※この記事では, 一般的なニューラルネットワークの特徴, CNN のしくみなどは取り上げません. それらは各自で学習済みと想定しています.
前回
Google Colaboratory で Chainer を触ってみるvol.4 ~活性化関数を理解する~
進捗
隠れ層の数, 活性化関数, optimizer, 学習時のパラメータなどが学習時間と学習精度にどのような影響を及ぼすか, 「00 Colaboratory で Chainer を動かしてみよう」で実験中です. 今回は, 「エポック数とバッチサイズの影響」を確認しました.
理解したこと表
| どの影響? | 学習時間 | 学習精度 | 備考 |
|---|---|---|---|
| 隠れ層の数 | + 0.3秒/1layer | 8層でほぼ頭打ち | - |
| 隠れ層の node 数 | ほぼ変わらず | 500 node で +1.5% | GPU 使えば何でもよさそう |
| 活性化関数 | +2.04s(selu) | +2.7%(selu) | パラメータをいじるともう少し精度上がる |
| エポック数 | エポック数増加に伴い増加 | 5 epoch で十分 | - |
| バッチサイズ | バッチサイズの減少に伴い増加 | 128 バッチがよさそう | - |
| optimizer | - | - | - |
エポック数とは
「訓練データを一巡したら1カウントされる数」のことです.
たとえば 100000 個の学習データがあり, 1000 個ずつのデータ(後述)で学習をする場合, 100 回学習を行えば1エポックとなります. 5 エポック学習する場合は, これを5回繰り返すことになります.
バッチとは
「一回の学習に使うデータの個数」です. 入力データを一定数の束に分割したものです. ミニバッチと呼ばれることもあります.
たとえば, 100000 個の入力データを 1000 個ずつに分割した場合, 100 個のバッチがあることになります. この場合, 100 個のバッチを一通り使った時のサイクルを, 1エポックと呼びます(上述).
ニューラルネットワークの計算に用いるライブラリは並列処理に長けているので, こまめに小さなデータを送って逐次処理をするよりも, ある程度の塊でデータを送って一気に処理した方が効率的なんだそうです.
試行錯誤するコード
いつものやつです. そのほかのコードは, Vo.1で投稿したものと同じです.
# class_model.py
import chainer.functions as F
import chainer.links as L
from chainer import Chain
class MLPNew(Chain):
def __init__(self):
super(MLPNew, self).__init__()
with self.init_scope():
# Add more layers?
self.l1 = L.Linear(784, 200) # Increase output node as (784, 300)?
self.l2 = L.Linear(200, 200) # Increase nodes as (300, 300)?
self.l3 = L.Linear(200, 10) # Increase nodes as (300, 10)?
def forward(self, x):
h1 = F.tanh(self.l1(x)) # Replace F.tanh with F.sigmoid or F.relu?
h2 = F.tanh(self.l2(h1)) # Replace F.tanh with F.sigmoid or F.relu?
y = self.l3(h2)
return y
# do_train_and_validate.py
device = 0
n_epoch = 5 # Add more epochs?
batchsize = 256 # Increase/Decrease mini-batch size?
model = MLPNew()
classifier_model = L.Classifier(model)
optimizer = optimizers.SGD() # Default SGD(). Use other optimizer, Adam()?(Are there Momentum and AdaGrad?)
train_and_validate(
classifier_model, optimizer, train, validation, n_epoch, batchsize, device)
今回は, 下記 epoch 数と batchsize を変更すれば試せます.
n_epoch = 5 # Add more epochs?
batchsize = 256 # Increase/Decrease mini-batch size?
結果詳細
デフォルト(HandsOn 通りの設定)
- 隠れ層 : 3
- 隠れ層の node 数 : 200
- 活性化関数 : tanh
- epoch 数 : 5 ←まずこれを変更する
- batchsize : 256 ←次にこれを変更する
- optimizer : SGD
エポック数
| エポック数 | 合計学習時間(sec) | 学習結果 | テスト結果 |
|---|---|---|---|
| 3 | 8.76625 | 0.763321 | 0.765044 |
| 5(デフォルト) | 14.9342(基準) | 0.798337(基準) | 0.7910156(基準) |
| 10 | 30.3417 | 0.824896 | 0.81396484 |
| 15 | 45.4701 | 0.839543 | 0.82529294 |
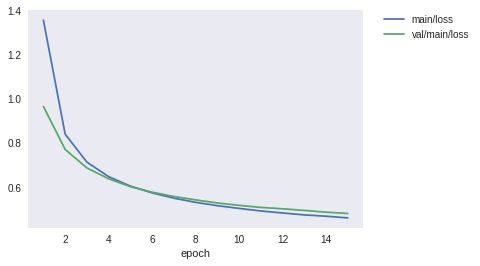
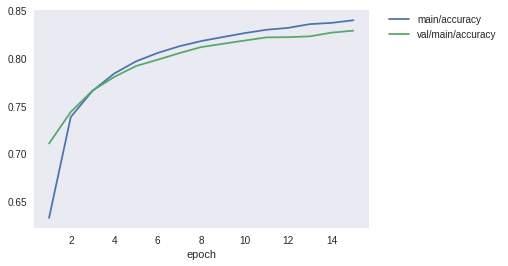
学習回数が増えるので, epoch 数が増えると学習時間は単純に伸びていきます. また, epoch 数が増加すると精度は上がるのですが, 学習結果とテスト結果の乖離が大きくなりそうです. 少し過学習しているのかな.
下記は epoch 数 15 の時の学習曲線です. この曲線を見る限り, epoch 数は 5 でちょうどよさそうですね.
バッチサイズ
| バッチサイズ | 合計学習時間(sec) | 学習結果 | テスト結果 |
|---|---|---|---|
| 32 | 93.5139 | 0.855106 | 0.84052736 |
| 64 | 48.611 | 0.841612 | 0.83144534 |
| 128 | 26.157 | 0.821551 | 0.81455076 |
| 256(デフォルト) | 14.9342(基準) | 0.798337(基準) | 0.7910156(基準) |
| 512 | 0.74785155 | 0.751076 | 9.37478 |
| 1024 | 0.709124 | 6.3029 | 0.7061523 |
バッチサイズが小さいと, データの読み込み回数が増えるため学習時間が単純に伸びました. 一方で, バッチファイルが小さいほど学習精度やテスト結果がよくなりました. これらを踏まえると, バッチサイズは 128 がバランスよいかもしれませんね. すこし過学習してるような気がしますが, このくらいは許容範囲なのかな.
まとめ
エポック数は, 同じ学習データをいろんな組合せに分割して何サイクルを回したか, という数です. 数が多いほど学習精度は上がりますが, 学習時間が延びます.
バッチサイズは, 一回の学習に用いるデータの個数です. バッチが小さい方が学習精度が高まりますが, データの読み込みに時間がかかるため学習時間が延びます.
次回
DeepLearning の optimizer を理解する.