画像生成 AI として話題の Stable Diffusion を python から使うための取っ掛かりを説明します。
動作環境
今回は CPU で動かすことを想定しているため特別な GPU は不要です。
- Python 3.10 系
- ディスク 10GB 以上
- メモリ 10GB 以上
仮想環境(WSL 含む)で動かす場合、ディスクやメモリが十分に確保されているか確認してください。
大量のデータをダウンロードするため、固定回線での利用を推奨します。
準備
関連ライブラリの開発速度が早く、バージョンアップによって今まで動いていたものが動かなくなる可能性があります。対策として Python の venv という機能を利用して環境を分離します。
作業用ディレクトリを作成して、そこで venv を実行します。
python -m venv ./virtualenv
virtualenv というディレクトリが作成されるので、その中に生成されたスクリプトを実行することで環境が切り替わります。
virtualenv\Scripts\activate.bat
source virtualenv/bin/activate
必要なライブラリをインストールします。
pip install diffusers transformers accelerate torch scipy safetensors omegaconf
diffusers が Stable Diffusion のモデルを処理します。diffusers 自体は色々な使い方を想定しているため、依存関係として自動でインストールされるのは必要最低限に限られます。そのため Stable Diffusion 関係を動かすのに必要なものを列挙しています。
【参考】記事執筆時点(2023.4.4)でインストールされるバージョン
>pip list
Package Version
---------------------- ---------
accelerate 0.18.0
antlr4-python3-runtime 4.9.3
certifi 2022.12.7
charset-normalizer 3.1.0
colorama 0.4.6
diffusers 0.14.0
filelock 3.10.7
huggingface-hub 0.13.3
idna 3.4
importlib-metadata 6.1.0
Jinja2 3.1.2
MarkupSafe 2.1.2
mpmath 1.3.0
networkx 3.0
numpy 1.24.2
omegaconf 2.3.0
packaging 23.0
Pillow 9.5.0
pip 23.0.1
psutil 5.9.4
PyYAML 6.0
regex 2023.3.23
requests 2.28.2
safetensors 0.3.0
scipy 1.10.1
setuptools 65.5.0
sympy 1.11.1
tokenizers 0.13.2
torch 2.0.0
tqdm 4.65.0
transformers 4.27.4
typing_extensions 4.5.0
urllib3 1.26.15
zipp 3.15.0
以前の pip で発生する問題(24.0 では解消)
pip を実行すると upgrade を促されることがあります。[notice] A new release of pip is available: 23.0.1 -> 23.1
[notice] To update, run: python.exe -m pip install --upgrade pip
Windows の Python 3.10.11 では pip 23.1 が venv との組み合わせで正常に機能しなくなるため、upgrade は保留することをお勧めします。
ERROR: Can not perform a '--user' install. User site-packages are not visible in this virtualenv.
このエラーが出るようになった場合、venv を有効にしたプロンプトを終了してから作業用ディレクトリに作られた virtualenv ディレクトリを削除して、最初からやり直してみてください。
Anything V3.1
いわゆる二次元系のイラストに特化した Anything v3.1 というモデルを試します。
もっと新しいバージョンもありますが、考慮すべき点などが増えるため段階的に導入します。
ダウンロード
モデルのデータをダウンロードします。(約 5GB)
import diffusers
pipe = diffusers.StableDiffusionPipeline.from_pretrained("Linaqruf/anything-v3-1")
from_pretrained の引数で指定するのはモデルのパスです。探索の優先順位は以下の通りです。
- ローカルのパス
- ホームディレクトリのキャッシュ(.cache/huggingface/hub/ 以下)
- Hugging Face(指定したバスの前に https://huggingface.co/ を付加)
1 と 2 になければ 3 からダウンロードして 2 に格納されます。
Hugging Face は GitHub のようにリポジトリを集めたサイトのため、git-lfs を有効にすれば git clone でも取得することは可能です。ただしリポジトリには diffusers からは使わない巨大ファイルも含まれており、単純に clone すると何倍ものディスク容量が必要となるため、diffusers 経由で必要なファイルだけダウンロードするのが無難です。
キャッシュディレクトリは環境変数 HUGGINGFACE_HUB_CACHE により変更できます。
set HUGGINGFACE_HUB_CACHE=D:\.cache\huggingface\hub
テスト
ピザを食べる女の子の絵を生成します。
import diffusers
pipe = diffusers.StableDiffusionPipeline.from_pretrained("Linaqruf/anything-v3-1")
result = pipe(prompt = "girl eating pizza", width = 256, height = 256, num_inference_steps = 10)
result.images[0].save("pizza.png")
所要時間は Ryzen 5 2500U (2GHz) で 1 分程度です。
乱数を使用しているため画像は毎回変わります。いくつか例を示します。



気に入った絵柄が生成されるまで何度も試すことになるため俗にガチャと呼ばれます。
引数
pipe() の引数を説明します。
| 引数 | 説明 |
|---|---|
| prompt | 生成する内容を英語で指示 |
| width | 横サイズ |
| height | 縦サイズ |
| num_inference_steps | 画像を生成するためのループ回数 |
今回は CPU で実行することを想定して画像サイズは小さめの 256×256 を指定しました。512×512 にすれば所要時間は 10 倍以上に増大します。
num_inference_steps が大きければ画像は細部まできれいに仕上がりますが、必要時間が増大します。今回は最低ラインの 10 を指定しました。
シード値
ランダムに生成されると再現性がなくなります。シード値を指定してその値を残しておくことで、再現性を確保します。
diffusers 内部では torch.randn を使用しているため torch.manual_seed で指定するのが簡単です。
import diffusers, torch
pipe = diffusers.StableDiffusionPipeline.from_pretrained("Linaqruf/anything-v3-1")
seed = 12345
torch.manual_seed(seed)
result = pipe(prompt = "girl eating pizza", width = 256, height = 256, num_inference_steps = 10)
result.images[0].save(f"{seed}.png")

連続で生成する例を示します。
import diffusers, torch
pipe = diffusers.StableDiffusionPipeline.from_pretrained("Linaqruf/anything-v3-1")
seeds = torch.randint(0, 2 ** 32, [5]) # 5個
for i, seed in enumerate(seeds):
print(f"{i}: {seed}")
torch.manual_seed(seed)
result = pipe(prompt = "girl eating pizza", width = 256, height = 256, num_inference_steps = 10)
result.images[0].save(f"{seed}.png")
基本的な使い方は以上です。モデルによる違いや考慮すべき点などを説明するため、他のモデルを導入します。
Anything v4.0
Anything v3.1 とは別の作者による v4.0 を試します。名前以外は無関係らしく特性がかなり異なります。
単純に参照先を変えるだけです。後で生成方法を変えて比較するためシード値を指定します。
import diffusers, torch
pipe = diffusers.StableDiffusionPipeline.from_pretrained("xyn-ai/anything-v4.0", allow_pickle=True)
seeds = [12345, 34567, 56789]
steps = 10
prompt = "girl eating pizza"
for i, seed in enumerate(seeds):
print(f"{i}: {seed}")
torch.manual_seed(seed)
result = pipe(prompt = prompt, width = 256, height = 256, num_inference_steps = steps)
result.images[0].save(f"{seed}-{steps}.png")
出力を見ると画像が荒く、真っ黒になっているものもあります。



NSFW
画像が真っ黒になっているのは NSFW によるフィルタリングです。次のようなメッセージが表示されています。
Potential NSFW content was detected in one or more images. A black image will be returned instead.
Try again with a different prompt and/or seed.
NSFW についての説明を引用します。
NSFWは、Not safe for work(ノット・セーフ・フォー・ワーク)の頭字語で、職場や学校などのフォーマルな環境下での閲覧に注意を促すため、裸、ポルノグラフィ、卑語、暴力などの要素を含む動画やウェブサイトのURLやハイパーリンクを示す際に使われるインターネットスラング[1][2]。NSFWは、性的コンテンツへのアクセスを禁止している職場や学校内で、個人的にインターネットを使う人物に特に関係がある[3]。
この NSFW によるフィルタリングは safety_checker と呼ばれ、モデルのトップディレクトリにある model_index.json で指定されます。
"requires_safety_checker": true,
"safety_checker": [
"stable_diffusion",
"StableDiffusionSafetyChecker"
],
v3.1 では null が指定されて無効になっています。
"requires_safety_checker": null,
"safety_checker": [
null,
null
],
先ほどの画像はピザを食べているだけで特に危険な情報は含まないため誤判定です。安全側に倒しているため誤判定はよくあります。
誤判定されると生成時間がもったいないので safety_checker を無効化します。model_index.json を書き換えるのは避け、コードで対処します。pipe = ... の次の行に以下を追加します。
pipe.safety_checker = None
古い diffusers での方法
pipe.safety_checker = lambda images, **kwargs: (images, [False] * len(images))
黒塗りされた画像が確認できました。



作画が完全に崩壊していますが、対策を述べます。
ステップ数
画質が見るに堪えないためステップ数を上げて再生成します。このように同じ画像を調整するためにもシード値を控えておくことは重要です。
steps = 35
画質は改善しましたがまだ微妙です。しかも所要時間が 5 倍以上に膨れ上がってしまいました。



女の子はこういう画風だと言われればそうかとも思いますが、ピザが異様です。
スケジューラ―
Stable Diffusion は拡散モデルと呼ばれる方法で画像を生成します。計算のためのアルゴリズムには様々な種類があり、diffusers ではスケジューラーとして実装されています。サンプラー (sampler)という呼び方もあります。
Anything v4.0 で必要ステップ数が増えたのは model_index.json で指定されるデフォルトのスケジューラーが異なるためです。
"scheduler": [
"diffusers",
"DDIMScheduler"
],
"scheduler": [
"diffusers",
"PNDMScheduler"
],
v3.1 と同じ DDIM スケジューラーを使うには pipe = ... の次の行に以下を追加します。
pipe.scheduler = diffusers.DDIMScheduler.from_config(pipe.scheduler.config)
DDIM スケジューラーに変更してステップ数 10 で生成した画像です。



先ほどのステップ数 35 の画像と比較すると、ピザが改善されています。1 番目の画像は別人になっていますが(目が病んでいるのが気になります)、2 番目と 3 番目は面影があります。このようにスケジューラーを変更すると、画質だけでなく絵柄にも影響があります。
ネガティブプロンプト
画像に含めて欲しい要素をプロンプトで指定するのに対して、含めて欲しくない要素を指定するためのネガティブプロンプトがあります。ほとんどおまじないにしか見えないのに効果がある例を示します。
import diffusers, torch
pipe = diffusers.StableDiffusionPipeline.from_pretrained("xyn-ai/anything-v4.0", allow_pickle=True)
pipe.scheduler = diffusers.DDIMScheduler.from_config(pipe.scheduler.config)
pipe.safety_checker = None
seeds = [12345, 34567, 56789]
steps = 10
prompt = "girl eating pizza"
negative_prompt = "EasyNegative, badhandv4"
for i, seed in enumerate(seeds):
print(f"{i}: {seed}")
torch.manual_seed(seed)
result = pipe(prompt = prompt, negative_prompt = negative_prompt,
width = 256, height = 256, num_inference_steps = steps)
result.images[0].save(f"{seed}-{steps}-ddim-neg.png")



画像ごとに画風がバラバラだったのが似たような雰囲気になっています。どの女の子も完全な別人ではなく面影があります。ピザもボリュームアップしています。
ここではただ指定するだけで一定の効果が出ていますが、本来 EasyNegative は別途ファイルを組み込んで使用するものです。
pipe.load_textual_inversion(
"sayakpaul/EasyNegative-test",
weight_name="EasyNegative.safetensors", token="EasyNegative")
Anything V5
v3.1 の元となった v3.0 と同じ作者によるものです。
配布方法が今までのものとは異なり、右上の Download から safetensors ファイルをダウンロードします。モデルを 1 つのファイルにまとめた形式です。最近のモデルはこの形式で配布されることが増えています。
StableDiffusionPipeline.from_single_file でファイル名を指定して読み込みます。
import diffusers
pipe = diffusers.StableDiffusionPipeline.from_single_file(
"anythingV3V5Anything_anythingV5PrtRE.safetensors")
古いバージョンでの方法
download_from_original_stable_diffusion_ckpt でファイル名を指定して読み込みます。
from diffusers.pipelines.stable_diffusion.convert_from_ckpt import download_from_original_stable_diffusion_ckpt
pipe = download_from_original_stable_diffusion_ckpt(
"anythingV3V5Anything_anythingV5PrtRE.safetensors", from_safetensors=True)
古い diffusers では関数名が load_pipeline_from_original_stable_diffusion_ckpt でした。diffusers-0.17 で download_from_original_stable_diffusion_ckpt に変更されました。diffusers-0.30.3 では、その関数は存在しません。
実行すると大量の警告が表示されますが、とりあえず無視しても動きます。また、追加で必要なファイルがダウンロードされます。(約 2.7GB)
読み込み以外は今までと同じです。
import diffusers, torch
pipe = diffusers.StableDiffusionPipeline.from_single_file(
"anythingV3V5Anything_anythingV5PrtRE.safetensors")
pipe.scheduler = diffusers.DDIMScheduler.from_config(pipe.scheduler.config)
pipe.safety_checker = None
seeds = [12345, 34567, 56789]
steps = 10
prompt = "girl eating pizza"
negative_prompt = ""
for i, seed in enumerate(seeds):
print(f"{i}: {seed}")
torch.manual_seed(seed)
result = pipe(prompt = prompt, negative_prompt = negative_prompt,
width = 256, height = 256, num_inference_steps = steps)
result.images[0].save(f"{seed}-{steps}-ddim.png")



Anything v3.1 や v4.0 で同じシード値から生成した画像に類似しています。
ベースとなるモデルが Stable Diffusion 1.5 で共通するためだと思われます。
変換
safetensors ファイルを読み込んでから、従来のディレクトリ構成にダンプすることが可能です。
import diffusers, torch
pipe = diffusers.StableDiffusionPipeline.from_single_file(
"anythingV3V5Anything_anythingV5PrtRE.safetensors",
torch_dtype = torch.float16)
pipe.save_pretrained("./anythingV5PrtRE", safe_serialization=True)
データ量を削減するため、torch.float16 を指定しています。
ダンプ先のディレクトリは今まで通り from_pretrained で読み込めます。新形式の safetensors で出力したため allow_pickle=True は不要となります。
import diffusers
pipe = diffusers.StableDiffusionPipeline.from_pretrained("./anythingV5PrtRE")
こうすれば警告が減って読み込みも高速化するため、あらかじめ変換しておくことを推奨します。
その他のモデル
モデルをダウンロードして試すのに最低限必要な事項は説明しました。これで面白そうなモデルを探して試すことができます。
二次元系のモデルは Anything 以外にもたくさん公開されています。
私が試した中で特徴的だと感じたモデルを 2 つ紹介します。
これまでの例と同じ設定で生成した画像を添えます。
pipe.scheduler = diffusers.DDIMScheduler.from_config(pipe.scheduler.config)
pipe.safety_checker = None
seeds = [12345, 34567, 56789]
steps = 10
prompt = "girl eating pizza"
negative_prompt = "EasyNegative, badhandv4"
for i, seed in enumerate(seeds):
print(f"{i}: {seed}")
torch.manual_seed(seed)
result = pipe(prompt = prompt, negative_prompt = negative_prompt,
width = 256, height = 256, num_inference_steps = steps)
result.images[0].save(f"{seed}-{steps}-ddim.png")
Counterfeit-V2.5
サンプル画像の美しさが話題になりました。キャラクターだけでなく背景にも力が入っています。



ピザがかなりリアルです。3 枚目はナンみたいですが。
Ambientmix
アニメ塗りを追求したモデルです。サンプルも豊富です。



スケジューラー一覧
利用可能なスケジューラーは pipe.scheduler.compatibles で取得できます。名前でソートして表示するコードです。
import diffusers
pipe = diffusers.StableDiffusionPipeline.from_pretrained("Linaqruf/anything-v3-1")
for sch in sorted(map(lambda c: c.__name__, pipe.scheduler.compatibles)):
print(sch)
実行結果は diffusers のバージョンによって異なります。0.14.0 での結果を示します。
DDIMScheduler
DDPMScheduler
DEISMultistepScheduler
DPMSolverMultistepScheduler
DPMSolverSinglestepScheduler
EulerAncestralDiscreteScheduler
EulerDiscreteScheduler
HeunDiscreteScheduler
KDPM2AncestralDiscreteScheduler
KDPM2DiscreteScheduler
LMSDiscreteScheduler
PNDMScheduler
UniPCMultistepScheduler
それぞれに特徴があり、画質だけでなく絵柄も変化します。同じパラメーターで画像を生成して比較します。
from PIL import Image, ImageDraw, ImageFont
font = ImageFont.load_default()
def font_image(t):
_, _, tw, th = font.getbbox(t)
image = Image.new("RGB", (tw, th), "white")
ImageDraw.Draw(image).text((0, 0), t, fill="black")
return image.resize((tw * 6 // 5, th * 3 // 2), Image.LANCZOS)
import diffusers, torch
pipe = diffusers.StableDiffusionPipeline.from_pretrained("Linaqruf/anything-v3-1")
seed = 12345
steps = 10
prompt = "girl eating pizza"
schs = [(sch.__name__, sch.from_config(pipe.scheduler.config)) for sch in pipe.scheduler.compatibles]
for i, (name, sch) in enumerate(schs):
pipe.scheduler = sch
print(f"[{i + 1}/{len(schs)}] {name}")
torch.manual_seed(seed)
result = pipe(prompt = prompt, width = 256, height = 256, num_inference_steps = steps)
image1 = result.images[0]
image1.save(f"schs-{name}.png")
# 記事用にキャプションを入れた画像も生成
image2 = font_image(name)
image3 = Image.new("RGB", (256, 256 + 22), "white")
image3.paste(image1, (0, 0))
image3.paste(image2, ((256 - image2.width) // 2, 258))
image3.save(f"schs-text-{name}.jpg")













1 種類の画像だけでは判断するのに不十分ですが、それでも大まかな傾向は分かるので簡単にまとめます。名前から共通する -Scheduler を省略します。
| 特徴 | スケジューラー |
|---|---|
| 良好な仕上がり | DDIM, DDPM, DEISMultistep, DPMSolverMultistep, EulerAncestralDiscrete, EulerDiscrete, UniPCMultistep |
| ステップ数不足 | KDPM2AncestralDiscrete, KDPM2Discrete, LMSDiscrete, PNDM |
| 絵柄の傾向が類似 | DEISMultistep, DPMSolverMultistep, DPMSolverSinglestep, EulerDiscrete, HeunDiscrete, KDPM2Discrete, LMSDiscrete, PNDM, UniPCMultistep |
ステップ数不足のものに関しては、もともとステップ数を大きく取ることで画質を上げる設計になっています。そういったスケジューラーではステップ数 50 くらいは必要なようです。
ステップ数 10 を指定したとき LMSDiscreteScheduler を 1 とした所要時間の比率を示します。
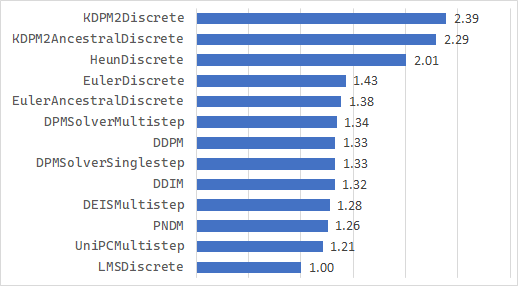
小さい画像を素早く生成するという観点では以下の 4 つを推奨します。似た画像を複数生成してもあまり意味がないため、異なった画像を生成する傾向が強い組み合わせを選びました。
- DDIMScheduler
- DDPMScheduler
- EulerAncestralDiscreteScheduler
- UniPCMultistepScheduler
diffusers 以外の処理系では DPM++ 2M Karras が人気のようですが、diffusers での実装も進んでいるようです。
おわりに
diffusers の基本的な使い方は以上です。
もっと詳しく知りたい方は、以下の記事がお勧めです。
参考
ピザを食べる女の子のプロンプトはこちらのツイートに触発されました。
Ambientmix はこちらのツイートで知りました。
私は AMD ユーザーのため、最初の目標は徒労日記さんのコードを動かすことでした。すんなりとはいきませんでしたが、試行錯誤の過程で得たノウハウのうち GPU に関係しない部分をまとめたのが今回の記事です。
venv でライブラリのバージョンを固定化するやり方は DLL HELL を彷彿とさせます。
スケジューラー関係で参考にした記事です。