる。一方でcGANは構造的な損失を学習することが出来る(理論的にはあらゆる構造も学習することが出来る)。
Conditional GANs
cGANに関する研究は多く行われており、画像を条件としたモデルは、インペインティング、未来フレーム予測、画風変換、超解像等の分野で成功している。いずれも特定のタスクに特化したものであるが、本論文のフレームワークは他よりもシンプルなものとなっている。
本手法では生成器と識別器のアーキテクチャの選択においても、先行研究と異なっている。過去の研究とは異なり、生成器にはU-netベースのアーキテクチャ、識別器にはパッチレベルの構造に注目する「PatchGAN」分類器を用いる。PatchGANのアーキテクチャは既存研究でも局所的なスタイル統計量を抽出するために使用されているが、本研究ではこのアプローチがより広い範囲の問題に対して有効であることを示す。
method
GANはランダムなノイズベクトルzから出力画像yへの写像G:z->yを学習する生成モデルである。これに対しcGANは観測画像xとランダムなノイズベクトルzから出力画像yへの写像G:{x,z}->yを学習する。生成器Gは敵対的に学習している識別器Dによって本物の画像と区別されないような出力画像を生成するように学習される。識別器Dは生成器の偽物を出来るだけうまく検出するように学習する。
objective
cGANの目的関数は次の式で表現できる。
$$ L_{cGAN}(G,D) = E_{x,y}[logD(x,y)] + E_{x,z}[log(1-D(x,G(x,z))] $$
Gは目的関数を最小化、Dは最大化するように学習する。(Dは本物が来たら1,偽物は0を出力したい。Gは本物に近い画像を生成したい。右辺第一項は本物の画像yが来た場合、第二項は偽物の画像G(x,z)が来た場合。)
既存研究ではGANの目的関数にL2距離のような損失と合わせることが有益であることが分かっている。これによって生成器は識別器をだますだけでなく、GT画像とL2距離的に近くなる。本研究ではL1距離を使用することによってぼかしが少なくなることを発見した。
$$ L_{L1}(G) = E_{x,y,z}[||y-G(x,z)||] $$
よって我々は次の目的関数を用いる。
$$ G* = arg min_G max_D L_{cGAN}(G,D) + \lambda L_{L1}(G) $$
zが無い場合決定論的な出力を生成し、分布はデルタ関数的になってしまう。そのため過去のcGANではxに加えてノイズzを生成器の入力としていた。しかし我々は実験によって生成器はノイズを無視するようになるためか有効性を見いだせなかった(生成器はノイズを無視するように学習する)。我々のモデルでは学習時とテスト時両方でいくつかの層にdropoutを導入するという形のみでノイズを与えた。しかしこのノイズでも出力にはわずかな確率性しか観測できない。高い確率的出力を生成するCGANの設計は本研究で残された問題である。
Network architectures
Generator with skips
画像間変換の問題の特徴は高解像度の入力を高解像度の出力に写像することにある。さらに我々が考える問題では入力と出力が表面上は異なるとはいえ構造的には同じである。
我々はこれらのことを考慮して生成器のアーキテクチャを設計した。既存研究ではencoder-decoderモデルを使用していたが、この場合全ての情報はボトルネック層を含む全ての層を通過する必要がある。しかし多くの画像変換問題では入力と出力の間で低レベルの情報が共有されていることが多い(カラー化ではエッジの位置を共有する)。そのためこのような情報のボトルネックを回避するために生成器に「U-Net」のようなスキップ接続を追加する。具体的にはレイヤーi,レイヤーn-iの間にスキップ接続を追加する。
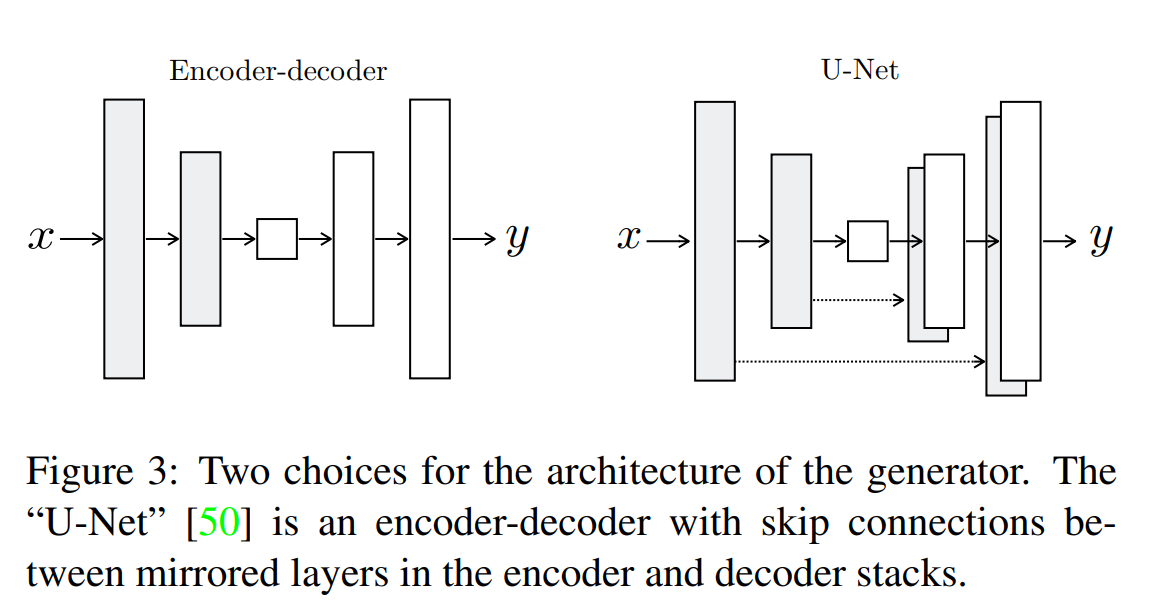
Markovian discriminator(Patch GAN)
L1,L2損失は画像生成問題でぼやけた結果を生成することは良く知られている。これらの損失は高周波の情報を促進することが出来ないが、多くの場合において低周波の情報を正確にとらえることが出来ている。よって低周波における正確さを強制する枠組みはL1損失で十分であると考えられる。
よってGANによる識別器は高周波構造のみをモデル化し、低周波はL1項に依存することとする。高周波をモデル化するためには局所的な画像パッチの構造に注目することを考え、パッチスケールの構造にペナルティを課すPatchGANの仕組みを用いる。PatchGANの識別器は画像中のN×Nピクセルのパッチが本物か偽物かを判定し、これを画像全体で行い平均化して出力としている。
Optimization and inference
GANの論文(Generative Adversarial Nets)でも提案されているように$log(1-D(x,G(x,z)))$を最小化するのではなく$logD(x,G(x,z))\ $を最大化するように学習する。最適化にはミニバッチSGDやAdam。通常の学習とは異なり、テスト時もDropoutを使用、テストバッチの統計量を用いたバッチ正規化を適用している。
experiments
cGANの一般性を探るために様々なタスクでテストする。
Semantic labels <-> photo
BlackWhite -> color photos
Edges -> photo
Day -> Night
入力と出力は単純に1-3チャネルの画像となっている。
Evaluation metrics
合成された画像の品質の評価は困難な問題である。平均二乗誤差のような測定法では構造を測定することが出来ない。本論文ではAMT(人間)による評価と、既存モデル(FCN)を用いた評価を行っている。
Analysis of the objective function

L1のみではぼやけた結果に、cGANのみではよりシャープな結果が得られるが視覚的なアーティファクトが発生する場合がある。両項を追加することでこれらのアーティファクトを抑えることが出来る。
また、色合いに注目した場合、L1では色が分からない場合灰色にしてしまうという問題がある(その方が損失を最小化できるため)。cGANの場合灰色の出力は非現実的であるとして真の色分布に一致するように学習できる。実際にL1はGTよりも狭い分布であるのに対し、cGANはGTの分布に近いものとなる。
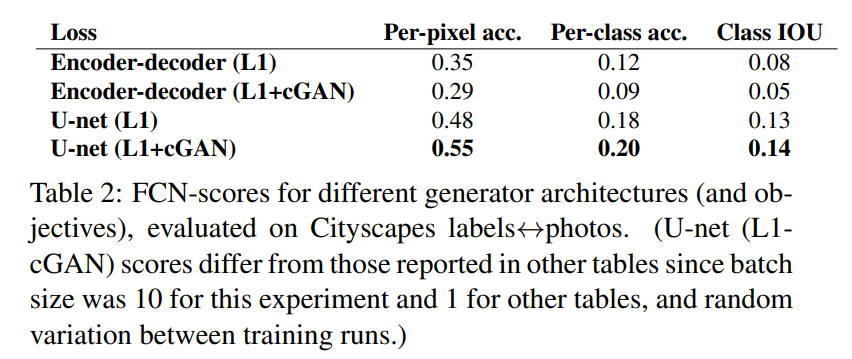
Analysis of the generator architecture
U-Netのアーキテクチャは低レベルの情報をネットワーク上でショートカットできるようにしている。このskip connectionの影響で良い結果を出すことが出来ることが分かった。

From PixelGANs to PatchGANs to ImageGANs
パッチのサイズN×Nを1×1(PixelGAN)から286×286(ImageGAN)まで変化させて検証する。以下の画像のように、L1ではぼかしや色彩の低下があり、1×1 PixelGANでは色の多様性は促進されるものの、空間的な影響はない。16×16 PatchGANではシャープな出力が期待できるがアーティファクトが出てしまう。70×70 PatchGANは空間的にも色彩的にもシャープな出力が得られる。286×286 ImageGANでは70×70に視覚的に近いものが得られるがFCNスコアでは低い結果となった(これはImageGANが70×70の場合よりも多くのパラメータを持ち学習が困難であることが原因と思われる。)。

PatchGANの利点として、識別器がパッチのサイズに対応しているため、入力画像は任意の大きさにできる部分にある。論文内では実際に256×256画像以外にも512×512画像でも実験を行っている。
Perceptual validation
AMT実験では、地図 <-> 航空写真のタスクにおいて、地図 -> 写真ではL1ベースラインを大幅に上回った。しかし写真 -> 地図ではL1と大きな差はなかった。これは航空写真よりも地図の方が微細な構造誤差が顕著に表れるためであると考えられる。またカラー化の実験でも単純なL2回帰には勝るものの専用の特化した手法にはかなわないという結果となった。
Semantic Segmentation
cGANは出力が精密または写真的であると効果的であると考えられる。それではsemantic segmentationのような出力が入力よりも単純な場合はどうなるだろうか?街並み写真 -> ラベルを学習させたところ、cGANを用いた場合もそれなりの精度は出せるものの単純にL1損失で学習させた方がcGANより良いスコアとなった。
Community-driven Research
pix2pixのコードは公開されており、多くのコミュニティが新しい画像間変換タスクにこのフレームワークを適用することに成功している。具体的には背景除去、スケッチ -> 肖像画、スケッチ -> ポケモン、エッジ -> 猫等がある。

Conclusion
本論文の結果からcGANは多くのimage-to-image translationタスクで有望なアプローチであると考えられる。このネットワークはタスクとデータに適応した損失を学習するため様々な場面で適用可能である。
実際に動かしてみる
上記のコードであれば、README.mdや以下のブログがとても参考になりました。
https://farml1.com/pix2pix_1/
https://farml1.com/pix2pix_2/
git clone https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix
cd pytorch-CycleGAN-and-pix2pix
bash ./datasets/download_pix2pix_dataset.sh facades
pytorch-CycleGAN-and-pix2pix/datasets/facades/{train,val,test}を見てみるとデータは以下の形式で保存されていることが分かります。カスタムデータセットを作成・使用する場合も同様に画像を並べて保存するのが良いです。

python train.py --dataroot ./datasets/facades --name facades_pix2pix --model pix2pix --direction BtoA --display_id 0
python test.py --dataroot ./datasets/facades --name facades_pix2pix --model pix2pix --direction BtoA
学習内容や結果はデフォルトではpytorch-CycleGAN-and-pix2pix/checkpoints/(facades_pix2pix)に保存される。以下に学習時の設定を変更するための情報を置きます。詳細はtrain_option.py、base_options.py参照。
--dataroot : 画像置き場、train,val,testのディレクトリがあることが想定されている。
--checkpoints_dir,--name : 保存先のディレクトリ、checkpoints_dir下に作成される。
--gpu_ids : 使用するGPU
--model : pix2pixかcycleGANかを選ぶ。今回はもちろんpix2pix
--input_nc,--output_nc : 入出力のチャネル数
--direction : AtoBであれば画像の左から右を、BtoAであれば右から左に学習する
--preprocess : データ拡張の種類を指定。(デフォルトは'resize_and_crop')
--load_size : 画像をこの値にリサイズする
--crop_size : 画像をこの値でクロップする(2の累乗が推奨)
--no_flip : データ拡張でflipをしないか
--display_id : 学習内容を出力するディスプレイを指定するらしい。0にしておくのが吉
--n_epochs : 初期値の学習率で学習するエポック数
--n_epochs_decay : ↑の後に学習するエポック数
終わりに
以前から気になっていたPix2Pixの論文を読んで、とりあえず実際に動かすところまで(思ったよりも簡単に使用できる)。近年では拡散モデルが主流なのでそちらについても調べたいですね。