はじめに
この記事は、AI AcademyのPython文法速習編とPython プログラミング入門編の内容をベースに一部修正を加えたものです。
この記事を読み進めることで、Pythonの基本文法の基礎を学ぶことが出来ます。
Pythonを学び終わった方は、無料(一部のコンテンツのみ有料だが基礎コンテンツはほぼ全て無料)でAI・機械学習が学べるAI Academyも活用ください。
オンライン機械学習スクールはこちら

なぜPythonなのか?
AI Academyでは人工知能(AI)分野を中心とした学習コンテンツを扱っており、その人工知能分野においてPythonは機械学習・ディープラーニングを容易に扱うことができるからです。
また、The 2018 Top Programming Languagesの記事でも、プログラマーの年収は1位でした。
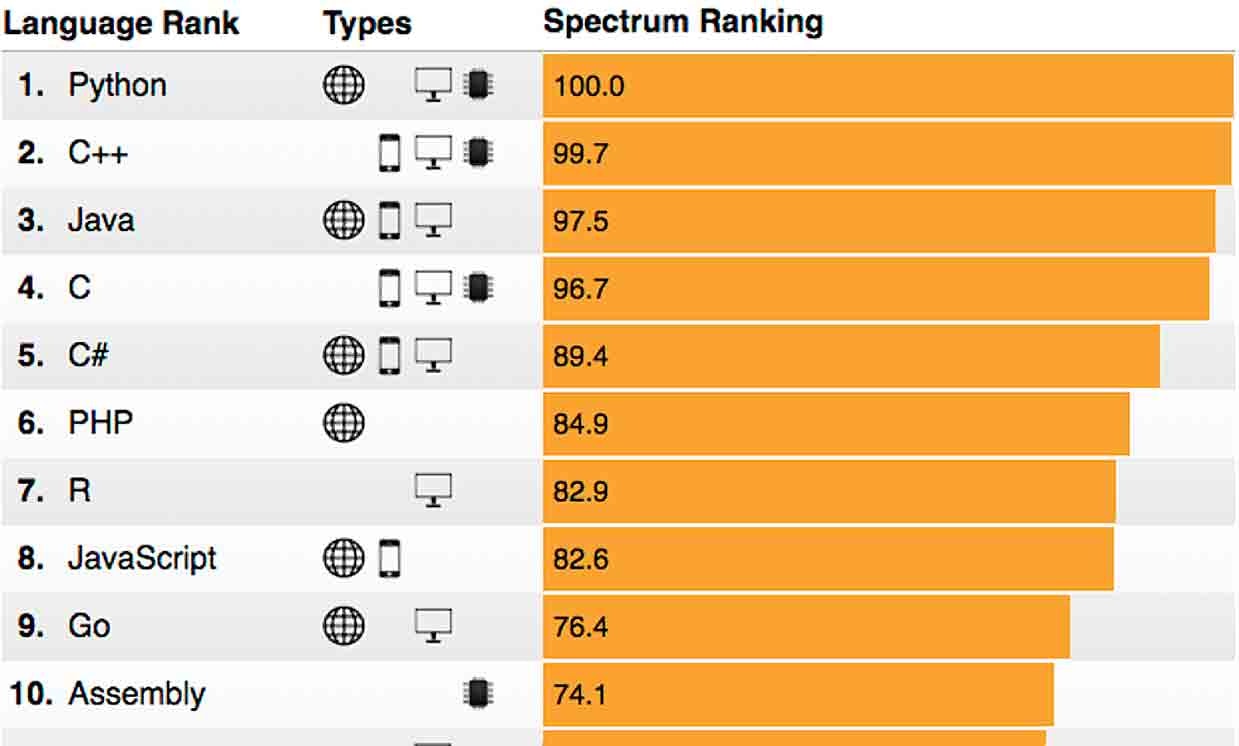
The 2018 Top Programming Languages 画像引用
Pythonは人工知能技術以外にも、Web開発や便利な業務自動化ツールなど幅広く開発することができ、Pythonを習得することで幅広いことを1つの言語で出来るようになります。
さらに、Pythonプログラミング自体が、シンプルで可読性も高く、習得しやすいことから大変オススメです。
是非ともAI AcademyでPythonの基本文法から始まり、Web開発や機械学習まで習得していきましょう!
※このテキストでは、Pythonの文法の必要最低限な内容のみを説明しています。
Pythonのより詳細な文法を学びたい方は、AI Academy Python文法編をご確認ください。
Python環境構築
この章ではPythonの基本文法の速習の解説に重きをおきます。
手っ取り早くプログラムを書きたい場合は、ブラウザでPythonの環境構築なしに、PythonプログラミングができるGoogle Colaboratoryを利用してください。
Google Colaboratoryを使う場合は環境構築は不要です。
また、このテキストではPython3系を扱います。
手元のPCにPythonが動く環境を作る場合は、Python 環境構築テキストを読み進めてください。
プログラミング言語 Pythonとは
プログラミング言語 Pythonとは、1991年にオランダ人のグイド・ヴァン・ロッサム氏によって開発された汎用的なプログラミング言語です。
Pythonの良さとして、少ないコードでシンプルに記述できることが挙げられます。
Pythonでは、GoogleやDropBoxなど世界的に使われている言語です。
Pythonで出来ること
ざっと大きくあげると以下になります。
- 人工知能関連(画像認識・自然言語処理・音声認識 etc..)
- 機械学習・統計解析
- Webアプリケーション・Webサービス開発
- デスクトップアプリ制作(tkinterなど)
- 業務効率化プログラム
- Webスクレイピング
- IoT
- ロボット制御
- ネットワーク・サイバーセキュリティプログラミング
- ゲーム開発
スマートフォンアプリなどは、あまりPythonは向いていないため、記載しておりません。
スマートフォンアプリ(iOSやAndroidアプリ)開発をされる場合は、iOSアプリですとSwift(iOS)、
AndroidアプリですとJavaやKotlin(コトリン)を学ぶ必要があります。
3DやAR・VRアプリケーションの場合は、Unity(C#など)を使う必要があります。
近年では、React NativeというFacebookが開発したモバイルアプリ向けのJavaScriptのフレームワークなどもあります。
上記の内容が気になった方は是非、ご自身で調べてみてください。
(プログラミングを行う上では調べるスキルはとても役に立ちます。)
Python2系と3系の違い
変更点はいくつかありますが、print文がprint()関数に変更されたことや、long型が廃止されint型として扱われたりなどあります。
Python2系は2020年にてサポート終了しますので、これから始める方はPython3系を選ぶのが良いです。
PEP8
PEP8は、Python のコーディング規約になります。
Pythonでプログラミングを始めるにあたって、その都度目を通して頂けたらと思います。
PEP8
コメント
コードの中にはコメントを書くことが出来ます。
行頭に「#」を書くことで行末までコメントとみなされます。
コメントを書くことで、コードが実行される時に全て無視されるので、コードに関するメモなどとして使うことが出来ます。
業務では、複数人でアプリケーションを作ることがほとんどです。
そのため、常日頃から他人がコードを読むときに読みやすいようにコメントを残しておくことは大事です。
なるべく、プログラム内には他人が読みやすいように、コメントを書く習慣をつけることをオススメ致します。
# この行はコメントです。この行は実行されません。
print("Hello, Python")
# この行はコメントです。この行は実行されません。
# この行はコメントです。この行は実行されません。
また、余力がある方は上記のプログラムを実行し、コメントした記述が表示されないことを確認してみてください。
文字列とは
文字列はダブルクォーテーション「"」または、シングルクォーテーション「'」で囲まれた文字は、プログラミングの世界で「文字列」と呼びます。
文字列はシングルクォーテーション「'」、またはダブルクォーテーション「"」で囲む必要があります。
Python3ではどちらで囲んでも出力結果は同じです。
また、文字列を出力する際に、「'」、「"」で囲んでいない場合、コードが動かなくなります。
余力がある方は、エラー(SyntaxErrror)を出して、コードが動かないようにしてみてください。
ここでは、「'」や「"」で囲まない場合にエラーが出て、動かないことを確認していただければより理解出来るかと思います。
・シングルクォーテーション「'」、またはダブルクォーテーション「"」の違い、使い分け
・エラーコード(例えば、SyntaxError)の種類について
数値
プログラミングでは、「数値」を扱うことも出来ます。
文字列と違い、クォーテーションで囲む必要がありません。
数字をクォーテーション及び、ダブルクォーテーションで囲むと文字列になるので注意です。
詳しくは次章、「変数とデータ型」で詳しく説明致します。
また、「+」、「-」、「/」、「%」のような記号を使うことで四則演算ができるようになります。
四則演算が出来るということは、電卓と同様のプログラムを作ることが可能になります。
print(10) # 数値はクォーテーションで囲む必要はありません。
print(10 + 5) # 足している
print(5 - 2) # 引いている
print(10 / 2) # 割っている
print(10 % 5) # あまりを求めている
# 優先順位の変更
# 通常は +と-よりも*や/の方が優先度が高いですが、()で囲むことで優先度を変えることができます。
print((20 - 5) // 3) # 5
では、上記のプログラムを実行してみましょう。
上から順に、
10
15
3
5.0
0
が出力されたことを確認出来れば大丈夫です。
次に、割算の出力結果が小数点という点に関して説明します。
Python2系であれば、例えば、10/2は5となるのに対して、
3系では5.0となります。
これは、2系では切り捨てているのに対して、3系は切り捨てていないためです。
3系で、2系と同じように切り捨てたい場合は、print(10//2)とすると出来ます。
文字列と数値の違い
さて、以下のコードを実行するとどうなるでしょう。
print(10 + 5)
print('10 + 5')
1行目のprint()では、15が出力され、2では10 + 5が出力されたでしょうか?
これは1では数値の足し算の結果がかえってきているのに対して、2では「10 + 5」という文字列になっています。
「'」や「"」で囲うと、文字列と解釈されそのまま「10 + 5」が出力されました。
プログラミングでは、文字列と数値は全く異なるものとして扱われます。
詳しくは次章、「変数とデータ型」で説明します。
ここでは、数字に対してダブルクォーテーション及びシングルクォーテーションで囲むと、文字列として扱われるということを知っていただければ問題ありません。
変数
変数とは値に付ける名札です。
ひとつの値に複数の名前を付けたり(複数の変数からひとつの値を参照)できます。
また、変数は名前を付けて使います。この名前を変数名と言います。
lang = "Python" # 変数langに文字列Pythonを代入
変数の名前(lang)は自由に決める事ができます。
代入という言葉が出てきましたが、代入とは左辺の変数に右辺の値を変数に入れることを意味します。
またPythonは、変数名は大文字と小文字は区別されます。
そして、変数に保持した値は、プログラムが終了するまで値を保持します。
プログラムを終了することでメモリ上のデータも消去されるため、データを残しておきたい場合は、データベースやファイルにして保存する必要があります。
var = "var"
Var = "Var"
print(var) # varと出力される
print(Var) # Varと出力される
# Pythonで変数名をつける際に2単語続ける場合
lowercase_underscore = "lowercase_underscore" # 推奨
lowercaseunderscore = "lowercase_underscore" # 非推奨
hello_world = "Hello, World" # 推奨
helloworld = "Hello, World" # 非推奨
# 上記のように変数名はすべて小文字で2つ以上の単語をつなげる場合は下線(_)を使うようにすることが推奨されています。
# また非推奨の書き方で、変数を定義することもできます。しかしプログラムにはエラーは出ませんが、推奨されている方法を使いましょう。
変数を使わないプログラムと使ったプログラムの比較
変数を使わないプログラムと使ったプログラムを比べてみてください。
ここでは、変数がどれだけ便利なものなのかを知って頂きたいと思います。
まずは、変数を使わない場合のプログラムを見てみましょう。
print(15 + 1)
print(15 - 2)
print(15 * 3)
print(15 / 4)
print(15 % 5)
では15を220に書き換えてください。
もしこの場合、15と書かれた5つのprintの部分を全て220に書き換える必要が出てきます。
5行だけならまだそこまで大変ではありませんが、例えば100行、1000行だとどうでしょうか?
1つ1つ変更していくのはかなり骨の折れる作業になります。
このような時こそ、変数が役立ちます。
もしも最初から変数xというものが定義されていたら、
x = 15というのを、x = 220に書き換えるだけで済みます。
x = 220
print(x + 1)
print(x - 2)
print(x * 3)
print(x / 4)
print(x % 5)
変数を使うことで、先ほどは5行分の修正が必要だったものが、1箇所変えただけで終わります。
変数は便利ですので、是非使っていきましょう。
定数
定数は値が変えられない値です。
変数では値を後から変えられますが、定数は変えられません。
ですが、Pythonには定数を定義する構文がないため、定数的な意図を持って定義する場合には、すべて大文字で変数名を定義することが多いです。
大文字の変数に出会った場合には、値を書き換えないようにしたほうが無難です。
Pythonの定数に関しては、Pythonのコーディング規約PEP8(公式)などにも説明されております。
予約語
関数名や変数名に使用できない単語を予約語と呼びます。
予約語を用いてしまうと、構文エラー(SyntaxError)が起こってしまいます。
Python3系では、おおよそ30個ほどあります。
以下は全てPython3.6系での予約語ですので、それらは変数名などに使用できません。
['False', 'None', 'True', 'and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
全体像
まずはじめに、Pythonにおけるデータ型の全体像を俯瞰しましょう。
この章では、下図の整数型、文字列型、リスト型、辞書型に絞って学びます。
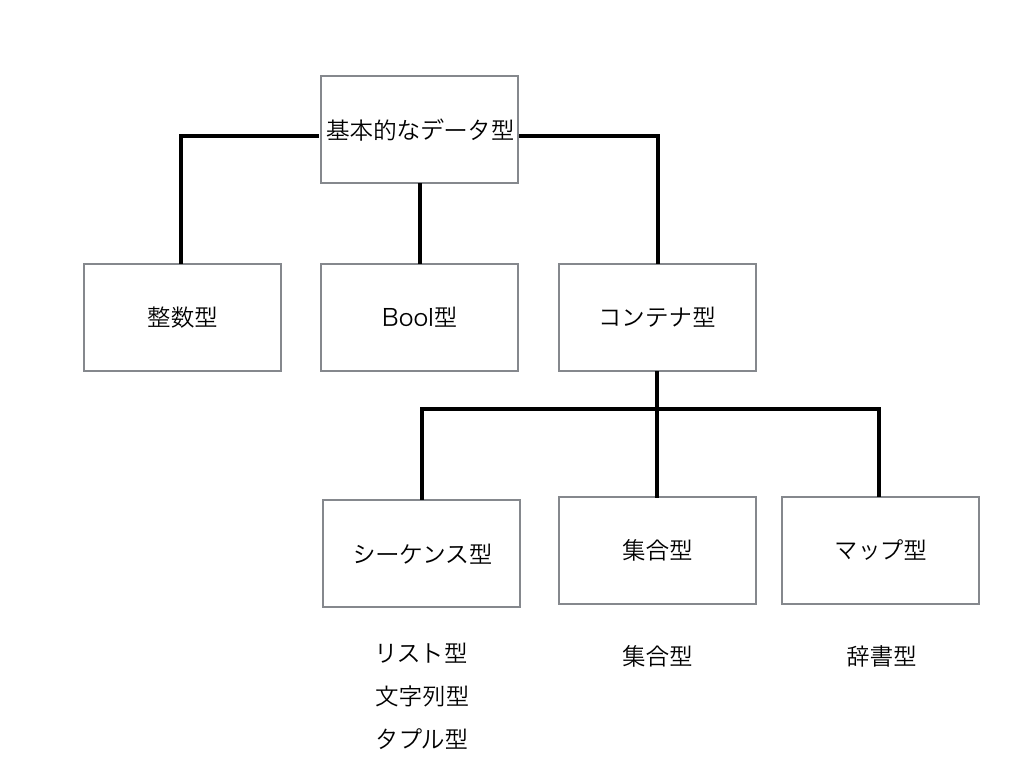
変数と型
プログラミング言語によっては、変数を宣言する際に、「型宣言(この変数にはこの型を格納するよという宣言)」を行う必要がある言語があります。
例えば、他のプログラミング言語(Java言語やC言語など)は型宣言が必要になります。
ですが、Pythonの変数には型宣言が必要ないため、変数にどのような型でも入れることができます。
x = 5
print(x) # 5が出力される。
x = "Python" # 問題なく代入可能。
print(x) # Pythonと出力される。
データ型
これまでに、「文字列」や「数値」という値を見てきました。
これらは「データ型」と呼ばれ、様々な種類があります。
主なものは、整数型、文字列型、辞書型、リスト型です。
数字(数値型)
1)整数(int)
2)小数・実数(float)
3)複素数
の3つあります。
文字列型
ダブルクォーテーション("と")またはシングルクォーテーション('と')で囲うと文字列になります。
次のように、3種類の記述方法があります。
# 1) シングルクオテーション
str1 = 'Hello World'
# 2) ダブルクオテーション
str2 = "Hello World"
# 3) トリプル・ダブルクオテーション
str3 = """Hello World
Hello Python"""
Pythonでは文字列型を定義する上で、ダブルクォーテーション("と")とシングルクォーテーション('と')の明確な使い分けはありませんので、どちらか好きな方を使って文字列型を定義して頂けたらと思います。
x = '1' # 文字列型
さらに、文字列型では+と*の2つを利用することが出来ますが、
+は文字列同士で使う場合、結合という意味になり、複数の文字列を1つの文字列として表現できます。
アスタリスク記号(*)を使うと文字列を反復することが出来ます。
実際にそれぞれ確認して見ましょう。
# 結合
a = "hello " # 結合後、見やすくするために、最後に半角スペースを入れています。
b = "world"
print(a + b) # hello world
次に、*を使う例です。
# 反復
a = "hello"
print(a * 3) # hellohellohello
型変換(キャスト)
下記のプログラムを記述して実際に、実行してみましょう。
print("Hello" + "World") # +により文字列同士を連結
name = "Tom"
print("My name is " + name)
age = 24
# 以下は、データ型の異なる文字列型と数値型を連結してエラーになっているプログラムです。
print("My name is " + name + "My age is " + age) # この行はエラーになります
# TypeError: Can't convert 'int' object to str implicitly
すると、TypeError: Can't convert 'int' object to str implicitlyとエラーがでます。
このように、データ型の異なる文字列型と数値型を連結した場合エラーになってしまいます。
そこで、このエラーを回避するには、数値型を文字列型に変換することで、文字列同士の連結として扱われることになり、連結することができます。
このようにデータ型を変えることを「型変換」または「キャスト」と呼びます。
数値型を文字列型に変換するにはstr()を使います。
name = "Tom"
age = 24
print("My name is " + name + "My age is " + str(age))
# 先ほど、数値型を文字列型に変換しましたが、反対に文字列型を数値型に変換することもできます。
# その場合「int」を用います。
string_price = "1000"
price = 500
total_price = int(string_price) + price
print(total_price) # 1500
リスト型
この節では、リスト型を説明します。
リスト型はデータ型の中でも、かなり大事な型になりますので、しっかりと扱えるようにしましょう。
さて、変数は、1つのデータしか管理できませんでしたが、リスト型は複数のデータ(変数)を管理できます。
他の言語では配列と呼ばれたりします。
Pythonのlistは、格納する型の定義は必要ありません。
複数のデータを管理したい場合にリストを用います。
listは 配列名 = ["x","y","z"] という形式で宣言します。
リストの中身は左から数え始め、最初は1ではなく、0から数えるので注意が必要です。
このリストの中身につけられた番号を添え字(そえじ)やインデックスなどと呼びます。
リストの追加
append()を使うことで、listの末尾に要素を追加することができます。
li = []
li.append("python")
print(li) # ['python']
li.append("php")
print(li) # ['python', 'php']
辞書型
辞書型(ディクショナリー型)はKeyとValueのペアを保持するデータ型です。
次は辞書型の構文になります。
辞書名 = {"キー" : "値", ・・・}
リスト型はインデックス番号が0から始まり0から順に値が格納されていましたが、辞書型は{}を使い囲います。
その点は、辞書型と書き方は似ていますが、辞書型にはインデックス0から値が割り当てられていません。
そのため、リストはインデックス番号で値にアクセスできるのに対し、辞書型では任意のキー文字列で値にアクセスすることができます。
はじめに簡単なプログラムを見てみます。
profile = {"name": "tani", "email": "kazunori-t@cyberbra.in" }
print(profile["name"]) # tani
# 新しく要素を追加
profile["gender"] = "male"
# 新しく要素を追加した辞書型(profile)を出力
print(profile)
オンライン機械学習スクールはこちら

リスト型と辞書型の違い
ここまでリスト型と辞書型を学んできましたが、両者の違いは何でしょうか。
それは要素のアクセスの仕方が異なることです。
リスト型はインデックス(添え字)で要素にアクセスしましたが、辞書型はキー(文字列や数値)で要素にアクセスします。
また、リスト型は[]を使いますが、辞書型は{}を使うという点でも異なります。
リスト型と辞書型の共通するところ
それでは両者が共通する部分はなんでしょうか。
共通する部分はリスト型も辞書型も、異なるデータ型(intやstr)などの要素の格納が可能であるという点です。
また、要素の書き換えが可能です。
制御構造
プログラムは、上から下に順に処理が実行されます。
決められた文法で処理方法を記述します。
この章では、if文やLoop文などを習い、プログラムの流れを制御する方法を学びます。
プログラム処理の流れ
プログラムの基本的な流れは上から下の順に流れていきます。

上の図をPythonのプログラムで記述すると、例えば下記のようになります。
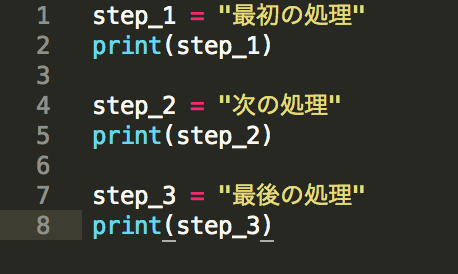
実行すると、次の内容が順に出力されます。
最初の処理
次の処理
最後の処理
つまり、基本的にプログラムは記述した順に上から下へと流れて処理されます。
コードブロックとインデント
Pythonでは、インデント(字下げ)で処理をまとめます。
このインデントはPythonの大きな特徴になります。
基本的には、半角スペース4つ(もしくはタブキー)がインデントの役割になりますが、Pythonの文法では、
末尾にコロン「:」がつく構文が多いです。
(条件分岐文(if, elif, else)、for文、while文、関数、クラスの定義)
末尾に:が出てきたら、インデントをする必要があるというのがPythonの決まりになっています。
例えば、:があるサンプルプログラムとして次を見てください。
この章では、これからif文及びfor文などを説明して行きますので、今の段階では下記のプログラムの意味が理解できなくて構いません。
一旦は:が出てきたらインデントが必要だということを理解してください。
for i in range(10):
if i%2==0:
print("{} is even.".format(i))
else:
print("{} is odd.".format(i))
# 出力結果
# 0 is even.
# 1 is odd.
# 2 is even.
# 3 is odd.
# 4 is even.
# 5 is odd.
# 6 is even.
# 7 is odd.
# 8 is even.
# 9 is odd.
条件分岐 (if文)
プログラミングでは、ある条件に当てはまるかどうかによって処理を分けます。
例えば「テストの点数(条件)によって成績(処理)を変える」というのも条件分岐で表すことが可能です。
構文としては次のようになります。
# 注) このコードは動作しないので注意です。
if 条件A:
条件AがTrueなら実行
elif 条件B:
条件AがFalseかつ条件BがTrueなら実行
else:
条件AもBもFalseなら実行
if文を用いると「もし○○ならば☓☓を行う」という処理を、条件分岐によって表現できますので、例えば、テストの点数がが78点以上であれば、合格と出力するプログラムは次のように記述できます。
# ifの後に条件式を指定し、その条件が成り立つときに実行する処理を次の行に書きます。
score = 80
if score > 78: # 比較演算子 > を使っています。比較演算子はこの後に説明します。
print("合格です")
条件式の作り方
条件式の中では、2つの値を比較するための記号「比較演算子」がよく使われます。
比較演算子には下記の画像のような演算子があります。
右辺と左辺が等しいかどうかを表すには == を使います。
また、右辺と左辺が等しくないかどうかを表すには != を使います。

条件部分は、「if 条件式 :」のように書きます。
行末のコロンをつけ忘れるとエラーになってしまいますので注意が必要です。
score = 80
if score > 78: # 比較演算子 > を使っています。
print("合格です。おめでとう!")
else:
print("不合格。次回頑張りましょう。")
score = 100
if score == 100:
print("満点")
elif score > 85:
print("合格!")
else:
print("不合格。次回頑張りましょう。")
Pythonではコードの字下げ(インデント/半角スペース4つもしくは2つ)がそのままプログラムの動作に影響しますので、字下げ(インデント)に気をつけましょう。
ループ
ほとんどのプログラミング言語で制御構文の基本はループです。
ループは複数回同じコードを実行するための制御構文です。
リストの各要素に同じ処理をしたいときなどに,よく使います。
for文
for文によるループ処理を見ていきます。
for文の書式は次の通りです。
# for ループ内変数 in リスト名:
# 実行する処理
for i in ["apple", "banana", "melon"]:
print(i)
# 出力結果
# apple
# banana
# 3 melon
リストがループ内変数のiに格納され、それが出力(print)されています。
詳しく説明します。
まず、先頭のapple(添え字0番目)という要素が変数iに代入され、print(i)で出力されます。
次に、bananaが取り出され、iに代入、最後のmelonも同様にiに代入され出力されます。
リストの要素を全て取り出したため、このfor文の処理はその時点で終了します。
for文で一定回数の繰り返し処理を行うにはrange()関数を用いることが多いです。
range()関数は次のような役割を持ちます。
range(x): 0からx-1までの連番のリストを返す
range(x,y): xからy-1までの連番のリストを返す
例えば、range()を用いて、0~9までの計10回繰り返すプログラムは次のようになります。
for i in range(10):
print(i)
# 出力結果
# 0
# 1
# 2
# 3
# 4
# 5
# 6
# 7
# 8
# 9
他の繰り返し処理の例も見てみましょう。
少し長いですが、じっくり読んでみてください。
data = [20, 40, 60, 88]
for d in data:
print(d)
# 出力結果
# 20
# 40
# 60
# 88
# (1)
sum_d = 0
for d in data:
# *=で、かけわせることもできます。
sum_d += d # sum_d = sum_d + dを省略した書き方です。
print(sum_d) # 208が出力される。20 + 40 + 60 + 88を足し合わせた数。
# 出力結果
# 208
# for文はelseを使用することができる。
sum_d = 0
# (2)
for d in data:
sum_d += d
# ループが終わったら1回処理したいものが処理できる。
else:
print(sum_d)
# 出力結果
# 208
# Pythonでは、ここで見たfor文、後から見るWhile文のループでelseを使うことが出来ます。
# elseを記述すると、ループが終了するときにelseの中が処理されます。
# 上の(1)と(2)はelseを使っているかどうかの違いですが、出力結果は同じです。
## breakとcontinue
# cotinue 1回スキップ
for i in range(10):
if i == 3:
continue
print(i)
# 出力結果
# 0
# 1
# 2
# 4
# 5
# 6
# 7
# 8
# 9
# break 処理を終了
for i in range(10):
if i == 3:
break
print(i) # 0 1 2を出力
# 出力結果
# 0
# 1
# 2
# 先ほど見たelseをfor文と使う際に、「break」を使うと、elseの中の処理は実行されないので注意が必要です。
# この場合ですと、リスト内に"f"があるので、foundが出力されますが、
3 else内のnot foundは出力されません。
data = [1, 2, 3, 4, 5, "f"]
for x in data:
if x == 'f':
print('found')
break
else:
print('not found') # このサンプルの場合elseの処理は実行されない!
# 出力結果
# found
pythonのforはiterator(イテレータ)と呼ばれる仕組みで、
タプルや、文字列、辞書などもkeyとして使えます。
for char in "hello":
print(char)
# h
# e
# l
# l
# o
リストの要素を順に処理しつつ、インデックス番号も知りたい場合があるかと思います。
その場合、**enumerate()**を使います。
for index, name in enumerate(["apple", "banana", "melon"]):
print(index, name)
# 0 apple
# 1 banana
# 2 melon
またlist()とrange()を組み合わせると、次のような1~100までの要素を持ったリストを簡潔に記述することも出来ます。
print(list(range(101)))
# 出力結果
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100]
辞書型のデータをループする
辞書型のデータをループするには次のように記述します。
data = {"tani": 21, "kazu": 22, "python": 100}
for key, value in data.items():
print("key: {} value: {}".format(key, value))
# key: tani value: 21
# key: kazu value: 22
# key: python value: 100
while文
while文は、特定条件を満たすまでループを繰り返します。
〜の間はずっとループといったイメージで、forほど使う頻度は少ないですが、
明示的に無限ループを行いたい場合は、whileでのループ処理を記述します。
# nが10になるまで繰り返し
n = 0
while n < 10:
print(n)
n += 1 # +1するのを忘れずに。
# 出力結果
# 0
# 1
# 2
# 3
# 4
# 5
# 6
# 7
# 8
# 9
n += 1もしくは、n = n + 1を記述しない場合、無限ループになってしまいます。
無限ループに入ったら、Ctrl + cで終了しましょう。
無限ループにならないように注意が必要です。
無限ループ
ちなみに、故意に無限ループにする場合には、次のように書きます。
# 無限ループですので、下記プログラムを実行する場合は、Ctrl + cで終了してください。
# もしくはターミナル/コマンドプロンプトを強制的に終了して(閉じて)ください。
while True:
print("無限ループ")
オンライン機械学習スクールはこちら
リスト内包表記
リスト内包表記(List Comprehensions)は既存のリストやジェネレータから新しいリストを作るものです。
例えば、以下は1から10までの数値をそれぞれ2乗した数値のリストを作る場合のプログラムを、リスト内包表記で記述したサンプルです。
result = [x**2 for x in range(1,11)]
print(result) # [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
# 通常のループでは次のようになります。
result = []
for i in range(1,11):
result.append(i**2)
print(result) # [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
リスト内包表記は、既存のリストから取り出した要素に対し処理をするだけでなく、条件に応じた場合にだけ新しいリストに追加したい場合にも使えます。
内包表記のメリットは、処理を簡潔に書け、新しいリストなどへの追加メソッドの呼び出しにかかるコストを軽減できます。
その他内包表記
リスト内包表記以外にも、セットと辞書を生成する内包表記もあります。
セットと辞書内包表記の場合、生成する値によっては出力される値の順番が保持されない場合もありますので、利用の際にはご注意ください。
s = {x**2 for x in range(1,6)}
print(s) # {1, 4, 9, 16, 25}
辞書内包表記の書き方は、キーと値をコロン「:」で区切り、
セット内包表記と同様に{}を使います。
d = {x*2:x**2 for x in range(1,11)}
print(d) # {2: 1, 4: 4, 6: 9, 8: 16, 10: 25, 12: 36, 14: 49, 16: 64, 18: 81, 20: 100}
また、tuple内包表記に関してですが、下記のように記述するとgenerator(ジェネレータ)になります。
()で定義すると、タプル内包表記にはなりませんので注意が必要です。
返ってくるのは要素を生成するgeneratorです。
※generatorという言葉の意味は今のところは理解しなくて構いません。
tupleの時はセット型と辞書型とは違いgeneratorが返ってきて、list()でキャストすると内包表記を実現できるというのを知っていれば問題ありません。
tupleにする際には、tuple()でキャストする必要があります。
t = (x for x in range(5))
print(t)
# <generator object <genexpr> at 0x1095c8eb8>
t = tuple([x for x in range(5)])
print(t) # (0, 1, 2, 3, 4)
標準入力
input()を用いることで、ユーザからの入力を受け取ることが可能です。
※Python バージョン2系では、raw_input()でしたが、Python3系では、raw_input()は使えず、input()を使います。
以下のプログラムを実行すると、コンソール(Macの方は、ターミナル、WIndowsの方はコマンドプロンプト)の入力が待ち状態になり、何かをコンソールに入力するとinput()で入力値を受け取ります。
print("名前を入力してください")
name = input()
print("あなたの名前は"+name+"です")
ここで1つ注意ですが、input()を使って受け取った値は、文字列型になります。
数値を入力した場合、文字列型にキャストされてしまいますので、その後の数値処理には気をつけてください。
(一旦int()等でキャストを行ってください。)
以下は無限にユーザが入力した内容を出力するプログラムです。
受け取った値を変数iに代入し、print()でiを出力します。
# Ctr-Cで終了します。
while True:
print("Please Input!")
i = input()
print(i)
関数とは
関数とはあるデータを受け取り、定められた独自の処理を実行し、その結果を返す命令のことです。
関数には2種類あり、1つ目は独自関数、2つ目は標準関数(組み込み関数)です。
独自関数は、プログラマーが変数を作るのと同じように自由に名前と処理を考え、プログラマーが作ることもできます。
関数を組み合わせることで、プログラムを効率的に作ることができます。
標準関数は、Pythonが最初から用意してある関数です。
標準関数は、print()やlen()、input()などを指します。
プログラミングの世界では、自由に関数を定義し、作った関数を何度も呼び出して使うことができるという特徴があります。
この章では主に独自関数の文法に重点を置き、説明します。
関数を使うメリット・デメリット
まず、メリットから説明します。
ここでは大きく2つ紹介します。
1)コードがわかりやすくなる
関数を使うことのメリットとして、まずコードがわかりやすくなります。
各機能をまとめておくことで見やすくなるだけではなく、デバッグ作業も効率良くなります。
2)関数でコードの重複を減らすことができる。
コードの保守性が上がります。
次は、デメリットですが、細かい説明をするといくつかピックアップできますが、
そこまでデメリットというデメリットはあまりあげられません。
ですので、積極的に関数を作って使う習慣を作って頂けるとプログラミングの幅も広がります。
関数の定義
独自関数の説明として、実際に関数を作っていきます。
(※関数を作ることを関数を定義するなどと言います。)
関数を定義するためには、defというキーワードを使います。
# 注) このコードは構文のため動作しませんので注意してください。
def 関数名():
# インデント(字下げ)をしっかりするように!
# 処理
それでは上記基本構文をベースに、hello!と出力するだけの関数hello関数を作って見ましょう。
helloが関数名で、インデントした行からが、hello関数の処理の定義を記述しています。
# インデントは半角スペース4つ分のことです。
# 以下、hello()関数を定義したサンプルです。
def hello():
print("hello!")
関数名は変数名と同様に、「予約語」を使わない限り、好きな名前で定義できます。
先ほどのプログラムでは、hello関数を定義しただけですので、呼び出しはしていません。
関数は定義しただけでは実行されず、実際に呼び出すことで使うことができます。
関数を実行(呼び出す)には次のように**関数名()とすることで呼び出せます。下記の例では、独自関数hello()を定義し、呼び出す(実行する)にはhello()**とします。
# hello関数の定義
def hello():
print("hello!")
# 関数の呼び出し(実行)
hello() # hello! が出力される
関数の定義では、あくまでも関数を定義しただけですので、処理は行われておりません。
実行するには、**関数名()**とある行で呼び出し処理が行われています。
関数名
関数名は、開発者が自由に名前をつけることが出来ますが、いくつか注意点があります。
注意点として関数名を定義する際に、予約語などで関数名をつけないことです。
また、Pythonで関数名を独自で定義する際に2単語以上の関数名にする場合は、以下のように、小文字で下線(_)を挟むスタイルが推奨されています。
def lowercase_underscore:
print("lowercase_underscore")
pass
また、関数は、空のリスト型や、空の辞書型を定義するときのように、中身の処理のない関数を定義することができます。
とりあえず関数を宣言しておいて、関数の処理としては何もしない時は、「pass」を使います。
# 何も処理のないtest関数を定義
def test():
pass
引数
引数とは、関数を呼び出す際に関数に与える値のことです。
大きく2種類に分けることが出来ます。
1) 仮引数(関数の定義側で受け取る値)
2) 実引数(関数の呼び出し側で与える値)
以下、引数を用いた関数のサンプルプログラムです。
def say_hello(name):
print("こんにちは" + str(name) + "さん")
say_hello("山田") # こんにちは山田さん
返り値(戻り値)

関数で処理されたデータを呼び出し元に返します。
後ほど、「引数とreturn」にて詳しく見ていきます。
引数とreturn
先ほど、返り値(戻り値)について説明しましたが、return文を実行すると、関数を終了し呼び出し元に戻ります。
return 【返り値(戻り値)】
引数と返り値(戻り値)がある場合の関数の書式を紹介します。
戻り値を省略した場合は、Noneが返り値(戻り値)となります。
また、関数内で戻り値がないreturnが実行された場合も、戻り値はNoneになります。
# def 関数名(引数):
# 処理
# return 返り値
def adder(a, b):
return a+b
# 関数内部の処理を変数に保持しておきたい時にreturnは便利です。
value = adder(5,10) # 変数valueに15が代入される
# 先ほどのlen()を用いて返り値(戻り値)に関して説明します。
# 変数dataは、1〜5の5つの要素を持ったリストです。
data = [1,2,3,4,5]
# 関数len()を実行することで、リストであるdataの要素5が返り値になります。
# その返り値5が変数valueに代入されます。
value = len(data)
print(value) # 5
上記len()を図にすると以下のような流れになります。

まず変数dataに[1,2,3,4,5]が代入され、リストとして定義されます。
次に、len()関数によってリストであるdataの要素の数を取得します。
その取得した結果がreturnによって返されており、この返された値が返り値になります。その後、返り値5が変数valueに代入されています。
なぜreturnを使うのか
なぜprint()ではなく、returnを使うのかという点がいまいちピンと来ないことがあります。
この節では、多くのプログラミング初心者がつまずきやすい
なぜ関数内で、print()ではなくreturnを使うのかという違いに説明します。
大前提として、print()とreturnは全くの別物なため、しっかり使い分けが出来るようにする必要があります。
まず、2つの違いとしては次の通りです。
returnは値を返すことが目的
print()は値を出力すること目的
つまり、returnを使うということは値を返す必要がある時に使用するということになります。
具体的にreturnを使った正しい例に関して説明します。
では、まず以下のプログラムを見てください。
def adder1(a, b):
print(a+b)
def adder2(a, b):
return a + b
adder1(2, 4)
sum = adder2(2, 4)
print(sum)
このプログラムでは、returnの良さが伝わりにくく、メリットが感じられないと思います。
というのも、adder1のほうが関数の呼び出しが早く出力も関数内部で行うためです。
ですが一般的に使われる関数の使い方の1つに、ある計算結果をreturnで受け取り再度別の関数にその値を渡すといったことを行います。
上記方法ではreturnの良さが伝わりません。
では、イメージとしてreturnの使い方として正しいプログラムを説明しましょう。
以下のサンプルプログラムを読んでください。
def a(a,b):
return a + b
def b(a,b):
return a * b
x = a(2,2) # xに4が代入
y = b(x, x) # 4 * 4
print(y) # 16が出力される
関数bのように前の処理結果xをまた関数bの引数で渡しています。
このように、returnを行うことで計算結果を一旦変数に格納することができ、
さらにその値を別の関数に渡して違う処理に繋げることが出来ます。
また、関数に渡すというのはreturnを使う一例ですが、**関数に渡さないでも返り値(戻り値)に対して更に何かしらの処理を行うことが出来るということがポイントになります。**関数内部で出力(print)するだけであればprint()で出力すれば良いですが、内部にprint関数が無い関数は、処理した結果をreturn(返り値/戻り値)で受け取り、
その値を変数に代入し、また他の関数にその返り値を渡すことで再度別の処理につなげる事が出来るようになります。
前述の通り、returnは値を返すことが目的であるため、関数内部の処理を、関数内部の処理以降のプログラムでも、戻り値として受け取った値を使用することが前提となっています。
returnを利用した関数のサンプル
それでは、関数内部にprint()を使わずreturnを使った関数をサンプルとしてみていきましょう。
def power(x):
return x*x
def absolute(x):
if (x < 0):
return -x
else:
return x
print(power(10)) # 100
print(absolute(-10)) # 10
引数のデフォルト値
関数では、引数を指定しなかった場合に引数を設定できます。
def func(a, b=5):
print(a)
print(b)
func(10,15) # 10と15が出力される
func(3) # 3と5が出力される
ここで、上記プログラムで、b=5となっておりますが、これが引数のデフォルト値です。
引数にはデフォルト値を指定することが出来ます。
この関数は整数値の引数を2つ与えることで、その2つを出力するだけの関数ですが、
もし引数を1つしか渡さなかった場合は、2つ目の値はデフォルト値bが5となっているために、5が出力されます。
さて、下記プログラムに関して考えてみてください。
下記のプログラムを実行すると、['python', 'Python']が最後の関数呼び出しで出力されます。
def sample(arg, arg_list=[]):
arg_list.append(arg)
print(arg_list)
sample('python')
sample('Python')
Q. この関数を実行する際に、毎回引数に渡した要素だけを返すようにしたい。
実際に修正するにはどうすれば良いでしょうか??
A. この場合は、次のように修正する必要があります。
def sample(arg):
arg_list = [] # リストの初期化
arg_list.append(arg)
print(arg_list)
sample('python') # ['python']
sample('Python') # ['Python']
上記は、毎回リストを初期化しています。
その後に、引数で渡されたargを初期化した空のリストにappendしています。
オンライン機械学習スクールはこちら
関数 変数のスコープ
スコープはかなり重要な部分になります。
今後、プログラミングをしていく上で、大事な考えになりますので、しっかり押さえていきましょう。
ポイントは、変数はどこで作成したかによってスコープ(有効範囲)が違ってきます。
まずは、通常の関数の例を見てみましょう。
def add(x1):
x2 = 10 # 関数内で変数を作成(ローカル変数)
result = x1 + x2
print(result)
add(5) # 5 + 10で15が出力
次に、変数のスコープ(有効範囲)に関するプログラムです。
def add(x1):
x2 = 10 # 関数内で変数を作成(ローカル変数)
result = x1 + x2
print(result)
add(5) # 5 + 10で15が出力
print(x2) # ここでエラーが発生
上記のコードを実行すると、NameError: name 'x2' is not definedというエラーが発生します。
これは関数内で定義した変数x2はローカル変数であり、ローカル変数か関数内部だけしか有効ではないため、関数の外側でx2を呼び出すとエラーになってしまいます。
有効な解決手段として関数の外にx2を定義することです。
(※変数のスコープ以外にも、関数内部処理などもわかりやすいよう、修正しています。)
def add(x1,x2):
result = x1 + x2
return result
x1 = 5
x2 = 10
result = add(x1, x2) # 5 + 10で15が出力
print(result)
他にも、globalを利用して関数内でグローバル変数を利用することもできます。
グローバル(global)宣言・グローバル変数
関数内でグローバル変数にアクセスするための宣言です。
ローカル変数(関数定義の内部で定義した関数)とグローバル変数(関数定義の外側で定義した変数)があります。
glb = 0
def func1():
glb = 1
def func2():
global glb
glb = 5
print(glb) # 0が出力される
func1()
print(glb) # 0が出力される
func2()
print(glb) # 5が出力される
もう一つ例題を見てみましょう。
var1 = 'グローバル変数'
def sample():
var2 = 'ローカル変数'
return (var1, var2)
print(sample())
上記の例は、グローバル変数とローカル変数をそれぞれ宣言しています。
次のサンプルは、関数内からグローバル変数を変更するプログラムです。
var1 = 'グローバル'
def sample():
global var1
var1 = 'ローカルに変更されました'
sample() # グローバル変数var1を関数内部で変更
print(var1) # ローカルに変更されました
おみくじアプリを作る前に
お好きなテキストエディタとターミナル(コマンドプロンプト)を元に、自作したモジュールを読み込み利用してみます。
そのため、Jupyter NotebookやGoogle Colabの場合、この章に書かれているプログラムだと動作しないため、次のようにして試して見てください。
また、下記リンクからColab上で動作させる方法もあげていますので確認してみてください。
YouTube動画 / Colabにて動作させる
-
お手元のPCでfortune.pyを作成。
次に、Colabの左メニュー(>を押します)から、目次、コードスニペット、ファイルの3つが表示され、その中のファイルタブを選択する。 -
1で開いたタブから、アップロードを押すと、手元のPCで作成したfortune.pyを選択出来るのでアップロードする。
def get_fortune():
import random # randamではなく、randomなので注意です
results = ['大吉', '吉', '小吉', '凶', '大凶', '末吉']
return random.choice(results)
- その後Colab側で次のプログラムを実行。
import fortune
result = fortune.get_fortune()
print("今日の運勢は...", result)
ライブラリ
ライブラリとは、ある程度まとまった汎用性の高い処理(関数・クラス・その他)を他のプログラムから読み込むことで、使うことが出来るようにしたファイルです。
Python内では基本的にimportできるものをライブラリと呼んだりします。
なお、ライブラリは一般的な呼び名であり、Pythonでは、基本的にライブラリという表記があったら、下記で説明するモジュールのことだと思ってください。
モジュールとパッケージ
モジュールはPythonのコードをまとめたファイルであり、他のプログラムから再利用できるようにしたファイルのことを「モジュール」と言います。
それ単体では動作しませんが、importすることでモジュールが使えるようになります。
パッケージとは__init__.pyと複数のモジュールがディレクトリに集まったものです。
__init__.pyはパッケージディレクトリに置かれ、そのパッケージをインポートした際に実行されます。
モジュールのインポート
import文の単純な使い方は次のようになります。
import 読み込みたいモジュール
読み込みたいモジュールの部分は、他のPythonファイルのファイル名から拡張子の.pyを取り除いたものです。
例えば、sysモジュールを読み込みたい時は次のようにします。
(sysモジュールは、Pythonをインストールした段階で利用できるモジュールの1つです。これを標準モジュールと呼び、他にもosモジュールなど様々あります。)
import sys
複数のモジュールをインポートする場合、「,」でモジュール名を区切ってインポートできます。
import sys, os
例えばmathモジュールのcos関数を利用したい場合は**モジュール名.関数名(引数)**で利用できます。
import math
math.cos(1) # 0.5403023058681398
独自で作成したモジュールをインポートする
今回は運勢プログラム(占いモジュール)を作ります。
まずmainプログラムを作成します。
(ファイル名は自由ですがここではmain.pyとします。)
import fortune
result = fortune.get_fortune()
print("今日の運勢は... ", result)
では次にfortuneモジュールを作っていきます。
下記プログラムをfortune.pyというファイル名で上の作成したmainプログラム(main.py)と同じ場所に保存してください。
def get_fortune():
import random # randamではなく、randomなので注意です
results = ['大吉', '吉', '小吉', '凶', '大凶', '末吉']
return random.choice(results)
それでは、main.pyとfortune.pyを同じフォルダに保存してあると思いますので、作成したmain.pyを実行してみましょう。
実行するには、Macをお使いの方は、ターミナル、Windowsの方はコマンドプロンプトから、保存されたmain.pyを実行します。
python main.py
上記を実行する際に、そのままターミナルを起動して上記のコマンドを実行した場合に、(null): can't open file 'main.py': [Errno 2] No such file or directoryというエラーがでる場合があります。
これは、main.pyというファイルが今いる階層に存在しないためです。
実行する度に、出力結果が変われば問題なく動作しています。
fromとimport
from ファイル名(モジュール名) import *でファイル名の指定なしに呼び出しが可能になります。
from モジュール名 import *
モジュールの関数などを利用する際に、モジュール名.の記述を省略して関数名だけで使用したい場合は以下になります。
from モジュール名 import 関数名, 関数名, ...
上記の構文を元に次のようにプログラムを書くことが出来ます。
from math import cos, sin, tan
cos(1)
先ほど、fortune.pyでrandom.choice(results)と記述しましたが、
fortune.pyはfromを使い以下のように書き換えることができます。
def get_fortune():
from random import choice
results = ['大吉', '吉', '小吉', '凶', '大凶', '末吉']
return choice(results)
また、名前を指定せずにモジュール内のすべてのメンバ(関数、定数、クラスなどのこと)をインポートする場合は、以下のように指定します。
# from モジュール名 import *
from math import *
cos(1)
sin(1)
fortune.pyでrandomをサンプルでimportしているのは関数内ですが、
関数外でもインポートできます。
from random import *
def get_fortune():
results = ['大吉', '吉', '小吉', '凶', '大凶', '末吉']
return choice(results)
print(get_fortune())
sin(1)
別名でのモジュールのインポート
# main.py
import fortune
result = fortune.get_fortune()
print("今日の運勢は... ", result)
import fortuneと記述していましたが、asを用いることで、別名をつけることができます。
以下が別名をつけたサンプルです。
import fortune as ft
result = ft.get_fortune()
print("今日の運勢は... ", result)
別名をつけたことでft.get_fortune()と呼び出すことが出来るようになりました。
必要なものだけをインポートする
*で全てインポートしましたが、必要な部品だけもインポートできます。
from fortune import get_fortune
result = get_fortune()
print("今日の運勢は... ", result)
また別名をつけ、かつget_fortuneだけインポートするサンプルです。
from fortune import get_fortune as gf
result = gf()
print("今日の運勢は... ", result)
ライブラリ・モジュールの場所を調べる
ライブラリの場所は、モジュールの file アトリビュートか path アトリビュートで調べることができます。
例えば次のようにすることで調べられます。
import os
print( os.__file__ ) # /Users/aiacademy/anaconda3/lib/python3.6/os.py
おみくじアプリを実行してみる。
Macの方は、ターミナル、Windowsの方はコマンドプロンプトを起動し、先ほど作成したmain.pyを次のmain.pyがあるフォルダに移動し、実行して見ましょう。
python main.py
実行すると、
今日の運勢は... ○○です。
というように、○○には、ランダムで実行毎に運勢の結果が変わっているのがわかるかと思います。
もしこの章でおみくじアプリが実行できなかった場合は下記テキストをご参考ください。
コマンドプロンプトで動作するおみくじアプリを作ってみよう!
はじめに
Pythonはオブジェクト指向言語と呼ばれております。
この章ではこのオブジェクト指向言語の理解には欠かせない、**『クラス』**の基本に関して説明します。
Pythonに限らず、オブジェクト指向言語には、クラスを使うことが出来ます。
オブジェクト指向は理解がしにくいものですので、
このテキストだけで全てを理解しようとせず、こういうものなんだなという程度の理解で構いませんので、自分のペースで学習を続けてください。
重要な用語
今回この章の中では、以下の10つの重要な用語が登場します。
これらは、Pythonに限らずオブジェクト指向言語(Javaなど)には全て持ち合わせています。
用語の意味がわからなくなったら、1つ1つそれを説明しているセクションに戻り、復習をしてみてください。
1.オブジェクト指向
2.クラス
3.オブジェクト
4.コンストラクタ
5.インスタンス
6.メソッド
7.継承
8.多重継承
9.オーバーライド
10.親クラスと子クラス
オンライン機械学習スクールはこちら
オブジェクト指向
オブジェクト指向とはプログラミングのスタイル・手法のことで、プログラミングパラダイムと呼ばれる1つです。
プログラミングパラダイムには、オブジェクト指向(オブジェクト指向プログラミング)以外にも、関数型プログラミング、手続き型プログラミングがあります。
手続き型プログラミングでは、連続した手続きを記述し、上から下へと流れ、変数などの状態が変化しながらコードを書いていきます。
例えば、手続き型とは次のようなものを言います。
a = 10
b = 20
y = a + b
print(y) # 20
しかし、手続き型プログラミングには、すべてのコードがグローバル変数なため、プログラムが多くなるにつれ様々な問題が出てきます。
例えば、ある関数でグローバル変数を変更し、別で書いた関数でそのグローバル変数を上書きするなどです。
こうすると手続き型プログラミングの場合、次第にプログラムを管理することが困難になってきます。
その問題を解決するきっかけにオブジェクト指向プログラミングが登場しています。
オブジェクト指向は上記の問題を解決するだけでなく、開発の効率や保守性を上げることが出来ます。
オブジェクト指向を活用可能なプログラミング言語は、PythonやJava、C++といった言語が挙げられます。
今回は、Pythonを使いオブジェクト指向の基礎となるクラスから説明していきます。
クラス
以前、intやstrなどのデータ型を見てきましたが、クラスとはデータ構造を作る仕組みで、クラスを使うと新しいデータ型を作ることができます。
よくクラスは、オブジェクトを作る設計書と説明されます。
クラスとインスタンスの関係のイメージ図です。
クラス(データ構造を作る仕組みで設計図)→インスタンス化(たこ焼きを焼く)によりインスタンス(オブジェクト)を作成します。
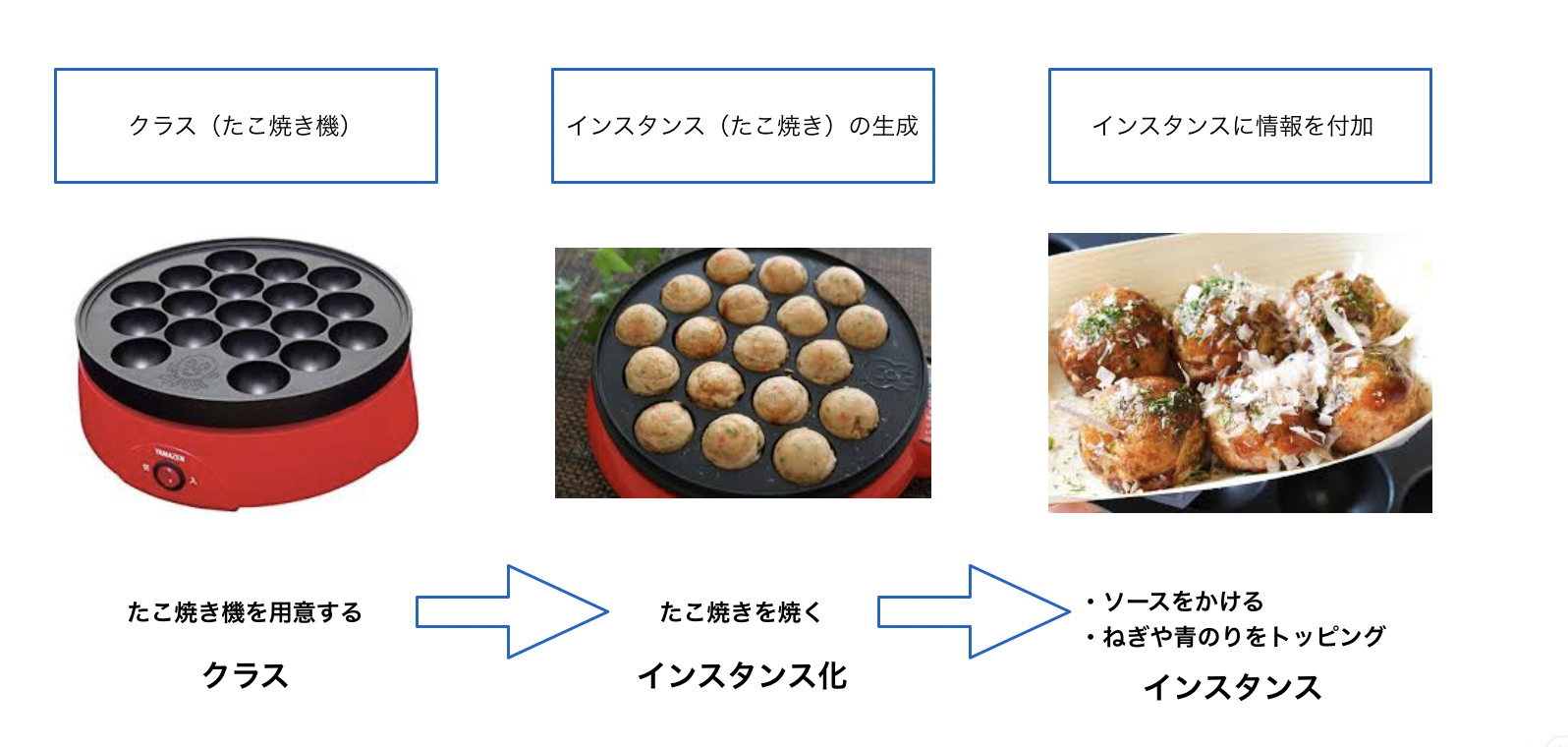
インスタンス化というのはクラスからインスタンス(オブジェクト)を作ることです。
オブジェクトに関して次のセクションにて説明致します。
では早速実際にクラスを作ってみましょう。
# クラスを作るとき,クラス名はCamelCase(キャメルケース)「単語の頭文字を大文字にして接続する書式」で作るようにしてください。
# また、関数やこの章で登場するメソッドの場合は、スネークケース(小文字の単語同士をアンダースコアで繋ぐ形式)を使います。
# (余談 ですが、小文字のみでアンダースコアなしのことをlowerケースと呼びます。)
# Sampleクラスを作ります。(保存するファイル名は任意の名前で可能です。)
class SampleClass: # クラス名の最初の文字は大文字で、また複数の単語の頭文字は大文字にします
# クラス内ではスペースを4つ開けてインデントしてください。クラスの中には変数やメソッド(クラスの中にある関数をメソッド)を定義できます。
'''sample class '''
sample = SampleClass() # インスタンス クラスを使うには、関数の呼び出しのように、クラス名()することでインスタンス化します。こうすることでクラスを使うことができます。sampleにSampleClassのインスタンスが格納されました。クラスからつくられたこのデータをインスタンスと呼びます。
sample.name = "A"
sample2 = SampleClass() # このSample型から、いくつでもデータを作ることができるのでsample2を作りましょう。
sample2.name = "B" # sample2に対してさまざなな属性を作ることができる。
print(sample.name) # sampleの名前はA
print(sample2.name) # sample2の名前はB
空のクラス(中身のないクラス)を作るには次のように書きます。
class SampleClass:
pass # passを使うことで空のクラス(や関数)を作ることが出来ます。
sample = SampleClass()
sample.name = "Sample"
オブジェクト
オブジェクトとはデータ(属性)とメソッド(クラスに定義された関数)を持ったものです。
そして、Pythonの値は全てオブジェクトであり、オブジェクトには実行で出来る関数(メソッド)が定義されています。
初期化メソッド(コンストラクタ)
コンストラクタは対象のクラスのインスタンスを初期化するために利用します。
※Pythonでは、厳密にはコンストラクタではなく、コンストラクタから呼び出される初期化メソッドになります。
インスタンスを作る時に初期値を与えたい時にコンストラクタを使うと便利です。
クラスには**__init__**という特殊なメソッドを書くことができます。
これが初期化を行うメソッドでコンストラクタと呼び、クラスのインスタンスが作成される際に一度だけ呼ばれるメソッドです。
また、クラスが内包するデータを属性と呼びます。
実際に、プログラムを見ていきましょう。
(今回はUserクラスを作っていきます。)
class User:
def __init__(self, name): # インスタンス化されて渡ってくる値を受ける変数を定義します
# インスタンス変数(属性の初期化)
self.name = name
print("コンストラクタが呼ばれました")
def hello(self):
print("Hello " + self.name)
user = User("Sample User") # userというインスタンスを生成しています。
Userクラスのコンストラクタはnameという引数を取り、その引数で変数であるself.name(この変数のことをインスタンス変数と呼びます)を初期化しています。
インスタンス変数は、個々のインスタンスに格納される変数のことです。
ここではnameがインスタンス変数です。
helloメソッド内で、selfの後に属性名を書いていますが、このように書くことで、インスタンス変数の作成及びアクセスができます。
user = User("Sample User")
py = User("python")
user.hello()
py.hello()
メソッド
メソッドとはクラスに定義された関数のことです。
前回、空のSampleClassを定義しましたが、今回はメソッドを持つ、SampleClassを作ります。
class SampleClass:
# メソッド メソッドには1つ目の引数selfを必ずつけてください。selfというのはクラスのインスタンス自身を指しています
def set_name(self, name):
self.name = name # 受け取った値をSampleClasasのインスタンスに格納する必要があります。そのためにself.name = nameとします。self自体がSampleClassのインスタンスをさしますので、nameと言うインスタンス変数を用意して引数nameを代入します。
def hello(self):
print("hello, {0}".format(self.name))
sample = SampleClass()
sample2 = SampleClass()
sample.set_name("Python") # selfは自分自身を示すものなので、nameに当たるPythonだけの引数だけで問題ありません。
sample2.set_name("AI")
sample.hello()
sample2.hello()
継承
継承は既存のクラスをもとに新しいクラスを作る仕組みです。
継承を利用することで既存のクラスの拡張が効率良く行なうことが可能になり、またプログラムの保守性も上がります。
User(親クラス・スーパークラス・基底クラス)-> SuperUser(子クラス・サブクラス・派生クラス)
これから定義する子クラスSuperUserクラスは、親クラスの機能が備わっているため、子クラスを定義する際には新しく追加したい機能だけを定義するだけで済みます。
継承することで既存のクラスを再利用し、新たなクラスを作成することができます。
では実際に見ていきましょう。
class User:
def __init__(self, name):
self.name = name
def hello(self):
print("Hello " + self.name)
class SuperUser(User): # ユーザークラスを継承するには、()の中にUserクラスを書けばoKです。
def __init__(self, name, age):
# super()を使うことで親クラスのメソッドを呼び出すことができます。
super().__init__(name) # こクラスから親クラスのコンストラクタを呼び出す
self.age = age
# メソッドのオーバーライド
def hello(self):
print("SuperHello" + self.name)
# またこクラスのメソッドの中で、例えばオーバライドした
# メソッド内で、super()を使うことで親クラスUserのメソッドを呼び出すこともできます。
super().hello()
t = SuperUser("tani", 100)
t.hello()
多重継承
多重継承とは、複数の親クラスから継承することです。
下記の例では、Base1とBase2の2つが親クラス(基底クラス)でその2つから継承されていることを意味します。
# Pythonは多重継承をサポートしています。
# 複数の基底クラスを持つクラス定義は次のような構文になります。
class SampleClassName(Base1, Base2):
・・・・
・・・・
# 上記のBase1を継承した後にBase2を継承します。
メソッドのオーバライド
メソッドを独自の機能で上書きすることをオーバーライド(over ride)と言います。
下記のDerivedクラス内のsampleメソッドがBaseクラスのsampleメソッドをオーバーライドすることで上書きされています。
今回sampleメソッドのみオーバーライドしましたが、__init()__を含むあらゆるメソッドをオーバーライド出来ます。
# 基底クラス
class Base:
def sample(self):
print("Base.sample()が呼ばれました")
def test(self):
print("Baseクラスtestメソッドが呼ばれました")
# 派生クラス
class Derived(Base):
def sample(self): # Baseクラスのsampleメソッドをオーバーライド
print("Derived.sample()が呼ばれました")
self.test() # Baseクラスのtestメソッドを呼び出し
d = Derived()
d.sample()
元のBaseクラスは、**親クラスもしくはスーパークラス(もしくは基底クラス)**と呼ばれます。
新しくできたDerivedクラスは子クラス、サブクラス、派生クラスなどと呼ばれます。
まとめ
この記事では、Pythonとは何か、Pythonで出来ること、変数とデータ型、if文やfor文、モジュールやクラスなどを学びました。どれも基本的な内容ですので、しっかり押さえましょう。
※この記事では、冒頭で説明した通り、AI AcademyのPython文法速習編とPython プログラミング入門編の内容をベースに一部修正を加えたものです。
オンライン機械学習スクールはこちら