初めに
Akira_0809だよ、
今回はProgate Pathのアドベントカレンダーに参加しています!
必要なもの
- Python
- Google Chrome
- ChromeDriver (Chromeのversionが115以下の場合)
- OCR
- やる気
Pythonでコーディングできる環境があることを前提にしています。
ChromeDriverのインストール
Chromeのバージョンが115以下の場合のみ
上のリンクからChromeのバージョンと同じものをダウンロードしてください。
適当なディレクトリに置きます。
driver = webdriver.Chrome('ChromeDriverのディレクトリ + chromedriver')
Seleniumのインストール
Seleniumとはブラウザを自動的に操作するためのライブラリです。
pip install selenium
Seleniumをインストールします。
PyAutoGUIのインストール
PyAutoGUIとはPythonスクリプトでマウスとキーボードを制御して,「マウス操作の自動化」や「キーボード入力の自動化」を実現します。
pip install pyautogui
PyAutoGUIをインストールします。
実際に作る!
準備が整ったので実際に作成していきます。
サイトにアクセスする
最初にサイトにアクセスしてみましょう。
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get("https://sushida.net/")
sleep(10)
このコードで寿司打のサイトにアクセスして10秒間Chromeが表示されます。
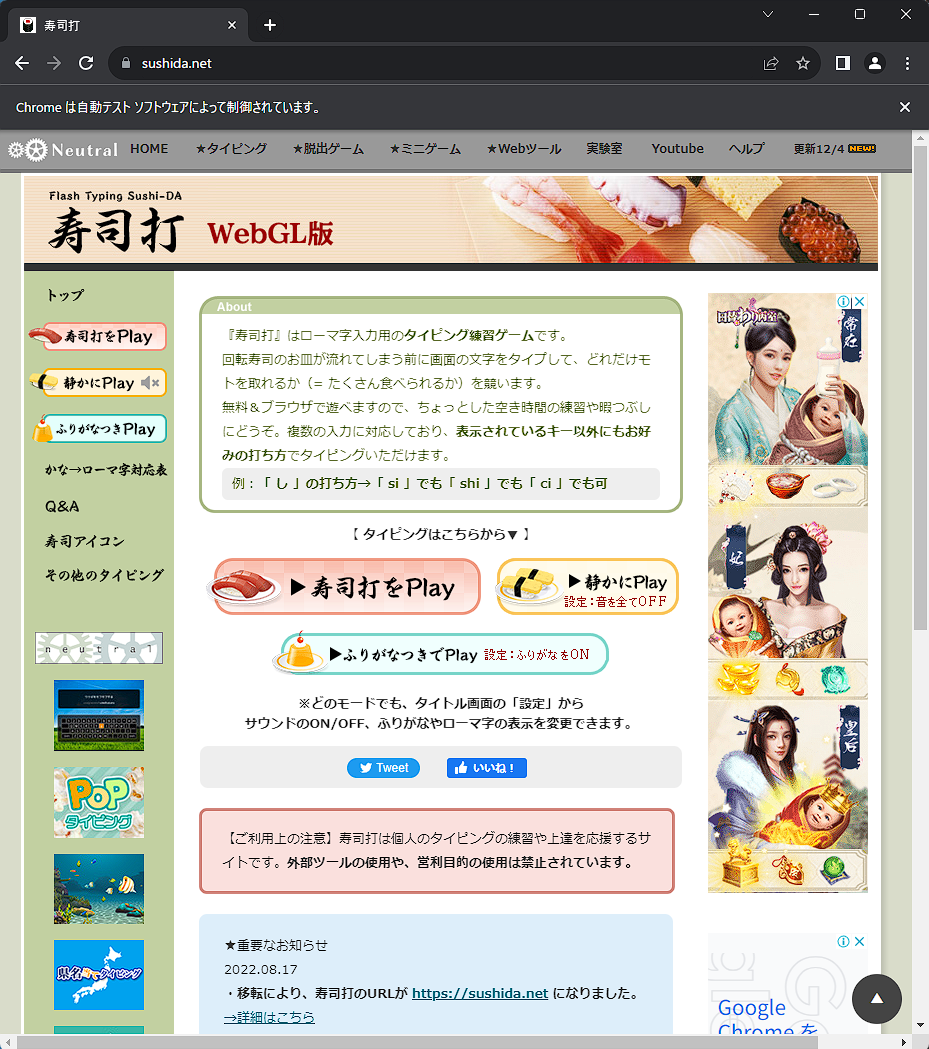
上の方に「Chromeは自動テストソフトウェアによって制御されています。」と表示されていれば成功です。
ボタンのクリック
次にボタンをクリックしてみます。
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
driver = webdriver.Chrome()
driver.get('https://sushida.net/')
sleep(5)
start = driver.find_element(By.XPATH, '//*[@id="main"]/div[3]/a[1]/img')
start.click()
sleep(10)
seleniumではHTMLの要素を取得するためのメソッドが複数個あります。
今回はxpathを使っていきます。
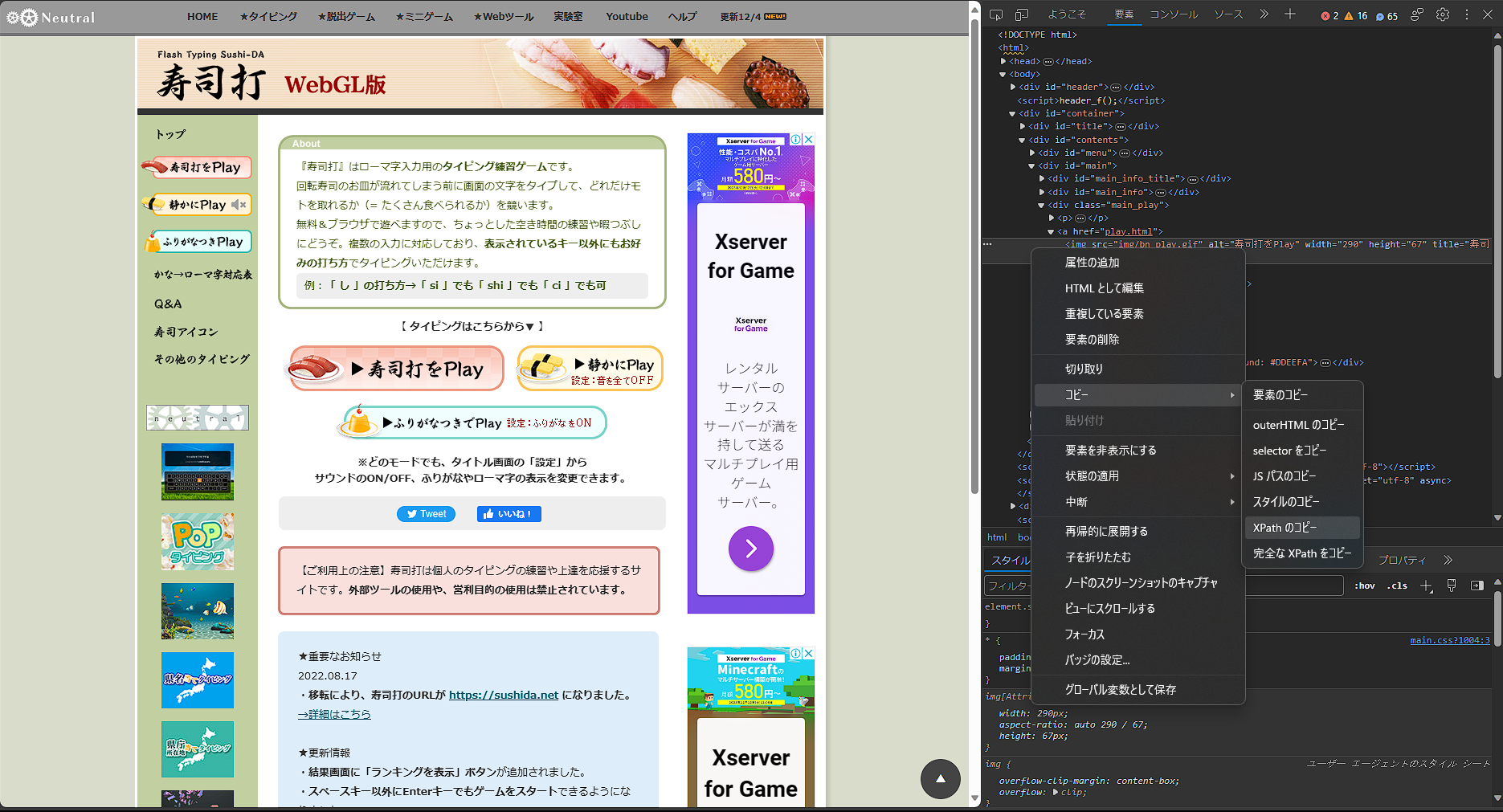
開発者モードで取得したい要素を左クリックして「xpathのコピー」をクリックしてコピーします。
寿司打のスタートボタンのクリック
寿司打のゲーム画面はHTMLではないのでPyAutoGUIのlocateOnScreen()を使います。
画面から設定された画像を探し出して座標を出力します。
スタートボタンがスケスケで表示が安定しないので設定ボタンの座標からスタートボタンの場所を割り出してクリックします。

マウス操作に関してはモニタの座標(x, y)を使用します。
(0, 0)は左上隅になり,X座標は右に行くほど,Y座標は下に行くほど増加します。
0,0 X increases -->
+---------------------------+
| | Y increases
| | |
| 1920 x 1080 screen | |
| | V
| |
| |
+---------------------------+ 1919, 1079
設定ボタンから-100くらいでスタートボタンが押せます。
from selenium import webdriver
from selenium.webdriver.common.by import By
import pyautogui as pag
from time import sleep
driver = webdriver.Chrome()
driver.get('https://sushida.net/')
sleep(5)
start = driver.find_element(By.XPATH, '//*[@id="main"]/div[3]/a[1]/img')
start.click()
sleep(10)
setteing_button = pag.center(pag.locateOnScreen("./images/setteing.png"))
start_button = pag.click(setteing_button.x, setteing_button.y-100)
sleep(10)
これでスタートボタンがクリックできます。
値段設定をする
値段設定も画像では厳しいので座標移動で実装します。
from selenium import webdriver
from selenium.webdriver.common.by import By
import pyautogui as pag
from time import sleep
import cv2
driver = webdriver.Chrome()
driver.get('https://sushida.net/')
sleep(5)
start = driver.find_element(By.XPATH, '//*[@id="main"]/div[3]/a[1]/img')
start.click()
sleep(10)
setteing_button = pag.center(pag.locateOnScreen("./images/setteing.png"))
pag.click(setteing_button.x, setteing_button.y-100)
sleep(3)
point = int(input("3000,5000,10000から選んで入力してください\n"))
while (1):
if point == 3000:
pag.move(0, -100)
pag.click()
break
elif point == 5000:
pag.click()
break
elif point == 10000:
pag.move(0, 100)
pag.click()
break
else:
point = int(input("3000,5000,10000から選んで入力してください\n"))
sleep(5)
モードを選択できるようにします。
入力するときにマウスカーソルを動かさないように注意しましょう。
OCRの導入
OCRの導入は説明がめんどくさいのでこのページを参照してください。
画面のスクショ
OCRに判定させるための画像を取得します。
from selenium import webdriver
from selenium.webdriver.common.by import By
import pyautogui as pag
from time import sleep
driver = webdriver.Chrome()
driver.get('https://sushida.net/')
sleep(5)
start = driver.find_element(By.XPATH, '//*[@id="main"]/div[3]/a[1]/img')
start.click()
sleep(10)
setteing_button = pag.center(pag.locateOnScreen("./images/setteing.png"))
pag.click(setteing_button.x, setteing_button.y-100)
sleep(3)
point = int(input("3000,5000,10000から選んで入力してください\n"))
while (1):
if point == 3000:
pag.move(0, -100)
pag.click()
break
elif point == 5000:
pag.click()
break
elif point == 10000:
pag.move(0, 100)
pag.click()
break
else:
point = int(input("3000,5000,10000から選んで入力してください\n"))
sleep(5)
while (1):
game = driver.find_element(By.XPATH, '//*[@id="#canvas"]')
game.screenshot("./images/image.png")
break
要素に対してスクショを撮ります。

こんな感じだったら成功!
文字列だけを切り取る
画像から入力する文字だけを切り取ります。
from selenium import webdriver
from selenium.webdriver.common.by import By
import pyautogui as pag
from time import sleep
from PIL import Image
import pyocr
import pyocr.builders
import cv2
import numpy as np
driver = webdriver.Chrome()
driver.get('https://sushida.net/')
sleep(3)
start = driver.find_element(By.XPATH, '//*[@id="main"]/div[3]/a[1]/img')
start.click()
sleep(10)
setteing_button = pag.center(pag.locateOnScreen("./images/setteing.png"))
pag.click(setteing_button.x, setteing_button.y-100)
sleep(1)
point = int(input("3000,5000,10000から選んで入力してください\n"))
while (1):
if point == 3000:
pag.move(0, -100)
pag.click()
break
elif point == 5000:
pag.click()
break
elif point == 10000:
pag.move(0, 100)
pag.click()
break
else:
point = int(input("3000,5000,10000から選んで入力してください\n"))
sleep(1)
while (1):
pag.press('enter')
sleep(3)
game = driver.find_element(By.XPATH, '//*[@id="#canvas"]')
game.screenshot("./images/image.png")
im = Image.open('./images/image.png')
im.crop((70, 230, 450, 260)).save('./images/image.png', quality=95)
sleep(5)
break

こんな感じになればOK!
OCRで文字列の検出
トリミングした画像から文字の検出をします。
from selenium import webdriver
from selenium.webdriver.common.by import By
import pyautogui as pag
from time import sleep
from PIL import Image
import pyocr
import pyocr.builders
import cv2
import numpy as np
def render_doc_text(file_path):
# ツール取得
pyocr.tesseract.TESSERACT_CMD = "C:/Users/akira/AppData/Local/Programs/Tesseract-OCR/tesseract.exe"
tools = pyocr.get_available_tools()
tool = tools[0]
# 画像取得
img = cv2.imread(file_path, 0)
img = Image.fromarray(img)
# OCR
builder = pyocr.builders.TextBuilder()
result = tool.image_to_string(img, lang="eng", builder=builder)
return result
driver = webdriver.Chrome()
driver.get('https://sushida.net/')
sleep(3)
start = driver.find_element(By.XPATH, '//*[@id="main"]/div[3]/a[1]/img')
start.click()
sleep(10)
setteing_button = pag.center(pag.locateOnScreen("./images/setteing.png"))
pag.click(setteing_button.x, setteing_button.y-100)
sleep(1)
point = int(input("3000,5000,10000から選んで入力してください\n"))
while (1):
if point == 3000:
pag.move(0, -100)
pag.click()
break
elif point == 5000:
pag.click()
break
elif point == 10000:
pag.move(0, 100)
pag.click()
break
else:
point = int(input("3000,5000,10000から選んで入力してください\n"))
sleep(1)
pag.press('enter')
sleep(3)
while (1):
game = driver.find_element(By.XPATH, '//*[@id="#canvas"]')
game.screenshot("./images/image.png")
im = Image.open("./images/image.png")
im.crop((90, 230, 400, 260)).save("./images/image.png", quality=95)
string = render_doc_text("./images/image.png")
pag.write(string)
関数を作成して、無限ループで回せば完成!
完成!
途中でトリミングした範囲よりも長い単語が出てきてミスを連発しましたが工夫しだいでどうにかなります。
頑張ってみてね!
最後に
めっちゃ忙しい中書いたのでおかしい所があるかも
次はハッカソンで人生変わった話書きます。
参考文献