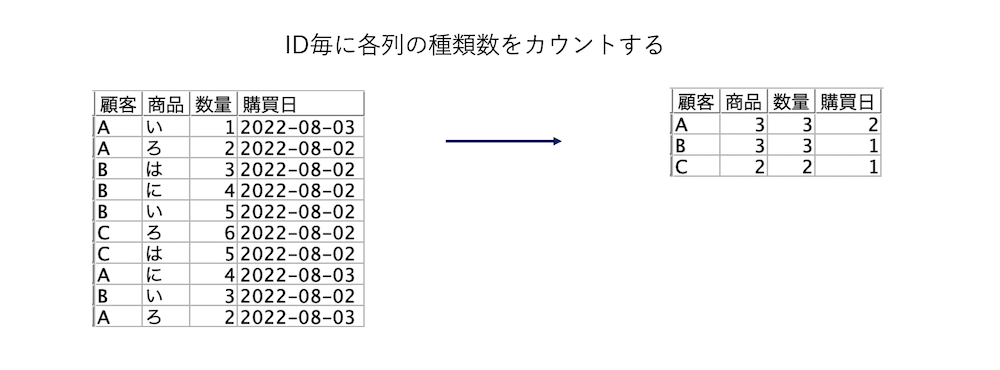
ID毎に各列に含まれる種類数をカウント(重複ノード)
1.想定される利用目的
・読み込んだデータの概要確認
・ID毎の特徴量作成
2.サンプルストリームのダウンロード
3.サンプルストリームの説明
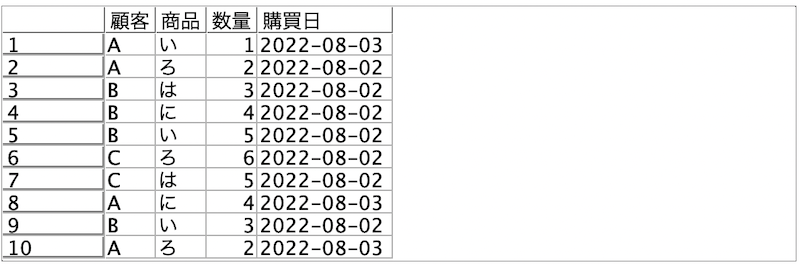
a.入力するデータは以下の通りです。
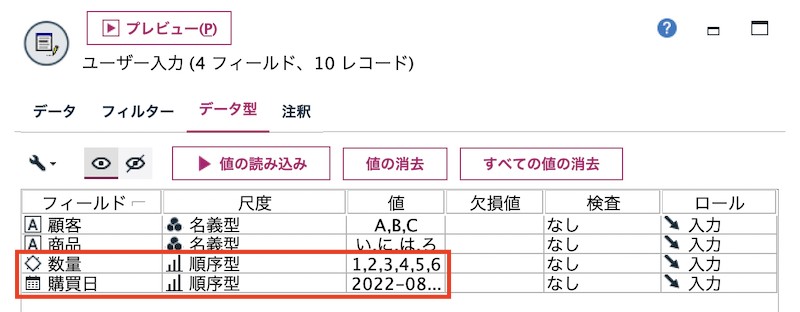
後続処理のために[データ型]タブで連続型を順序型に尺度の変更をしてから[値の読み込み]ボタンで確定します。
全てのレコード(行)で各フィールド(列)に含まれるユニークな種類数をカウントする
b.[データ検査]ノードを実行します。全てのレコードでの確認はこの方法が便利です。
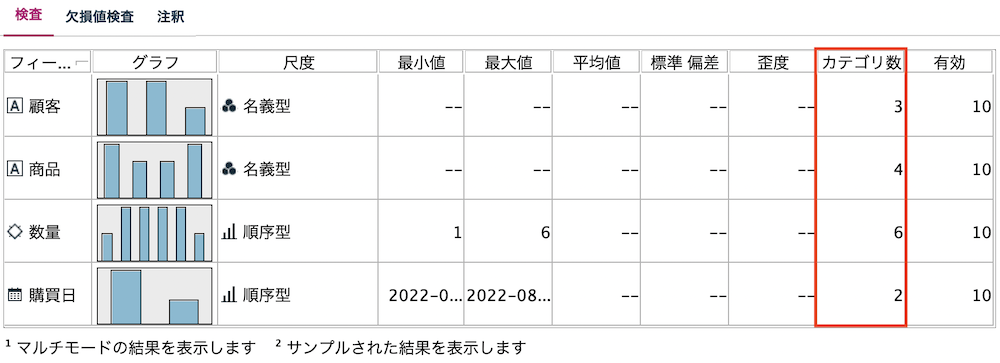
ID毎に各フィールド(列)に含まれるユニークな種類数をカウントする
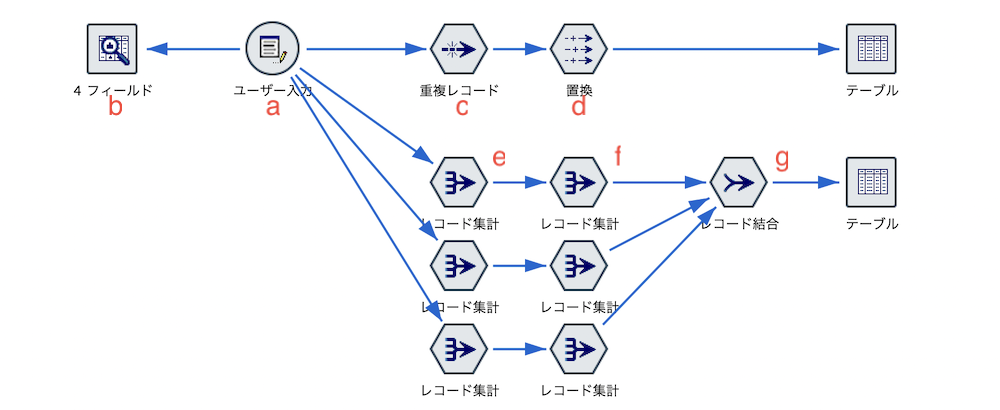
c.[重複]ノードを編集します。[グループ化のキーフィールド]を[顧客]にします。
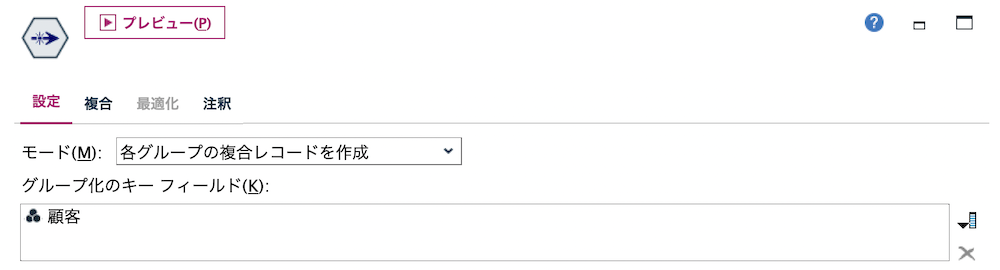
[複合]タブを編集します。
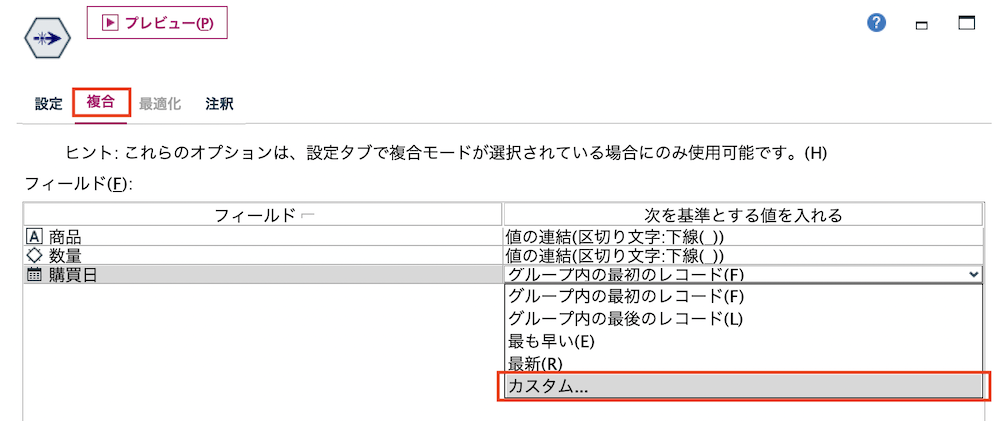
[カスタム]のダイアログで[区切り文字を使用]にチェックして[下線]を選択します。

[プレビュー]します。ID毎の商品、数量、購買日のユニークな種類数が1つのセルに下線で結合されて収まっています。

d.[データ検査]ノードを実行します。関数count_substring(@FIELD,"_")で下線の数を数えます。その値に1を加えるとユニークな種類数になります。@FIELDはワイルドカードで同時に複数のフィールドを同時に対象にできます。
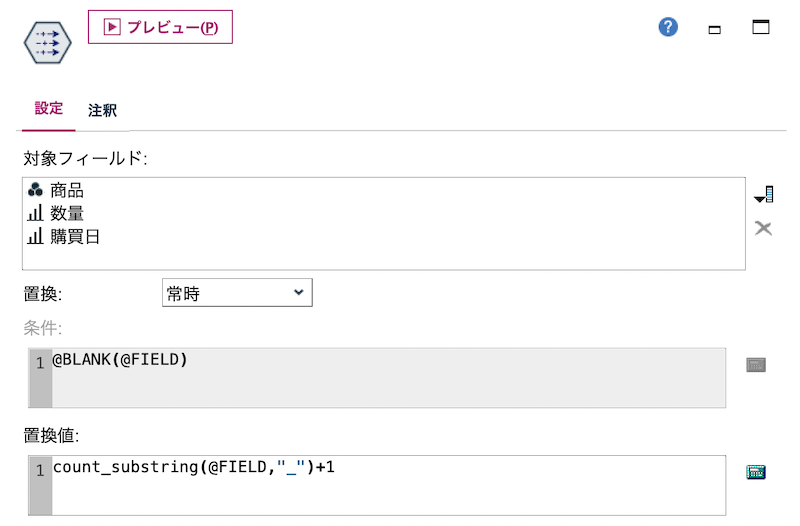
[プレビュー]します。
各列を分割して処理した結果をレコード結合する方法
e.[レコード集計]ノードを編集します。顧客と商品の組み合わせの重複を排除します。
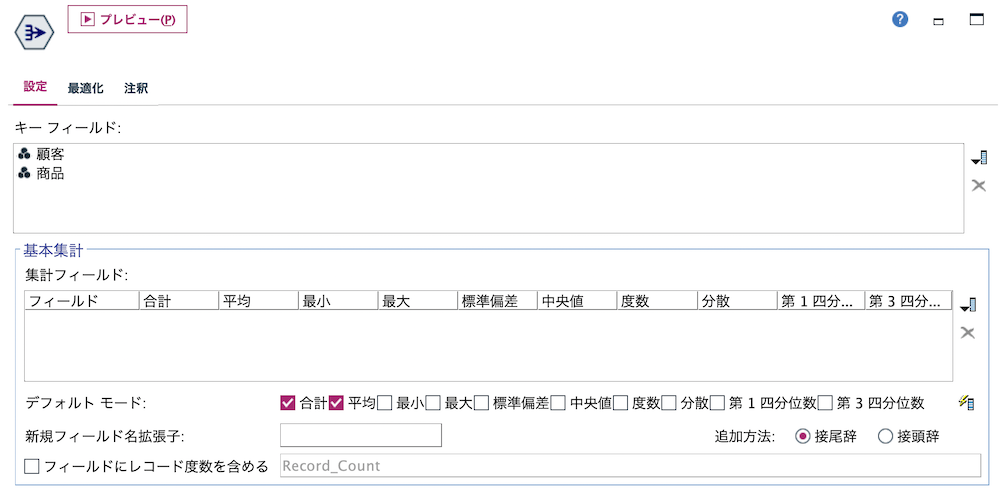
[プレビュー]します。

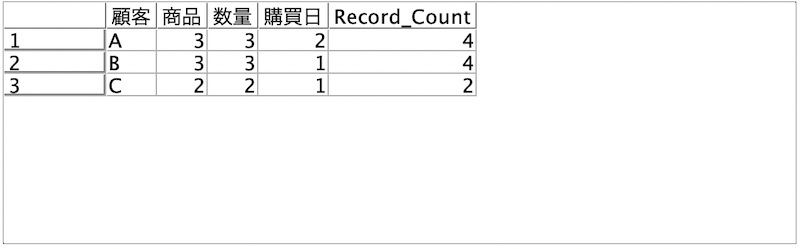
f.[レコード集計]ノードを編集します。[顧客]で集約しレコード数を[商品]にしています。
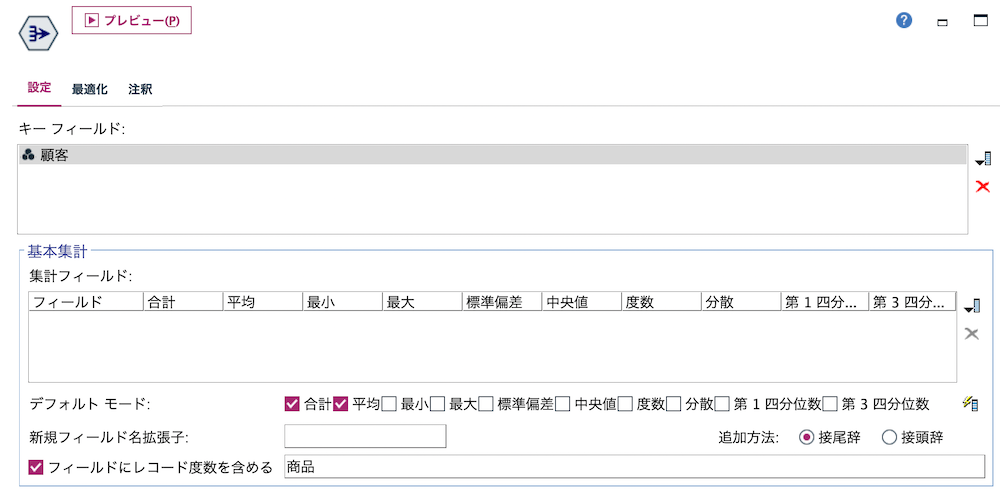
[プレビュー]します。顧客毎の[商品]の種類数が得られました。

商品と同じことを[数量]と[購買日]でも行います。
g.[レコード結合]ノードを編集します。[キーフィールド]を[顧客]に内部結合します。

[テーブル]ノードを実行します。

注意事項
重複ノードを利用する方法はセルに文字列を集めるため、文字数の長さや種類の数に注意してください。
含まれる値に下線(_)が含まれる場合には前処理でハイフンへの置き換え(関数はreplace)を行うか区切り文字の変更を検討してください。
250以上の種類が想定される場合には、あらかじめストリームのプロパティで設定します。
4.参考情報
[重複]ノードを扱った記事
SPSS Modeler ノードリファレンス目次
SPSS Modeler 逆引きストリーム集(データ加工)