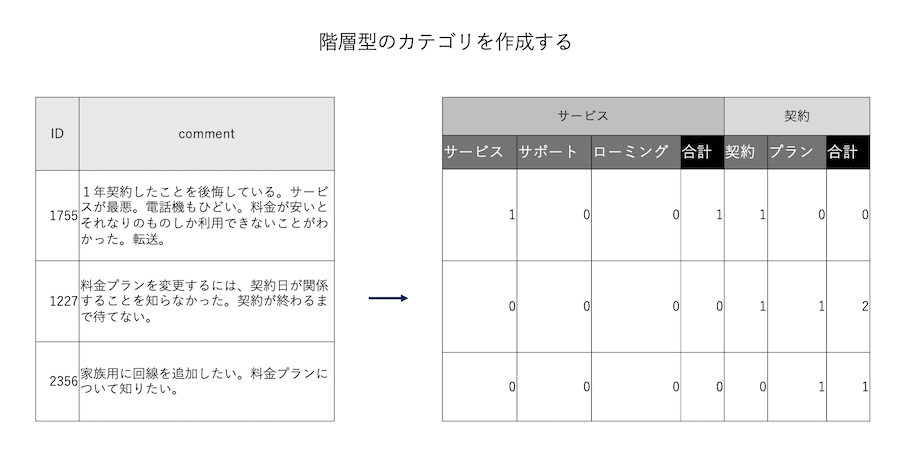
階層型のカテゴリを作成する
この記事はSPSS Modeler Premium Ver18.6から追加された日本語テキスト機能を利用して書いています。SPSS Modeler Professionalをお使いの方はアップグレードするかPython連携を用いて実現します。
Python連携を紹介する記事はこちら
1.想定される利用目的
・カテゴリを階層化して文章情報を適切にスコア化する
2.ストリームとデータのダウンロード
ストリーム
データ
3.サンプルストリームの説明
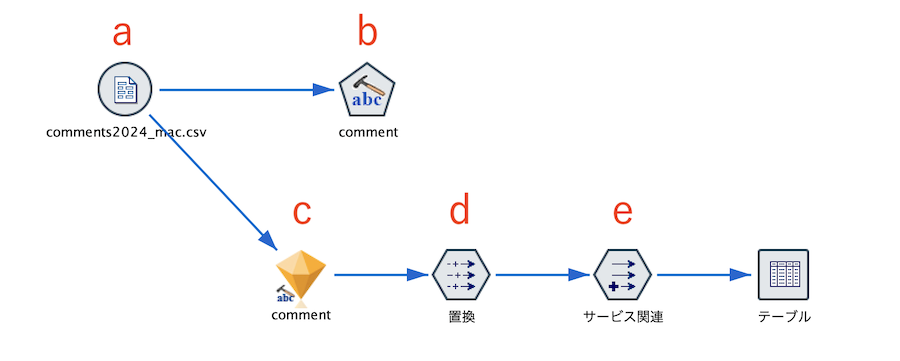
a.入力データは以下の通りです。

b.[テキストマイニング]ノードを編集します。[IDフィールド]と[テキストフィールド]を以下の通り選択します。
[モデル]タブを以下の通り設定して[実行]します。
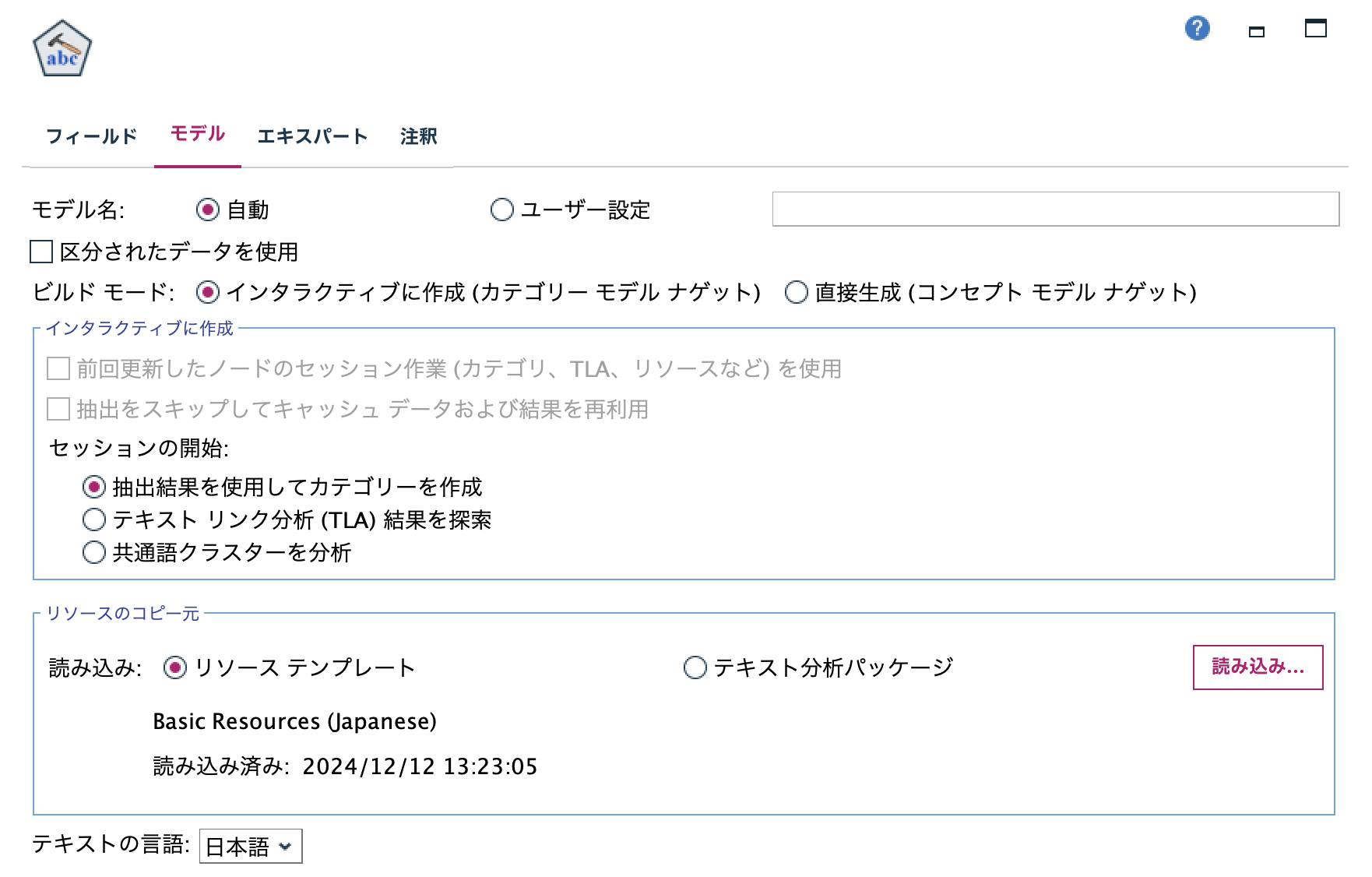
インタラクティブワークベンチ左下のコンセプトから赤枠ボタンで[ローミング][サービス][サポート]を
それぞれ一度カテゴリ登録します。
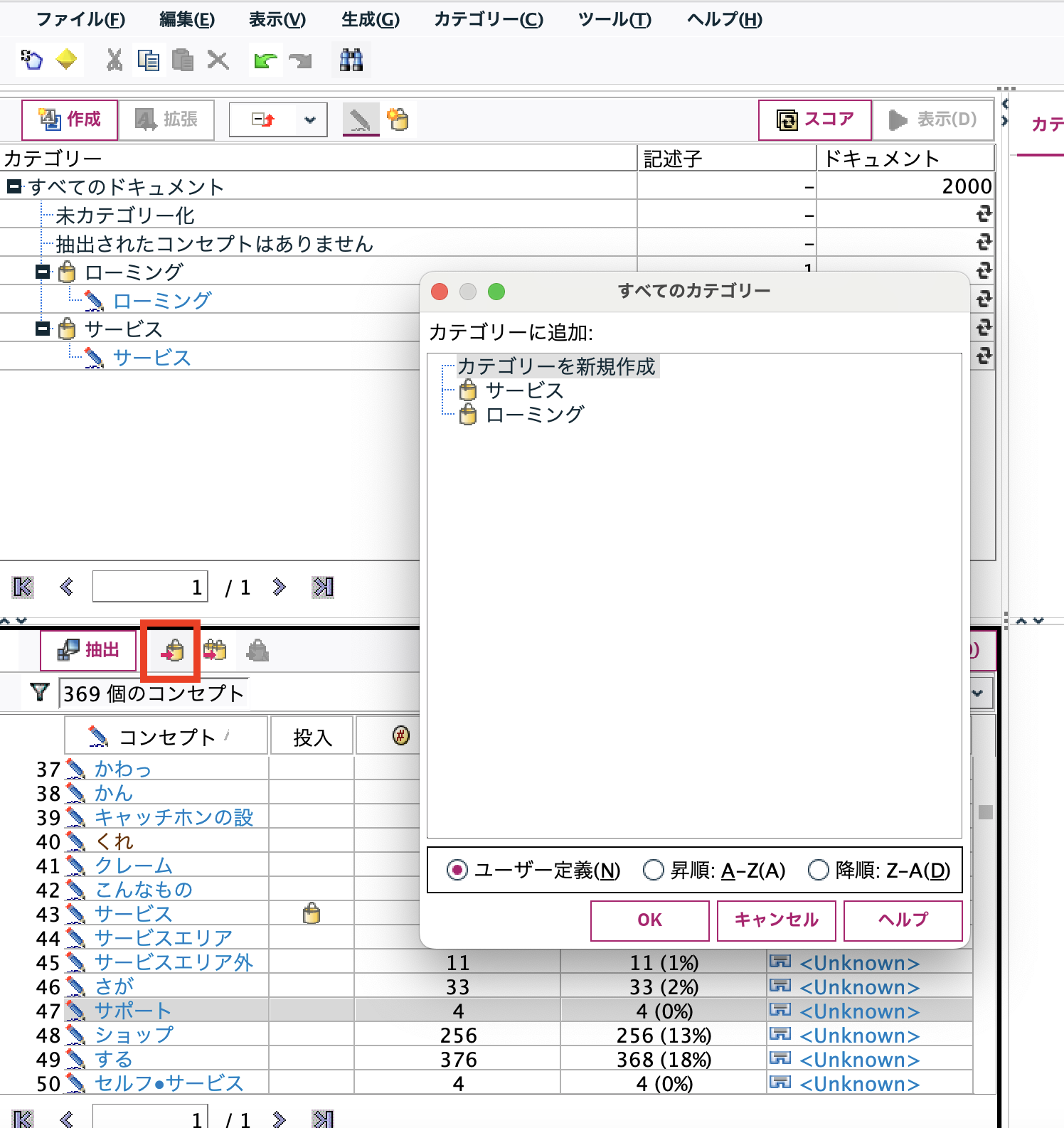
[サポート]と[ローミング]を以下の方法で[サービス]のサブカテゴリにします。
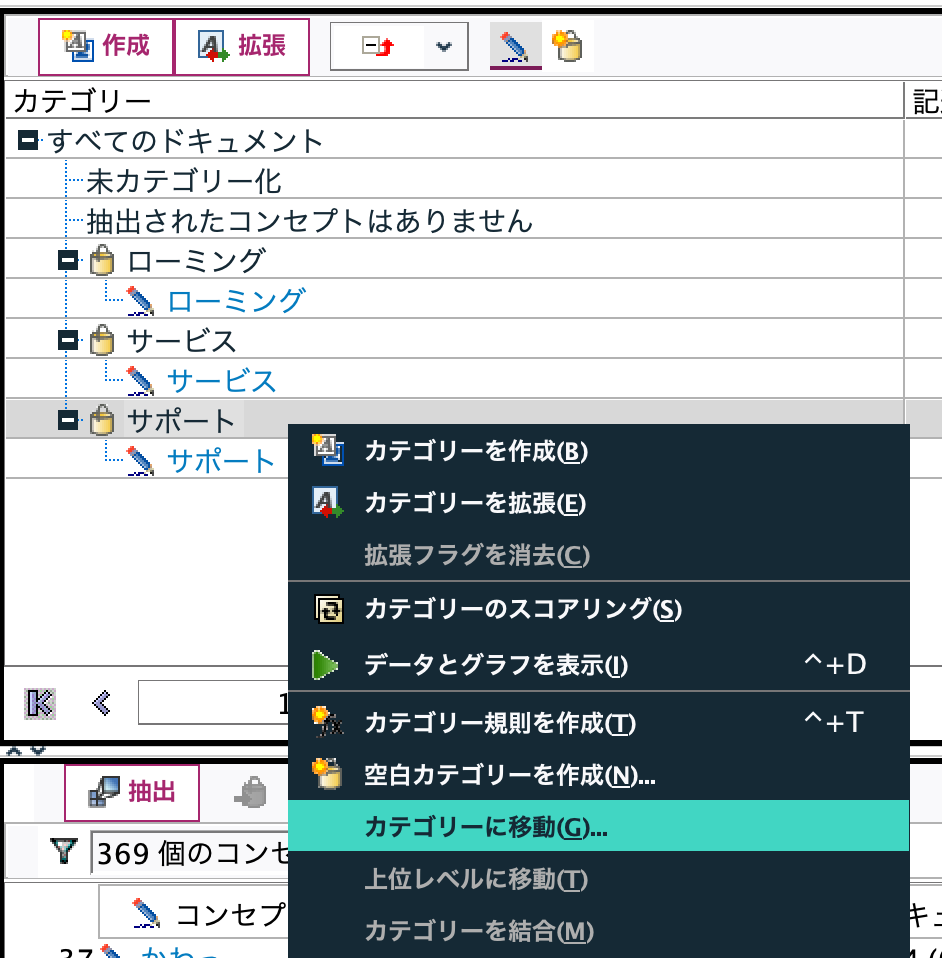
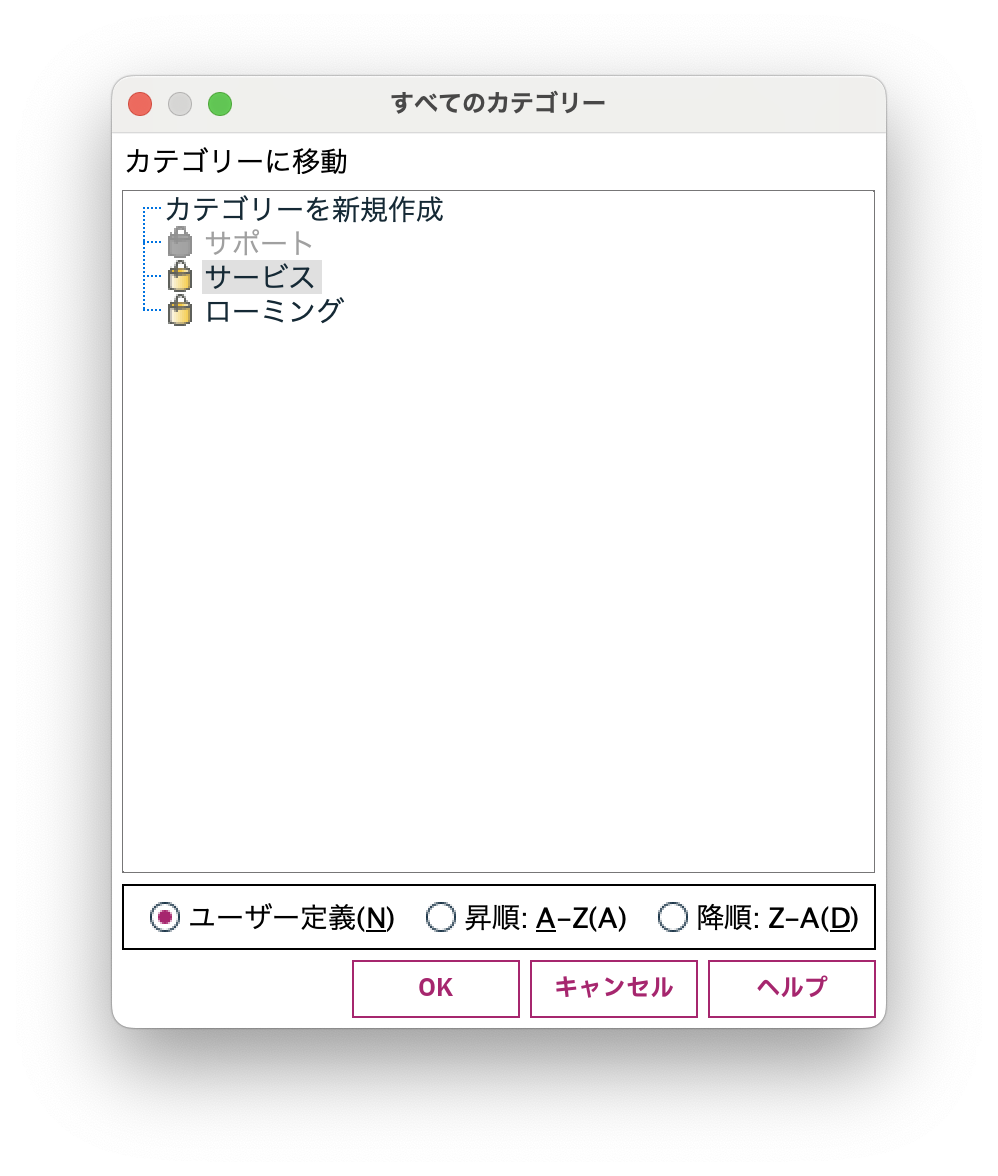
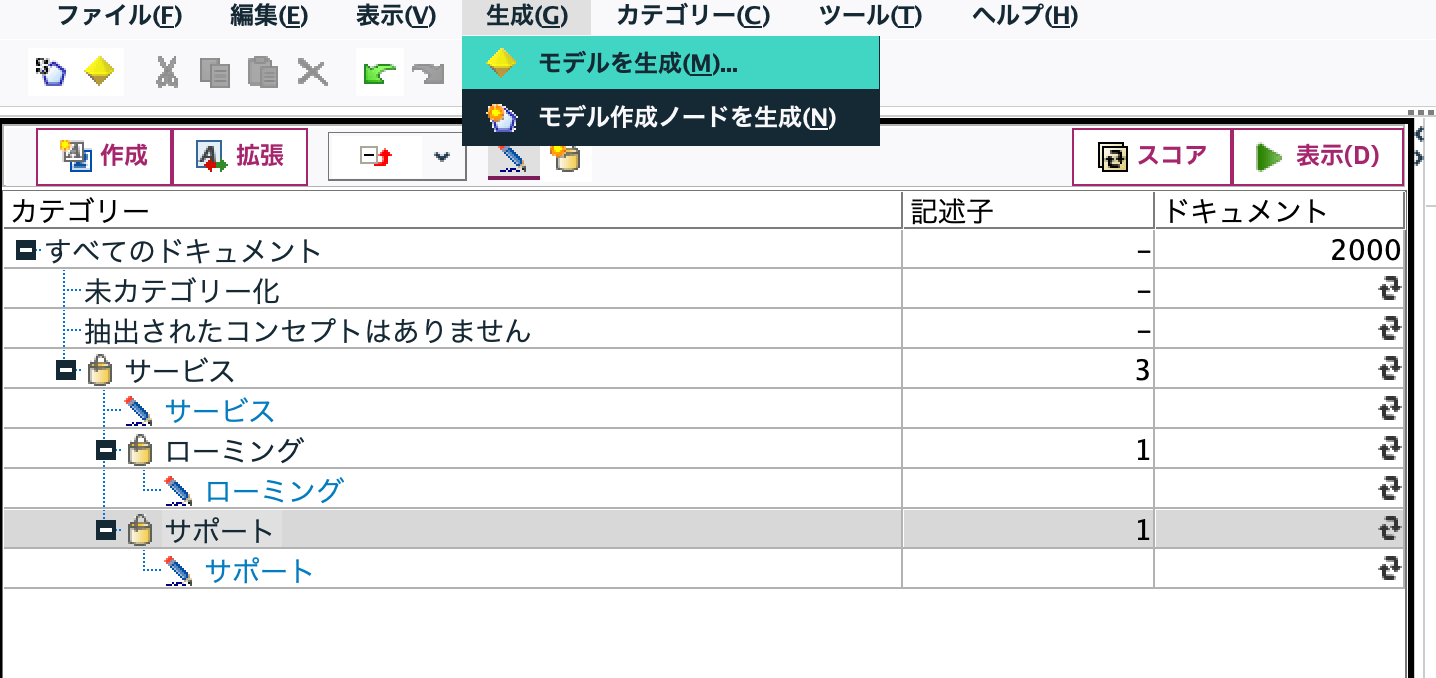
階層化できたら生成メニューからモデルを作成します。
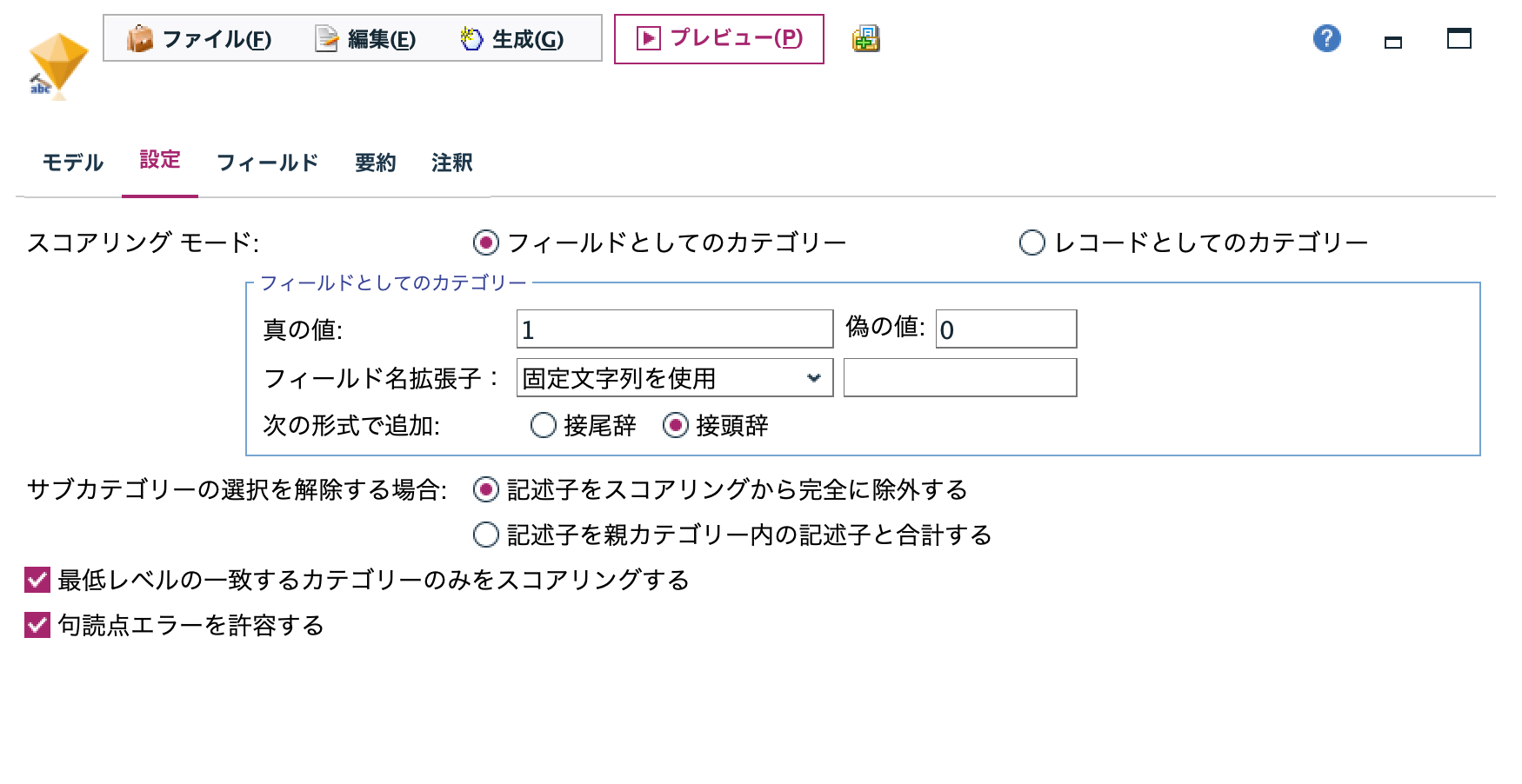
c.[テキストマイニング]ナゲットを編集します。T/Fを1/0にして接頭辞をブランクにします。
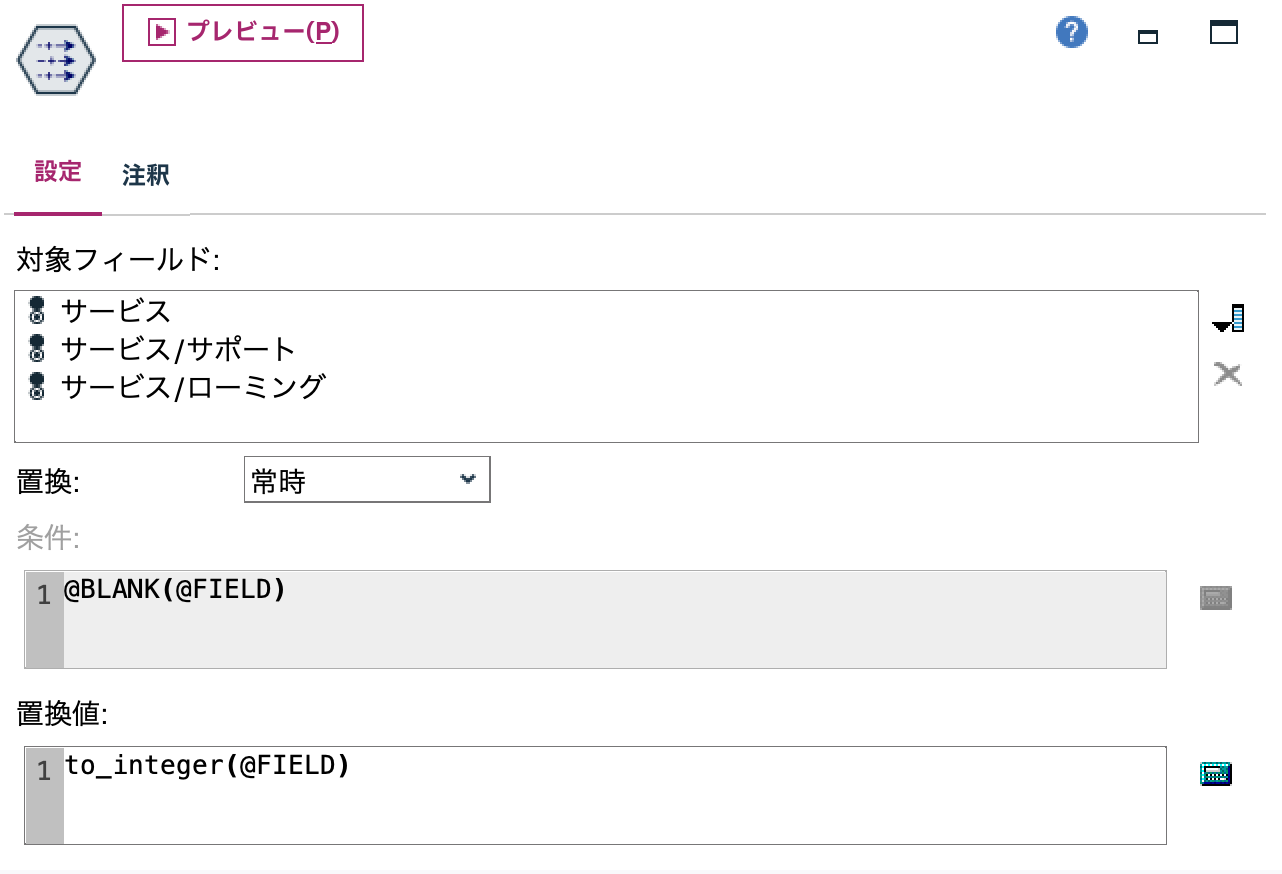
d.[置換]ノードを編集します。フラグ型を強制的に整数型に変更します。@FIELDはワイルドカードです。3つのフィールドを同時に処理することが可能です。
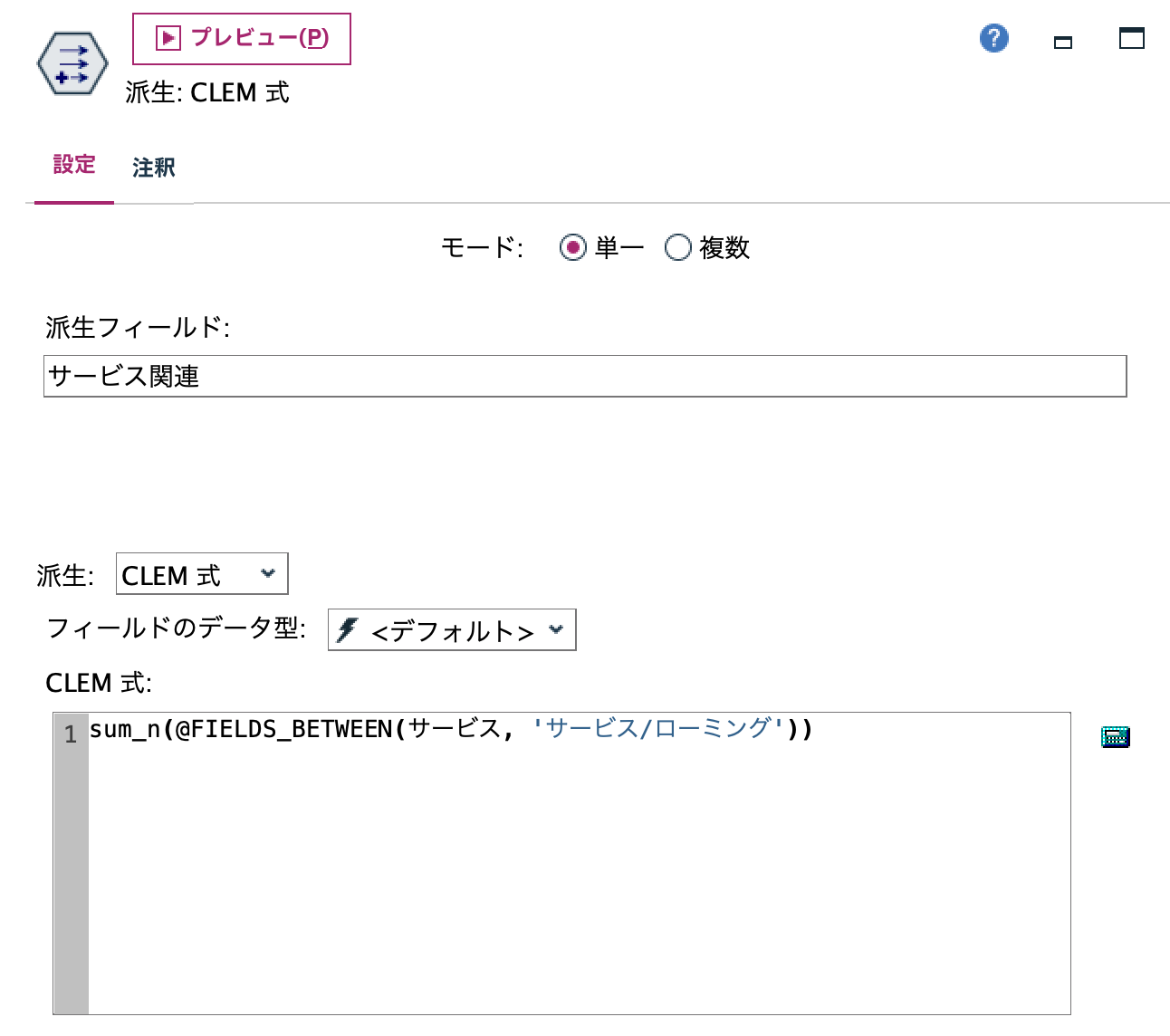
d.[フィールド作成]ノードを編集します。起点列と終点列を指定して合計を求める関数を利用します。
[テーブル]を実行します。

注意事項
子カテゴリの合計を親カテゴリで示しましたが、目的によっては最大値(1)で計算します。
4.参考情報
Python連携によるテキストマイニング
SPSS Modeler ノードリファレンス目次
SPSS Modeler 逆引きストリーム集(データ加工)