ユーザー辞書で不要語を登録する
この記事はSPSS Modeler Premium Ver18.6から追加された日本語テキスト機能を利用して書いています。SPSS Modeler Professionalをお使いの方はアップグレードするかPython連携を用いて実現します。
Python連携を紹介する記事はこちら
1.想定される利用目的
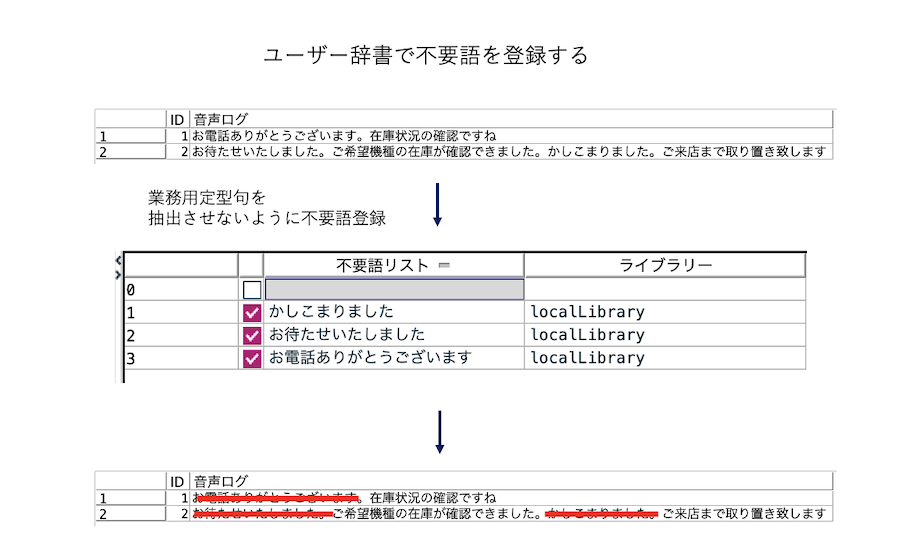
・抽出されるコンセプトとして不要な業務定型句を辞書に登録する。
2.ストリームとデータのダウンロード
ストリーム
3.サンプルストリームの説明

a.入力データは以下の通りです。

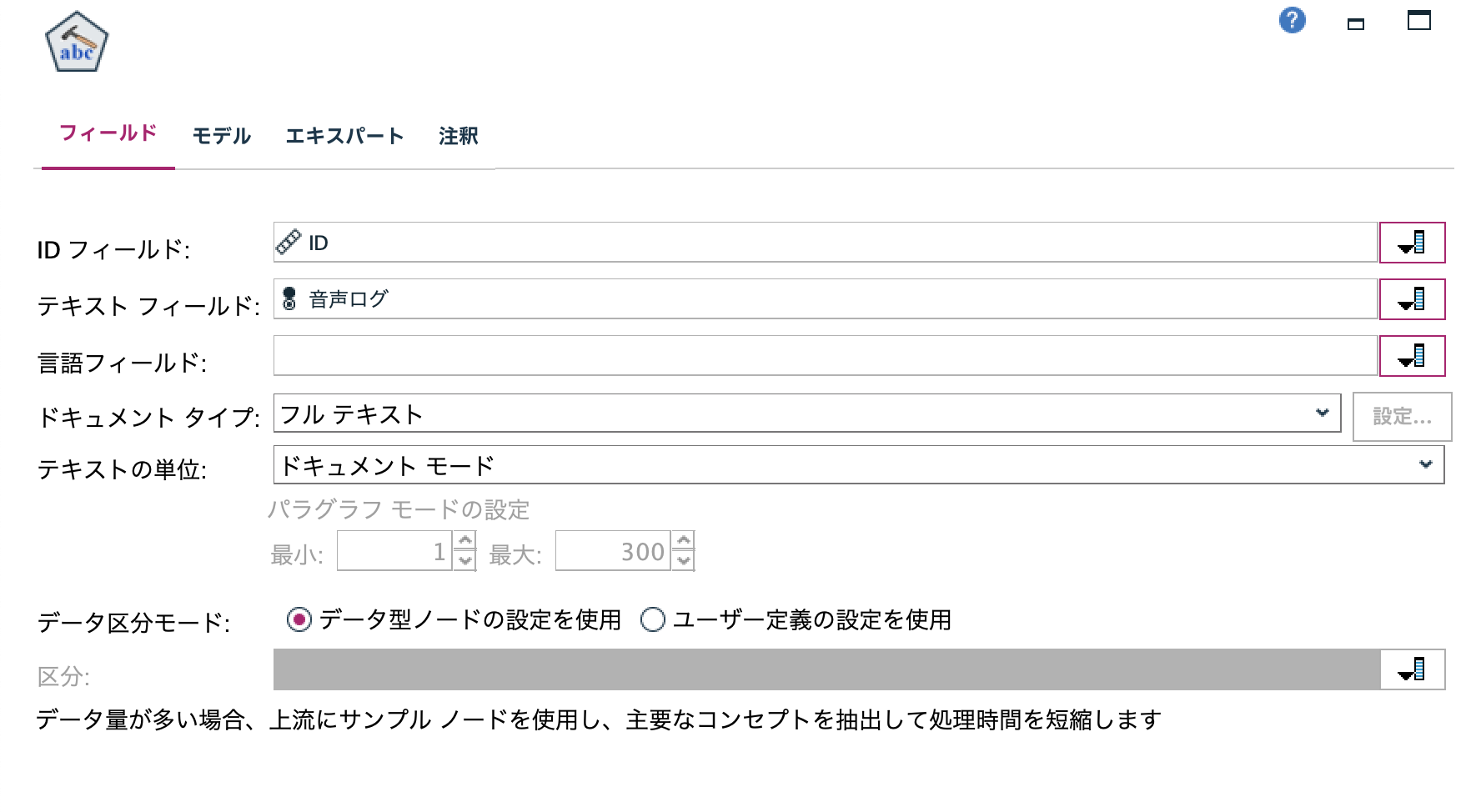
b.[テキストマイニング]ノードを編集します。[IDフィールド]と[テキストフィールド]を以下の通り選択します。
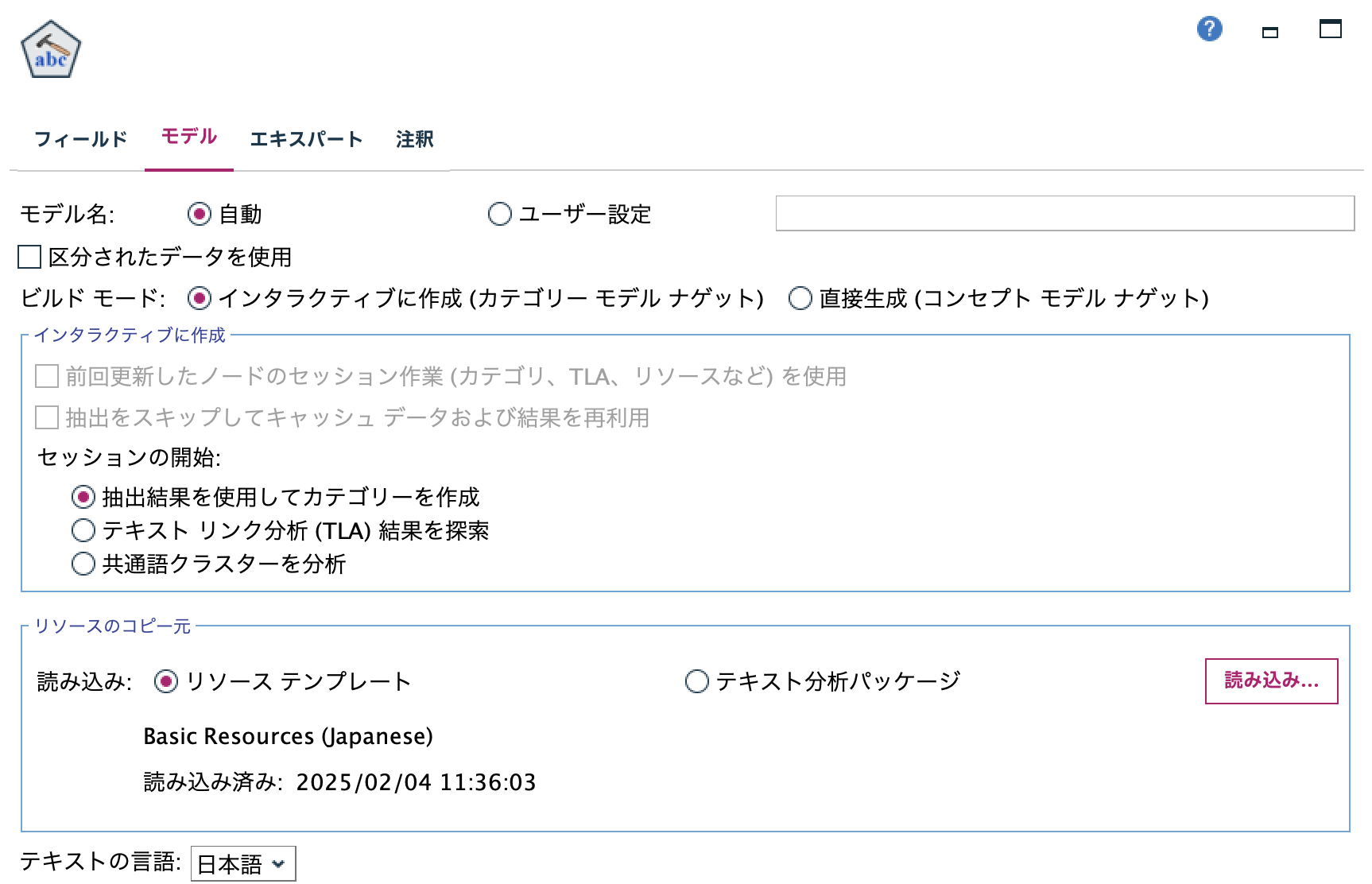
[モデル]タブを編集します。[抽出結果を利用して...]を選択します。
[実行]します。「かしこまりました」などの音声ログ特有定型句が抽出されており、不要語登録します。画面右上のドロップダウンリストから辞書[リソースエディター]を呼び出します。
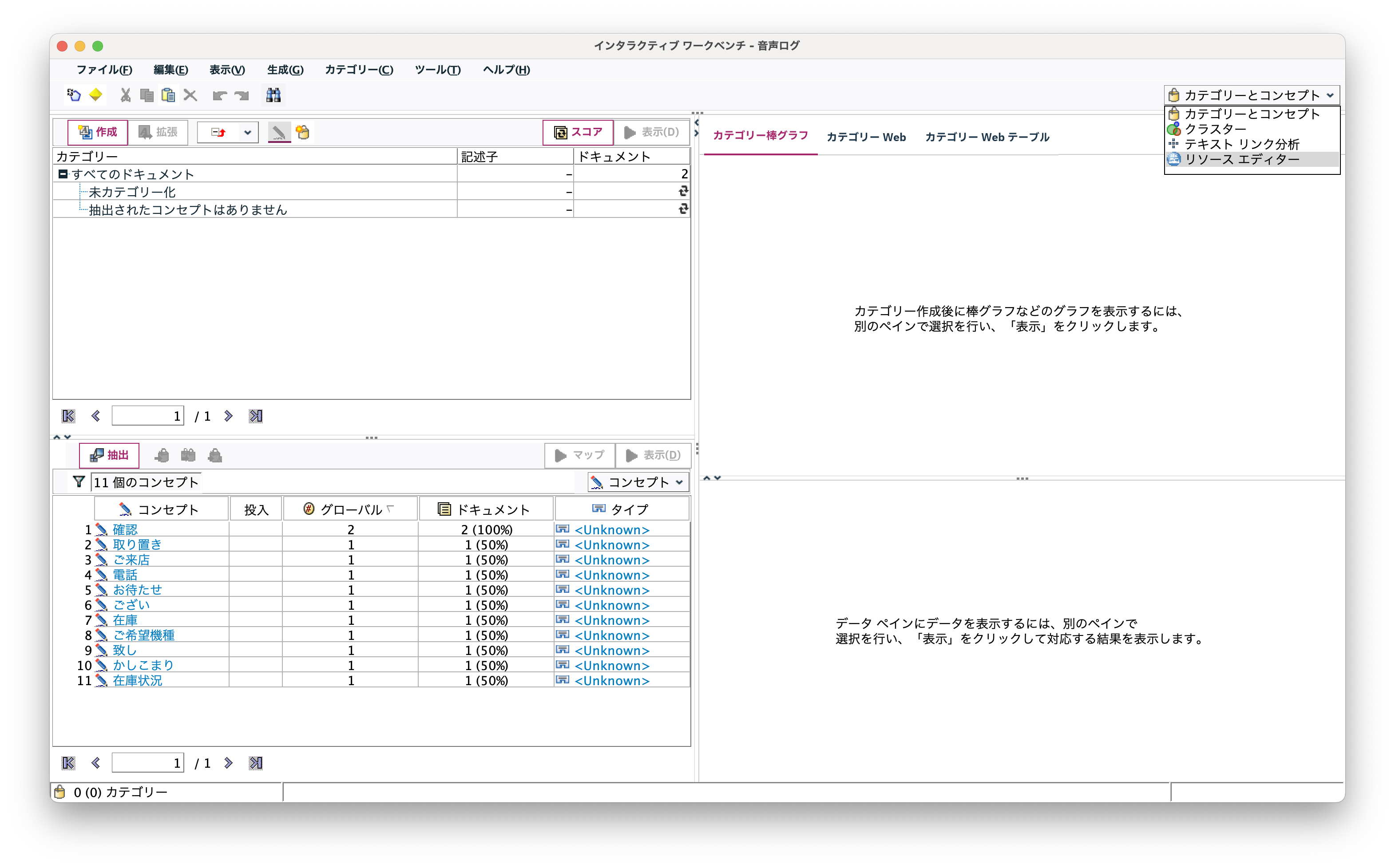
ユーザー辞書[ローカルライブラリー]のみを表示させます。
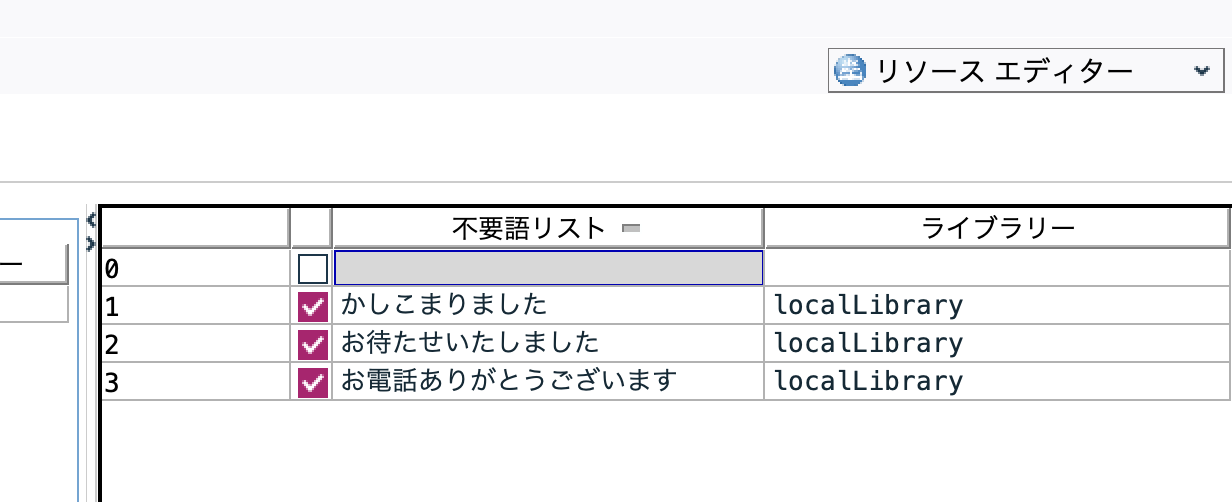
[不用語リスト]に3つの表現を記述します。
以下のように3つ登録して、元の[カテゴリーとコンセプト]画面に戻ります。
辞書が更新されたのでコンセプトが黄色くハイライト(辞書が未適用)になっています。
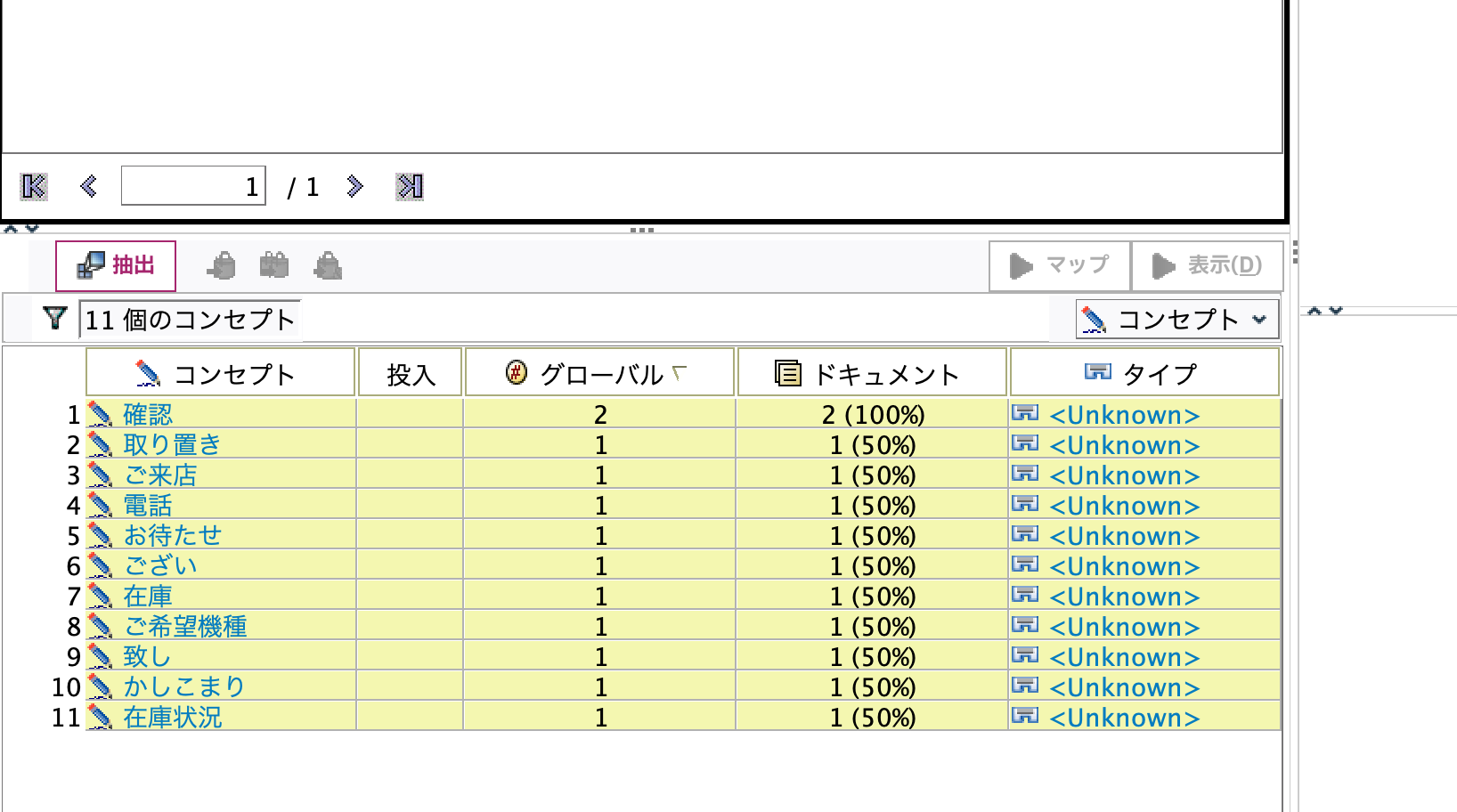
[抽出]ボタンを押します。不要語が除かれています。
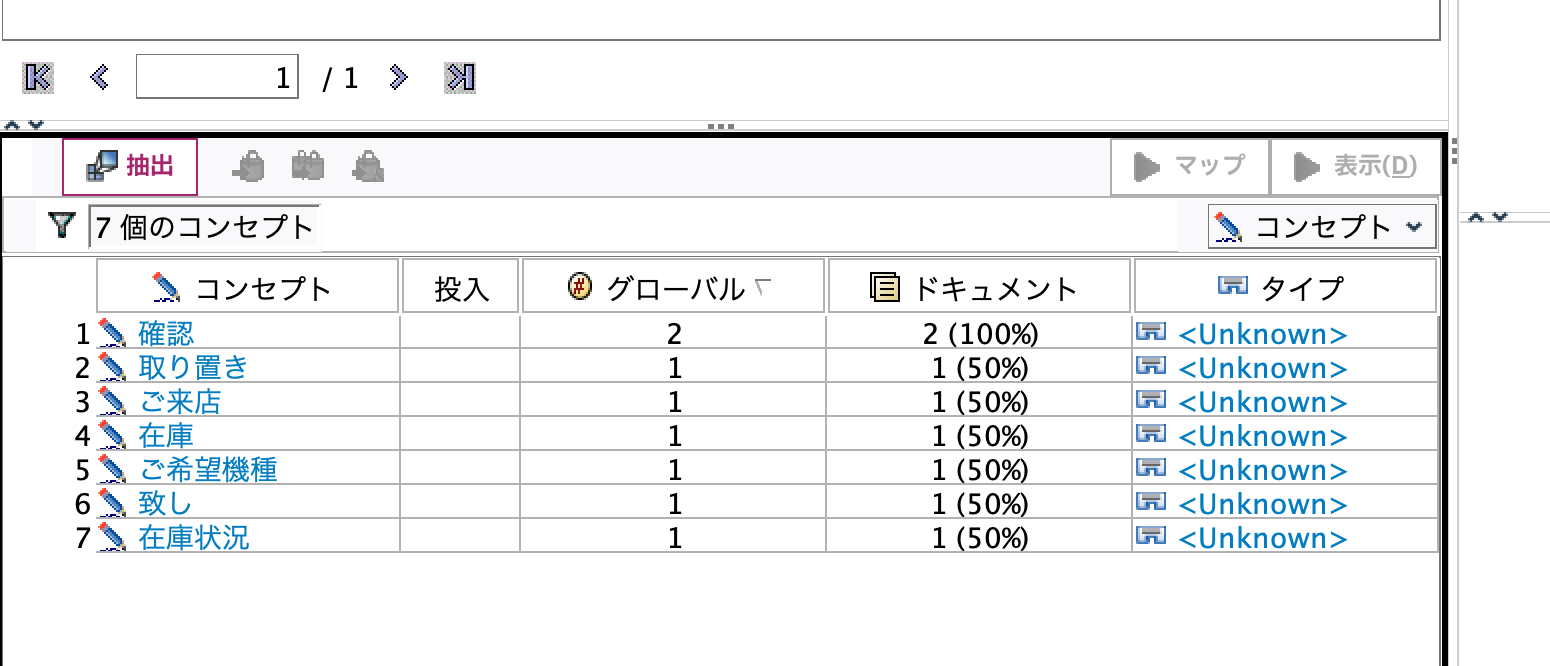
注意事項
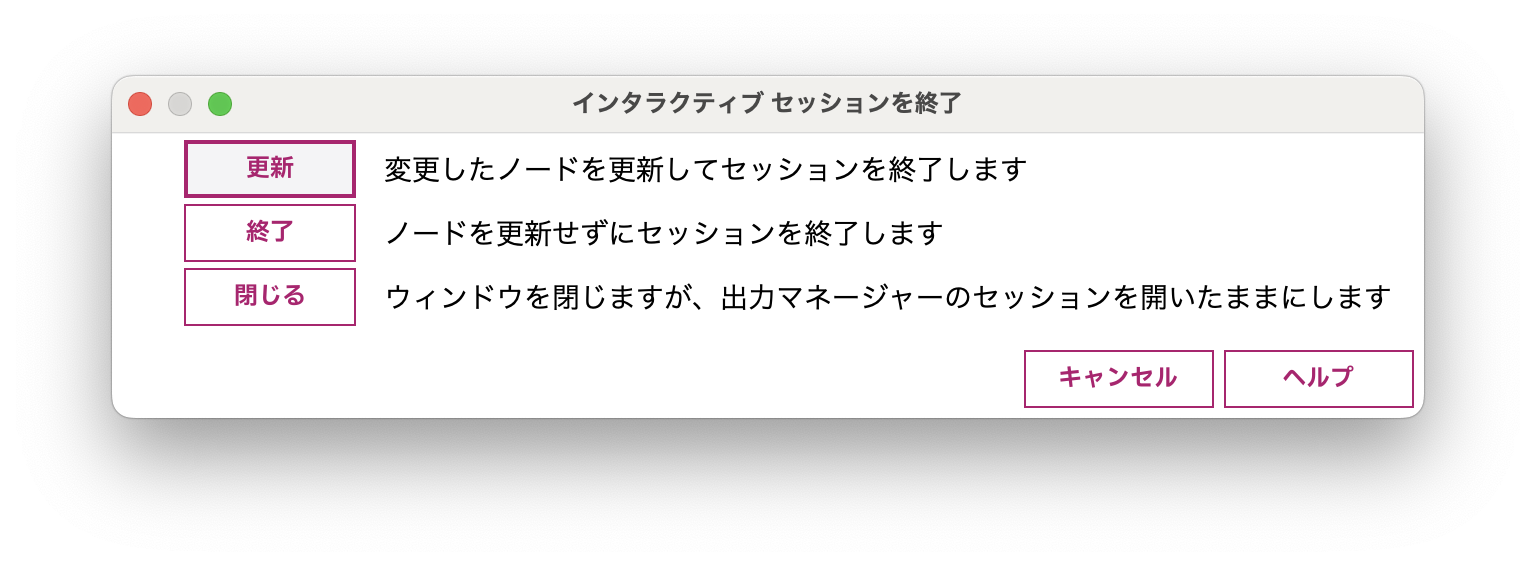
ローカル辞書を保存するにはインタラクティブセッション終了時に以下の[更新]を選択します。
チームメンバーと辞書を共有するにはライブラリに任意の名前をつけて公開/管理します。
4.参考情報
Python連携によるテキストマイニング
SPSS Modeler ノードリファレンス目次
SPSS Modeler 逆引きストリーム集(データ加工)