目的
- ローカルサーバに構築したK3sにn8nと軽量なローカルLLMをインストールします。
- n8nとLLMを連携させ、チャットの応答を確認します。
前提条件
以下の環境が構築済であることを前提とします。細かい手順については割愛します。
- OS: Ubuntu Server 24.02 LTS
- K3s: v1.33.3+K3s1
kubectl get pods -n test
No resources found in test namespace.
- Helm: v3.18.6
helm version
version.BuildInfo{Version:"v3.18.6", GitCommit:"b76a950f6835474e0906b96c9ec68a2eff3a6430", GitTreeState:"clean", GoVersion:"go1.24.6"}
- Traefik: K3s built-inのTraefikが有効化済み
- Let's Encrypt: Traefik経由でLet's Encrypt証明書の取得が設定済み
- Persistent Volume: LLMモデルの保存用
手順
- n8nのインストールと設定
- ローカルLLMのデプロイ
- n8nとローカルLLMを連携するパイプラインの作成
- 動作検証
1. n8nのインストール
n8sをHelmチャートを使用してインストールします。
1.1 Helmリポジトリの追加
helm repo add community-charts https://community-charts.github.io/helm-charts
helm repo update
1.2 Valuesファイルの取得と編集
n8nをqueueモードで動作させるため、デフォルトのvaluesファイルを取得し、必要な設定を変更します。
helm show values community-charts/n8n > n8n-values-queue-mode.yaml
取得したn8n-values-queue-mode.yamlを編集し、以下の変更を行います。
データベースの設定変更
database:
- type: sqlite
+ type: postgresdb
実行モードの変更(2箇所)
execution:
- mode: regular
+ mode: queue
worker:
- mode: regular
+ mode: queue
Webhook URLの設定
webhook:
- url: ""
+ url: "https://webhook.n8n.mydomain.jp"
Redisの有効化
redis:
- enabled: false
+ enabled: true
PostgreSQLの有効化と認証情報の設定
postgresql:
- enabled: false
+ enabled: true
auth:
- username: ""
- password: ""
+ username: "advent"
+ password: "calendar2025"
1.3 n8nのインストール
編集したvaluesファイルを使用してn8nをインストールします。
helm install n8n community-charts/n8n --values n8n-values-queue-mode.yaml
NAME: n8n
LAST DEPLOYED: Sat Dec 20 12:17:08 2025
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
1. Get the application URL by running these commands:
export POD_NAME=$(kubectl get pods --namespace default -l "app.kubernetes.io/name=n8n,app.kubernetes.io/instance=n8n" -o jsonpath="{.items[0].metadata.name}")
export CONTAINER_PORT=$(kubectl get pod --namespace default $POD_NAME -o jsonpath="{.spec.containers[0].ports[0].containerPort}")
echo "Visit http://127.0.0.1:8080 to use your application"
kubectl --namespace default port-forward $POD_NAME 8080:$CONTAINER_PORT
kubectl get pods
NAME READY STATUS RESTARTS AGE
n8n-7788475d69-46jxd 1/1 Running 0 82s
n8n-mcp-webhook-55dd847bcc-frfjh 1/1 Running 0 82s
n8n-postgresql-0 1/1 Running 0 82s
n8n-redis-master-0 1/1 Running 0 82s
n8n-webhook-788c4d8d88-2rslx 0/1 Running 0 82s
n8n-webhook-788c4d8d88-dgb7f 1/1 Running 0 82s
n8n-worker-59d669b878-86ckv 1/1 Running 0 82s
n8n-worker-59d669b878-mxfkk 0/1 Running 0 82s
kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
n8n ClusterIP 10.43.33.195 <none> 5678/TCP 2m5s
n8n-mcp-webhook ClusterIP 10.43.194.191 <none> 5678/TCP 2m5s
n8n-postgresql ClusterIP 10.43.106.62 <none> 5432/TCP 2m5s
n8n-postgresql-hl ClusterIP None <none> 5432/TCP 2m5s
n8n-redis-headless ClusterIP None <none> 6379/TCP 2m5s
n8n-redis-master ClusterIP 10.43.197.140 <none> 6379/TCP 2m5s
n8n-webhook ClusterIP 10.43.62.209 <none> 5678/TCP 2m5s
1.4 Traefik(Ingress)の設定
n8nとn8n-webhookをTraefik経由でアクセスできるようにIngressリソースを作成します。
n8n-ingress.yamlを作成します。
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: mydomain
annotations:
cert-manager.io/cluster-issuer: mydomain-issuer-prod
traefik.ingress.kubernetes.io/router.entrypoints: "web,websecure" # HTTPSのエントリポイントを指定
traefik.ingress.kubernetes.io/router.tls: "true" # TraefikにTLSを使用することを明示
spec:
ingressClassName: "traefik"
tls:
- hosts:
- n8n.mydomain.jp
- webhook.n8n.mydomain.jp
rules:
- host: n8n.mydomain.jp
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: n8n
port:
number: 5678
- host: webhook.n8n.mydomain.jp
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: n8n-webhook
port:
number: 5678
Ingressリソースを適用します。
kubectl apply -f n8n-ingress.yaml
kubectl describe ingress
Rules:
Host Path Backends
---- ---- --------
n8n.mydomain.jp
/ n8n:5678 (10.42.0.182:5678)
webhook.n8n.mydomain.jp
/ n8n-webhook:5678 (10.42.0.181:5678,10.42.0.184:5678)
1.5 n8nへのアクセス
Traefik経由でn8nにアクセスできます。ブラウザで以下のURLにアクセスします:
https://n8n.mydomain.jp
管理者アカウントの作成画面が表示されるので設定します。
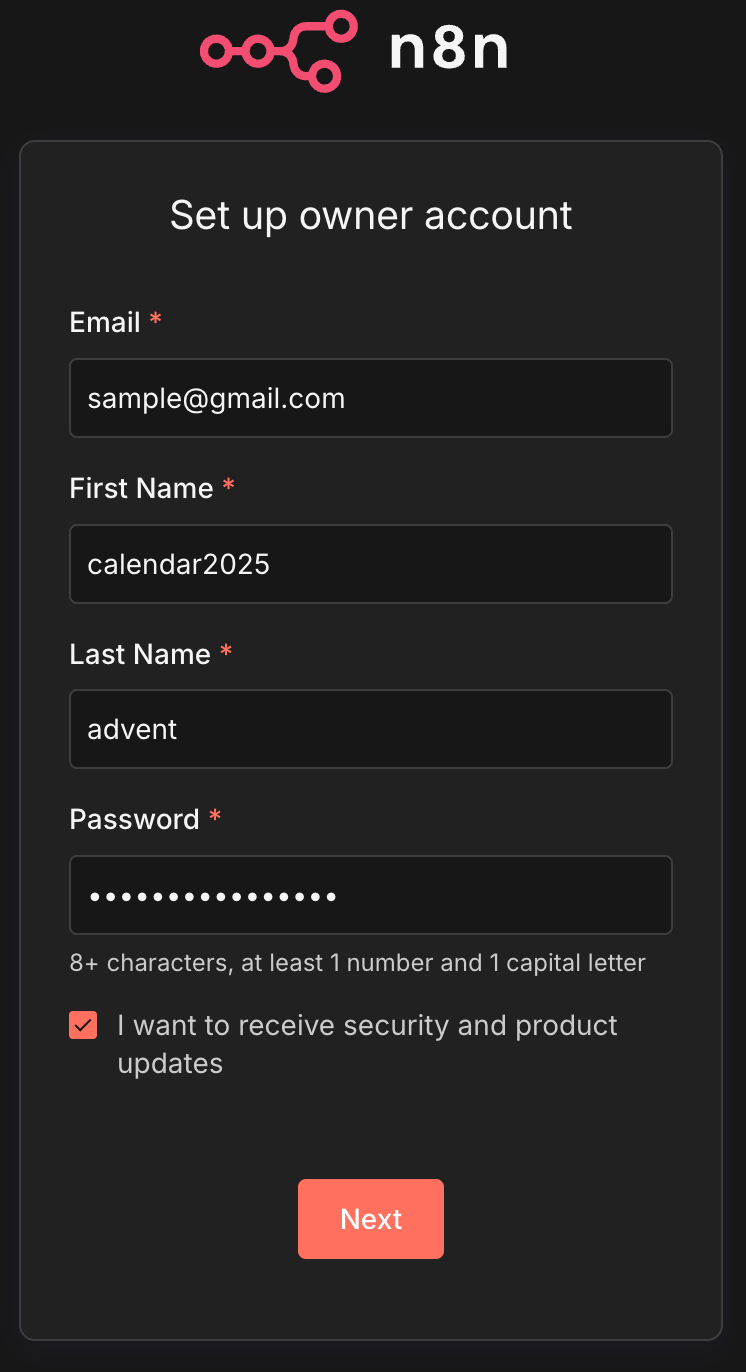
初期セットアップが完了しました。

2. ローカルLLMの選定とデプロイ
検証PCの空きメモリ量は潤沢というわけでもないため、なるべく軽量なLLMを選定し、K3s上にデプロイします。
top - 13:26:32 up 27 days, 4:23, 1 user, load average: 0.22, 0.30, 0.33
Tasks: 450 total, 2 running, 448 sleeping, 0 stopped, 0 zombie
%Cpu(s): 1.8 us, 0.7 sy, 0.0 ni, 97.4 id, 0.1 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 128577.2 total, 77831.1 free, 8166.2 used, 43899.3 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 120411.0 avail Mem
2.1 LLMモデルの選定
軽量なモデルとして以下のような選択肢があります。
- Llama 2 7B/13B: 量子化版を使用すれば10-20GB程度
- Mistral 7B: 量子化版で約10GB
- Phi-2: より軽量で約5GB
LLMの管理には、Ollamaを使用します。OllamaはローカルLLMの実行環境として広く使われており、複数のモデルを簡単に切り替えられます。
2.2 Ollamaのデプロイ
OllamaをK3s上にデプロイするためのマニフェストを作成します。
apiVersion: v1
kind: Service
metadata:
name: ollama
namespace: default
spec:
type: ClusterIP
ports:
- port: 11434
targetPort: 11434
selector:
app: ollama
---
apiVersion: v1
kind: Pod
metadata:
name: ollama
namespace: default
labels:
app: ollama
spec:
containers:
- name: ollama
image: ollama/ollama:latest
ports:
- containerPort: 11434
resources:
requests:
memory: "40Gi"
cpu: "4"
limits:
memory: "48Gi"
cpu: "8"
volumeMounts:
- name: conf
mountPath: /root/.ollama # コンテナ内のパス
subPath: ollama # PVC内のサブパス
volumes:
- name: conf
persistentVolumeClaim:
claimName: conf-pvc
2.3 Ollamaのデプロイ実行
# デプロイ
kubectl apply -f ollama.yaml
# デプロイ状況の確認
kubectl get pods
NAME READY STATUS RESTARTS AGE
ollama 1/1 Running 0 3m28s
kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ollama ClusterIP 10.43.194.59 <none> 11434/TCP 13h
2.4 LLMモデルのダウンロード
Ollamaが起動したら、いくつかモデルをダウンロードします。
kubectl exec -it ollama -- ollama pull mistral:7b-instruct-q4_K_M
pulling manifest
pulling faf975975644: 100% ▕█████████████████████████████████████████████████████████▏ 4.4 GB
pulling 43070e2d4e53: 100% ▕█████████████████████████████████████████████████████████▏ 11 KB
pulling 22e1b2e8dc2f: 100% ▕█████████████████████████████████████████████████████████▏ 43 B
pulling ed11eda7790d: 100% ▕█████████████████████████████████████████████████████████▏ 30 B
pulling 126aeb334a49: 100% ▕█████████████████████████████████████████████████████████▏ 485 B
verifying sha256 digest
writing manifest
success
kubectl exec -it ollama -- ollama pull phi:2.7b
pulling manifest
pulling 04778965089b: 100% ▕█████████████████████████████████████████████████████████▏ 1.6 GB
pulling 7908abcab772: 100% ▕█████████████████████████████████████████████████████████▏ 1.0 KB
pulling 774a15e6f1e5: 100% ▕█████████████████████████████████████████████████████████▏ 77 B
pulling 3188becd6bae: 100% ▕█████████████████████████████████████████████████████████▏ 132 B
pulling 0b8127ddf5ee: 100% ▕█████████████████████████████████████████████████████████▏ 42 B
pulling 4ce4b16d33a3: 100% ▕█████████████████████████████████████████████████████████▏ 555 B
verifying sha256 digest
writing manifest
success
モデルのサイズとメモリ使用量。
-
mistral:7b-instruct-q4_K_M: 約4.1GB、実行時約8-10GB -
phi:2.7b: 約1.6GB、実行時約3-4GB
2.5 Ollama APIの動作確認
kubectl port-forward pod/ollama 11434:11434 &
[1] 2291845
Forwarding from 127.0.0.1:11434 -> 11434
curl http://localhost:11434/api/tags
Handling connection for 11434
{"models":[{"name":"phi:2.7b","model":"phi:2.7b","modified_at":"2025-12-20T14:03:15.521124874Z","size":1602463378,"digest":"e2fd6321a5fe6bb3ac8a4e6f1cf04477fd2dea2924cf53237a995387e152ee9c","details":{"parent_model":"","format":"gguf","family":"phi2","families":["phi2"],"parameter_size":"3B","quantization_level":"Q4_0"}},{"name":"mistral:7b-instruct-q4_K_M","model":"mistral:7b-instruct-q4_K_M","modified_at":"2025-12-20T14:01:02.728332456Z","size":4369387754,"digest":"1a85656b534f84f8ab5b235aa0e24a954769539b0f47a4bd11f5272cba43c892","details":{"parent_model":"","format":"gguf","family":"llama","families":["llama"],"parameter_size":"7B","quantization_level":"Q4_K_M"}}]}
3. n8nパイプラインの作成
ダッシュボード上で手動でパイプラインを作成することもできますが、先人のパイプラインが公開されているのでありがたくそれを使いましょう。
3.1 テンプレートライブラリへのアクセス
- n8nのダッシュボードにログインします。
- 左側のメニューからTemplatesを選択しテンプレートライブラリページに遷移します。
3.2 テンプレートの検索およびimport
- 「Chat with local LLMs using n8n and Ollama」を検索し、Use for freeボタンをクリックします。
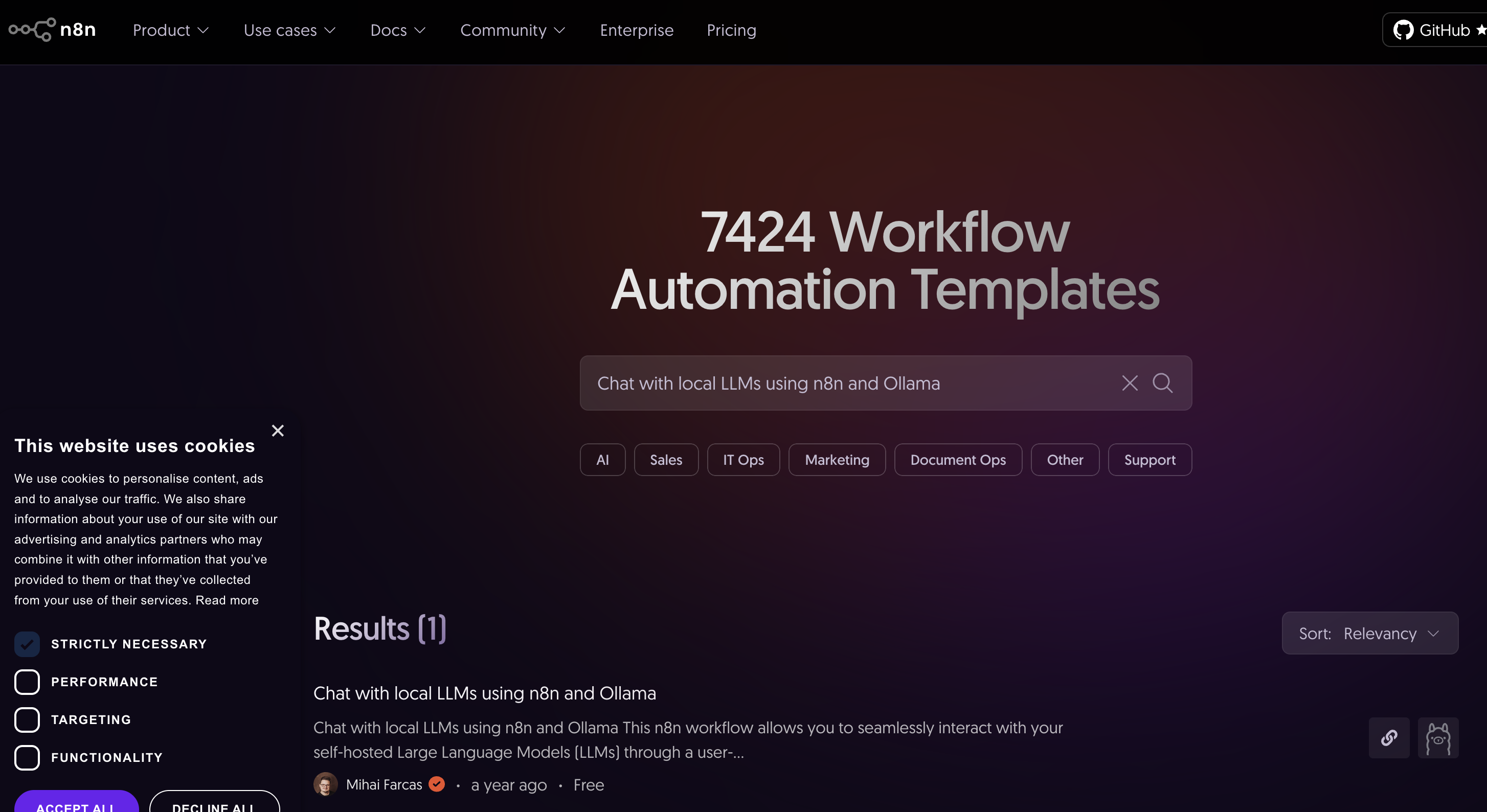

- 表示されたダイアログ内の「 Import template to (n8n domain) self-hosted instance」を選択してimportを行います。


instance内のtemplatesボタン経由でライブラリに遷移しないと、importオプションが表示されません
3.3 Ollamaの設定調整
テンプレートをimport後、Ollamaの接続設定を環境に合わせて調整します。
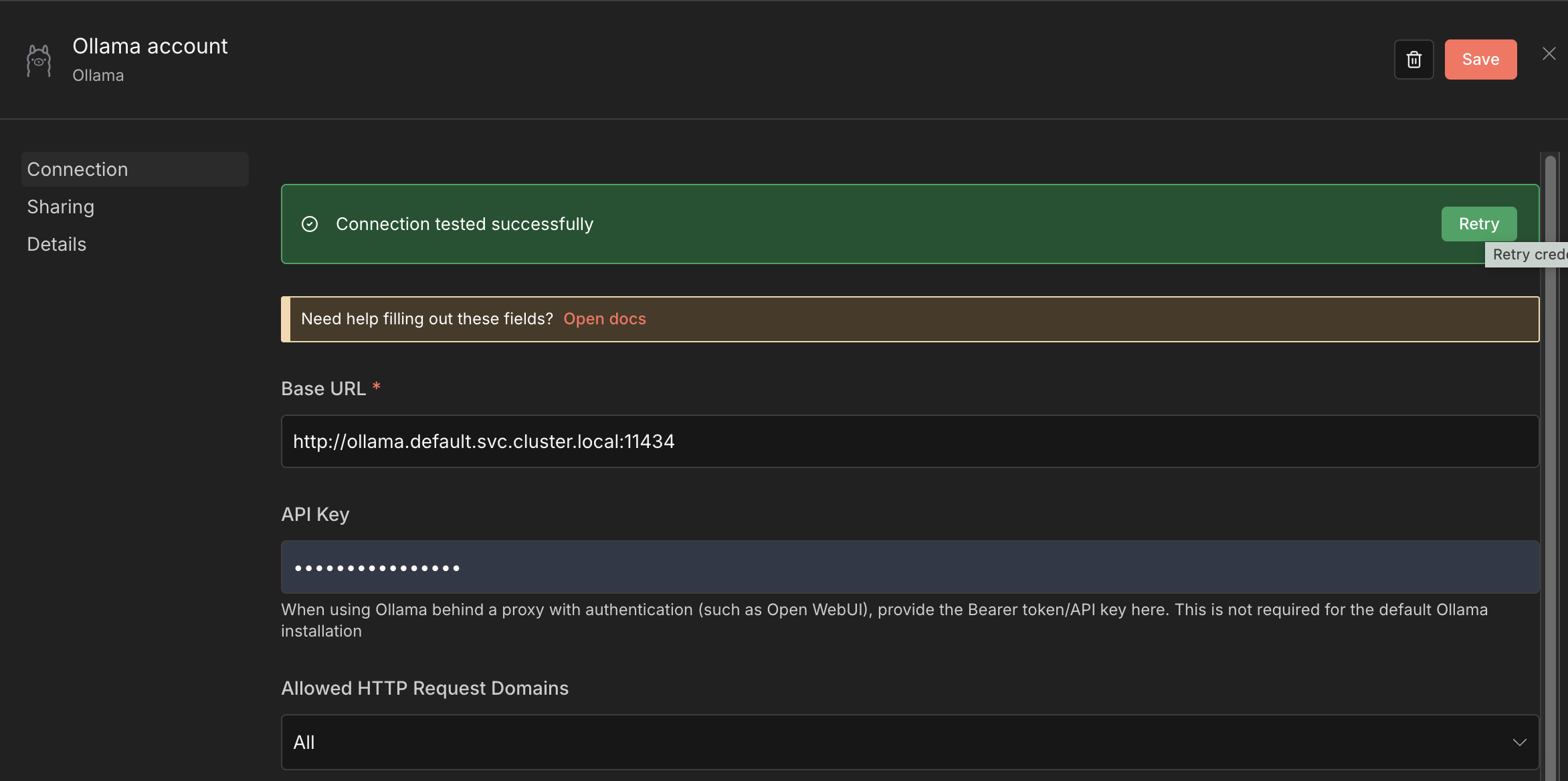
- Ollama Chat Modelノードを開きます。

- OllamaサーバーのURLを環境に合わせて設定します。設定後ConnectionTestを行っておきましょう。
- デフォルト:
http://localhost:11434 - 変更後:
http://ollama.default.svc.cluster.local:11434
- デフォルト:
- 使用するモデル名を指定します(例:
mistral:7b-instruct-q4_K_M)。

何故か1度パイプラインの実行を失敗させないとモデルが表示されませんでした。(開き直せばOK?)
3.4 ワークフローの保存と有効化
- 設定を確認し、ワークフローを保存(Save)します
- Publishボタンを押下して有効化します

4. 動作検証
設定完了したテンプレートを実際に動作させてみます。
4.1 チャットインターフェースでの動作確認
importしたテンプレートは、n8nのチャットインターフェースから直接LLMと対話できるワークフローです。
- ワークフロー編集画面の下部にある[Open Chat]をクリックします。
- チャットインターフェースが開くのでなにか入力して正しく応答が返ってくるか確認します。
質問に対し、回答に7秒となかなか牧歌的なチャットですが正常に動作させることができました。
ちなみに、日本語で「アドベントカレンダーについて教えて」と聞いたところ8分以上かかりました、、、
4.2 リソース使用量の確認
# Podのリソース使用量を確認
kubectl top pods
NAME CPU(cores) MEMORY(bytes)
n8n-7788475d69-46jxd 2m 319Mi
n8n-mcp-webhook-55dd847bcc-frfjh 2m 179Mi
n8n-postgresql-0 14m 41Mi
n8n-redis-master-0 27m 8Mi
n8n-webhook-788c4d8d88-2rslx 2m 199Mi
n8n-webhook-788c4d8d88-dgb7f 1m 199Mi
ollama 0m 2443Mi
5. 検証を終えて
検証PCのSpecがそこまで高くないのもあり、チャットの応答はできるものの時間が相当にかかりました。
応答速度改善は今後の課題ですね。
Helmやn8nのTemplatesなど、先人の知恵を手軽に取り込める機能が充実しているのでスムーズに検証することができました。
n8nはワークフローがわかりやすく可視化されているのも個人的にかなり好みです。
LLMに限らず他のWebリソースとの連携も今後試していきたいです。
今後の追加検証
- 応答速度改善のためのチューニング
- Webhookを追加し、API経由でのアクセスを検証する
- 認証機能の追加
- 他のn8nノードとの連携(データベース、API等)