こんにちは。
最近、NVIDIA-Certified Associate: Generative AI and LLMs (NCA-GENL)を習得しました。
その際に知っておいた方が良い基礎知識とコードの書き方を共有したいと思います。
生成AIのチュートリアル:
Quantization(量子化)とは?(モデルの運用時に使う)
FP32やFP16をIntに変換し大規模なモデルをより効率的に動かすための技術。
FP32のレンジは±1.18×10^−38 ~ ±3.4×10^38 (±1600万桁)です。
Int8のレンジは-127 ~ 127です。
Int4のレンジは-7 ~ 7です。
Mixed PrecisionはFP32をFP16に変換し、トレーニングに使うのを目的。
QuantizationはFP32やFP16をInt8やInt4に変換し、モデルを軽量化するのが目的。
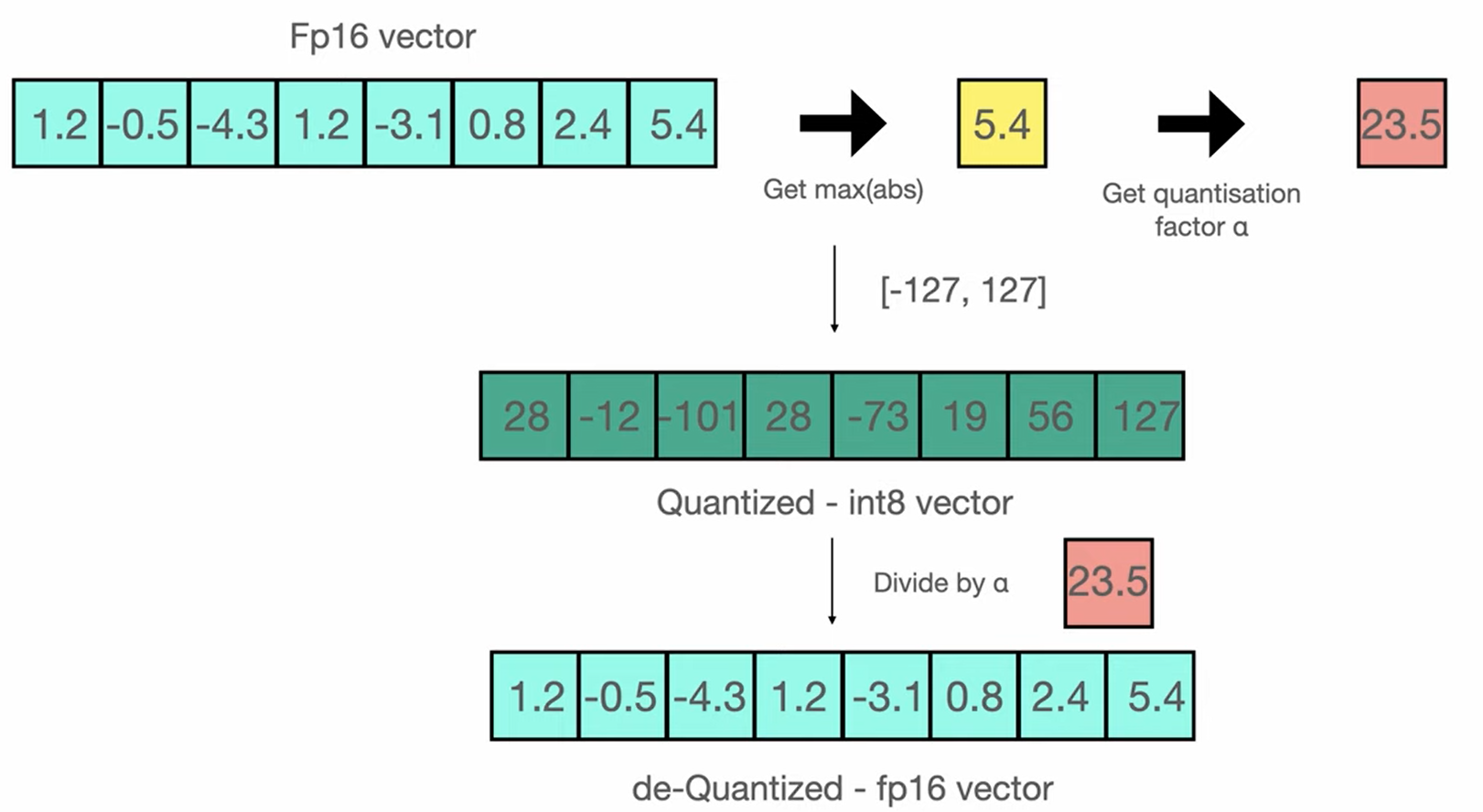
上記の写真から
「1.2、0.5、ー4.3、…」のFP16をー127~127のInt8のバケツに変換。(これにより大体の値になる)
Quantizationファクター = Int8(Max) - Int8(Min) / FP16(Max) - FP16(Min)
Quantizationファクター = 127 - (-101) / 5.4 - (-4.3) = 23.5
その後、Quantizationファクター23.5でInt8のバケツを割れば、元の値FP16に戻る。
(*FP32やFP16はNormal Distributionだけど、QuantizationはNormal Distributionにならないので注意。
ー>FP4を使えばNormal Distributionは確保しやすい)
FP4 All the Way: Fully Quantized Training of LLMs: https://arxiv.org/pdf/2505.19115
QuantizationはFP32やFP16等の元の値をInt8やInt4にマッピングし、モデルを軽量化させている事が分かる。
2.Quantization(量子化)のメリット
- メモリ使用量の削減: モデルを動かすために必要なメモリが大幅に減り、大きなモデルを小さなデバイスで動かせる。(DeepSeekはこの技術を使用)
- 推論速度の向上: 低精度での計算は高速であるため、モデルの応答速度が向上。
3.Quantizationした軽量化したモデルをトレーニングするー>QLoRA
QLoRAはQuantized Low-Rank Adaptationの略。
トレーニングするベースモデルをInt8やInt4にQuantizationし(パラメーターはフリーズさせ)、LoRAのアダプター(FP32やFP16)を入れる。
この際、LoRAのアダプター自身もQuantization可能で、その事をDual Quantizationと呼びます。
パラメーターはフリーズさせる事でバックプロパゲーションをする際は、大量のパラメーターのアップデートは必要なく、アダプターのみをアップデート可能。
HuggingFaceを使ったコード
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
TrainingArguments,
)
import peft
from peft import LoraConfig
from trl import SFTTrainer
hf_auth = 'HF_AUTH_TOKEN' # ここにHuggingFaceのトークンを入れる
model_id = 'elyza/ELYZA-japanese-Llama-2-7b-instruct'
# モデルのQuantization
quantization_config = BitsAndBytesConfig(
load_in_4bit=True, # 4bitのQuantizationの有効化
bnb_4bit_quant_type="nf4", # 4bitのQuantizationのタイプ (fp4 or nf4)
bnb_4bit_compute_dtype=torch.float16, # 4bitのQuantizationのdtype (float16 or bfloat16)
bnb_4bit_use_double_quant=False, # 4bitのDouble-Quantizationの有効化
)
# Quantizationしたモデルのロード
model_config = transformers.AutoConfig.from_pretrained(
model_id,
use_auth_token=hf_auth
)
model = AutoModelForCausalLM.from_pretrained(
model_id,
trust_remote_code=True,
config=model_config,
quantization_config=quantization_config,
device_map='auto',
use_auth_token=hf_auth,
weights_only=True
)
# QuantizationしたモデルをLoRAを使いトレーニング
peft_config = LoraConfig(
r=4, # LoRAアテンションの次元
lora_alpha=16, # LoRAスケーリングのAlphaパラメータ
lora_dropout=0.05, # LoRA レイヤーのドロップアウト確率
bias="none", # LoRAのバイアス種別 ("none","all", "lora_only")
task_type="CAUSAL_LM", # タスク種別
target_modules=["q_proj", "v_proj", "k_proj", "o_proj", "gate_proj", "up_proj", "down_proj", "embed_tokens", "lm_head"],
)
model = peft.get_peft_model(model, peft_config)
eval_steps = 50
save_steps = 400
logging_steps = 400
max_steps = 400
output_dir = './'
trainer = SFTTrainer(
model=model,
train_dataset=train_data,
eval_dataset=val_data,
args=transformers.TrainingArguments(
num_train_epochs=3,
fp16=True, # fp16学習の有効化
bf16=False, # bf16学習の有効化
optim="paged_adamw_32bit", # オプティマイザ
learning_rate=3e-4, # 初学習率
lr_scheduler_type="cosine", # 学習率スケジュール
max_grad_norm=0.3, # 最大法線勾配 (勾配クリッピング)
warmup_ratio=0.03, # 線形ウォームアップのステップ比率 (0から学習率まで)
weight_decay=0.001, # bias/LayerNormウェイトを除く全レイヤーに適用するウェイト減衰
logging_steps=logging_steps, # nステップ毎にログを記録する
eval_strategy="steps",
save_strategy="steps",
max_steps=max_steps, # 学習ステップ数
eval_steps=eval_steps, # nステップ毎にEvalをする
save_steps=save_steps, # nステップ毎にチェックポイントを保存
output_dir=output_dir, # 出力ディレクトリ
report_to="none",
save_total_limit=3,
push_to_hub=False,
auto_find_batch_size=True
),
data_collator=transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False),
)
trainer.train()