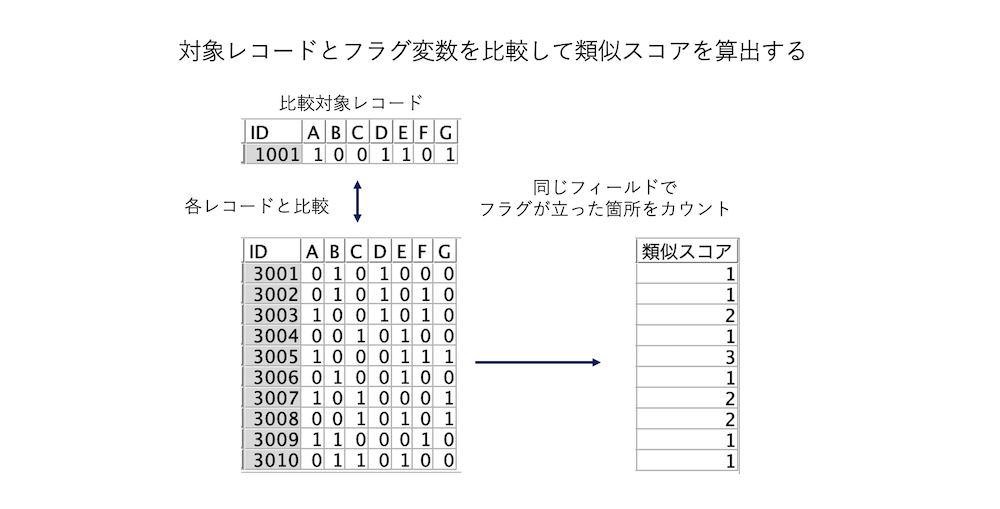
複数のフラグ変数を比較して類似スコアを算出する
この記事は以下のブログを題材にしています
1.想定される利用目的
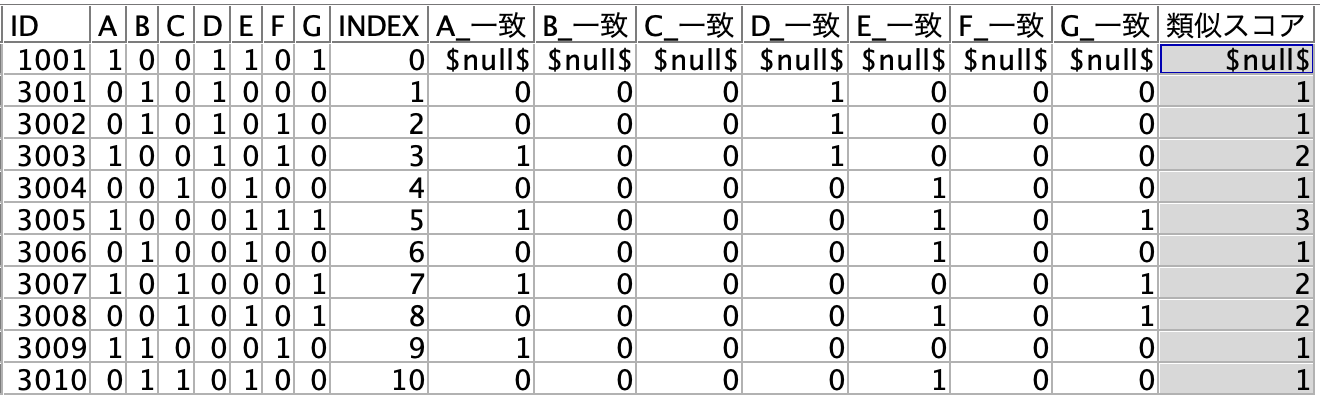
先頭レコードと比較して同じフィールド(列)にフラグが立った数をカウントする
・形態素に分解した文章/特許/コンタクトログの類似度を判定する
・アンケートの複数回答や購買記録から類似する被験者や顧客を特定する
2.サンプルストリームのダウンロード
3.サンプルストリームの説明
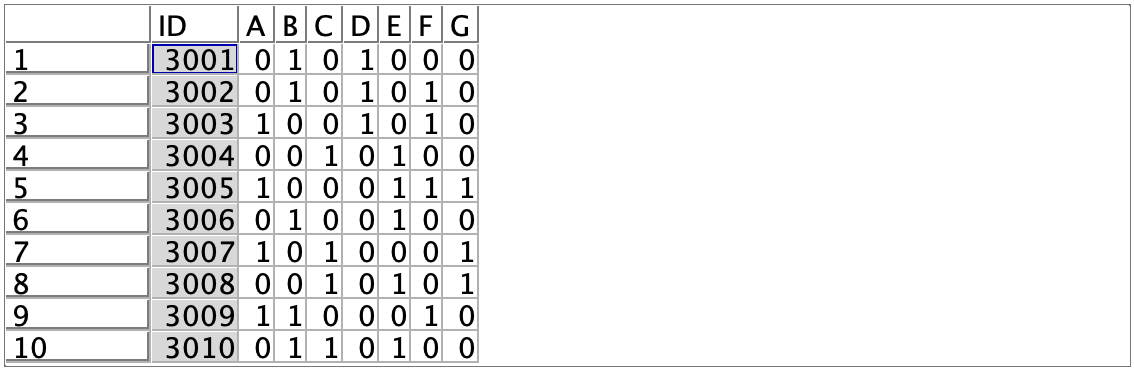
a.入力するデータのひとつ目は以下の通りです。類似度を求める対象レコードです。

b.入力するデータのふたつ目は以下の通りです。
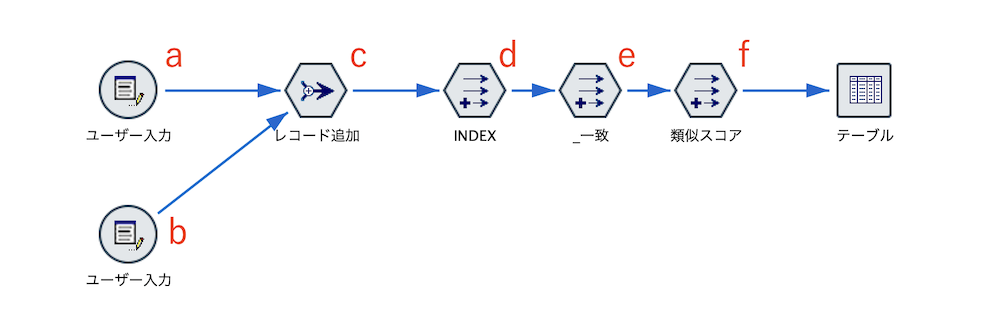
c.[レコード追加]ノードを配置します。フィールドの構造と型が一致しているのでデフォルト設定にします。
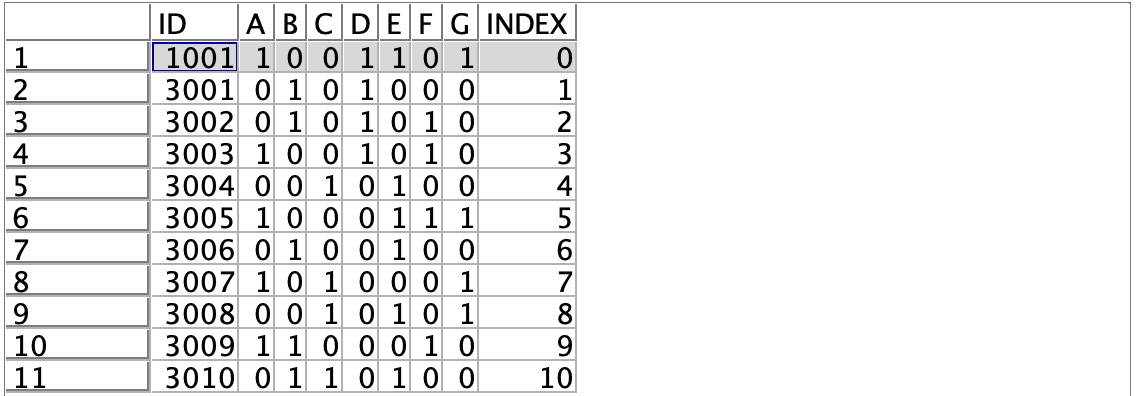
d.[フィールド作成]ノードを編集します。@INDEXでレコードに連番を振ります。この時比較対象をゼロにして2行目から1を割り当てるため@INDEX−1とします。

[プレビュー]します。INDEXの1から10を先頭0と比較していきます。
e.[フィールド作成]ノードを編集します。[モード]を[複数]に選択して[フィールドリスト]にAからGを投入します。新しいフィールド(列)がもう1セットできるので拡張子を[_一致]として識別します。
INDEXが0の場合にはヌル(undef)を割り当てそれ以外は各フィールドの先頭行と掛け算を行います。
@FIELDはワイルドカードです。@OFFSET(列,N)は N行上のレコードを参照します。

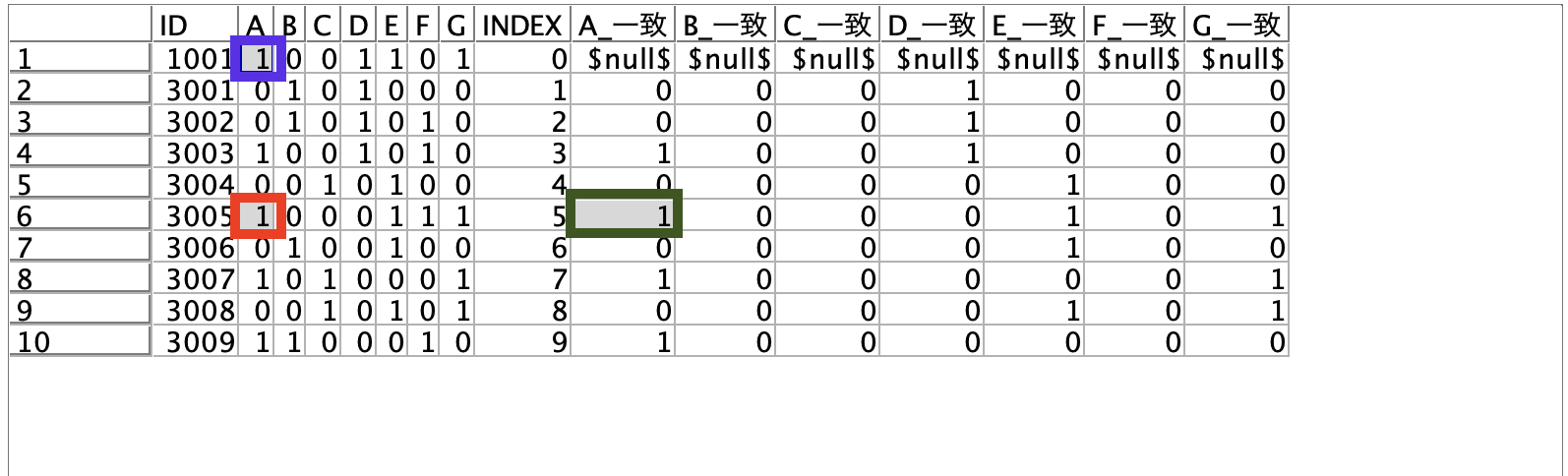
[プレビュー]します。例えば赤枠の箇所を例にとると5行上の対象セル(青枠)を参照し
A ✖︎ @OFFSET(A,5)が計算され[A_一致](緑)に1が記述されます。
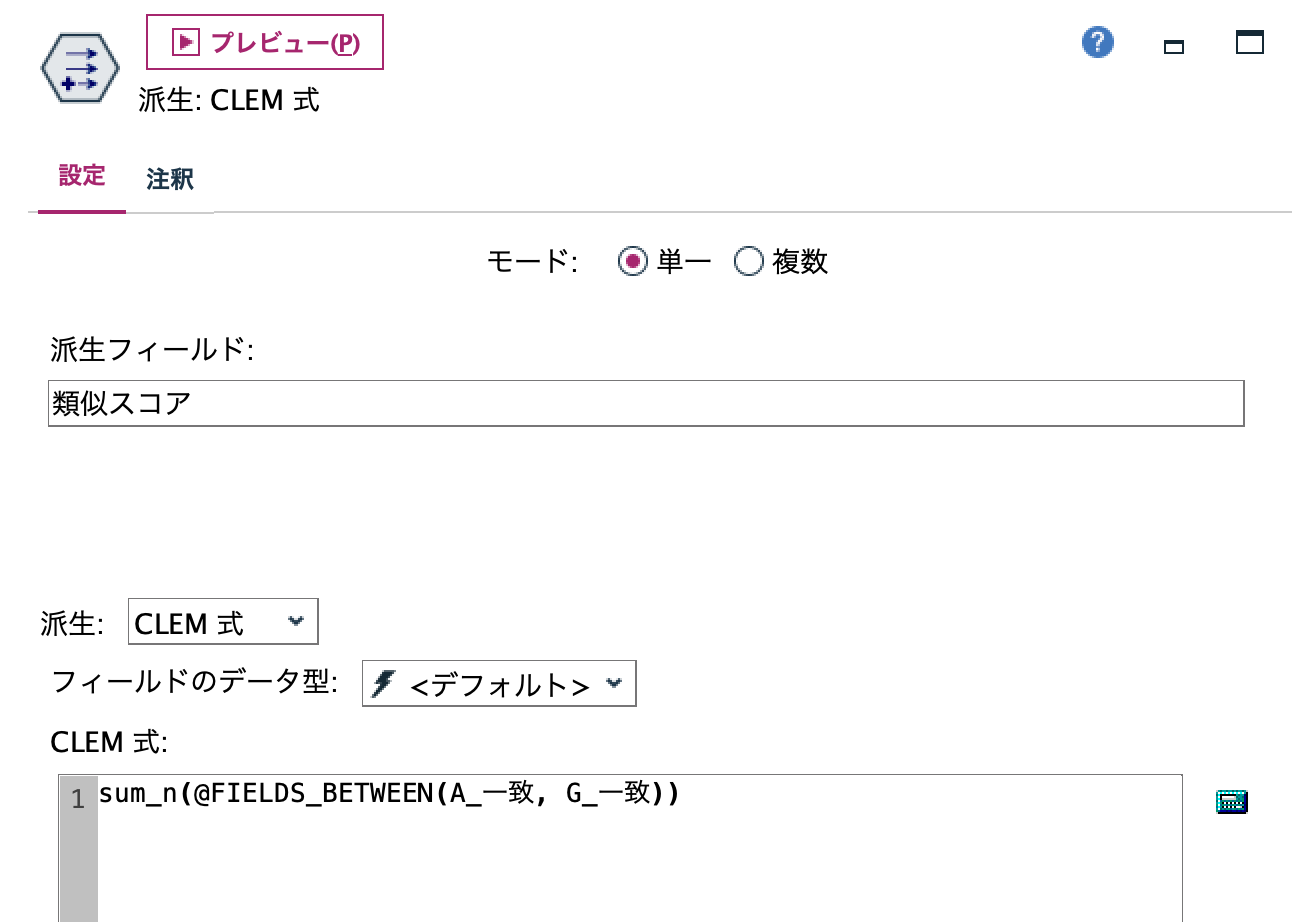
f.[フィールド作成]ノードを編集します。
[プレビュー]します。
注意点
@OFFSET関数はSQLプッシュバックが効かないため、大規模データセットでは別途工夫が必要です。
4. 参考情報
1行上/先頭行との値の差を求める
SPSS Modeler ノードリファレンス目次
SPSS Modeler 逆引きストリーム集(データ加工)