追記:
本記事は g++ について書かれており、clang については補足で述べる程度でしたが、clang側の検証結果が間違っておりました。
別途 clang++ で検証した記事も書きましたので、ご覧いただけますと幸いです。
本記事の目的
昨日、株式会社フィックスターズの「Fixstars Tech Blog /proc/cpuinfo」に以下の記事が掲載されました。
本記事では、上記記事の
- 手元環境における追試
- C++の敗因/Rustの勝因分析
- 条件をある程度統一した際のベンチマーク結果
の3点を行います。
ベンチマーク環境
- OS
- Fedora 30
- CPU
- AMD A6-1450
- Memory
- DDR3-1333 4GB x 1 (4GB)
- GCC
- 9.2.1
- Rustc
- 1.39.0-nightly
ベンチマーク環境は、買ったものの全く使われていないサーバー環境を利用しました。
ベンチマークの追試
ベンチマークのコマンド
ベンチマークの追試は以下のコマンドで行いました。
git clone https://bitbucket.org/LWisteria/conjugategradient.git -b rust fixstar-bench
cd fixstar-bench/src/ConjugateGradient
# libSolveRust の作成
sed -i '1i#![crate_type = "cdylib"]' SolveRust.rs
rustc -C opt-level=3 -C debug_assertions=no SolveRust.rs
# gcc の場合
g++ main.cpp -O3 -L. -lSolveRust
# clang++ の場合(手元環境では何故か -I を指定しないといけないし、一発でリンクまでできない)
clang++ main.cpp -I/usr/include/c++/9/x86_64-redhat-linux/ -O3 -c -o main.o
g++ main.o -lSolveRust -L.
# 今回はコンパイル環境と実行環境が別だったので転送する
scp a.out libSolveRust.so *****:.
# 実行時 (20回連続実行する)
for i in `seq 20`; do LD_LIBRARY_PATH="." ./a.out; done | tee result.txt
また、別途 main.cpp を C++ → Rust → Rust → C++ の順で実行するように改造しています(順番でキャッシュの効きとか変わらないかなぁ程度の配慮です)。
diff --git a/src/ConjugateGradient/main.cpp b/src/ConjugateGradient/main.cpp
index 85f5f72..391fdce 100644
--- a/src/ConjugateGradient/main.cpp
+++ b/src/ConjugateGradient/main.cpp
@@ -231,5 +231,21 @@ int main()
}
#endif
+#ifdef SOLVER_RUST
+ {
+ std::cout << "Rust, ";
+ ConjugateGradient::SolveRust solver;
+ ConjugateGradient::Solver::Solve(problem, solver);
+ }
+#endif
+
+#ifdef SOLVER_SEQUENTIAL_NATIVE
+ {
+ std::cout << "SequentialNative, ";
+ ConjugateGradient::SolveSequentialNative solver;
+ ConjugateGradient::Solver::Solve(problem, solver);
+ }
+#endif
+
return 0;
}
実行結果
./a.out の一回の実行でC++/Rustがそれぞれ2回ずつ実行されるので、計40サンプル結果が得られることになります。
これを、横軸実行回数、縦軸Solve実行時間(ms)でプロットしたものが、以下の図となります。
C++(g++) vs Rust
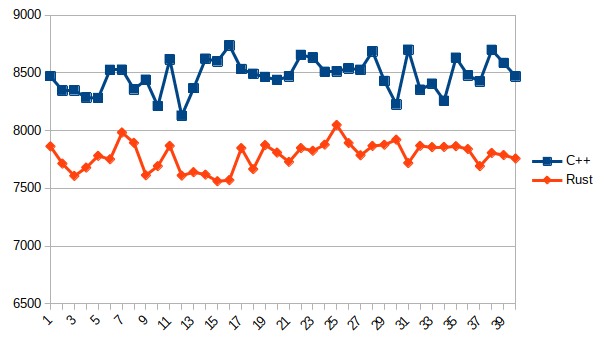
C++ 圧倒的敗北!!!
C++の敗因/Rustの勝因分析
コードレベルで比較してもあまり良くわからないので、アセンブリレベルで比較しました。
rustc -C opt-level=3 -C debug_assertions=no SolveRust.rs --emit asm
で SolveRust.s へRustのコンパイル結果が出力されます。
この出力を眺めていた所、以下のようなコードに気づきました。
.LBB0_57:
movupd (%r15,%rdx,8), %xmm3
movupd 16(%r15,%rdx,8), %xmm4
mulpd %xmm2, %xmm3
mulpd %xmm2, %xmm4
movupd (%rbx,%rdx,8), %xmm5
addpd %xmm3, %xmm5
movupd 16(%rbx,%rdx,8), %xmm3
addpd %xmm4, %xmm3
movupd 32(%rbx,%rdx,8), %xmm4
movupd 48(%rbx,%rdx,8), %xmm6
movupd %xmm5, (%rbx,%rdx,8)
movupd %xmm3, 16(%rbx,%rdx,8)
movupd 32(%r15,%rdx,8), %xmm3
movupd 48(%r15,%rdx,8), %xmm5
mulpd %xmm2, %xmm3
addpd %xmm4, %xmm3
mulpd %xmm2, %xmm5
addpd %xmm6, %xmm5
movupd %xmm3, 32(%rbx,%rdx,8)
movupd %xmm5, 48(%rbx,%rdx,8)
addq $8, %rdx
addq $-2, %rax
jne .LBB0_57
cmpq $0, 16(%rsp)
je .LBB0_60
.LBB0_59:
movupd (%r15,%rdx,8), %xmm3
movupd 16(%r15,%rdx,8), %xmm4
mulpd %xmm2, %xmm3
mulpd %xmm2, %xmm4
movupd (%rbx,%rdx,8), %xmm2
addpd %xmm3, %xmm2
movupd 16(%rbx,%rdx,8), %xmm3
addpd %xmm4, %xmm3
movupd %xmm2, (%rbx,%rdx,8)
movupd %xmm3, 16(%rbx,%rdx,8)
.LBB0_60:
movq 24(%rsp), %rdx
movq %rdx, %rax
cmpq %r14, %rdx
je .LBB0_62
.p2align 4, 0x90
勘が良い方ならお気づきでしょうが、これはSIMD+ループアンローリングがされています。
対応するRustのコードは こちら になります。
ではC++側のアセンブリを見てみましょう。
もっと良い方法があるかもしれませんが、今回は以下のコマンドで出力しました。
g++ main.cpp -O3 -L. -lSolveRust -g
objdump -d -M intel -S a.out | c++filt > main.s
ここで上と同じ部分を見てみると、以下のようになっています。
const auto x_i = x[i];
401dd2: 48 8b 7b 40 mov rdi,QWORD PTR [rbx+0x40]
auto y_i = y[i];
401dd6: 48 8b 43 10 mov rax,QWORD PTR [rbx+0x10]
401dda: 48 8d 57 0f lea rdx,[rdi+0xf]
401dde: 48 29 c2 sub rdx,rax
401de1: 48 83 fa 1e cmp rdx,0x1e
401de5: 0f 86 45 04 00 00 jbe 402230 <void ConjugateGradient::Solver::Solve<ConjugateGradient::SolveSequentialNative>(ConjugateGradient::Problem const&, ConjugateGradient::SolveSequentialNative&)+0xb30>
401deb: 48 83 7c 24 68 01 cmp QWORD PTR [rsp+0x68],0x1
401df1: 0f 86 39 04 00 00 jbe 402230 <void ConjugateGradient::Solver::Solve<ConjugateGradient::SolveSequentialNative>(ConjugateGradient::Problem const&, ConjugateGradient::SolveSequentialNative&)+0xb30>
401df7: 66 0f 28 d6 movapd xmm2,xmm6
401dfb: 31 d2 xor edx,edx
401dfd: 66 0f 14 d2 unpcklpd xmm2,xmm2
401e01: 0f 1f 80 00 00 00 00 nop DWORD PTR [rax+0x0]
y_i += alpha * x_i;
401e08: 66 0f 10 0c 17 movupd xmm1,XMMWORD PTR [rdi+rdx*1]
401e0d: 66 0f 10 3c 10 movupd xmm7,XMMWORD PTR [rax+rdx*1]
401e12: 66 0f 59 ca mulpd xmm1,xmm2
401e16: 66 0f 58 cf addpd xmm1,xmm7
y[i] = y_i;
401e1a: 0f 11 0c 10 movups XMMWORD PTR [rax+rdx*1],xmm1
for(auto i = decltype(n)(0); i < n; i++)
401e1e: 48 83 c2 10 add rdx,0x10
401e22: 48 3b 54 24 20 cmp rdx,QWORD PTR [rsp+0x20]
401e27: 75 df jne 401e08 <void ConjugateGradient::Solver::Solve<ConjugateGradient::SolveSequentialNative>(ConjugateGradient::Problem const&, ConjugateGradient::SolveSequentialNative&)+0x708>
401de5 まではエイリアシングがないかの分岐で、それ以降がSIMDでの処理となっています。
これを見て分かるように、ループアンローリングされていません。
つまり、RustとC++でループアンローリングされているかいないかという、最適化のされ方が違うことがわかりました。
条件をある程度統一した際のベンチマーク結果
では、C++側もループアンローリングをして比較をしましょう。
コンパイル時に-funroll-loopsオプションを付けることによって、最適化がおこなわれます。
他は同条件で計測しプロットした所、以下のようになりました。
実行結果
C++(g++) vs Rust
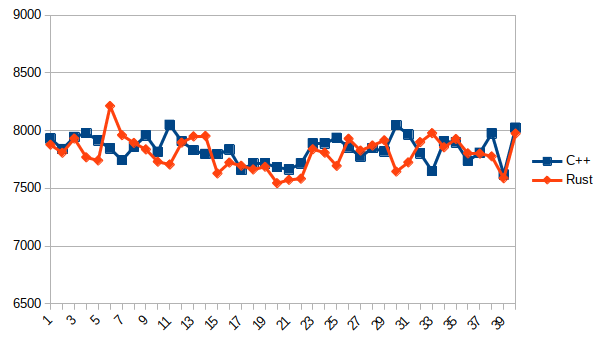
ほぼ差はない!!!
結論
手元環境における差は、ループアンローリングをするか否かの最適化オプションが揃っていなかったことによって発生したまやかしであると思われる。
(ただし、上記記事の差は環境が違いすぎて参考にならない可能性があります。)
(向こうの記事は0.6%の差を語っているのにこっちは10%ぐらいの差を語っている時点で変な気はする、、、。安定して、0.6%未満の誤差で時間を計測する方法を知りたい……)
どうでもいい備考
- clang でもほぼ同一の結果が得られた。
- 始めはメインのデスクトップ機でベンチマークをしており
-march=nativeを付けて比較していたが、付けると逆に遅くなっていたようだった。 - メインのデスクトップ機は冷却が駄目で実行するごとに実行時間が長くなり、全くベンチマークにならなかった。
- Rustはエイリアシングの最適化が効かせれるので、将来的にはC++よりも早くなるような気もする。C++に
restrictキーワードが導入されて欲しい。