SudachiPy という素晴らしい形態素解析を見つけたので普段遣いの PowerShell から呼び出せるようにしてみました。
できあがったもの
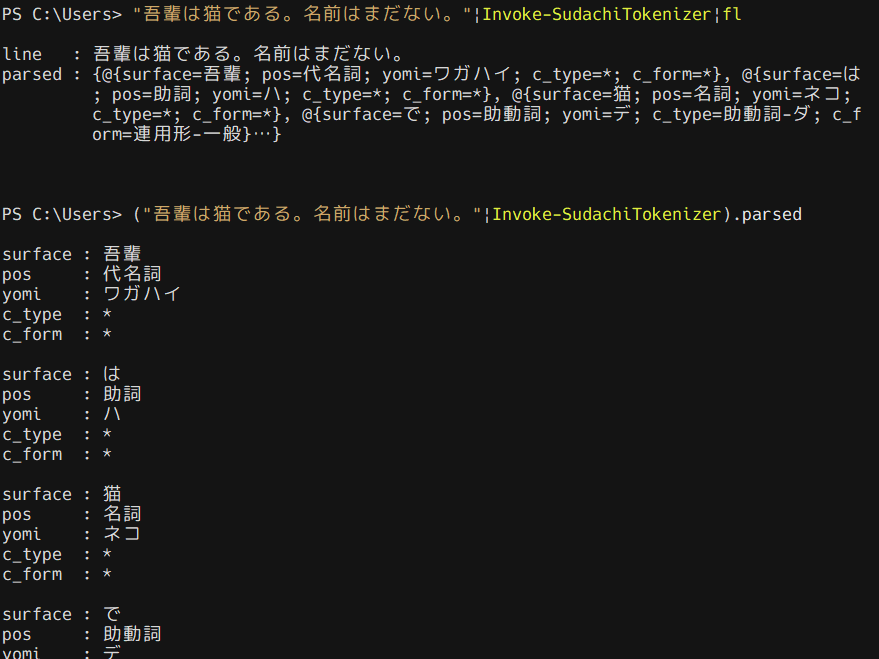
文字列をパイプしてやると、line プロパティに入力した文字列、 parsed プロパティに解析結果を持つオブジェクトを返します。
コード
主な解析処理を Python で書き、 PowerShell から呼び出すという構造です。
文字列の入出力にはコマンドライン引数や print での標準出力を使うのも手ですが、以下のような問題があるので一時ファイルを利用することにします。
- 引数の上限
- 数百行程度が限界?
- 文字列エスケープ
- 引用符やタブ文字が含まれる場合の処理が煩雑。
- 文字コードの問題
- Windows 環境では CP932 で表現できない文字を
printしようとするとUnicodeEncodeErrorが発生してしまう。 - 回避するには該当文字を無視するか
?に置換するしかない。
- Windows 環境では CP932 で表現できない文字を
Python 側での処理
Python は Scoop 経由で入手しておくとパス周りをいい感じに処理してくれて楽です。事前準備として SudachiPy と fire を pip でインストールしておきましょう。
pip install sudachipy
pip install fire
「テキストファイルの内容を行ごとに形態素解析して、その結果を別のテキストファイルに出力する」という処理を関数にまとめて fire.Fire() で cli ツール化します。
sudachi_tokenizer.py
import fire
import re
from sudachipy import tokenizer
from sudachipy import dictionary
def main(input_file_path, output_file_path, ignore_paren = False):
tokenizer_obj = dictionary.Dictionary().create()
mode = tokenizer.Tokenizer.SplitMode.C
with open(input_file_path, "r", encoding="utf-8") as input_file:
all_lines = input_file.read()
lines = all_lines.splitlines()
json_style_list = []
for line in lines:
if not line:
json_style_list.append({"line": "", "parsed": []})
else:
if ignore_paren:
target = re.sub(r"\(.+?\)|\[.+?\]|(.+?)|[.+?]", "", line)
else:
target = line
tokens = tokenizer_obj.tokenize(target, mode)
parsed = []
for t in tokens:
parsed.append({
"surface": t.surface(),
"pos": t.part_of_speech()[0],
"reading": t.reading_form(),
"c_type": t.part_of_speech()[4],
"c_form": t.part_of_speech()[5]
})
json_style_list.append({"line": line, "parsed": parsed})
with open(output_file_path, mode = "w", encoding="utf-8") as output_file:
output_file.write(str(json_style_list))
if __name__ == "__main__":
fire.Fire(main)
業務上、丸パーレン () () やブラケット [] [] の中を飛ばして処理することが多いのでオプションも追加しました。
PowerShell 側の処理
上記の sudachi_tokenizer.py と同じディレクトリに下記の .ps1 ファイルを作成し、 $PROFILE から読み込むことでコンソールからコマンドレットを使えるようになります。
function Invoke-SudachiTokenizer {
param (
[switch]$ignoreParen
)
try {
(Get-Command "sudachipy.exe" -ErrorAction Stop) > $null
}
catch {
Write-Host " 'sudachipy' is not found in this computer!`n install by pip: " -ForegroundColor Magenta -NoNewline
Write-Host "pip install sudachipy"
Write-Host "https://github.com/WorksApplications/SudachiPy" -ForegroundColor White
return
}
$outputTmp = New-TemporaryFile
$inputTmp = New-TemporaryFile
$input | Out-File -Encoding utf8NoBOM -FilePath $inputTmp.FullName
$sudachiPath = "$($PSScriptRoot)\python\sudachi_tokenizer.py"
$command = 'python -B "{0}" "{1}" "{2}"' -f $sudachiPath, $inputTmp.FullName, $outputTmp.FullName
if ($ignoreParen) {
$command += ' --ignore_paren=True'
}
Invoke-Expression -Command $command
$parsed = Get-Content -Path $outputTmp.FullName -Encoding utf8NoBOM
@($inputTmp, $outputTmp) | Remove-Item
return $($parsed | ConvertFrom-Json)
}
Python でリストに辞書型をまとめると json 形式の配列と同形式になるので、 PowerShellの ConvertFrom-Json でオブジェクトに変換しています。