作ったもの
実装コード__は、「作ったもの」の次の節に掲載__しています。
コードのうち、CaboChaを使って、strオブジェクトから、"係り受け元単語 -> 係り受け先単語"の配列を得る処理__は、@ayuchiyさんのQiita記事__を参考にしました。
python3 tkinter_ner_sub_pred_pair.py
スクリプトファイルを実行すると、Tkinterが起動して、次のGUI画面が立ち上がります。
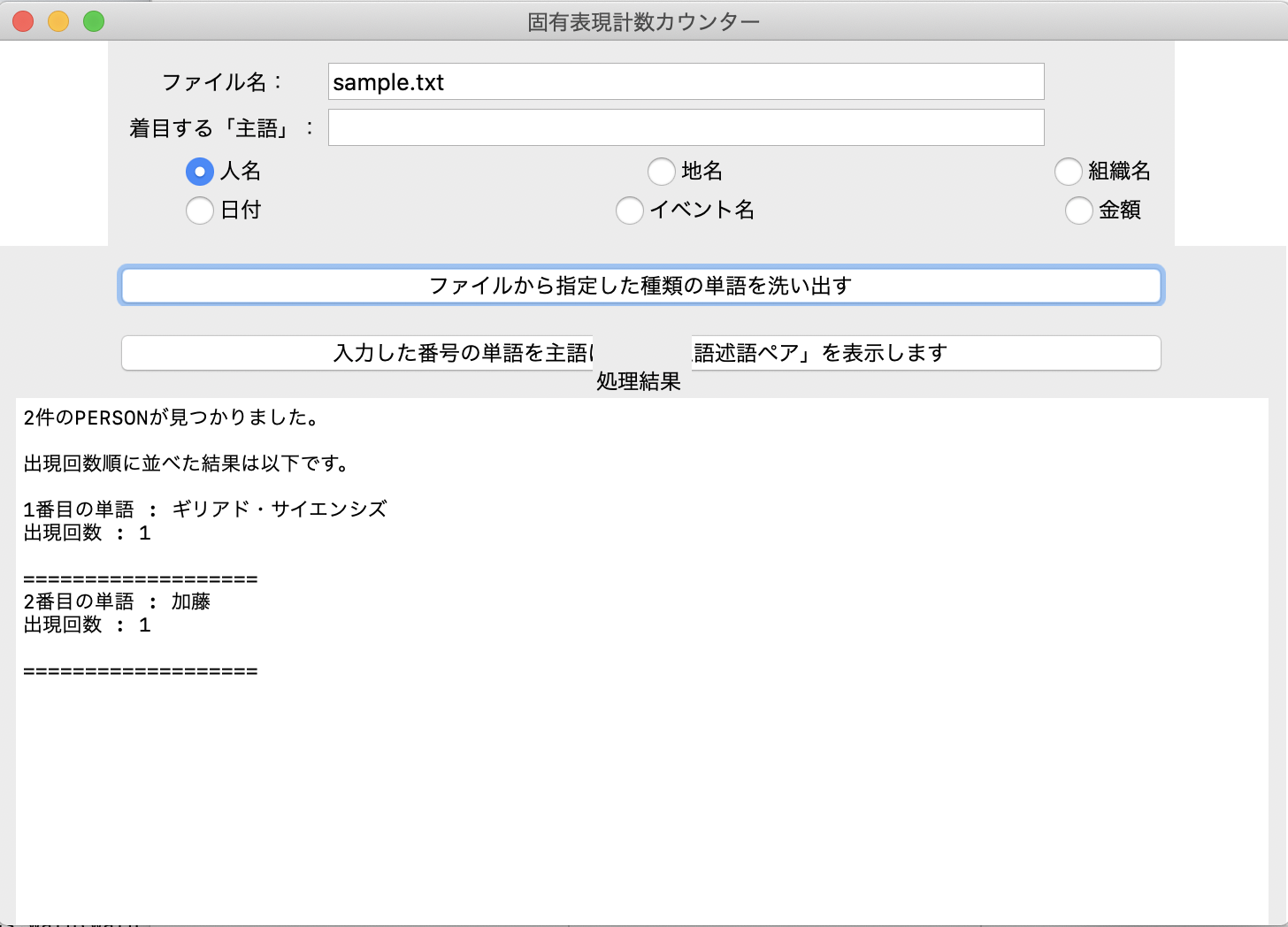
- スクリプトファイルと同じディレクトリにあるsample.txtを相対パスで入力。
- 「人名」のラジオボタンを選択後、「ファイルから指定した種類の単語を洗い出す」ボタンを押す。
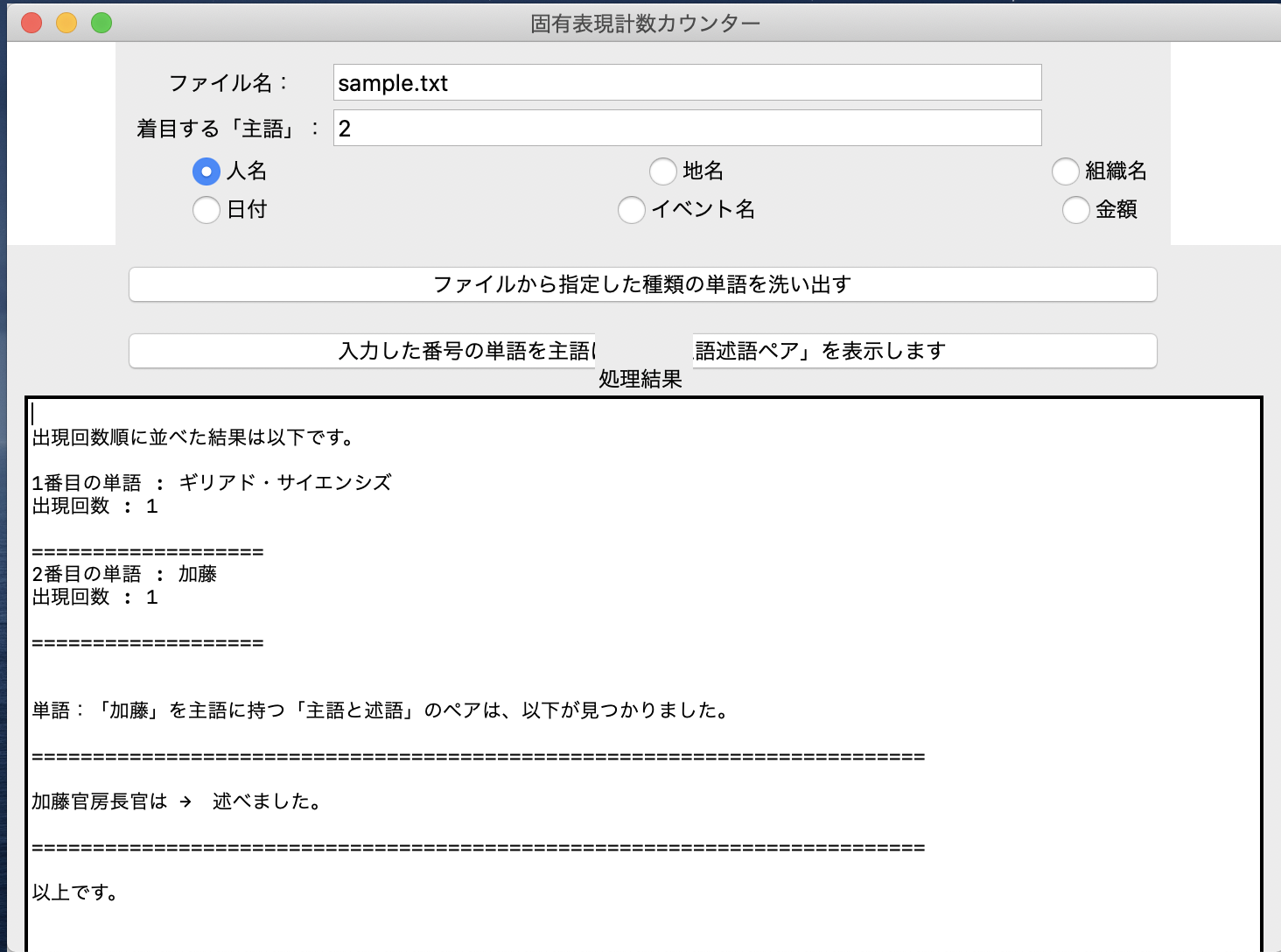
『着目する「主語」』入力欄に「2」を入力して、「入力した単語の番号の単語を主語に持つ「主語述語ペア」を表示します。」ボタンを押す。
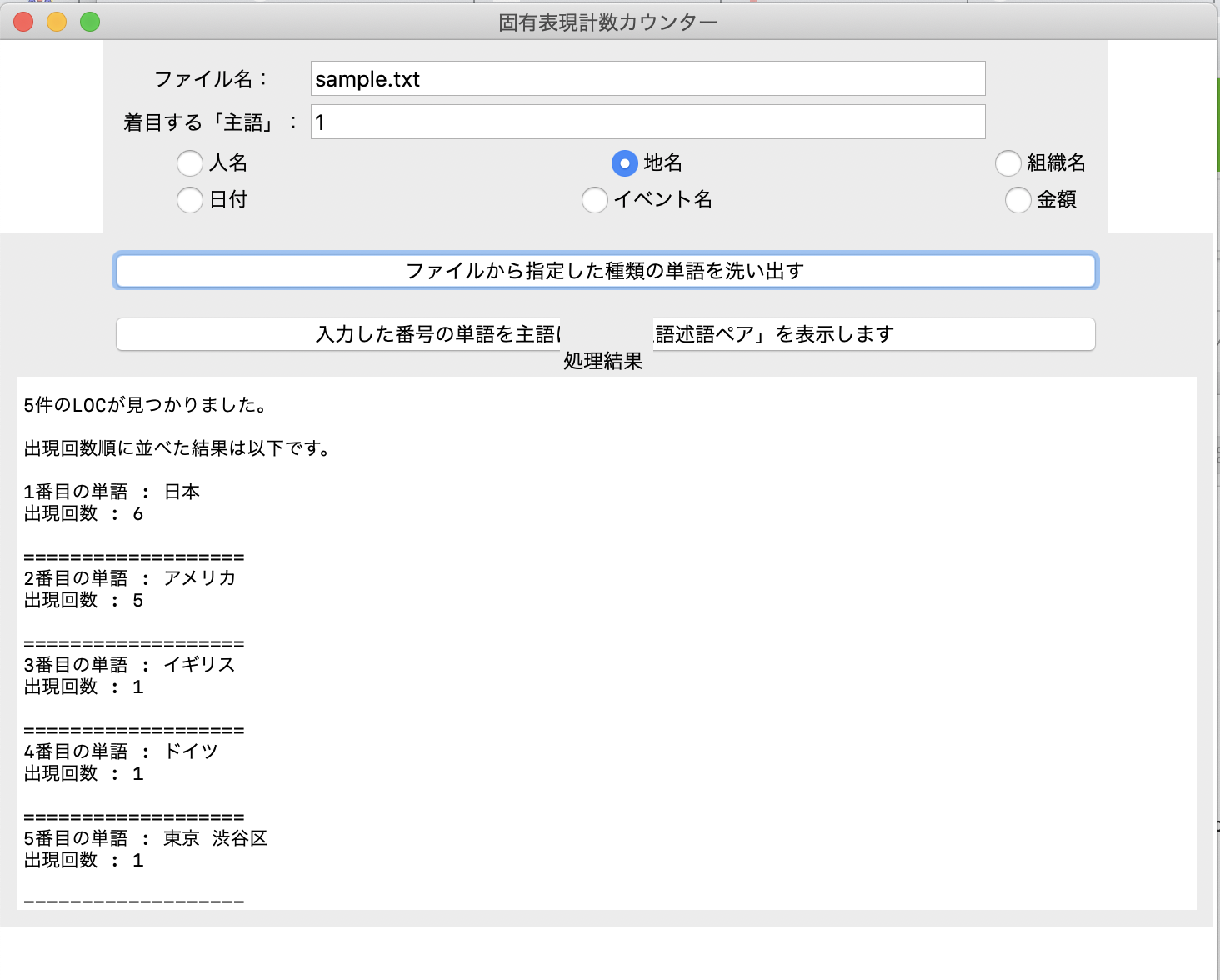
次は、「地名」のラジオボタンを選択。「ファイルから指定した種類の単語を洗い出す」ボタンを押す。
『着目する「主語」』入力欄に「2」を入力して、「入力した単語の番号の単語を主語に持つ「主語述語ペア」を表示します。」ボタンを押す。
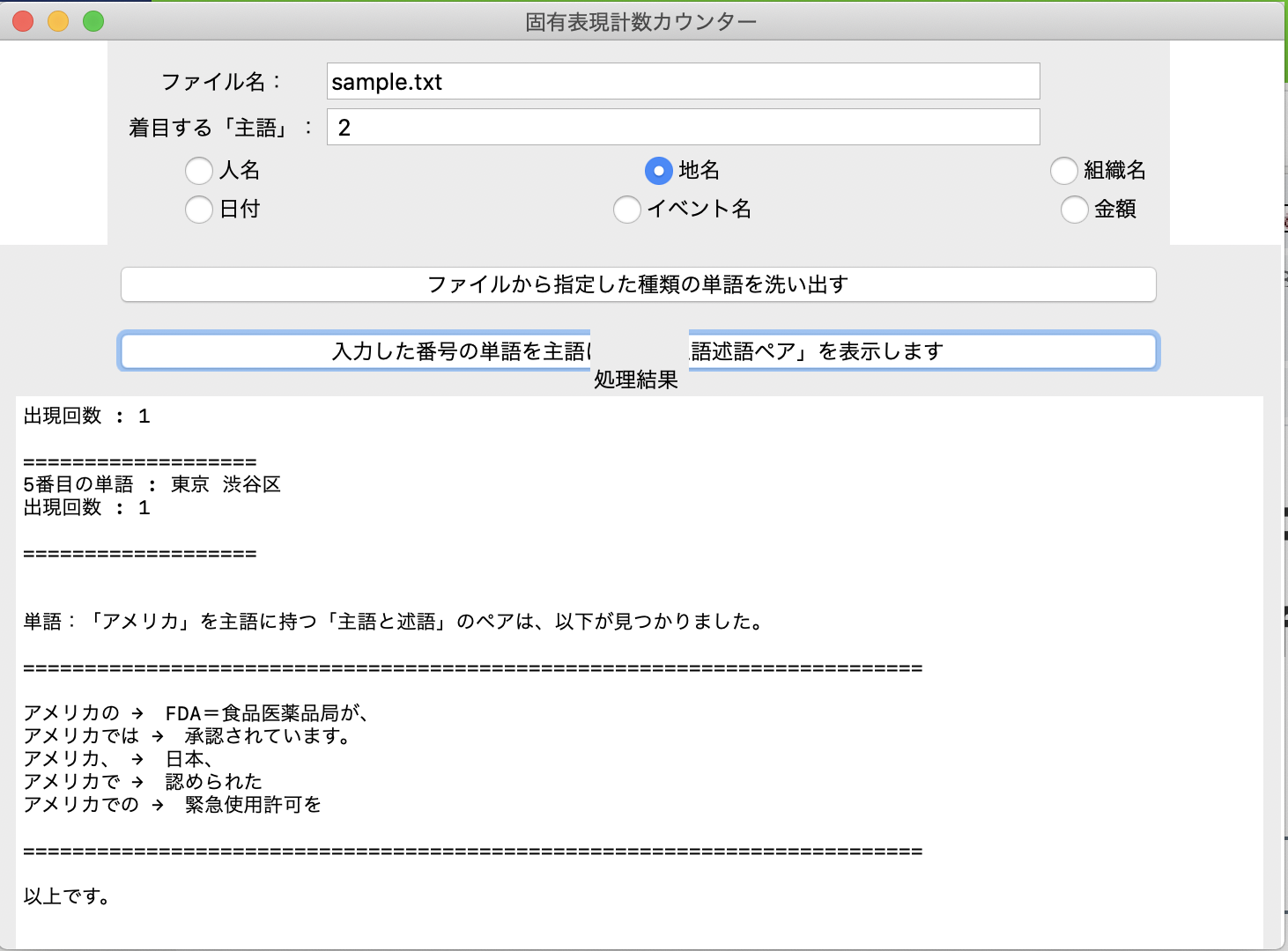
『着目する「主語」』入力欄に「4」を入力して、「入力した単語の番号の単語を主語に持つ「主語述語ペア」を表示します。」ボタンを押す。
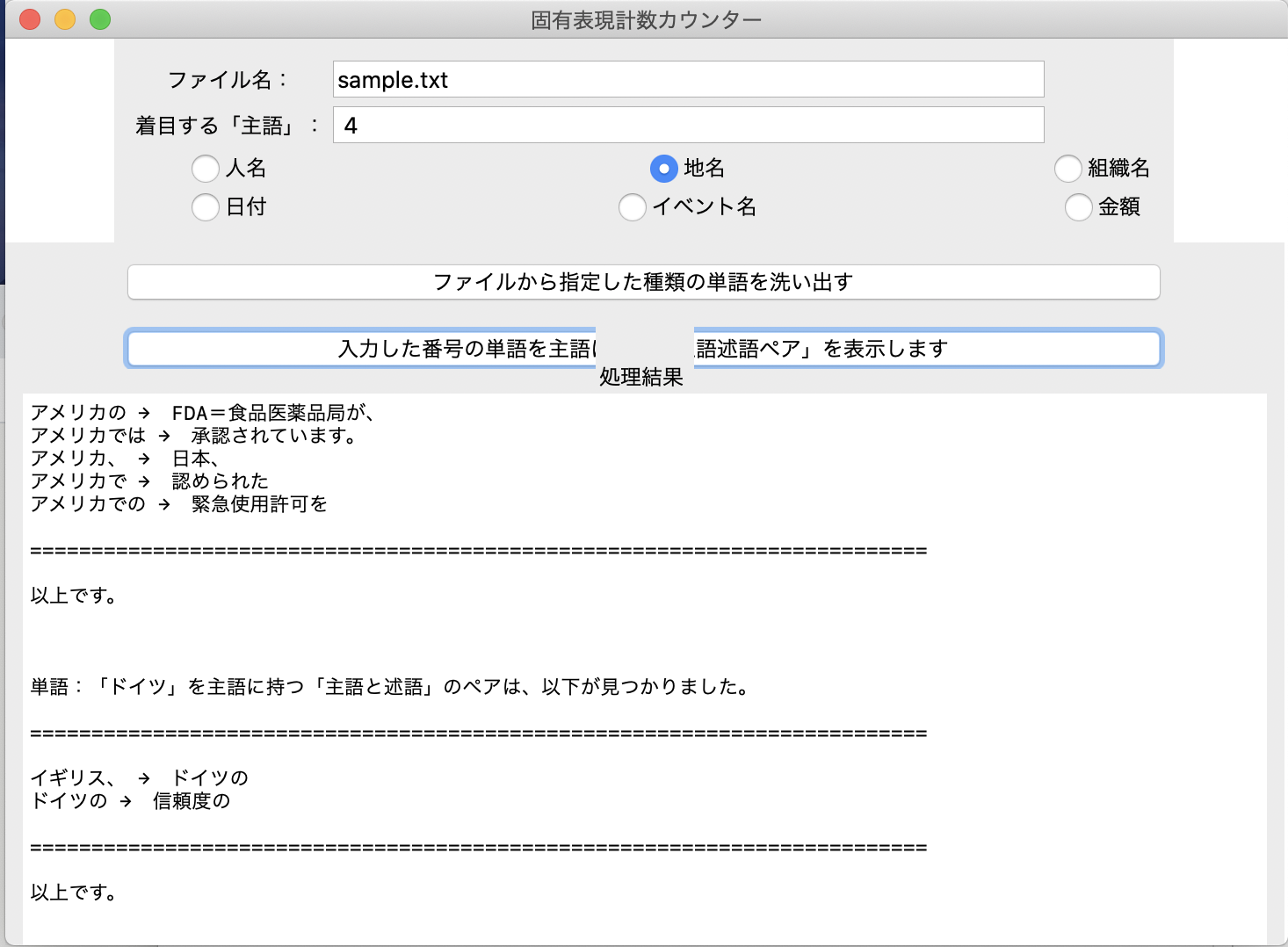
次は、「組織名」のラジオボタンを選択。「ファイルから指定した種類の単語を洗い出す」ボタンを押す。
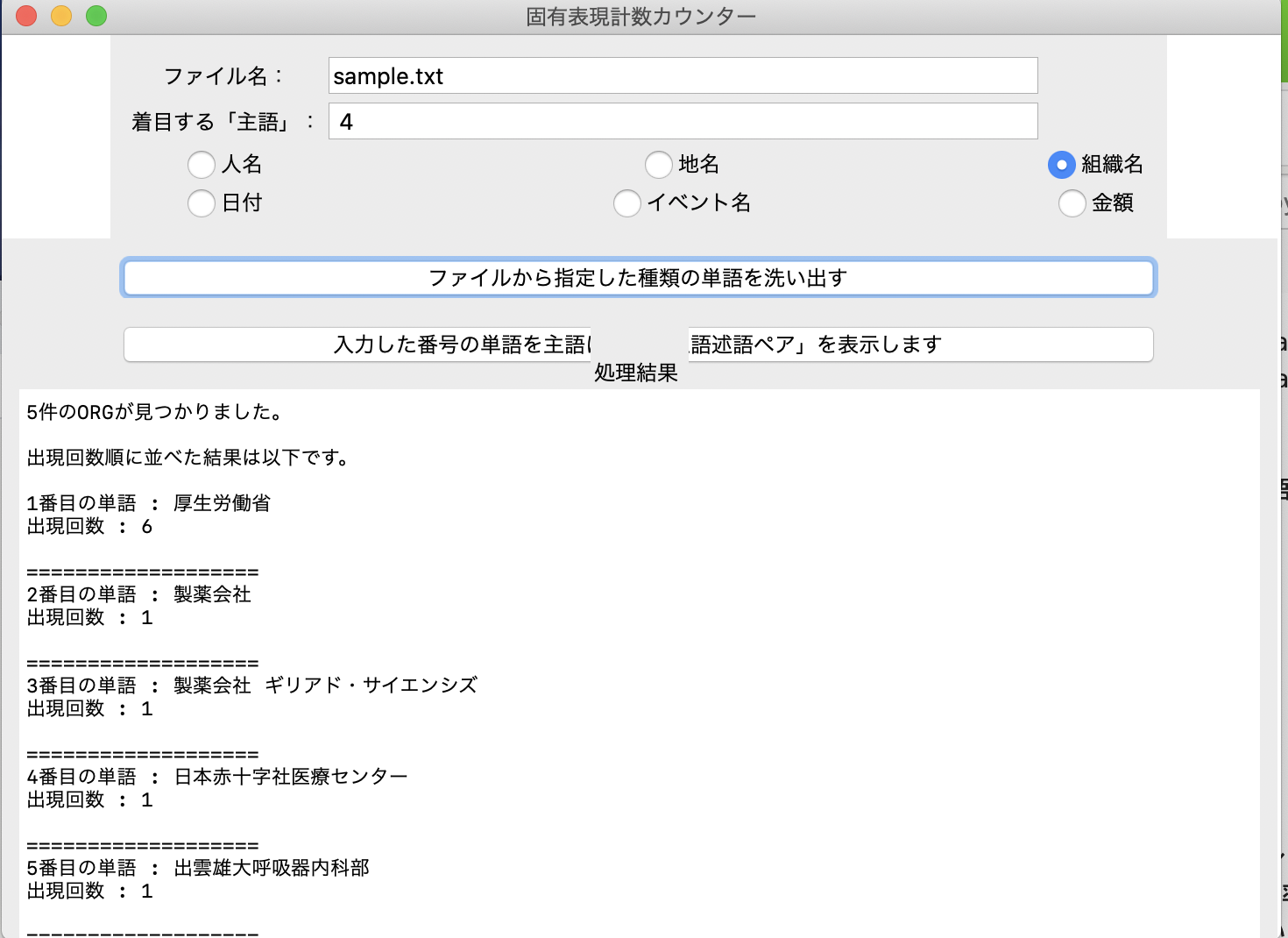
『着目する「主語」』入力欄に「1」を入力して、「入力した単語の番号の単語を主語に持つ「主語述語ペア」を表示します。」ボタンを押す。
( 読み込んだテキストファイル )
NHK NewsWebから、ある日のニュース記事を拝借しました。
新型コロナウイルスの治療薬として日本で特例承認されている、抗ウイルス薬レムデシビルについて、WHO=世界保健機関は、世界各地の臨床試験を分析した結果、「死亡率の低下などにつながる重要な効果はなかった」として、入院患者への投与は勧められないとする指針を公表しました。
レムデシビルを開発した製薬会社ギリアド・サイエンシズは、患者が回復に至るまでの期間は大幅に短縮しているなどと反論しています。
WHOは20日、抗ウイルス薬レムデシビルを使った世界各地の入院患者に対する臨床試験を分析し、治療に関する指針を公表しました。
それによりますと、
▽死亡率の低下や
▽人工呼吸器の必要性、
それに
▽症状の改善にかかる時間について、
「重要な効果はなかった」としています。
このため、WHOはレムデシビルについて「症状の軽い重いにかかわらず、入院患者への投与は勧められない」としています。
レムデシビルについては、アメリカのFDA=食品医薬品局が、ことし5月、緊急での使用を許可し、これを受けて日本も特例で使用を承認していて、アメリカでは先月、新型コロナウイルスの治療薬として正式に承認されています。
製薬会社 ギリアド・サイエンシズが声明
ギリアド・サイエンシズは、WHOが指針を公表したことに対して声明を出しました。
それによりますと「製品は、アメリカ、日本、イギリス、ドイツの信頼度の高い多くの治療指針で、入院患者への標準治療薬として認識されている。これらの推奨は、複数の試験からの強固なエビデンスに基づいていて行われている」としています。
そのうえで「患者が回復に至るまでの期間の大幅な短縮などの効果は、医療機関に恩恵をもたらしている。WHOの指針はこのエビデンスを軽視しているように見え、残念に思う。現在世界中で患者数が劇的に増加している中、およそ50か国で、初めてかつ唯一の承認された治療薬として、医師たちに信頼されている」としています。
厚生労働省「承認 見直す予定ない」
レムデシビルは、日本で初めての新型コロナウイルスの治療薬として、ことし5月に承認されました。
アメリカで重症患者に対する緊急的な使用が認められたことを受けて、厚生労働省は審査を大幅に簡略化する「特定承認」の制度を適用し、製薬会社の申請から3日という異例の早さで承認しました。
厚生労働省が公表している「診療の手引き」では、原則、人工呼吸器や人工心肺装置=ECMOなどを装着する重症患者に投与することとしています。
レムデシビルは新型コロナウイルスの増殖を抑える作用がある治療薬としては、今も国内で承認された唯一の薬となっています。
供給量が限定されるため、現在は厚生労働省から使用を希望する医療機関に配付されています。
今回のWHOの指針について、厚生労働省は「承認時に根拠にした治験のデータが否定されたわけではないうえ、有効性がないという結果でもないため、承認について見直す予定はない」と話しています。
加藤官房長官は閣議のあとの記者会見で、指針について「レムデシビルの効果がないとまでは証明されておらず、また、レムデシビルに効果があるとする十分なエビデンスもないという説明などが記載されている」と述べました。
そのうえで「日本ではアメリカでの緊急使用許可を契機に、複数の臨床試験の結果から一定の有効性が確認できたことから、5月に特例承認を行い、現在、レムデシビルを使った治療がなされている。厚生労働省では特段、承認について見直す必要はないというのが、現時点での認識だと承知している」と述べました。
現場の医師「効果を実感 引き続き使っていく」
これまでレムデシビルを使った治療を行ってきた、東京 渋谷区の日本赤十字社医療センターの出雲雄大呼吸器内科部長は、「日本で特例承認されてから、これまでおよそ40人の新型コロナウイルスの重症患者に対してレムデシビルを投与してきたが、生存率の向上や、人工呼吸器から離脱できるようになるなど、効果を実感してきた。レムデシビルは、1人に25万円程度かかるなど高価なこともあり、WHOは『推奨しない』と判断したのかもしれないが、命はお金より重いはずだ。ほかに特効薬が出るまでは、私たちとしては引き続き使っていくことになる」と話していました。
事前準備
CaboChaをインストール
・ @/minetta30さんのQiita記事 「Mac(Catalina)にcabocha-pythonがインストールできないときの対処法」
実装コード
以下のコードのうち、CaboChaを使って、strオブジェクトから、__"係り受け元単語 -> 係り受け先単語"__の配列を得る処理は、@ayuchiyさんのQiita記事を参考にしました。
・ @ayuchiyさんのQiita記事 「CaboCha & Python3で文節ごとの係り受けデータ取得」
# Tkinterのライブラリを取り込む
import tkinter, spacy, collections, CaboCha, os
from typing import List, TypeVar
from tkinter import *
from tkinter import ttk
from tkinter import filedialog
from tkinter import messagebox
from spacy.matcher import Matcher
# グローバル変数の宣言
exracted_entity_word_list = ""
user_input_text = ""
named_entity_label = ""
T = TypeVar('T', str, None)
Vector = List[T]
# ファイルの参照処理
def click_refer_button():
fTyp = [("","*")]
iDir = os.path.abspath(os.path.dirname(__file__))
filepath = filedialog.askopenfilename(filetypes = fTyp, initialdir = iDir)
file_path.set(filepath)
# 固有表現抽出処理
def extract_words_by_entity_label(text, named_entity_label):
nlp = spacy.load('ja_ginza')
text = text.replace("\n", "")
doc = nlp(text)
words_list = [ent.text for ent in doc.ents if ent.label_ == named_entity_label]
return words_list
# 出力処理
def click_export_button():
# 入力されたテキストファイルの相対パスを取得
path = file_path.get()
# 選択された固有表現の種別名を取得
named_entity_label = flg.get()
if path[-4:] == '.txt':
global user_input_text
f = open(path, encoding="utf-8")
user_input_text = f.read()
label_word_list = extract_words_by_entity_label(user_input_text, named_entity_label)
# 指定された固有表現に該当する単語を取得した結果(単語リスト)を、{単語文字列 : 出現回数}の辞書に変換する
count_per_word = collections.Counter(label_word_list)
# 出現回数の多い順番に並べる
freq_per_word_dict = dict(count_per_word.most_common())
#output_list = ["{k} : {v}".format(k=key, v=value) for (key, value) in freq_per_word_dict.items()]
# 単語数を取得する
unique_word_num = len(freq_per_word_dict)
if unique_word_num > 0:
message = "{num}件の{label}が見つかりました。\n\n出現回数順に並べた結果は以下です。\n\n".format(num=unique_word_num, label=named_entity_label)
word_list = list(freq_per_word_dict.keys())
word_freq_list = list(freq_per_word_dict.values())
for i in range(unique_word_num):
tmp = "{rank}番目の単語 : {word}\n出現回数 : {count}\n\n===================\n".format(rank=i+1, word=word_list[i], count=word_freq_list[i])
message += tmp
else:
message = "{num}件の{label}が見つかりました。\n\n".format(num=unique_word_num, label=named_entity_label)
textBox.insert(END, message)
global exracted_entity_word_list
exracted_entity_word_list = word_list
return exracted_entity_word_list
else:
textBox.insert(END, '\nファイルがテキストファイルではありません')
return []
def get_subject_predicate_pair_list(sentence: str, subject_word: str) -> Vector:
T = TypeVar('T', str, None)
c = CaboCha.Parser()
tree = c.parse(sentence)
# 形態素を結合しつつ[{c:文節, to:係り先id}]の形に変換する
chunks = []
text = ""
toChunkId = -1
for i in range(0, tree.size()):
token = tree.token(i)
text = token.surface if token.chunk else (text + token.surface)
toChunkId = token.chunk.link if token.chunk else toChunkId
# 文末かchunk内の最後の要素のタイミングで出力
if i == tree.size() - 1 or tree.token(i+1).chunk:
chunks.append({'c': text, 'to': toChunkId})
# ループの中で出力される「係り元→係り先」文字列をlistに格納
pair_list = []
#
for chunk in chunks:
if chunk['to'] >= 0:
pair_list.append(chunk['c'] + " → " + chunks[chunk['to']]['c'])
output_list = [pair for pair in pair_list if subject_word in pair]
return output_list
def click_export_button2():
# 入力された主語単語の文字列を取得
order_num = int(subject_num.get())-1 #ユーザが1を入力したとき、配列の0番地を指定する。
subject_string = exracted_entity_word_list[order_num]
output_list = get_subject_predicate_pair_list(user_input_text, subject_string)
result = "\n".join(output_list)
message = """
単語:「{subject_word}」を主語に持つ「主語と述語」のペアは、以下が見つかりました。
=========================================================================
{result}
=========================================================================
以上です。
""".format(subject_word=subject_string, result=result)
textBox.insert(END, message)
if __name__ == '__main__':
# ウィンドウを作成
root = tkinter.Tk()
root.title("固有表現計数カウンター") # アプリの名前
root.geometry("730x500") # アプリの画面サイズ
# Frame1の作成
frame1 = ttk.Frame(root, padding=10)
frame1.grid()
# 「ファイル」ラベルの作成
s = StringVar()
s.set('ファイル名:')
label1 = ttk.Label(frame1, textvariable=s)
label1.grid(row=0, column=0)
#テキストボックス1(テキストファイルパス入力欄)の作成
file_path = StringVar()
filepath_entry = ttk.Entry(frame1, textvariable=file_path, width=50)
filepath_entry.grid(row=0, column=1)
# 「」ラベルの作成
t = StringVar()
t.set('着目する「主語」:')
label1 = ttk.Label(frame1, textvariable=t)
label1.grid(row=1, column=0)
#テキストボックス2(「主語述語ペア」の「主語」入力欄)の作成
subject_num = StringVar()
subject_num_entry = ttk.Entry(frame1, textvariable=subject_num, width=50)
subject_num_entry.grid(row=1, column=1)
# ラジオボタンの作成
#共有変数
flg= StringVar()
#ラジオ1
rb1 = ttk.Radiobutton(frame1, text='人名',value="PERSON", variable=flg)
rb1.grid(row=2,column=0)
#ラジオ2
rb2 = ttk.Radiobutton(frame1, text='地名',value="LOC", variable=flg)
rb2.grid(row=2,column=1)
#ラジオ3
rb3 = ttk.Radiobutton(frame1, text='組織名', value="ORG", variable=flg)
rb3.grid(row=2,column=2)
#ラジオ4
rb4 = ttk.Radiobutton(frame1, text='日付',value="DATE", variable=flg)
rb4.grid(row=3,column=0)
#ラジオ5
rb5 = ttk.Radiobutton(frame1, text='イベント名',value="EVENT", variable=flg)
rb5.grid(row=3,column=1)
#ラジオ6
rb6 = ttk.Radiobutton(frame1, text='金額',value="MONEY", variable=flg)
rb6.grid(row=3,column=2)
# Frame2の作成
frame2= ttk.Frame(root, padding=10)
frame2.grid()
# 固有表現単語を抽出した結果を表示させるボタンの作成
export_button = ttk.Button(frame2, text='ファイルから指定した種類の単語を洗い出す', command=click_export_button, width=70)
export_button.grid(row=0, column=0)
# 「主語述語ペア」を抽出した結果を表示させるボタンの作成
export_button2 = ttk.Button(frame2, text='入力した番号の単語を主語に持つ「主語述語ペア」を表示します', command=click_export_button2, width=70)
export_button2.grid(row=1, column=0)
# テキスト出力ボックスの作成
textboxname = StringVar()
textboxname.set('\n\n処理結果 ')
label3 = ttk.Label(frame2, textvariable=textboxname)
label3.grid(row=1, column=0)
textBox = Text(frame2, width=100)
textBox.grid(row=3, column=0)
# ウィンドウを動かす
root.mainloop()
( その他、参考にしたサイト )
(参考1)
from typing import List, TypeVar
T = TypeVar('T', str, None)
def get_subject_predicate_pair_list(subject_word: str) -> List(T):
コンストラクタなど、処理を定義
とすると、
TypeError: Type List cannot be instantiated; use list() instead
になりました。
・ kb84tkhrのブログ 「寄り道:Type Hint」
本記事では、上記のWebページを参考にして、
from typing import List
T = TypeVar('T', str, None)
Vector = List[T]
def get_subject_predicate_pair_list(sentence: str, subject_word: str) -> Vector:
としました。
以下の公式サイトにある__「型エイリアス」__のサンプルコードを参考にしたものです。
・ Python3.9.1rc1 Documentation » Python 標準ライブラリ » 開発ツール »「typing --- 型ヒントのサポート」
Vector = list[float]
def scale(scalar: float, vector: Vector) -> Vector:
return [scalar * num for num in vector]
# typechecks; a list of floats qualifies as a Vector.
new_vector = scale(2.0, [1.0, -4.2, 5.4])
・Python 3.8.6 Documentation » Python 標準ライブラリ » 開発ツール »「typing --- 型ヒントのサポート」には、
以下のように書いてあるのですが。
この型は次のように使えます:
T = TypeVar('T', int, float)
def vec2(x: T, y: T) -> List[T]:
return [x, y]
def keep_positives(vector: Sequence[T]) -> List[T]:
return [item for item in vector if item > 0]
(参考2)
Tkinterで、ボタンが押された時にイベント駆動されるメソッドを定義する際、このメソッドがreturn文で返す「返り値」を、このメソッドの外で受け取ることができませんでした。
ここは、以下のサイトを参考に、メソッドの外で定義した__グローバル変数__を、メソッドの中で__global__を付けて呼び出して、グローバル変数のなかに、必要なデータを格納することで対処しました。
・ 「コマンドで使用される関数からのPython tkinter戻り値」
・ 日曜プログラマーの休日 「関数の中でグローバル変数に代入する」
今後やってみたいこと
- __GUIアプリ__ではなく、Webブラウザアプリ__を、Streamlit__で作ってみたい。
( 参考 )
・ @Nate0928さんのQiita記事 「[簡単爆速]HTMLファイル要らずのStreamlitで数分でWebアプリを作る」
・ @keisuke-otaさんのQiita記事 「Streamlit を用いたデータ分析アプリ制作」
・ @SatoshiTerasakiさんのQiita記事 「Streamlit を使ってデータ可視化ツールを作る」
- 拡張子が「.txt」のテキストファイルだけでなく、__PDFファイルやPowerPointファイル、Wordファイル、Excelファイルも読み込めるように拡張__したい。
( 過去に作成した拙記事 )
・ 「PDF・Word・PowerPoint・Excelファイルからテキスト部分を一括抽出するメソッド」