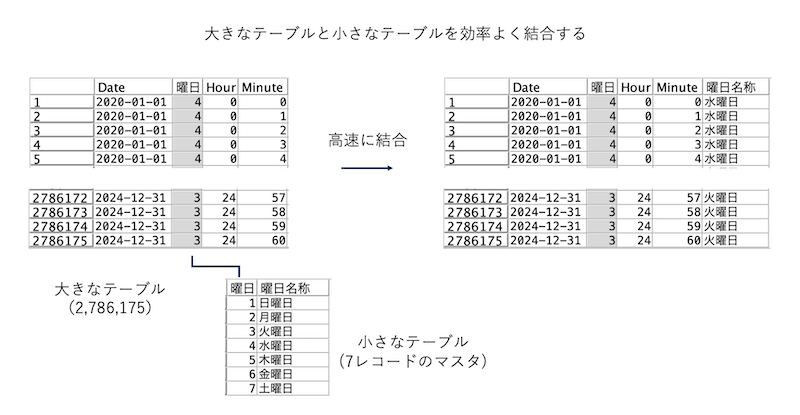
大きなテーブルと小さなテーブルを効率よく結合する
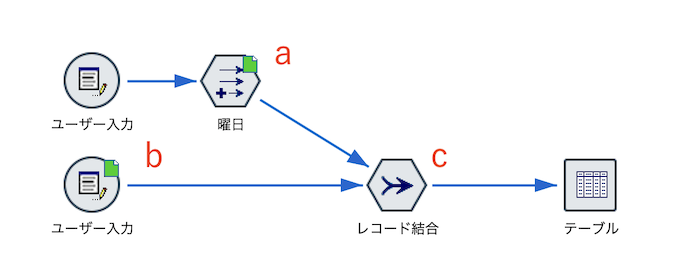
1.想定される利用目的
・なるべく高速に大きなテーブルを結合する(CSVなどのフラットファイルを想定)
2.サンプルストリームのダウンロード
3.サンプルストリームの説明
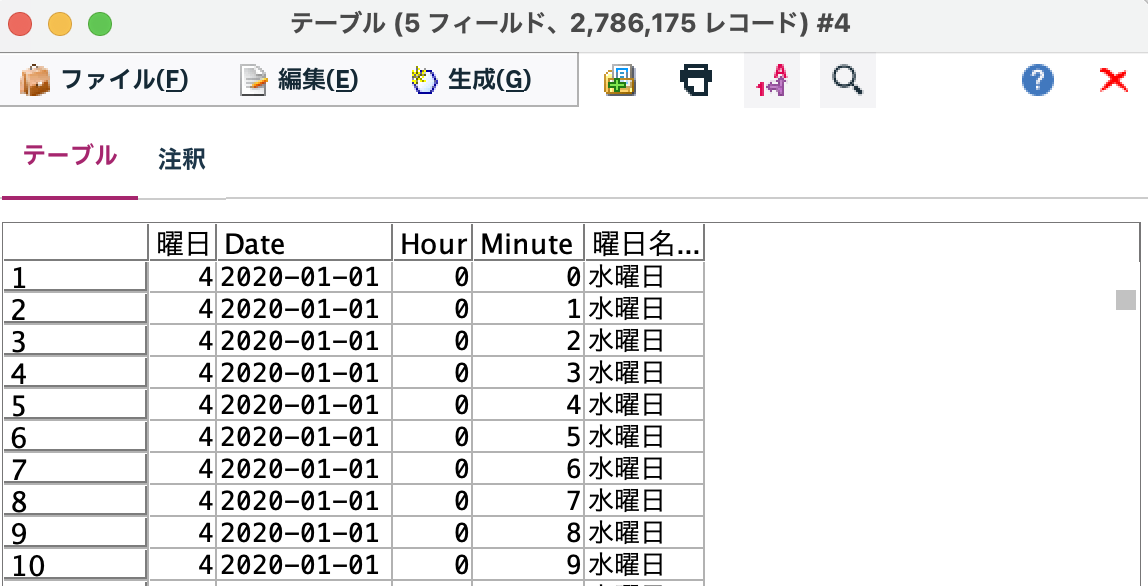
a.入力するデータのひとつめは以下の通りです。278万行の大規模なテーブルです。
b.入力するデータふたつめは以下の通りです。7行のマスタテーブルです。

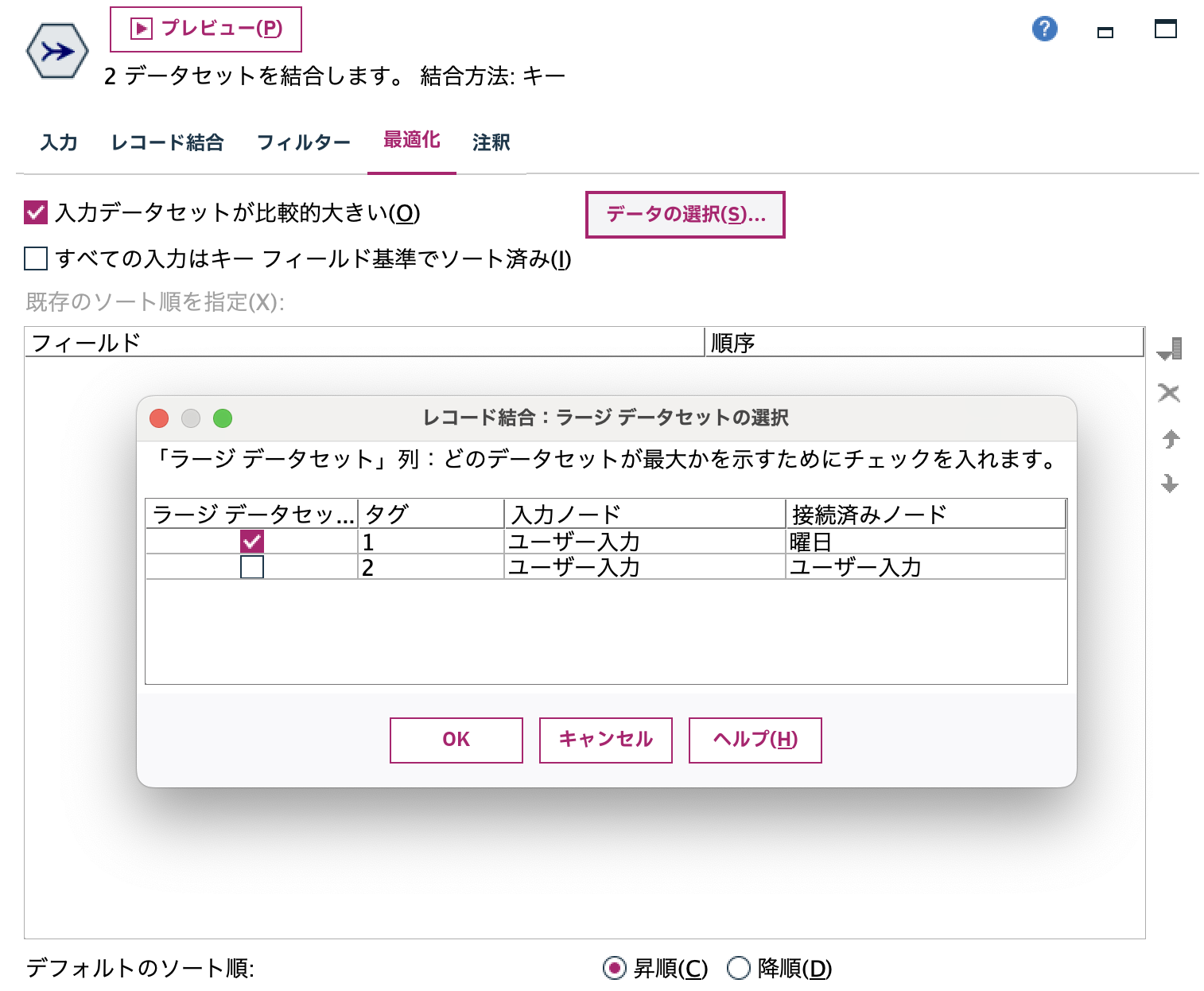
c.[レコード結合]ノードを編集します。曜日番号をキーにします。
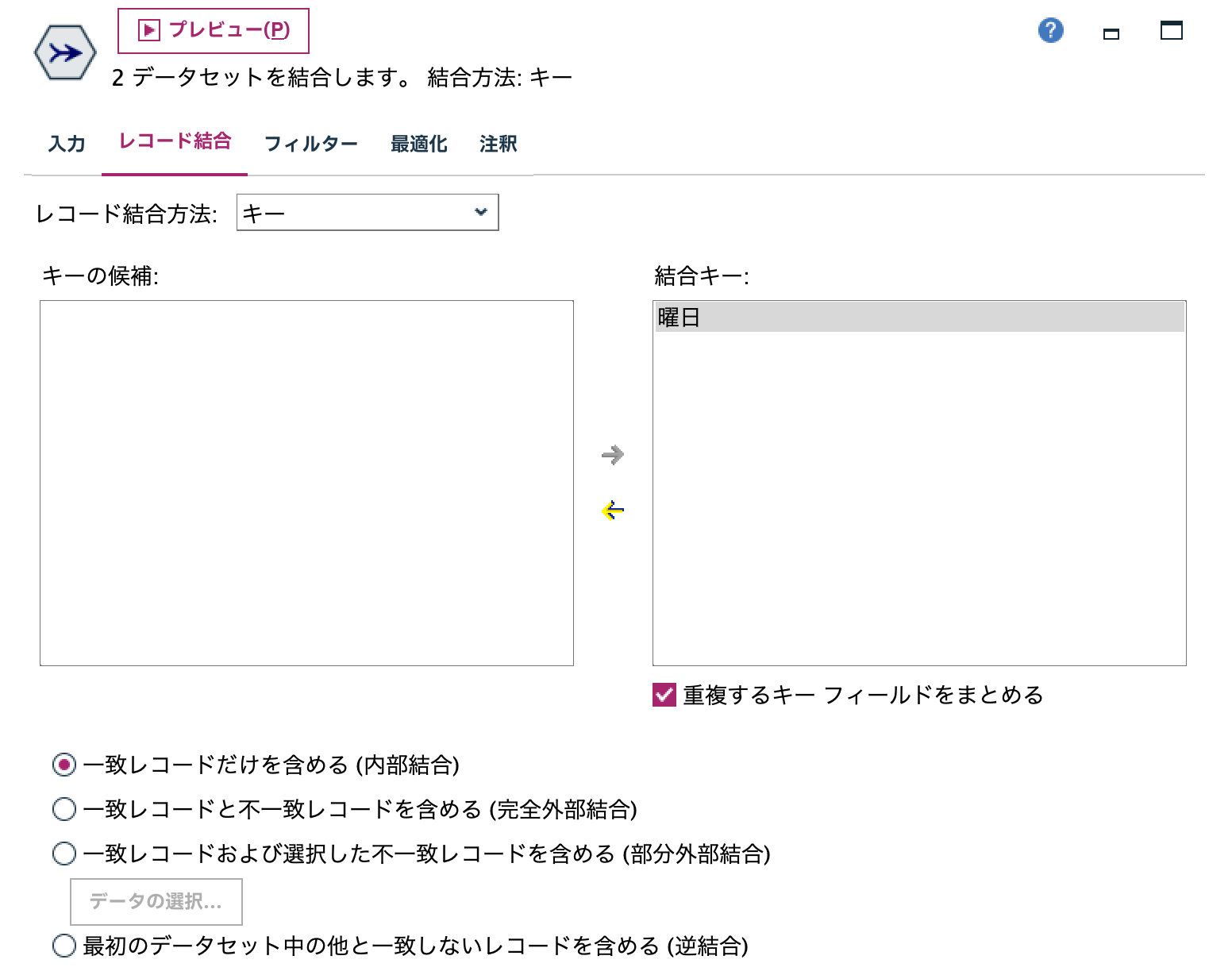
効率的に結合させるため[最適化]タブで大規模データの選択を行います。
[テーブル]を実行します。
サンプルストリームを最初に実行するとパターン3のキャッシュなしが該当します。

キャッシュのバッジがグリーンに点灯した状態で再度[テーブル]を実行するとパターン4になります。11秒であったため、「最適化なし」のパターン2と比較しても半分のスピードで結合が終了したことになります。

キャッシュの説明はこちらを参照してください。
注意事項
今回はフラットファイルのためにキャッシュを利用しましたが、DB接続のケースではキャッシュを外してSQLプッシュバックを想定した工夫を検討します。例えばDBによってはあらかじめテーブルサイズの統計を取ることで、今回と同じようように効率化を実現できます。
4.参考情報
レコード結合を解説した記事
SPSS Modeler ノードリファレンス目次
SPSS Modeler 逆引きストリーム集(データ加工)