やりたいこと
決定株分類器をブースティングアルゴリズムの一つであるAdaBoostを用いて実装する
ちなみに前回はバギングを用いて実装した
前回:http://qiita.com/241824182418/items/6c19024f6e26fa9f9344
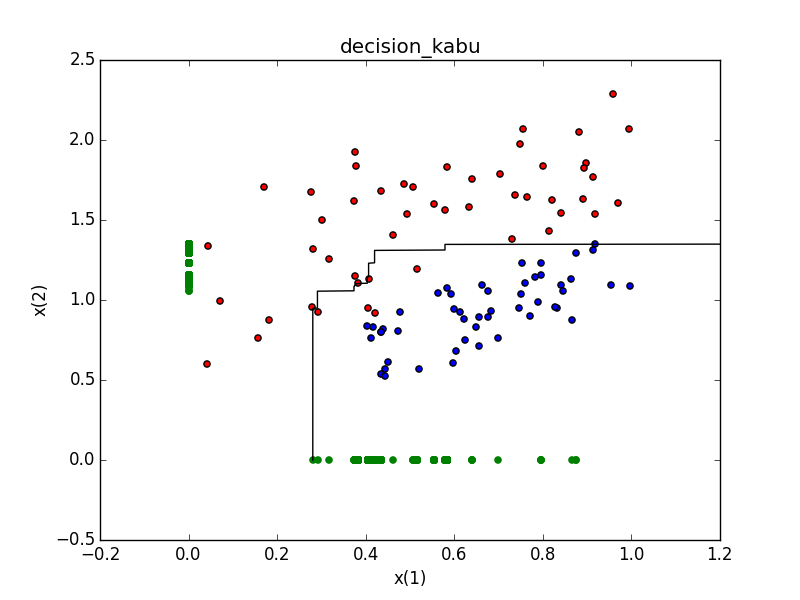
バギングによる学習結果
- 2000の弱学習器を組み合わせている
- 2000では全てを識別しきれなかった
環境
- OS X El Capitan
- Python 3.4.3-0
- Anaconda - spyder:Version 2.3.5.2
参考
イラストで学ぶ機械学習 小二乗法による識別モデル学習を中心に (KS情報科学専門書)
アンサンブル学習の章にあるAdaBoost
https://www.amazon.co.jp/dp/4061538217
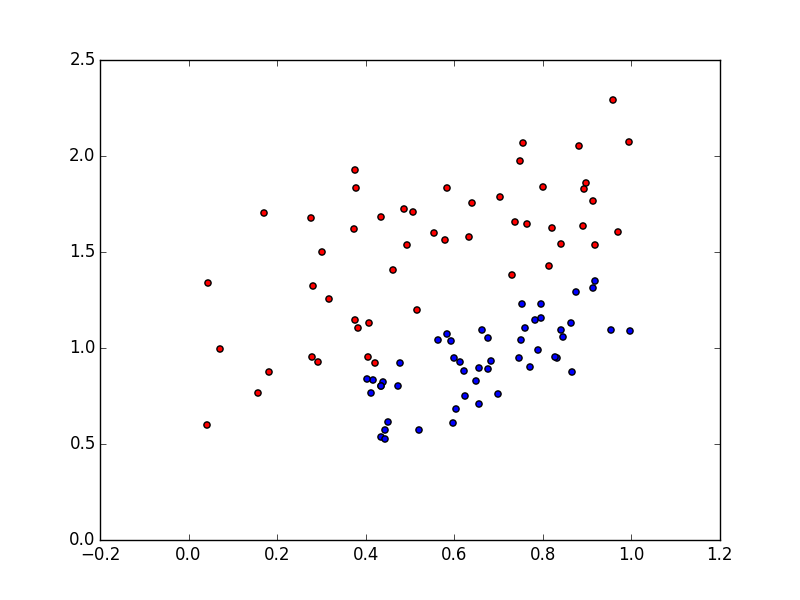
分類するデータ
結果を比較したいので前回バギングと同じデータを使用する
使用する学習法
Adaboost
-イメージ-
- 弱学習器を順々に学習していくという方法(バギングは各々別々に学習していた)
- 一個前の弱学習器でうまく分類できなかったデータに対して重みを持たせたデータで次の弱学習器を学習させるということを繰り返していく
- 重みも付加した状態での誤分類率の低い学習器に対して大きな重みを持たせ、最終的なアウトプットは全ての学習器の重み付き和で表す
- 詳しいアルゴリズム等は本を読んでください
動かす
お手製のAdaBoostプログラムを動かしてみる(codeは最下にリンク貼ります)
- バギングの時と同じように2000回学習させる
AdaBoost.py
>>>t = Adaboost(LearnData,teachData)
>>>t.learn(2000)#2000回学習
>>>t.plot(350)#出力領域の目の細かさを350等分にしてplot
すると・・・。
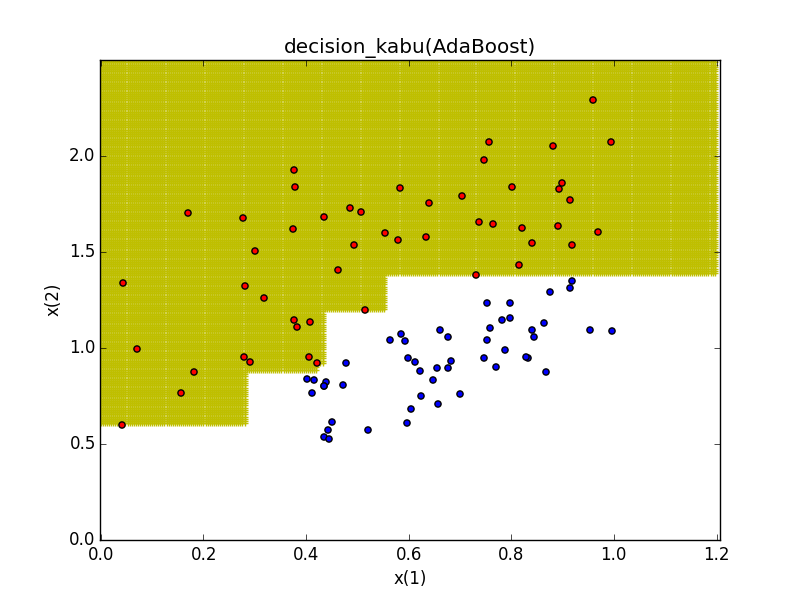
学習されました!!
バギングの時よりしっかりと分けられているように見えますがどうでしょう?
比較するために前回の識別境界を重ねてみます
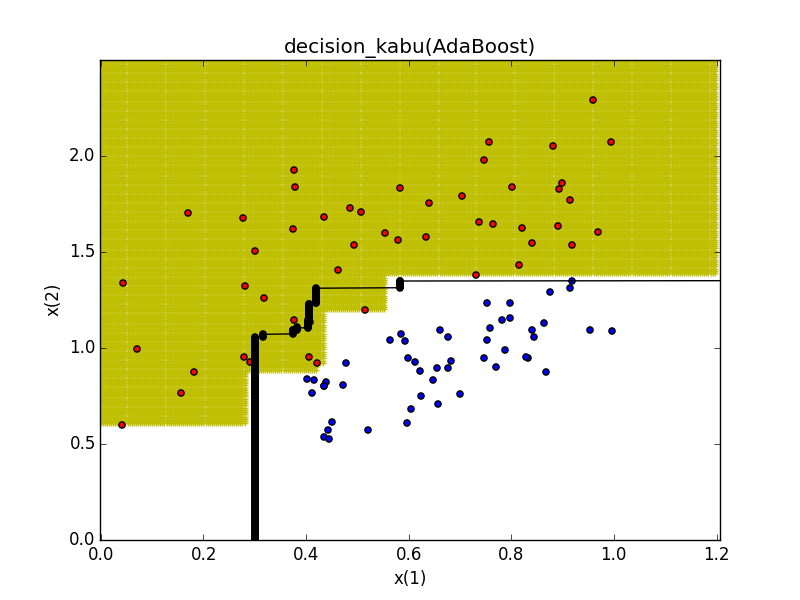
青に近かった奴もきちんと識別できるようになりました
ただ、バギングは過学習しにくいのが良さでもあるので一概にAdaBoostがいいわけでもない模様
今回はこれでおしまい
感想等(メモ)
- データをもっと複雑してみようかな
- 汎化性能とかも測ってみると面白いかも
- プログラム自体ももっと汎用できる形にすればよかったと後から思った
- 学習時間とかを見てみるのもあり