コーディングに最適なLLM:包括的な2024–2025年分析
コーディングに最適なLLM:包括的な2024–2025年分析
複数のコーディングベンチマークとパフォーマンスメトリクスに基づく広範な研究により、この分析では15の主要な大規模言語モデルを評価し、さまざまなユースケースにおける最適なコーディング能力を提供するモデルを特定します。
エグゼクティブサマリー
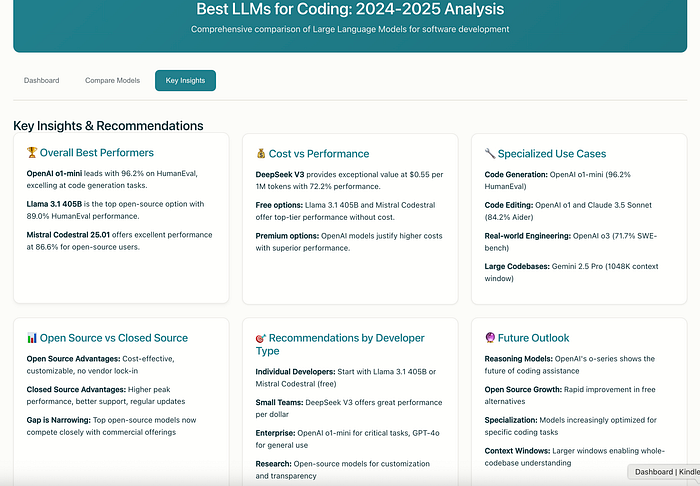
HumanEval、SWE-bench、Aider、CodeForcesのベンチマークでのパフォーマンスを分析した結果、OpenAIのo1-miniが全体的に最も優れたコーディングLLMとして浮上し、HumanEvalで96.2%を達成し、卓越した推論能力を示しました。オープンソースの代替案としては、Llama 3.1 405BがHumanEvalで89.0%のパフォーマンスを記録し、DeepSeek V3は1百万トークンあたり$0.55という最もコスト効率の良いソリューションを提供しています。
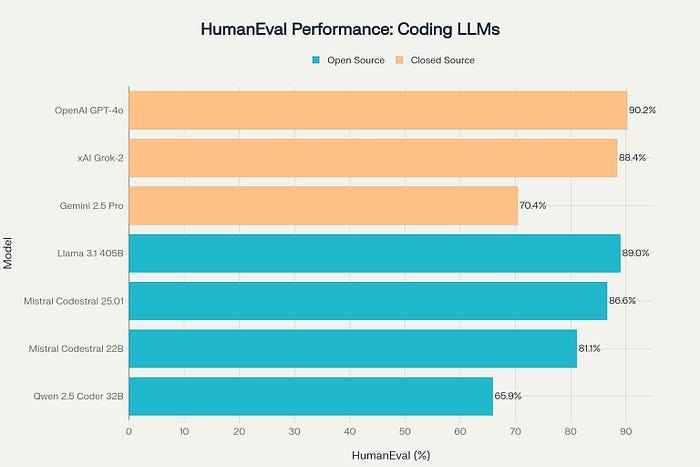
Pythonコード生成タスクにおけるパフォーマンス比較を示すHumanEvalベンチマーク
方法論とベンチマーク
この分析では、コーディングLLMを4つの主要なベンチマークで評価します368:
- HumanEval: 164の手書き問題を用いてPythonコード生成の精度を測定
- SWE-bench: GitHubの課題を使用して実世界のソフトウェアエンジニアリングタスクをテスト
- Aider: 225のコーディング演習にわたるコード編集能力を評価