随時更新中
machinaを使って深層強化学習をやりたいと思います.
強化学習
強化学習は「エージェント」が「環境」と相互作用することで自己学習する仕組みです.
環境はアーケードゲームや囲碁などの解き明かしたい何かです.エージェントはその環境で遊ぶAIです.(語彙力なくてすいません)
私達はこのAIをなるべく賢くするのが目標です.

machina
machinaはDeepXによってリリースされた深層強化学習のライブラリです.
今回はこのmachinaを使ってみたいと思います.

インストール
コマンドラインで以下のコマンドを実行するとmachinaがインストール出来ます.
>> pip install machina-rl
Pytorchが入ってない人はエラーするかもしれません.以下のURLからインストールして下さい.
https://pytorch.org/
必要なライブラリのインポート
使用するライブラリは以下の通りです.特に重要なのが,gymとtorchです.
・OpenAI Gym(gym)はアーケードゲームなどの「環境」を提供しているライブラリです.
・PyTorch(torch)は深層学習のライブラリですが,ここでは「エージェント」の作成に使用します.
import numpy as np
import gym
import torch
import os
import time
全体の流れ
全体の流れとしては,
- 環境を作成(gym)
- ニューラルネットワークを作成(torch)
- エージェントを作成(machina)
- 環境とエージェントをSamplerに登録(machina)
- 学習に必要な諸々を定義(machina)
- 実行と学習(machina)
となります.
1. 環境を作成
OpenAI Gym(gym)を使って環境の作成します.ここでは,Cartpole(状態数:4, 行動数:2)を使います.
自分で環境を作成することもできます.(参考: OpenAI GymでFXのトレーディング環境を構築する[ https://qiita.com/hide-tono/items/bb9691477831e48f0989 ])
# 1. 環境を作成
env_name = 'CartPole-v0' # 実行したい環境
env = gym.make(env_name)
obs = env.reset()
# env.render() # jupyter notebookだと動かない
# time.sleep(5)
ob_space = env.observation_space
ac_space = env.action_space
print('obs:', ob_space)
print('act:', ac_space)
# 出力
# obs: Box(4,) 状態: 1:Cartの位置, 2:Cartの速度, 3:Poleの角度, 4:Poleの角速度
# act: Discrete(2) 行動: 1:左 or 2:右
コメント部分(env.render())をコメント外してもエラーしない人は以下のようなウィンドウが表示されてると思います.
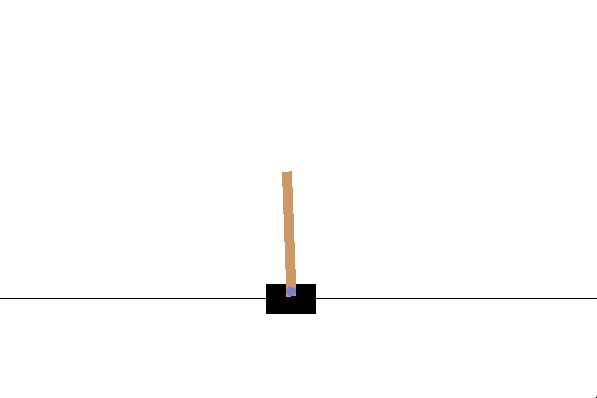
2. ニューラルネットワークを作成
学習器にあたるニューラルネットワークを作成します.machinaでは基本的にPyTorchを使います.
PolNetとVNetを分けて作っていますが,これはPolicyネットワークとValueネットワークです.
- Policyネットワークは,エージェントの出力をニューラルネットワークで関数近似します.ニューラルネットワークは状態を受け取って行動を出力します[状態→行動]. 手法としては方策勾配法とか
- Valueネットワークは,環境を近似します.ニューラルネットワークは状態を受け取って価値(報酬の合計の期待値)を出力します[状態→価値].手法としてはDQNとか
PolicyネットワークとValueネットワークを同時に学習させるのがActor-Criticです.このサンプルコードではActor-Critic法の応用のPPO手法を用いています.
# 2. ニューラルネットワークを作成
import torch
import torch.nn as nn
from torch.nn.init import kaiming_uniform_, uniform_
import torch.nn.functional as F
def mini_weight_init(m): # 重みの初期化
if m.__class__.__name__ == 'Linear':
m.weight.data.copy_(uniform_(m.weight.data, -3e-3, 3e-3))
m.bias.data.fill_(0)
def weight_init(m): # Heによる重みの初期化
if m.__class__.__name__ == 'Linear':
m.weight.data.copy_(kaiming_uniform_(m.weight.data))
m.bias.data.fill_(0)
class PolNet(nn.Module): # Policyネットワークを定義
def __init__(self, ob_space, ac_space, h1=200, h2=100, deterministic=False):
super(PolNet, self).__init__()
self.deterministic = deterministic
if isinstance(ac_space, gym.spaces.Box): # 行動が離散か{連続:Box(MountainCarContinuous-v0), 離散:Discrete}
self.discrete = False
else:
self.discrete = True
if isinstance(ac_space, gym.spaces.MultiDiscrete): # 複数行動ゲームか(「ボタンA+右スティック」など)
self.multi = True
else:
self.multi = False
self.fc1 = nn.Linear(ob_space.shape[0], h1) # 1層目(状態数✖︎200)
self.fc2 = nn.Linear(h1, h2) # 2層目(200✖︎100)
self.fc1.apply(weight_init) # 重みの初期化(kaiming Heの初期化)
self.fc2.apply(weight_init) # 重みの初期化(kaiming Heの初期化)
self.output_layer = nn.Linear(h2, ac_space.n) # 出力層(200✖︎行動数)
self.output_layer.apply(mini_weight_init) # 重みの初期化
def forward(self, ob):
h = F.relu(self.fc1(ob)) # 1層目
h = F.relu(self.fc2(h)) # 2層目
return torch.softmax(self.output_layer(h), dim=-1) # softmaxで一番良い行動を出力
class VNet(nn.Module): ## Valueネットワークを定義
def __init__(self, ob_space, h1=200, h2=100):
super(VNet, self).__init__()
self.fc1 = nn.Linear(ob_space.shape[0], h1)
self.fc2 = nn.Linear(h1, h2)
self.output_layer = nn.Linear(h2, 1)
self.apply(weight_init)
def forward(self, ob):
h = F.relu(self.fc1(ob))
h = F.relu(self.fc2(h))
return self.output_layer(h)
3. エージェントを作成
定義したニューラルネットワークをmachinaの形式にします.
# 3. エージェントを作成
from machina.pols import CategoricalPol
from machina.vfuncs import DeterministicSVfunc
vf_net = VNet(ob_space) # Valueネットワーク(自作しよう☆(ゝω・)v)
vf = DeterministicSVfunc(ob_space, vf_net) # 出力形式の設定とRNNの追加?ができる
pol_net = PolNet(ob_space, ac_space) # policyネットワーク(自作しよう☆(ゝω・)v)
pol = CategoricalPol(ob_space, ac_space, pol_net)
4. 環境とエージェントをSamplerに登録
1と3で作成した環境とエージェントをSamplerに登録します.Samplerではエピソードをマルチプロセスで実行してくれます.
# 4. 環境とエージェントをSamplerに登録
from machina.samplers import EpiSampler
sampler = EpiSampler(env, pol, num_parallel=2, seed=42) # 環境とエージェントを登録(num_parallel:マルチプロセス設定)
# del sampler
5. 学習に必要な諸々を定義
学習用ライブラリ,最適化法,各種パラメータを定義します.
# 5. 学習に必要な諸々を定義
## 5.1 学習用ライブラリ
from machina.traj import epi_functional as ef
from machina.utils import measure
from machina.traj import Traj
from machina.algos import ppo_clip
## 5.2 最適化法を定義
pol_lr = 1e-4
optim_pol = torch.optim.Adam(pol_net.parameters(), pol_lr)
vf_lr = 3e-4
optim_vf = torch.optim.Adam(vf_net.parameters(), vf_lr)
## 5.3 学習とPPOのパラメータ
gamma = 0.995
lam = 1
clip_param = 0.2
epoch_per_iter = 50
batch_size = 64
max_grad_norm = 10
## 5.4 実行用のパラメータ
total_epi = 0 # 現在の実行回数
max_steps_per_iter = 150 # 実行するステップ数(ステップ数が150回になるまで何回もエピソードを繰り返すことに注意)
max_episodes = 100 # 実行するエピソード数
6. 実行と学習
以下のコードで実行することができます.
学習を行なっている箇所は,with measure('train')で囲まれている部分なので,コメントアウトすれば学習しないです.
めっちゃ実行速い.
# 6. 実行と学習
while max_episodes > total_epi:
## 6.1 エピソードを実行
with measure('sample'):
epis = sampler.sample(pol, max_steps=max_steps_per_iter) # obs:状態,acs:?,rews:報酬,pi:行動 max_steps数になるまで何回もエピソードを繰り返す
## エピソード実行終了
##### こっから(コメントアウトすると学習しないで実行できます)
## 6.2 学習(実行したエピソードepisをもとに学習する)
with measure('train'):
traj = Traj() # trajectoryクラスを作成
traj.add_epis(epis) # 実行したエピソードを代入
### 6.2.1 episを使って,報酬や価値などを計算していく
traj = ef.compute_vs(traj, vf) # 価値を計算
traj = ef.compute_rets(traj, gamma) # 割引報酬を計算
traj = ef.compute_advs(traj, gamma, lam) # アドバンテージを計算(遅延報酬を抑制)
traj = ef.centerize_advs(traj)
traj = ef.compute_h_masks(traj)
traj.register_epis()
### 6.2.2 実際ここで学習
result_dict = ppo_clip.train(traj=traj, pol=pol, vf=vf, clip_param=clip_param,
optim_pol=optim_pol, optim_vf=optim_vf,
epoch=epoch_per_iter, batch_size=batch_size,
max_grad_norm=max_grad_norm)
del traj
### ここまで
## 6.3 エピソードでの報酬の計算
rewards = [np.sum(epi['rews']) for epi in epis]
print("epi: {}, reward: {}".format(total_epi, rewards))
total_epi += 1
del sampler
学習結果の確認
以下のコードで学習結果を確認できます.
# # ビデオを撮りたい場合
# from gym import wrappers
# video_path = './video' # 保存するパス
# env = wrappers.Monitor(env, video_path, force=True)
done = False
o = env.reset()
for step in range(500): # 500ステップ実行
if step % 10 == 0: print("step: ", step)
if done:
time.sleep(1)
o = env.reset()
break
ac_real, ac, a_i = pol.deterministic_ac_real(torch.tensor(o, dtype=torch.float)) # ac_real:出力値, ac:Tensor値, a_i:出力情報
ac_real = ac.reshape(pol.ac_space.shape)
next_o, r, done, e_i = env.step(np.array(ac_real)) # next_o:状態, r:報酬, done:終了判定, e_i:その他情報
o = next_o # 状態を更新
# env.render() # 実行結果を見たい人はコメントを外す
# time.sleep(0.01)
env.close()
学習結果の動画は次のようになります.
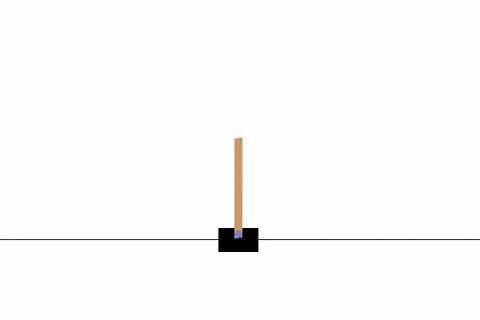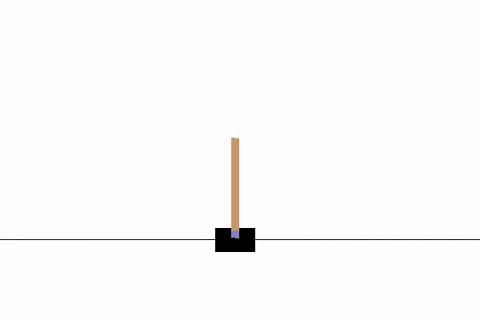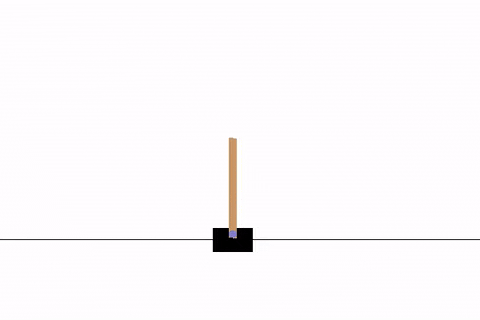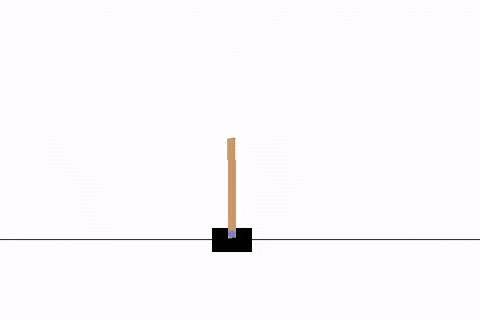
最終的なソースコード
# ライブラリインポート
import numpy as np
import gym
import torch
import os
import time
# 1. 環境を作成
env_name = 'CartPole-v0'
env = gym.make(env_name)
obs = env.reset()
# env.render() # jupyter notebookだと動かない
# time.sleep(5)
ob_space = env.observation_space # 状態数
ac_space = env.action_space # 行動数
print('obs:', ob_space)
print('act:', ac_space)
# 2. ニューラルネットワークを作成
import torch
import torch.nn as nn
from torch.nn.init import kaiming_uniform_, uniform_
import torch.nn.functional as F
import gym
def mini_weight_init(m): # 重みの初期化
if m.__class__.__name__ == 'Linear':
m.weight.data.copy_(uniform_(m.weight.data, -3e-3, 3e-3))
m.bias.data.fill_(0)
def weight_init(m): # Heによる重みの初期化
if m.__class__.__name__ == 'Linear':
m.weight.data.copy_(kaiming_uniform_(m.weight.data))
m.bias.data.fill_(0)
class PolNet(nn.Module): # Policy Networkを定義
def __init__(self, ob_space, ac_space, h1=200, h2=100, deterministic=False):
super(PolNet, self).__init__()
self.deterministic = deterministic
if isinstance(ac_space, gym.spaces.Box): # 行動が離散か{連続:Box(MountainCarContinuous-v0), 離散:Discrete}
self.discrete = False
else:
self.discrete = True
if isinstance(ac_space, gym.spaces.MultiDiscrete): # 複数行動ゲームか(「ボタンA+右スティック」など)
self.multi = True
else:
self.multi = False
self.fc1 = nn.Linear(ob_space.shape[0], h1) # 1層目(状態数✖︎200)
self.fc2 = nn.Linear(h1, h2) # 2層目(200✖︎100)
self.fc1.apply(weight_init) # 重みの初期化(kaiming Heの初期化)
self.fc2.apply(weight_init) # 重みの初期化(kaiming Heの初期化)
self.output_layer = nn.Linear(h2, ac_space.n) # 出力層(200✖︎行動数)
self.output_layer.apply(mini_weight_init) # 重みの初期化
def forward(self, ob):
h = F.relu(self.fc1(ob)) # 1層目
h = F.relu(self.fc2(h)) # 2層目
return torch.softmax(self.output_layer(h), dim=-1) # softmaxで一番良い行動を出力
class VNet(nn.Module): # Value Networkを定義
def __init__(self, ob_space, h1=200, h2=100):
super(VNet, self).__init__()
self.fc1 = nn.Linear(ob_space.shape[0], h1)
self.fc2 = nn.Linear(h1, h2)
self.output_layer = nn.Linear(h2, 1)
self.apply(weight_init)
def forward(self, ob):
h = F.relu(self.fc1(ob))
h = F.relu(self.fc2(h))
return self.output_layer(h)
# 3. エージェントを作成
from machina.pols import CategoricalPol
from machina.vfuncs import DeterministicSVfunc
vf_net = VNet(ob_space) # Valueネットワーク(自作しよう☆(ゝω・)v)
vf = DeterministicSVfunc(ob_space, vf_net) # 出力形式を設定とRNNしてくれる?
pol_net = PolNet(ob_space, ac_space) # policyネットワーク(自作しよう☆(ゝω・)v)
pol = CategoricalPol(ob_space, ac_space, pol_net)
# 4. 環境とエージェントをSamplerに登録
from machina.samplers import EpiSampler
sampler = EpiSampler(env, pol, num_parallel=2, seed=42) # 環境とエージェントを登録(num_parallel:マルチエージェント設定)
# del sampler
# 5. 学習に必要な諸々を定義
## 5.1 学習用ライブラリ
from machina.traj import epi_functional as ef
from machina.utils import measure
from machina.traj import Traj
from machina.algos import ppo_clip
## 5.2 最適化を定義
pol_lr = 1e-4
optim_pol = torch.optim.Adam(pol_net.parameters(), pol_lr)
vf_lr = 3e-4
optim_vf = torch.optim.Adam(vf_net.parameters(), vf_lr)
## 5.3 学習とPPOのパラメータ
gamma = 0.995
lam = 1
clip_param = 0.2
epoch_per_iter = 50
batch_size = 64
max_grad_norm = 10
## 5.4 実行用のパラメータ
total_epi = 0 # 現在の実行回数
max_steps_per_iter = 150 # 実行するステップ数
max_episodes = 100 # 実行するエピソード数
# 6. 実行と学習
while max_episodes > total_epi:
## 6.1 エピソードを実行
with measure('sample'):
epis = sampler.sample(pol, max_steps=max_steps_per_iter) # obs:状態,acs:?,rews:報酬,pi:行動
## エピソード実行終了
### 『こっから(コメントアウトすると学習しないで実行できます)
## 6.2 学習(エピソードepisをもとに学習する)
with measure('train'):
traj = Traj() # trajectoryクラスを作成
traj.add_epis(epis) # 実行したエピソードを代入
### 6.2.1 episを使って,報酬や価値などを計算していく
traj = ef.compute_vs(traj, vf) # 価値を計算
traj = ef.compute_rets(traj, gamma) # 割引報酬を計算
traj = ef.compute_advs(traj, gamma, lam) # アドバンテージを計算(遅延報酬を抑制)
traj = ef.centerize_advs(traj)
traj = ef.compute_h_masks(traj)
traj.register_epis()
### 6.2.2 実際ここで学習
result_dict = ppo_clip.train(traj=traj, pol=pol, vf=vf, clip_param=clip_param,
optim_pol=optim_pol, optim_vf=optim_vf,
epoch=epoch_per_iter, batch_size=batch_size,
max_grad_norm=max_grad_norm)
del traj
### ここまで』
## 6.3 エピソードでの報酬の計算
rewards = [np.sum(epi['rews']) for epi in epis]
print("epi: {}, reward: {}".format(total_epi, rewards))
total_epi += 1
del sampler
# # ビデオを撮りたい場合
# from gym import wrappers
# video_path = './video' # 保存するパス
# env = wrappers.Monitor(env, video_path, force=True)
done = False
o = env.reset()
for step in range(500): # 500ステップ実行
if step % 10 == 0: print("step: ", step)
if done:
time.sleep(1)
o = env.reset()
break
ac_real, ac, a_i = pol.deterministic_ac_real(torch.tensor(o, dtype=torch.float)) # ac_real:出力値, ac:Tensor値, a_i:出力情報
ac_real = ac.reshape(pol.ac_space.shape)
next_o, r, done, e_i = env.step(np.array(ac_real)) # next_o:状態, r:報酬, done:終了判定, e_i:その他情報
o = next_o # 状態を更新
# env.render() # 実行結果を見たい人はコメントを外す
# time.sleep(0.01)
env.close()
まとめ
machinaを実際に動かしてみました.machinaではそれぞれのインスタンスがうまく分割されているため,強化学習やってる人,これからやる人のデファクトスタンダードになるかと思います.
個人的にはPyTorchの使いやすさにも今更ながらびっくりです!
修正や質問どしどしお待ちしております.