ユーザー辞書で類義語を登録する
この記事はSPSS Modeler Premium Ver18.6から追加された日本語テキスト機能を利用して書いています。SPSS Modeler Professionalをお使いの方はアップグレードするかPython連携を用いて実現します。
Python連携を紹介する記事はこちら
1.想定される利用目的
・抽出されたコンセプトの時点で表記の揺れを正規化する
2.ストリームとデータのダウンロード
ストリーム
3.サンプルストリームの説明
a.入力データは以下の通りです。

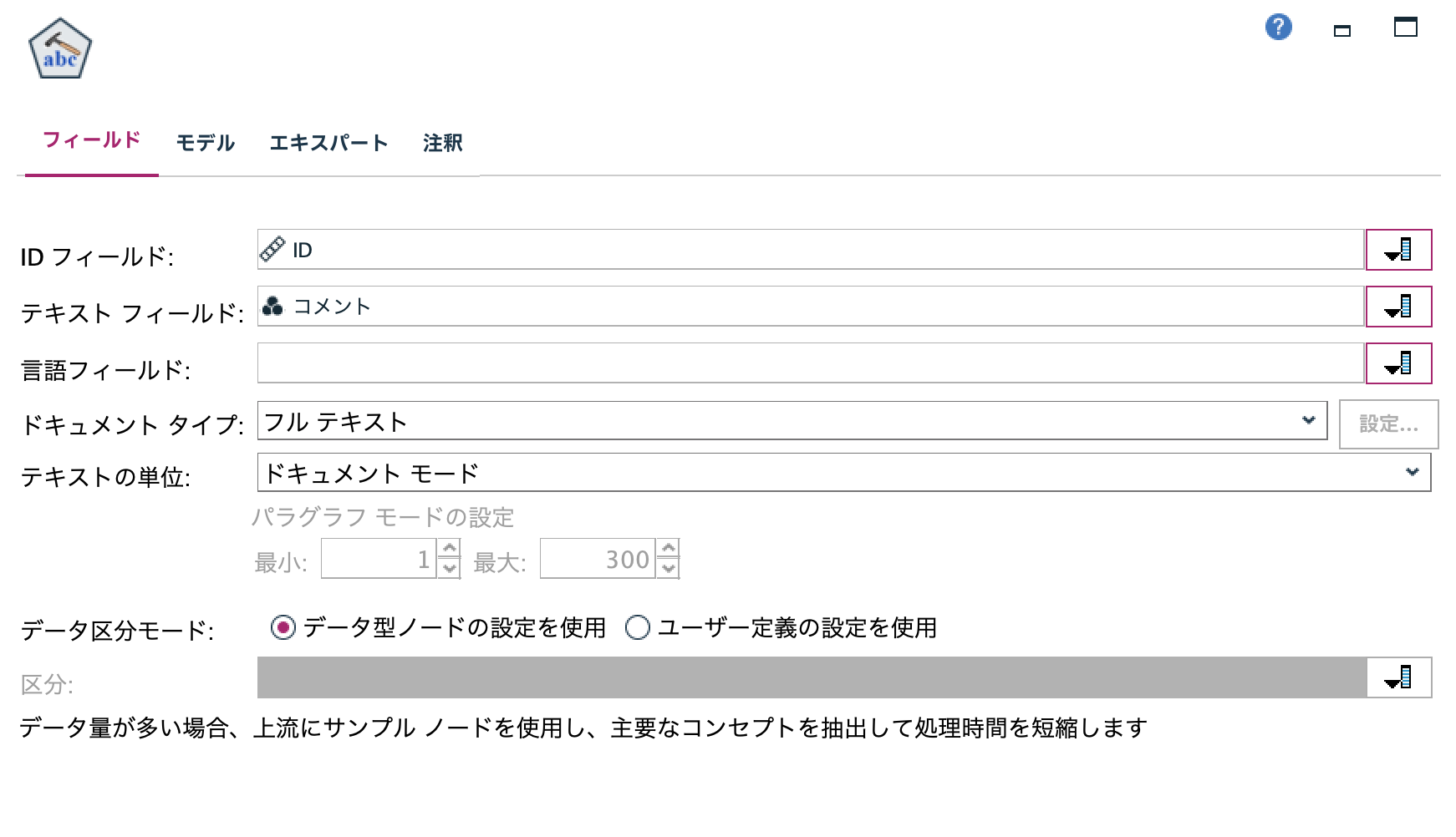
b.[テキストマイニング]ノードを編集します。[IDフィールド]と[テキストフィールド]を以下の通り選択します。
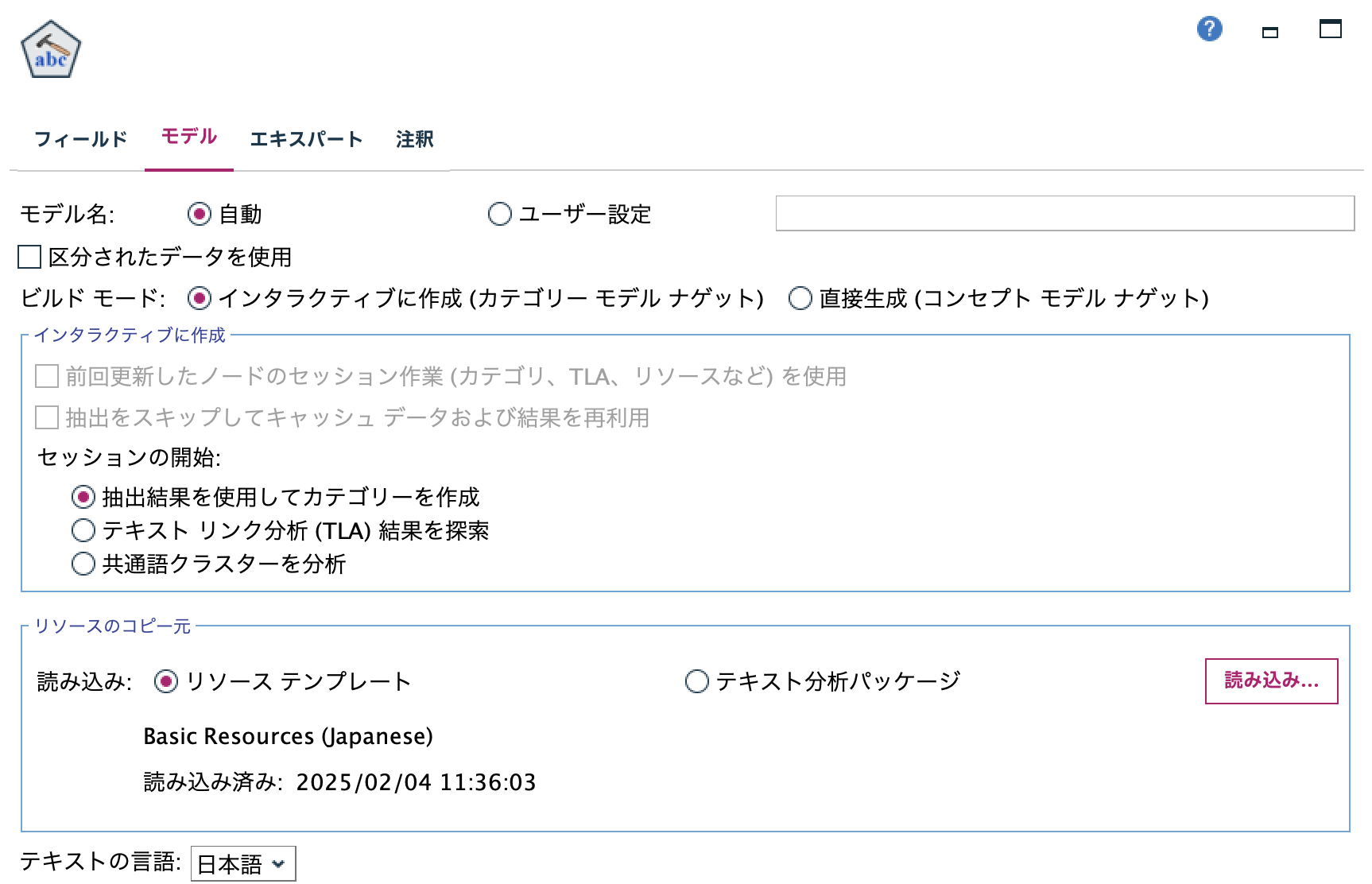
[モデル]タブを編集します。[抽出結果を利用して...]を選択します。
[実行]します。画面右上のドロップダウンリストから辞書[リソースエディター]を呼び出します。
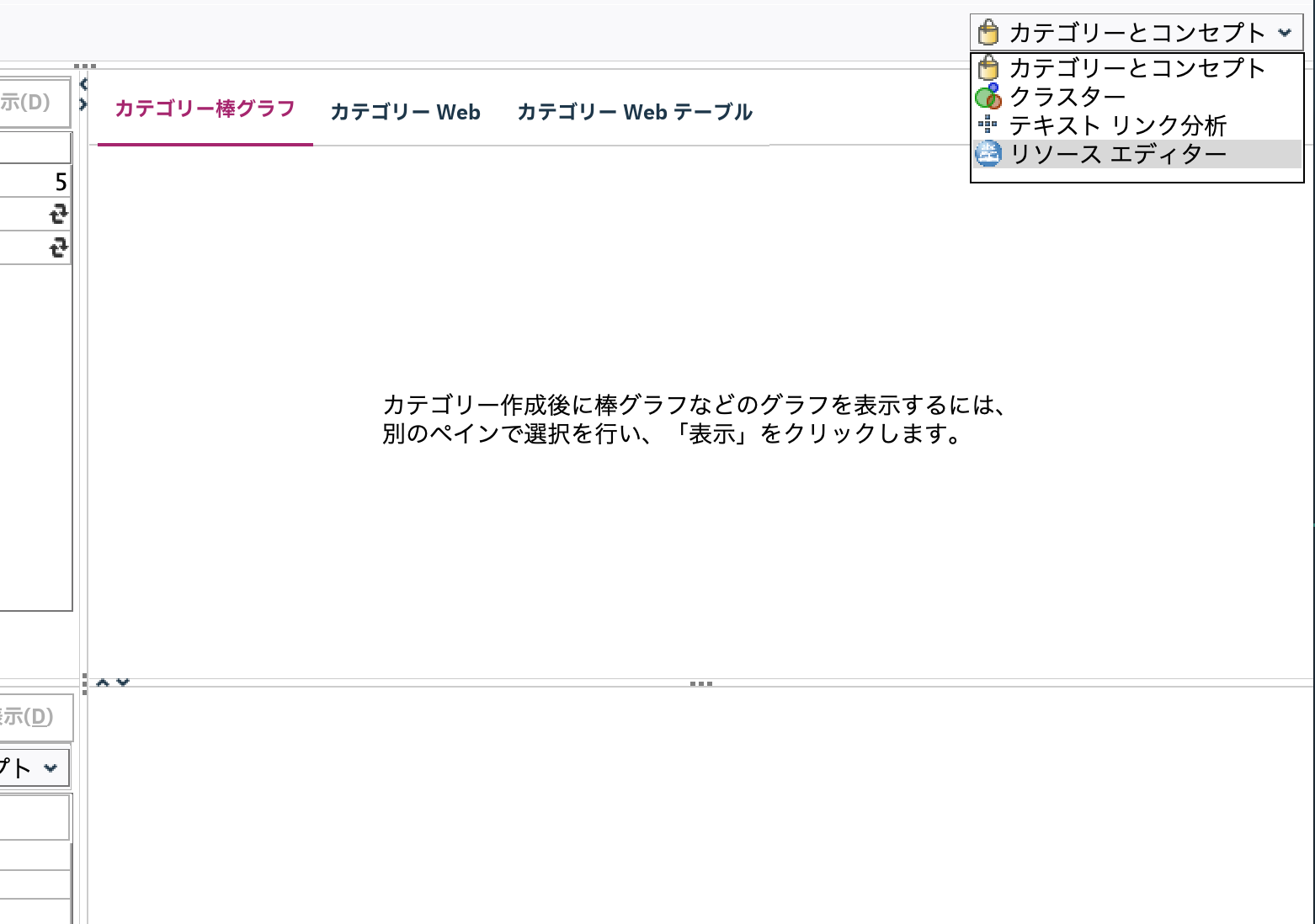
左上の辞書が3つアクティブになっていることを確認します。
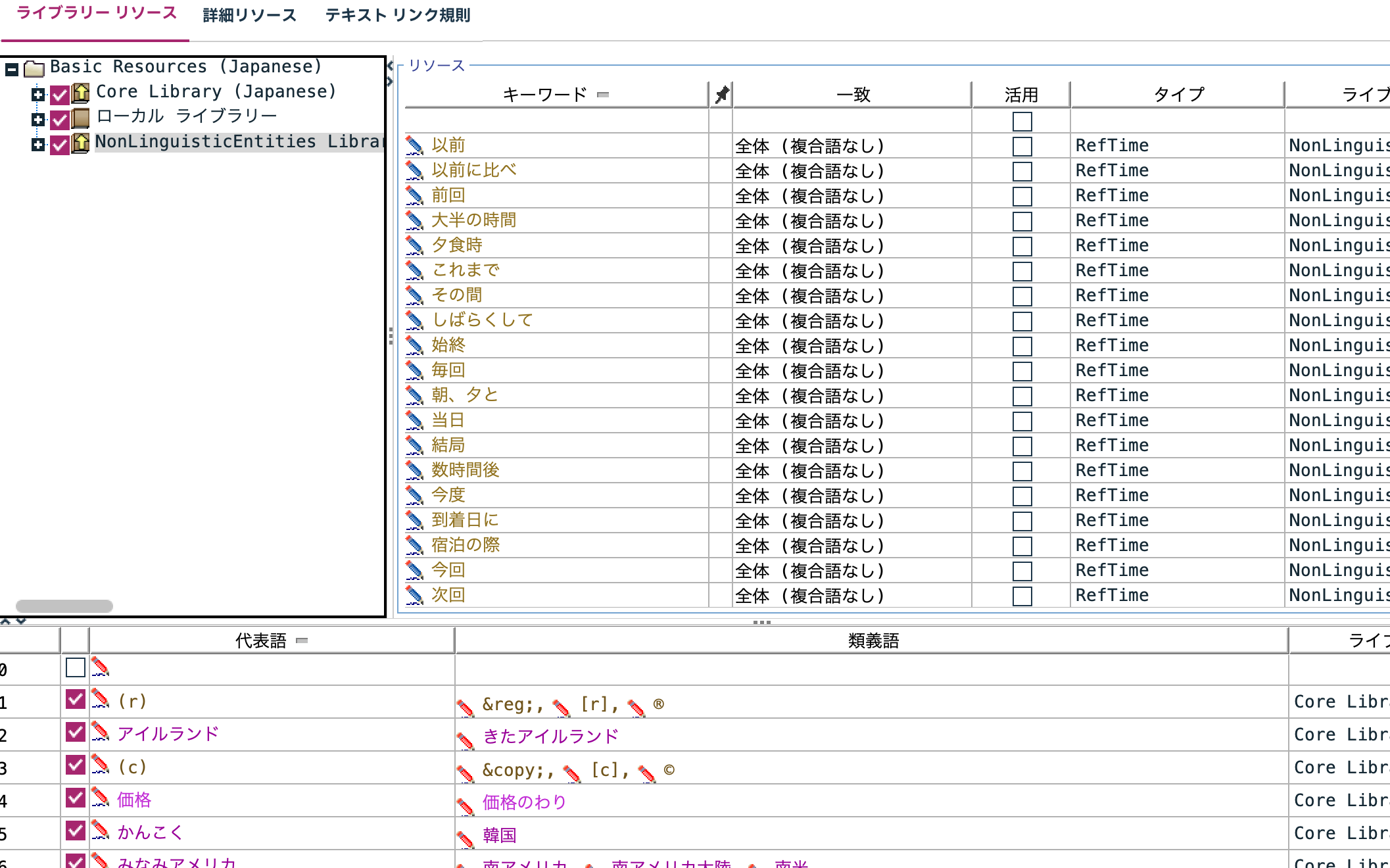
ユーザー辞書[ローカルライブラリー]のみを表示させます。
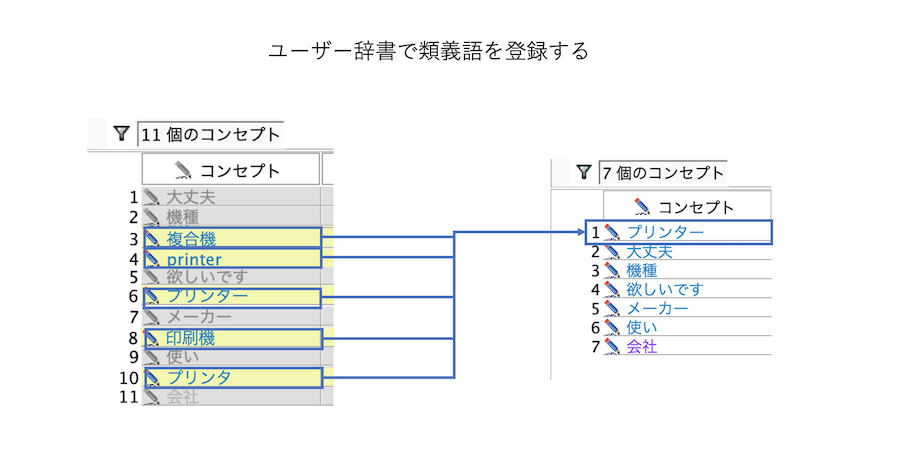
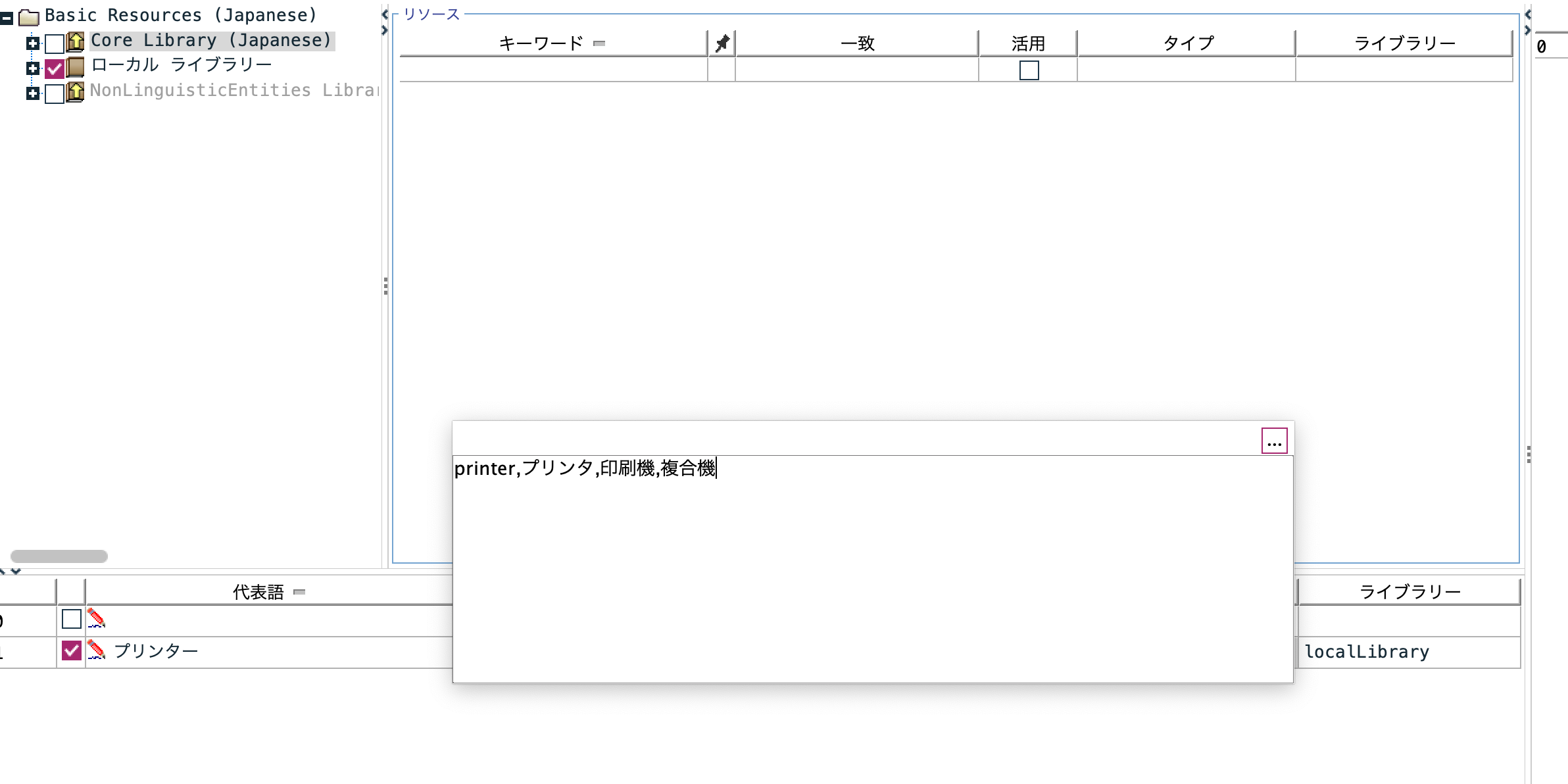
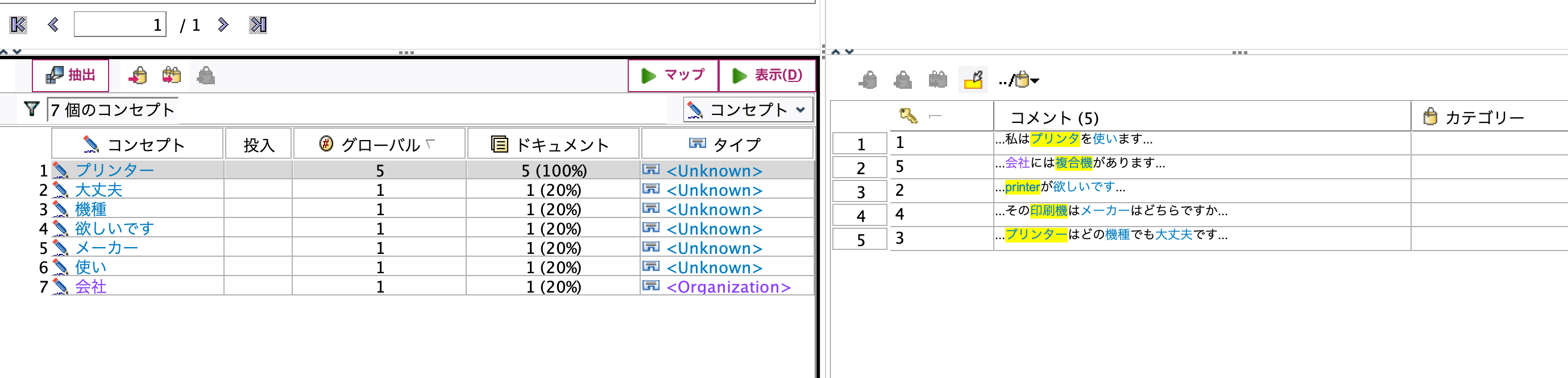
画面下部の類義語エリアで以下のように[代表語]を[プリンター]として[類義語]に[printer,プリンタ,印刷機,複合機]を登録します。
[リソースエディター]から[カテゴリーとコンセプト]に戻します。辞書が更新されたのでコンセプトが黄色く反転しています。
[抽出]ボタンを押します。表記揺れが正規化され、原文では異なっていてもコンセプトは[プリンター]で認識されます。
注意事項
表記揺れは必ずしも辞書で整えず、カテゴリに編成する際まとめたり、ストリーム上で処理することも可能です。目的と効率を考えて方法を選択します。
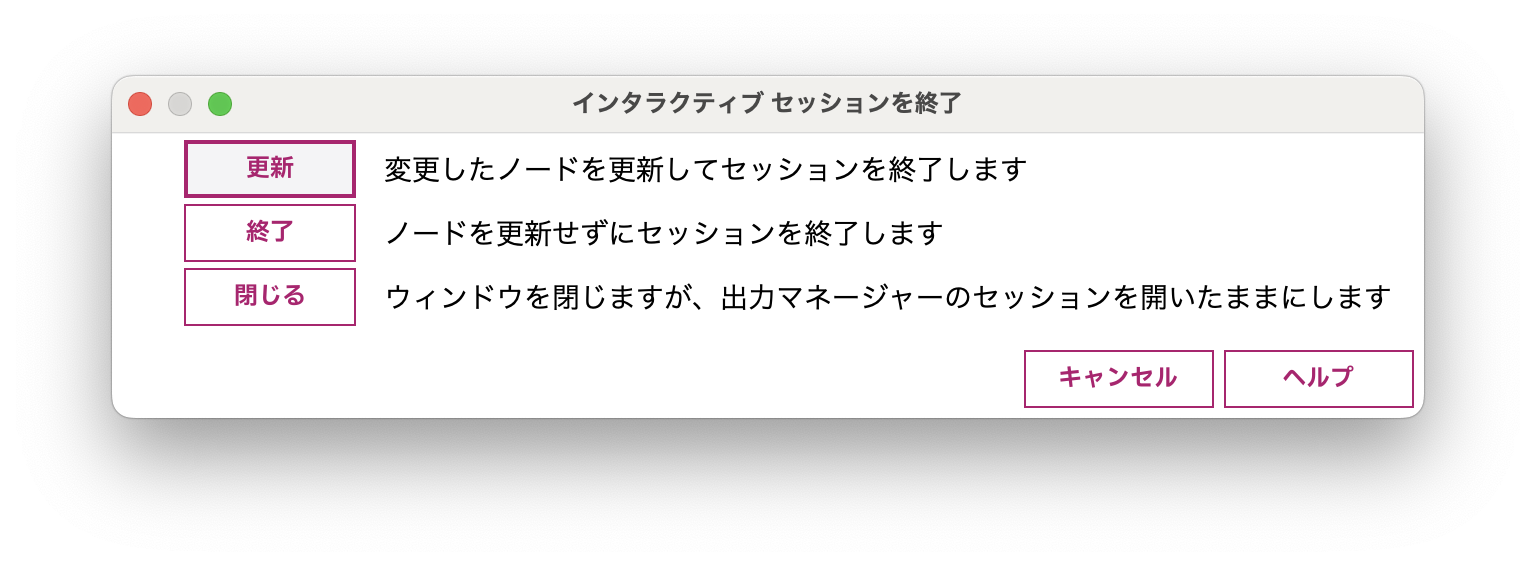
ローカル辞書を保存するにはインタラクティブセッション終了時に以下の[更新]を選択します。
チームメンバーと辞書を共有するにはライブラリに任意の名前をつけて公開/管理します。
4.参考情報
Python連携によるテキストマイニング
SPSS Modeler ノードリファレンス目次
SPSS Modeler 逆引きストリーム集(データ加工)