はじめに
だんだん更新速度が遅くなってるなと思いながら,第3章の進捗です.
もし何かためになるアドバイス等があれば優しいコメントを残して頂けると幸いですm(_ _)m
(正規表現よくわからん...)
コードだけはコチラへ.
第3章: 正規表現
Wikipediaのページのマークアップ記述に正規表現を適用することで,様々な情報・知識を取り出します.
キーワード:正規表現, JSON, Wikipedia, InfoBox, ウェブサービス
Wikipediaの記事を以下のフォーマットで書き出したファイルjawiki-country.json.gzがある.
・1行に1記事の情報がJSON形式で格納される
・各行には記事名が"title"キーに,記事本文が"text"キーの辞書オブジェクトに格納され,そのオブジェクトがJSON形式で書き出される
・ファイル全体はgzipで圧縮される以下の処理を行うプログラムを作成せよ.
問題20 JSONデータの読み込み
Wikipedia記事のJSONファイルを読み込み,「イギリス」に関する記事本文を表示せよ.問題21-29では,ここで抽出した記事本文に対して実行せよ.
# !/usr/local/bin python3
# -*- coding: utf-8 -*-
import gzip
import json
def extract_text_from_wiki_gzip(in_filepath: str, key_title: str) -> str:
"""
titleをkeyに記事本文を抽出する関数
Parameter
----------
in_filepath, out_filepath: str
入力/出力ファイルパス
key_title: str
検索タイトル
Return
----------
該当のテキスト(存在しなければ'')
"""
with gzip.open(in_filepath, "rt", "utf-8") as in_file:
for line in in_file:
data = json.loads(line)
if data['title'] == key_title:
return data['text']
return ''
def main():
in_filepath = './jawiki-country.json.gz'
out_filepath = './UK.txt'
key_title = 'イギリス'
text = extract_text_from_wiki_gzip(in_filepath, key_title)
print(text)
# with open(out_filepath, 'w') as out_file:
# out_file.write(text)
if __name__ == '__main__':
main()
$ python3 20.py
{{redirect|UK}}
{{基礎情報 国
|略名 = イギリス
|日本語国名 = グレートブリテン及び北アイルランド連合王国
|公式国名 = {{lang|en|United Kingdom of Great Britain and Northern Ireland}}<ref>英語以外での正式国名:<br/>
*{{lang|gd|An Rìoghachd Aonaichte na Breatainn Mhòr agus Eirinn mu Thuath}}([[スコットランド・ゲール語]])<br/>
*{{lang|cy|Teyrnas Gyfunol Prydain Fawr a Gogledd Iwerddon}}([[ウェールズ語]])<br/>
*{{lang|ga|Ríocht Aontaithe na Breataine Móire agus Tuaisceart na hÉireann}}([[アイルランド語]])<br/>
*{{lang|kw|An Rywvaneth Unys a Vreten Veur hag Iwerdhon Glédh}}([[コーンウォール語]])<br/>
*{{lang|sco|Unitit Kinrick o Great Breetain an Northren Ireland}}([[スコットランド語]])<br/>
...
{{デフォルトソート:いきりす}}
[[Category:イギリス|*]]
[[Category:英連邦王国|*]]
[[Category:G8加盟国]]
[[Category:欧州連合加盟国]]
[[Category:海洋国家]]
[[Category:君主国]]
[[Category:島国|くれいとふりてん]]
[[Category:1801年に設立された州・地域]]
問題21 カテゴリ名を含む行を抽出
記事中でカテゴリ名を宣言している行を抽出せよ.
# !/usr/local/bin python3
# -*- coding: utf-8 -*-
import gzip
import json
import re
def extract_category_lines(text: str) -> list:
"""
カテゴリーの行を記事本文テキストから抽出する関数
Parameter
----------
text: str
wikipediaの記事本文
Return
----------
category_lines: str
カテゴリの行のリスト
"""
category_lines = []
text_split = text.split('\n')
for line in text_split:
if 'Category:' in line:
category_lines.append(line)
return category_lines
def extract_text_from_wiki_gzip(in_filepath: str, key_title: str) -> str:
"""
省略
"""
def main():
in_filepath = './jawiki-country.json.gz'
out_filepath = './UK.txt'
key_title = 'イギリス'
text = extract_text_from_wiki_gzip(in_filepath, key_title)
category_lines = extract_category_lines(text)
print(' / '.join(category_lines))
if __name__ == '__main__':
main()
$ python3 21.py
[[Category:イギリス|*]] / [[Category:英連邦王国|*]] / [[Category:G8加盟国]] / [[Category:欧州連合加盟国]] / [[Category:海洋国家]] / [[Category:君主国]] / [[Category:島国|くれいとふりてん]] / [[Category:1801年に設立された州・地域]]
問題22 カテゴリ名の抽出
記事のカテゴリ名を(行単位ではなく名前で)抽出せよ.
# !/usr/local/bin python3
# -*- coding: utf-8 -*-
import gzip
import json
import re
def extract_category_lines(text: str) -> list:
"""
省略
"""
def extract_category_from_lines(category_lines: list) -> list:
"""
カテゴリ名をカテゴリーの行から抽出する関数
Parameter
----------
category_lines: list
カテゴリー行
Return
----------
categories: list
カテゴリー名
"""
categories = []
for line in category_lines:
categories.append(re.search(r'^\[\[Category:(.+?)(|\|.+)\]\]$', line).group(1))
return categories
def extract_text_from_wiki_gzip(in_filepath: str, key_title: str) -> str:
"""
省略
"""
def main():
in_filepath = './jawiki-country.json.gz'
out_filepath = './UK.txt'
key_title = 'イギリス'
text = extract_text_from_wiki_gzip(in_filepath, key_title)
category_lines = extract_category_lines(text)
categories = extract_category_from_lines(category_lines)
print(' / '.join(categories))
if __name__ == '__main__':
main()
$ python3 22.py
イギリス / 英連邦王国 / G8加盟国 / 欧州連合加盟国 / 海洋国家 / 君主国 / 島国 / 1801年に設立された州・地域
問題23 セクション構造
記事中に含まれるセクション名とそのレベル(例えば"== セクション名 =="なら1)を表示せよ.
# !/usr/local/bin python3
# -*- coding: utf-8 -*-
import gzip
import json
import re
def extract_sections(text: str) -> list:
"""
記事データからセクション名とその深さの対を返す関数
Parameter
----------
text: str
wikipedia記事
Return
----------
section_names: list
セクション名と深さの辞書を格納するリスト
"""
section_names = []
text_split = text.split('\n')
for line in text_split:
m = re.search(r'^(=+)(.+?)=+?$', line)
if m:
section_names.append({m.group(2): int(len(m.group(1))) - 1})
return section_names
def extract_text_from_wiki_gzip(in_filepath: str, key_title: str) -> str:
"""
省略
"""
def main():
in_filepath = './jawiki-country.json.gz'
out_filepath = './UK.txt'
key_title = 'イギリス'
text = extract_text_from_wiki_gzip(in_filepath, key_title)
section_names = extract_sections(text)
for el in section_names:
print(el)
if __name__ == '__main__':
main()
$ python3 23.py
{'国名': 1}
{'歴史': 1}
{'地理': 1}
{'気候': 2}
{'政治': 1}
{'外交と軍事': 1}
{'地方行政区分': 1}
{'主要都市': 2}
{'科学技術': 1}
{'経済': 1}
{'鉱業': 2}
{'農業': 2}
{'貿易': 2}
{'通貨': 2}
{'企業': 2}
{'交通': 1}
{'道路': 2}
{'鉄道': 2}
{'海運': 2}
{'航空': 2}
{'通信': 1}
{'国民': 1}
{'言語': 2}
{'宗教': 2}
{' 婚姻 ': 2}
{'教育': 2}
{'文化': 1}
{'食文化': 2}
{'文学': 2}
{' 哲学 ': 2}
{'音楽': 2}
{'イギリスのポピュラー音楽': 3}
{'映画': 2}
{'コメディ': 2}
{'国花': 2}
{'世界遺産': 2}
{'祝祭日': 2}
{'スポーツ': 1}
{'サッカー': 2}
{'競馬': 2}
{'モータースポーツ': 2}
{'脚注': 1}
{'関連項目': 1}
{'外部リンク': 1}
問題24 ファイル参照の抽出
記事から参照されているメディアファイルをすべて抜き出せ.
# !/usr/local/bin python3
# -*- coding: utf-8 -*-
import gzip
import json
import re
def extract_mediafiles(text: str) -> list:
"""
記事データからメディアファイルを抽出する関数
Parameter
----------
text: str
wikipedia記事
Return
----------
mediafiles: list
メディアファイル名のリスト
"""
mediafiles = []
text_split = text.split('\n')
for line in text_split:
m = re.search(r'(File|ファイル):(.+?)\|', line)
if m:
mediafiles.append(m.group(2))
return mediafiles
def extract_text_from_wiki_gzip(in_filepath: str, key_title: str) -> str:
"""
省略
"""
def main():
in_filepath = './jawiki-country.json.gz'
out_filepath = './UK.txt'
key_title = 'イギリス'
text = extract_text_from_wiki_gzip(in_filepath, key_title)
mediafiles = extract_mediafiles(text)
for el in mediafiles:
print(el)
if __name__ == '__main__':
main()
$ python3 24.py
Royal Coat of Arms of the United Kingdom.svg
Battle of Waterloo 1815.PNG
The British Empire.png
Uk topo en.jpg
BenNevis2005.jpg
Elizabeth II greets NASA GSFC employees, May 8, 2007 edit.jpg
Palace of Westminster, London - Feb 2007.jpg
David Cameron and Barack Obama at the G20 Summit in Toronto.jpg
Soldiers Trooping the Colour, 16th June 2007.jpg
Scotland Parliament Holyrood.jpg
London.bankofengland.arp.jpg
City of London skyline from London City Hall - Oct 2008.jpg
Oil platform in the North SeaPros.jpg
Eurostar at St Pancras Jan 2008.jpg
Heathrow T5.jpg
Anglospeak.svg
CHANDOS3.jpg
The Fabs.JPG
PalaceOfWestminsterAtNight.jpg
Westminster Abbey - West Door.jpg
Edinburgh Cockburn St dsc06789.jpg
Canterbury Cathedral - Portal Nave Cross-spire.jpeg
Kew Gardens Palm House, London - July 2009.jpg
2005-06-27 - United Kingdom - England - London - Greenwich.jpg
Stonehenge2007 07 30.jpg
Yard2.jpg
Durham Kathedrale Nahaufnahme.jpg
Roman Baths in Bath Spa, England - July 2006.jpg
Fountains Abbey view02 2005-08-27.jpg
Blenheim Palace IMG 3673.JPG
Liverpool Pier Head by night.jpg
Hadrian's Wall view near Greenhead.jpg
London Tower (1).JPG
Wembley Stadium, illuminated.jpg
問題25 テンプレートの抽出
記事中に含まれる「基礎情報」テンプレートのフィールド名と値を抽出し,辞書オブジェクトとして格納せよ.
# !/usr/local/bin python3
# -*- coding: utf-8 -*-
import gzip
import json
import re
def extract_basic_info(text: str) -> list:
"""
記事データから基礎情報を抽出する関数
Parameter
----------
text: str
wikipedia記事
Return
----------
basic_info: list
メディアファイル名のリスト
"""
pre_idx = ''
basic_info = {}
basic_info_text = re.search(r'^\{\{基礎情報.*?$(.*?)^\}\}$', text, flags=(re.MULTILINE | re.DOTALL)).group(1)
splited_text = [line for line in basic_info_text.split('\n') if line != '']
for line in splited_text:
if line[0] == '|':
m = re.search('^\|(.+?)\s=\s(.+?)$', line)
basic_info[m.group(1)] = m.group(2)
pre_idx = m.group(1)
else:
basic_info[pre_idx] += line.rstrip('\n')
return basic_info
def extract_text_from_wiki_gzip(in_filepath: str, key_title: str) -> str:
"""
省略
"""
def main():
in_filepath = './jawiki-country.json.gz'
out_filepath = './UK.txt'
key_title = 'イギリス'
text = extract_text_from_wiki_gzip(in_filepath, key_title)
basic_info = extract_basic_info(text)
for k, v in basic_info.items():
print('{}: {}'.format(k, v))
if __name__ == '__main__':
main()
$ python3 25.py
略名: イギリス
日本語国名: グレートブリテン及び北アイルランド連合王国
公式国名: {{lang|en|United Kingdom of Great Britain and Northern Ireland}}<ref>英語以外での正式国名:<br/>*{{lang|gd|An Rìoghachd Aonaichte na Breatainn Mhòr agus Eirinn mu Thuath}}([[スコットランド・ゲール語]])<br/>*{{lang|cy|Teyrnas Gyfunol Prydain Fawr a Gogledd Iwerddon}}([[ウェールズ語]])<br/>*{{lang|ga|Ríocht Aontaithe na Breataine Móire agus Tuaisceart na hÉireann}}([[アイルランド語]])<br/>*{{lang|kw|An Rywvaneth Unys a Vreten Veur hag Iwerdhon Glédh}}([[コーンウォール語]])<br/>*{{lang|sco|Unitit Kinrick o Great Breetain an Northren Ireland}}([[スコットランド語]])<br/>**{{lang|sco|Claught Kängrick o Docht Brätain an Norlin Airlann}}、{{lang|sco|Unitet Kängdom o Great Brittain an Norlin Airlann}}(アルスター・スコットランド語)</ref>
国旗画像: Flag of the United Kingdom.svg
国章画像: [[ファイル:Royal Coat of Arms of the United Kingdom.svg|85px|イギリスの国章]]
国章リンク: ([[イギリスの国章|国章]])
標語: {{lang|fr|Dieu et mon droit}}<br/>([[フランス語]]:神と私の権利)
国歌: [[女王陛下万歳|神よ女王陛下を守り給え]]
位置画像: Location_UK_EU_Europe_001.svg
公用語: [[英語]](事実上)
首都: [[ロンドン]]
最大都市: ロンドン
元首等肩書: [[イギリスの君主|女王]]
元首等氏名: [[エリザベス2世]]
首相等肩書: [[イギリスの首相|首相]]
首相等氏名: [[デーヴィッド・キャメロン]]
面積順位: 76
面積大きさ: 1 E11
面積値: 244,820
水面積率: 1.3%
人口統計年: 2011
人口順位: 22
人口大きさ: 1 E7
人口値: 63,181,775<ref>[http://esa.un.org/unpd/wpp/Excel-Data/population.htm United Nations Department of Economic and Social Affairs>Population Division>Data>Population>Total Population]</ref>
人口密度値: 246
GDP統計年元: 2012
GDP値元: 1兆5478億<ref name="imf-statistics-gdp">[http://www.imf.org/external/pubs/ft/weo/2012/02/weodata/weorept.aspx?pr.x=70&pr.y=13&sy=2010&ey=2012&scsm=1&ssd=1&sort=country&ds=.&br=1&c=112&s=NGDP%2CNGDPD%2CPPPGDP%2CPPPPC&grp=0&a= IMF>Data and Statistics>World Economic Outlook Databases>By Countrise>United Kingdom]</ref>
GDP統計年MER: 2012
GDP順位MER: 5
GDP値MER: 2兆4337億<ref name="imf-statistics-gdp" />
GDP統計年: 2012
GDP順位: 6
GDP値: 2兆3162億<ref name="imf-statistics-gdp" />
GDP/人: 36,727<ref name="imf-statistics-gdp" />
建国形態: 建国
確立形態1: [[イングランド王国]]/[[スコットランド王国]]<br />(両国とも[[連合法 (1707年)|1707年連合法]]まで)
確立年月日1: [[927年]]/[[843年]]
確立形態2: [[グレートブリテン王国]]建国<br />([[連合法 (1707年)|1707年連合法]])
確立年月日2: [[1707年]]
確立形態3: [[グレートブリテン及びアイルランド連合王国]]建国<br />([[連合法 (1800年)|1800年連合法]])
確立年月日3: [[1801年]]
確立形態4: 現在の国号「'''グレートブリテン及び北アイルランド連合王国'''」に変更
確立年月日4: [[1927年]]
通貨: [[スターリング・ポンド|UKポンド]] (£)
通貨コード: GBP
時間帯: ±0
夏時間: +1
ISO 3166-1: GB / GBR
ccTLD: [[.uk]] / [[.gb]]<ref>使用は.ukに比べ圧倒的少数。</ref>
国際電話番号: 44
注記: <references />
問題26 強調マークアップの除去
25の処理時に,テンプレートの値からMediaWikiの強調マークアップ(弱い強調,強調,強い強調のすべて)を除去してテキストに変換せよ(参考: マークアップ早見表).
# !/usr/local/bin python3
# -*- coding: utf-8 -*-
import gzip
import json
import re
def extract_basic_info(text: str) -> list:
"""
省略
"""
def extract_text_from_wiki_gzip(in_filepath: str, key_title: str) -> str:
"""
省略
"""
def remove_italic_and_bold(basic_info: dict) -> dict:
"""
基本情報から太字と斜体を取り除く関数
Parameter
----------
basic_info: dict
基本情報
Return
----------
basic_info_wo_italic_bold: dict
強調が除去された基本
"""
basic_info_wo_markup = {}
for k, v in basic_info.items():
basic_info_wo_markup[k] = re.sub(r'(\'{2,5})(.*?)(\'{2,5})', r'\2', v)
return basic_info_wo_markup
def main():
in_filepath = './jawiki-country.json.gz'
out_filepath = './UK.txt'
key_title = 'イギリス'
text = extract_text_from_wiki_gzip(in_filepath, key_title)
basic_info = extract_basic_info(text)
basic_info_wo_markup = remove_italic_and_bold(basic_info)
for k, v in basic_info_wo_markup.items():
print('{}: {}'.format(k, v))
if __name__ == '__main__':
main()
$ python3 26.py
略名: イギリス
日本語国名: グレートブリテン及び北アイルランド連合王国
公式国名: {{lang|en|United Kingdom of Great Britain and Northern Ireland}}<ref>英語以外での正式国名:<br/>*{{lang|gd|An Rìoghachd Aonaichte na Breatainn Mhòr agus Eirinn mu Thuath}}([[スコットランド・ゲール語]])<br/>*{{lang|cy|Teyrnas Gyfunol Prydain Fawr a Gogledd Iwerddon}}([[ウェールズ語]])<br/>*{{lang|ga|Ríocht Aontaithe na Breataine Móire agus Tuaisceart na hÉireann}}([[アイルランド語]])<br/>*{{lang|kw|An Rywvaneth Unys a Vreten Veur hag Iwerdhon Glédh}}([[コーンウォール語]])<br/>*{{lang|sco|Unitit Kinrick o Great Breetain an Northren Ireland}}([[スコットランド語]])<br/>**{{lang|sco|Claught Kängrick o Docht Brätain an Norlin Airlann}}、{{lang|sco|Unitet Kängdom o Great Brittain an Norlin Airlann}}(アルスター・スコットランド語)</ref>
国旗画像: Flag of the United Kingdom.svg
国章画像: [[ファイル:Royal Coat of Arms of the United Kingdom.svg|85px|イギリスの国章]]
国章リンク: ([[イギリスの国章|国章]])
標語: {{lang|fr|Dieu et mon droit}}<br/>([[フランス語]]:神と私の権利)
国歌: [[女王陛下万歳|神よ女王陛下を守り給え]]
位置画像: Location_UK_EU_Europe_001.svg
公用語: [[英語]](事実上)
首都: [[ロンドン]]
最大都市: ロンドン
元首等肩書: [[イギリスの君主|女王]]
元首等氏名: [[エリザベス2世]]
首相等肩書: [[イギリスの首相|首相]]
首相等氏名: [[デーヴィッド・キャメロン]]
面積順位: 76
面積大きさ: 1 E11
面積値: 244,820
水面積率: 1.3%
人口統計年: 2011
人口順位: 22
人口大きさ: 1 E7
人口値: 63,181,775<ref>[http://esa.un.org/unpd/wpp/Excel-Data/population.htm United Nations Department of Economic and Social Affairs>Population Division>Data>Population>Total Population]</ref>
人口密度値: 246
GDP統計年元: 2012
GDP値元: 1兆5478億<ref name="imf-statistics-gdp">[http://www.imf.org/external/pubs/ft/weo/2012/02/weodata/weorept.aspx?pr.x=70&pr.y=13&sy=2010&ey=2012&scsm=1&ssd=1&sort=country&ds=.&br=1&c=112&s=NGDP%2CNGDPD%2CPPPGDP%2CPPPPC&grp=0&a= IMF>Data and Statistics>World Economic Outlook Databases>By Countrise>United Kingdom]</ref>
GDP統計年MER: 2012
GDP順位MER: 5
GDP値MER: 2兆4337億<ref name="imf-statistics-gdp" />
GDP統計年: 2012
GDP順位: 6
GDP値: 2兆3162億<ref name="imf-statistics-gdp" />
GDP/人: 36,727<ref name="imf-statistics-gdp" />
建国形態: 建国
確立形態1: [[イングランド王国]]/[[スコットランド王国]]<br />(両国とも[[連合法 (1707年)|1707年連合法]]まで)
確立年月日1: [[927年]]/[[843年]]
確立形態2: [[グレートブリテン王国]]建国<br />([[連合法 (1707年)|1707年連合法]])
確立年月日2: [[1707年]]
確立形態3: [[グレートブリテン及びアイルランド連合王国]]建国<br />([[連合法 (1800年)|1800年連合法]])
確立年月日3: [[1801年]]
確立形態4: 現在の国号「グレートブリテン及び北アイルランド連合王国」に変更
確立年月日4: [[1927年]]
通貨: [[スターリング・ポンド|UKポンド]] (£)
通貨コード: GBP
時間帯: ±0
夏時間: +1
ISO 3166-1: GB / GBR
ccTLD: [[.uk]] / [[.gb]]<ref>使用は.ukに比べ圧倒的少数。</ref>
国際電話番号: 44
注記: <references />
問題27 内部リンクの除去
26の処理に加えて,テンプレートの値からMediaWikiの内部リンクマークアップを除去し,テキストに変換せよ(参考: マークアップ早見表).
# !/usr/local/bin python3
# -*- coding: utf-8 -*-
import gzip
import json
import re
def extract_basic_info(text: str) -> list:
"""
省略
"""
def extract_text_from_wiki_gzip(in_filepath: str, key_title: str) -> str:
"""
省略
"""
def remove_italic_and_bold(basic_info: dict) -> dict:
"""
省略
"""
def remove_internal_link(basic_info: dict) -> dict:
"""
基本情報から内部リンクマークアップを取り除く関数
Parameter
----------
basic_info: dict
基本情報
Return
----------
basic_info_wo_internal_link: dict
内部リンクマークアップが除去された基本情報
"""
basic_info_wo_internal_link = {}
pattern1 = re.compile(r'\[\[([^|]+?)\]\]')
pattern2 = re.compile(r'\[\[([^:]+?)\|(.+?)\]\]')
for k, v in basic_info.items():
basic_info_wo_internal_link[k] = re.sub(pattern2, r'\2', re.sub(pattern1, r'\1', v))
return basic_info_wo_internal_link
def main():
in_filepath = './jawiki-country.json.gz'
out_filepath = './UK.txt'
key_title = 'イギリス'
text = extract_text_from_wiki_gzip(in_filepath, key_title)
basic_info = extract_basic_info(text)
basic_info_wo_italic_bold = remove_italic_and_bold(basic_info)
basic_info_wo_internal_link = remove_internal_link(basic_info_wo_italic_bold)
for k, v in basic_info_wo_internal_link.items():
print('{}: {}'.format(k, v))
if __name__ == '__main__':
main()
$ python3 27.py
略名: イギリス
日本語国名: グレートブリテン及び北アイルランド連合王国
公式国名: {{lang|en|United Kingdom of Great Britain and Northern Ireland}}<ref>英語以外での正式国名:<br/>*{{lang|gd|An Rìoghachd Aonaichte na Breatainn Mhòr agus Eirinn mu Thuath}}(スコットランド・ゲール語)<br/>*{{lang|cy|Teyrnas Gyfunol Prydain Fawr a Gogledd Iwerddon}}(ウェールズ語)<br/>*{{lang|ga|Ríocht Aontaithe na Breataine Móire agus Tuaisceart na hÉireann}}(アイルランド語)<br/>*{{lang|kw|An Rywvaneth Unys a Vreten Veur hag Iwerdhon Glédh}}(コーンウォール語)<br/>*{{lang|sco|Unitit Kinrick o Great Breetain an Northren Ireland}}(スコットランド語)<br/>**{{lang|sco|Claught Kängrick o Docht Brätain an Norlin Airlann}}、{{lang|sco|Unitet Kängdom o Great Brittain an Norlin Airlann}}(アルスター・スコットランド語)</ref>
国旗画像: Flag of the United Kingdom.svg
国章画像: [[ファイル:Royal Coat of Arms of the United Kingdom.svg|85px|イギリスの国章]]
国章リンク: (国章)
標語: {{lang|fr|Dieu et mon droit}}<br/>(フランス語:神と私の権利)
国歌: 神よ女王陛下を守り給え
位置画像: Location_UK_EU_Europe_001.svg
公用語: 英語(事実上)
首都: ロンドン
最大都市: ロンドン
元首等肩書: 女王
元首等氏名: エリザベス2世
首相等肩書: 首相
首相等氏名: デーヴィッド・キャメロン
面積順位: 76
面積大きさ: 1 E11
面積値: 244,820
水面積率: 1.3%
人口統計年: 2011
人口順位: 22
人口大きさ: 1 E7
人口値: 63,181,775<ref>[http://esa.un.org/unpd/wpp/Excel-Data/population.htm United Nations Department of Economic and Social Affairs>Population Division>Data>Population>Total Population]</ref>
人口密度値: 246
GDP統計年元: 2012
GDP値元: 1兆5478億<ref name="imf-statistics-gdp">[http://www.imf.org/external/pubs/ft/weo/2012/02/weodata/weorept.aspx?pr.x=70&pr.y=13&sy=2010&ey=2012&scsm=1&ssd=1&sort=country&ds=.&br=1&c=112&s=NGDP%2CNGDPD%2CPPPGDP%2CPPPPC&grp=0&a= IMF>Data and Statistics>World Economic Outlook Databases>By Countrise>United Kingdom]</ref>
GDP統計年MER: 2012
GDP順位MER: 5
GDP値MER: 2兆4337億<ref name="imf-statistics-gdp" />
GDP統計年: 2012
GDP順位: 6
GDP値: 2兆3162億<ref name="imf-statistics-gdp" />
GDP/人: 36,727<ref name="imf-statistics-gdp" />
建国形態: 建国
確立形態1: イングランド王国/スコットランド王国<br />(両国とも1707年連合法まで)
確立年月日1: 927年/843年
確立形態2: グレートブリテン王国建国<br />(1707年連合法)
確立年月日2: 1707年
確立形態3: グレートブリテン及びアイルランド連合王国建国<br />(1800年連合法)
確立年月日3: 1801年
確立形態4: 現在の国号「グレートブリテン及び北アイルランド連合王国」に変更
確立年月日4: 1927年
通貨: UKポンド (£)
通貨コード: GBP
時間帯: ±0
夏時間: +1
ISO 3166-1: GB / GBR
ccTLD: .uk / .gb<ref>使用は.ukに比べ圧倒的少数。</ref>
国際電話番号: 44
注記: <references />
問題28 MediaWikiマークアップの除去
27の処理に加えて,テンプレートの値からMediaWikiマークアップを可能な限り除去し,国の基本情報を整形せよ.
# !/usr/local/bin python3
# -*- coding: utf-8 -*-
import gzip
import json
import re
def extract_basic_info(text: str) -> list:
"""
省略
"""
def extract_text_from_wiki_gzip(in_filepath: str, key_title: str) -> str:
"""
省略
"""
def remove_external_link(basic_info: dict) -> dict:
"""
基本情報から外部リンクマークアップを取り除く関数
Parameter
---------
basic_info: dict
基本情報
Return
----------
basic_info_wo_external_link: str
外部リンクマークアップが除去された基本情報
"""
basic_info_wo_external_link = {}
pattern1 = re.compile(r'\[https??.+?\]')
pattern2 = re.compile(r'\[https??://.+?\s(.+?)\]')
for k, v in basic_info.items():
basic_info_wo_external_link[k] = re.sub(pattern1, r'', re.sub(pattern2, r'\1', v))
return basic_info_wo_external_link
def remove_file(basic_info: dict) -> dict:
"""
基本情報からファイルマークアップを取り除く関数
Parameter
----------
basic_info: dict
基本情報
Return
----------
basic_info_wo_file: dict
ファイルマークアップが除去された基本情報
"""
basic_info_wo_file = {}
for k, v in basic_info.items():
basic_info_wo_file[k] = re.sub(r'\[\[(File|ファイル):.+?\|.+?\|(.+?)\]\]', r'\2', v)
return basic_info_wo_file
def remove_html_tag(basic_info: dict) -> dict:
"""
基本情報からhtmlタグを取り除く関数
Parameter
----------
basic_info: dict
基本情報
Return
----------
basic_info_wo_html_tag: dict
htmlタグが除去された基本情報
"""
basic_info_wo_html_tag = {}
for k, v in basic_info.items():
basic_info_wo_html_tag[k] = re.sub(r'<(.+?)>', r'', v)
return basic_info_wo_html_tag
def remove_italic_and_bold(basic_info: dict) -> dict:
"""
省略
"""
def remove_internal_link(basic_info: dict) -> dict:
"""
省略
"""
def remove_lang(basic_info: dict) -> dict:
"""
基本情報から言語マークアップを取り除く関数
Parameter
----------
basic_info: dict
基本情報
Return
----------
basic_info_wo_lang: dict
言語マークアップが除去された基本情報
"""
basic_info_wo_lang = {}
for k, v in basic_info.items():
basic_info_wo_lang[k] = re.sub(r'{{lang\|.+?\|(.+?)}}', r'\1', v)
return basic_info_wo_lang
def remove_markup(basic_info: dict) -> dict:
"""
基本情報からマークアップを取り除く関数
Parameter
----------
basic_info: dict
基本情報
Return
----------
basic_info_wo_markup: dict
マークアップが取り除かれた基本情報
"""
basic_info_wo_markup = {}
# 太字と斜体
basic_info_wo_markup = remove_italic_and_bold(basic_info)
# 内部リンクマークアップ
basic_info_wo_markup = remove_internal_link(basic_info_wo_markup)
# htmlタグ
basic_info_wo_markup = remove_html_tag(basic_info_wo_markup)
# 外部リンクマークアップ
basic_info_wo_markup = remove_external_link(basic_info_wo_markup)
# 言語マークアップ
basic_info_wo_markup = remove_lang(basic_info_wo_markup)
# ファイルマークアップ
basic_info_wo_markup = remove_file(basic_info_wo_markup)
return basic_info_wo_markup
def main():
in_filepath = './jawiki-country.json.gz'
out_filepath = './UK.txt'
key_title = 'イギリス'
text = extract_text_from_wiki_gzip(in_filepath, key_title)
basic_info = extract_basic_info(text)
basic_info_wo_markup = remove_markup(basic_info)
for k, v in basic_info_wo_markup.items():
print('{}: {}'.format(k, v))
if __name__ == '__main__':
main()
$ python3 28.py
略名: イギリス
日本語国名: グレートブリテン及び北アイルランド連合王国
公式国名: United Kingdom of Great Britain and Northern Ireland英語以外での正式国名:*An Rìoghachd Aonaichte na Breatainn Mhòr agus Eirinn mu Thuath(スコットランド・ゲール語)*Teyrnas Gyfunol Prydain Fawr a Gogledd Iwerddon(ウェールズ語)*Ríocht Aontaithe na Breataine Móire agus Tuaisceart na hÉireann(アイルランド語)*An Rywvaneth Unys a Vreten Veur hag Iwerdhon Glédh(コーンウォール語)*Unitit Kinrick o Great Breetain an Northren Ireland(スコットランド語)**Claught Kängrick o Docht Brätain an Norlin Airlann、Unitet Kängdom o Great Brittain an Norlin Airlann(アルスター・スコットランド語)
国旗画像: Flag of the United Kingdom.svg
国章画像: イギリスの国章
国章リンク: (国章)
標語: Dieu et mon droit(フランス語:神と私の権利)
国歌: 神よ女王陛下を守り給え
位置画像: Location_UK_EU_Europe_001.svg
公用語: 英語(事実上)
首都: ロンドン
最大都市: ロンドン
元首等肩書: 女王
元首等氏名: エリザベス2世
首相等肩書: 首相
首相等氏名: デーヴィッド・キャメロン
面積順位: 76
面積大きさ: 1 E11
面積値: 244,820
水面積率: 1.3%
人口統計年: 2011
人口順位: 22
人口大きさ: 1 E7
人口値: 63,181,775United Nations Department of Economic and Social Affairs>Population Division>Data>Population>Total Population
人口密度値: 246
GDP統計年元: 2012
GDP値元: 1兆5478億IMF>Data and Statistics>World Economic Outlook Databases>By Countrise>United Kingdom
GDP統計年MER: 2012
GDP順位MER: 5
GDP値MER: 2兆4337億
GDP統計年: 2012
GDP順位: 6
GDP値: 2兆3162億
GDP/人: 36,727
建国形態: 建国
確立形態1: イングランド王国/スコットランド王国(両国とも1707年連合法まで)
確立年月日1: 927年/843年
確立形態2: グレートブリテン王国建国(1707年連合法)
確立年月日2: 1707年
確立形態3: グレートブリテン及びアイルランド連合王国建国(1800年連合法)
確立年月日3: 1801年
確立形態4: 現在の国号「グレートブリテン及び北アイルランド連合王国」に変更
確立年月日4: 1927年
通貨: UKポンド (£)
通貨コード: GBP
時間帯: ±0
夏時間: +1
ISO 3166-1: GB / GBR
ccTLD: .uk / .gb使用は.ukに比べ圧倒的少数。
国際電話番号: 44
注記:
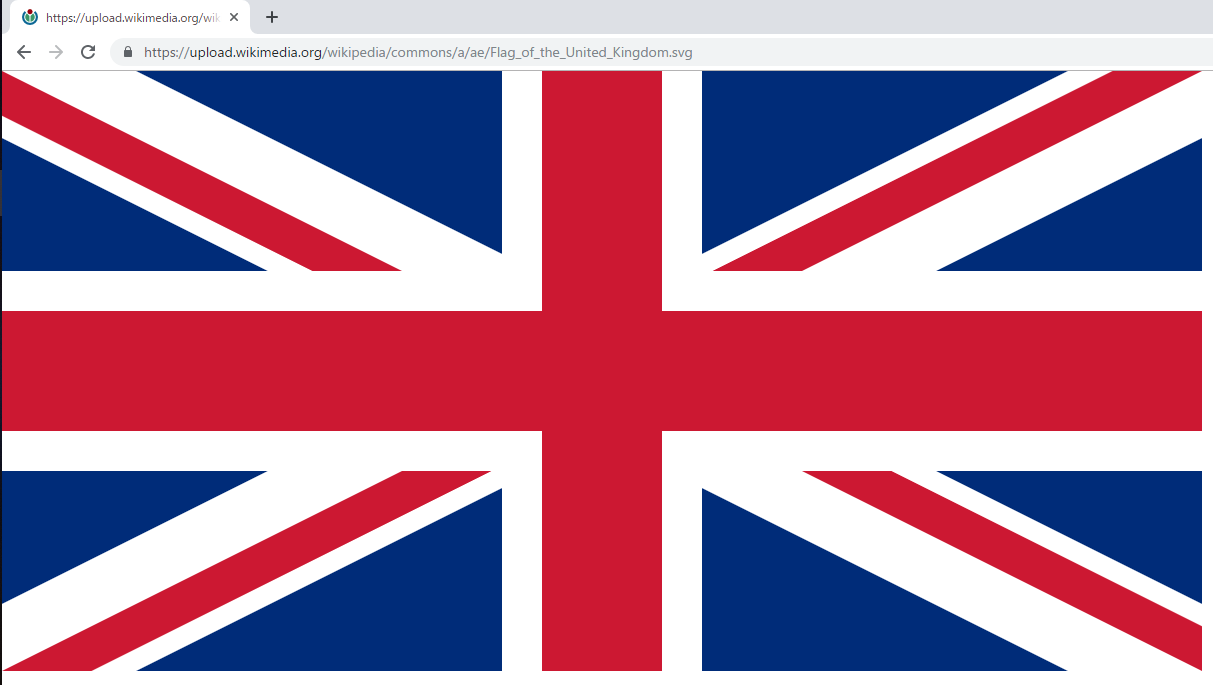
問題29 国旗画像のURLを取得する
テンプレートの内容を利用し,国旗画像のURLを取得せよ.(ヒント: MediaWiki APIのimageinfoを呼び出して,ファイル参照をURLに変換すればよい)
# !/usr/local/bin python3
# -*- coding: utf-8 -*-
import gzip
import json
import re
import requests
def extract_basic_info(text: str) -> list:
"""
省略
"""
def extract_text_from_wiki_gzip(in_filepath: str, key_title: str) -> str:
"""
省略
"""
def get_national_flag(img_filename: str) -> str:
"""
渡されたファイル名の画像をwikiにrequestして取得する関数
Parameter
----------
img_filename: str
画像ファイル名
Return
----------
img_link:
画像へのリンク
"""
url = 'https://www.mediawiki.org/w/api.php' + '?' + 'action=query' + '&' + 'format=json' \
+ '&' + 'titles=File:' + img_filename + '&' + 'prop=imageinfo' + '&' + 'iiprop=url'
response = requests.get(url, headers={'User-Agent': 'NLP100Knock_Python(@3000manJPY)'})
return response.json()['query']['pages']['-1']['imageinfo'][0]['url']
def remove_external_link(basic_info: dict) -> dict:
"""
省略
"""
def remove_file(basic_info: dict) -> dict:
"""
省略
"""
def remove_html_tag(basic_info: dict) -> dict:
"""
省略
"""
def remove_italic_and_bold(basic_info: dict) -> dict:
"""
省略
"""
def remove_internal_link(basic_info: dict) -> dict:
"""
省略
"""
def remove_lang(basic_info: dict) -> dict:
"""
省略
"""
def remove_markup(basic_info: dict) -> dict:
"""
省略
"""
def main():
in_filepath = './jawiki-country.json.gz'
out_filepath = './UK.txt'
key_title = 'イギリス'
text = extract_text_from_wiki_gzip(in_filepath, key_title)
basic_info = extract_basic_info(text)
basic_info_wo_markup = remove_markup(basic_info)
img_link = get_national_flag(basic_info_wo_markup['国旗画像'])
print(img_link)
if __name__ == '__main__':
main()
$ python3 29.py
https://upload.wikimedia.org/wikipedia/commons/a/ae/Flag_of_the_United_Kingdom.svg