はじめに
データ拡張は深層学習モデルの訓練に大切な要素の1つです。深層学習モデルの性能を左右するのはデータセットの質と量といってもいいのではないでしょうか。しかし、大規模なデータを収集するのは大変です。そこで画像に対して変化を与えることでデータ量を疑似的に増やすデータ拡張の存在はとても重要です。本記事では様々なデータ拡張について紹介します。
一般的な画像変換系データ拡張
一般的に使用されるデータ拡張は,画像1枚に対して幾何学的変形や色変換を行うものが多いです。
- RandomResizedCrop
- CenterCrop
- HorizontalFlip / VerticalFlip
- Rotation
- ColorJitter
- RandomErasing など
ただし、非現実的な画像は学習に悪影響を与える可能性もあるため注意が必要です。
 |
| 上下反転した建物 |
RandAugment
データ拡張は豊富な種類があるだけでなく、パラメータを設定することができます。タスクやモデルによって最適なデータ拡張の組み合わせは異なるため、経験的な要素が求められることもあるかもしれません。そこで提案されているのが、RnadAugmentです。色変化や幾何学的変形など15種類の拡張の中から、様々な拡張手法とパラメータの強度が選択してくれる非常にシンプルな手法でありながら効果的な手法です。
2枚の画像を使用したデータ拡張
Mixup/CutMix
ラベルの異なる2枚の画像を使用したデータ拡張です。
これらの拡張手法は混合画像と混合ラベルを補間する拡張手法です。
どちらかの手法を確率的に切り替えて適用することが一般的です。
- Mixup
"mixup: Beyond empirical risk minimization." (2017)
2枚の画像を線形補間により重ね合わせることで1枚の混合画像に拡張します。
混合ラベルは、ベータ分布という確率分布からサンプリングによって決定します。
 |
- CutMix
"Cutmix: Regularization strategy to train strong classifiers with localizable features." (2019)
ソース画像の一部をランダムに切り抜き、ターゲット画像のランダムな位置に貼り付けることで1枚の混合画像に拡張します。混合ラベルは、切り抜きに使用する矩形マスクの面積比から決定します。
(記載の図はラベルスムーシングを導入しているため、表示しているラベル比率の合計が100%になっていません。)
 |
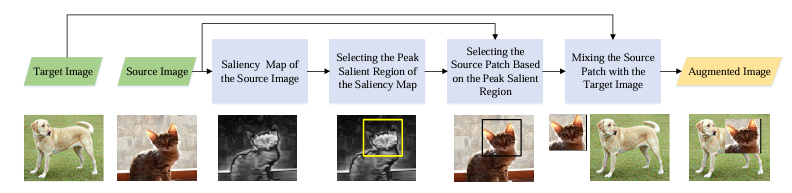
SaliencyMix
"Saliencymix: A saliency guided data augmentation strategy for better regularization." (2020)
CutMixでは混合した画像の内容とラベルの混合比率のミスマッチが指摘されていました。
(下図ではソース画像の背景のみが切り抜かれおり、混合画像に猫の要素が見られないにもかかわらず、猫クラスのラベル確率が割り当てられている。)

SaliencyMixは、画像の切り抜く際に顕著性検出を導入し、重要な領域を意図的に切り抜く手法です。この論文では生成したヒートマップの最も重要な座標を中心に矩形領域を切り抜き、ターゲット画像の同じ座標位置にペーストする拡張が最も有効的だったそうです。混合ラベルの割り当て比率はCutMixと同じです。
トークン空間上でのデータ拡張
ここからはViTモデルの訓練に有効なデータ拡張を紹介していきます。
Vision Transformerを始めとする,TransformerベースのモデルはAttention機構や画像をパッチトークンとして処理する特徴があります。そこで、アテンションレベル/トークンレベルでのデータ拡張が重要なのではないかというアイディアに基づいたデータ拡張が提案されています。
TokenMix
"Tokenmix: Rethinking image mixing for data augmentation in vision transformers." (2022)
従来の画像を混合するデータ拡張は画像とラベルの混合比率を画像の面積や線形補間の比率によって決めていました。

TokenMixはトークン単位で画像の混合を行います。
2枚の画像$(x_A,x_B)$をパッチトークン$(x_a^p,x_b^p)$に分割します。
得られたパッチトークンとトークンレベルの混合マスク$(M_t)$から混合画像$(\tilde{x}^p)$を作成します。
\tilde{x}^p=M_t \odot x_a^p+\left(1-M_t\right) \odot x_b^p
混合ラベルは、画像の内容を考慮した比率でラベルの割り当てを行います。
事前学習済みモデルに各画像を入力しヒートマップ$(A_a,A_b)$を取得しておきます。混合画像と各ヒートマップから、混合画像が画像$(x_A)$と$(x_B)$の特徴を含む程度をパッチごとに計算し、ラベル比率の決定に用います。
\tilde{y}=\sum_{i \in \mathscr{C}} M_{t i} \odot A_{a i}+\sum_{i \in \mathscr{C}}\left(1-M_{t i}\right) \odot A_{b i}
TransMix
"Transmix: Attend to mix for vision transformers."(2022)

TransMixはMixup/CutMixにアテンション情報を組み込むことでラベル混合比を補正するデータ拡張です。したがって、作成される混合画像に関しては従来のMixup/CutMixと同じで、ラベルの混合比率の決め方に工夫点があります。
まず、2枚の画像$(x_A,x_B)$と矩形バイナリマスク($M$)から従来のCutMixと同様に混合画像$(\hat{x})$を作成します。
\hat{x} = M \odot x_A + (1-M) \odot x_{B}
作成した混合画像をViTモデルに入力し、アテンションマップ$(A)$を取得します。
次にCutMixで使用した矩形マスクと取得したアテンションマップから、ViTモデルが画像のどの領域(どちらの画像)が重要だったかを反映したラベル混合係数$\lambda$を取得します。
\lambda = A^{\top} \downarrow(M)
混合ラベル比率の定義に$\lambda$を適用することで分類の重要度に適した混合ラベルと画像で学習を行うことができます。
\tilde{y} = \lambda y_A + (1-\lambda) y_{B}
MixPro

MixProはTransMixに2つの課題を提起し、改善手法を提案しています。
1つ目の課題は、矩形マスクを利用した混合画像のパッチ分割についてです。
CutMixやTransMixの矩形マップを用いた混合画像生成方法では、上図(a)のような画像が生成されます。この混合画像をViTモデルで処理する際にパッチ分割すると合成に使った2つの画像の両方の要素を含むパッチ(赤いパッチ)が得られる場合があります。このようなパッチはViTの学習において整合性が低く、学習を妨げる可能性が指摘されています。

MixProでは、マスクの境界とパッチの境界を必ず一致させるMaskMixを提案しています。
MaskMixは単純な手法で、混合マスクのサイズがViTのパッチサイズの倍数になるような制約を設けることで、混合画像での各パッチに2枚の画像の要素が含まれないようにしています。
2つ目の課題はラベル作成で使用するアテンションマップの信頼性です。
アテンションマップは、ターゲットネットワークとなるViTモデルからを取得しますが、学習初期のアテンションマップは信頼性が低く適切な混合ラベル付与できていない可能性が指摘されています。
MixProでは、学習初期は従来の矩形マップの面積比によりラベル比率を採用し、学習が進んだ段階でアテンションベースのラベル比率を採用することでTransMixの課題を改善しています。
具体的には信頼度$(\alpha)$によって面積$(\lambda_{area})$とアテンション$(\lambda_{attn})$のどちらを優先的に使用するかを制御します。$\alpha$はターゲットモデルの出力と教師ラベルのコサイン類似度で計算されます。
\lambda = \alpha \cdot \lambda_{attn} + (1-\alpha) \cdot \lambda_{area}
ViTに有効的なデータ拡張の組み合わせはこれ!?
"DeiT iii: Revenge of the vit." (2022)
RandAugmentなどの自動的なデータ拡張は実はViTには不向きであると指摘し、ViTに有効なデータ拡張の組み合わせが提案している。具体的な組み合わせは下記のようになっている。
- 必ず適応する
- Colojitter
- HorizontalFlip
- 3つの中からランダムに1つを適用する
- Grayscale
- Solarization
- GaussianBlur
- 適用しないほうがいい
- RandomResizedCrop
シンプルでありながら、RnadAugmentよりも十分な効果を発揮することが報告されています。また、RandomResizedCropはラベル対象が切り抜かれない、アスペクト比や見かけの整合性が崩れてしまう可能性があるため適用しないほうがいいとのことです。
この論文ではRandomResizedCropの代わりに、SimpleRandomCropというクロップを提案しています。
Solarizationは、色強度の反転で強い擾乱を与えることで、形状重視・色変動耐性を高めることができるらしいです

拡散モデルを使ったデータ拡張
拡散モデルはノイズから画像を生成することが可能なモデルで、Stable Diffusionなどの有名な画像生成モデルの基盤となった技術です。画像とプロンプトから様々な高品質画像を生成することができることから、学習データを拡散モデルによって生成し訓練にしようする手法が提案されています。
DiffuseMix
"Diffusemix: Label-preserving data augmentation with diffusion models." (2024)
拡散モデルはプロンプトの影響を非常に受けやすく、プロンプトが不適切な場合は学習に悪影響を与える画像が生成されてしまうほど、プロンプトに依存していると言えます。
DiffuseMixでは、bespoke conditional promptsと呼ばれる、原画像の意味性を保持しながら多様な画像の生成をするためのプロンプトを提案しています。プロンプトは画像全体に対してフィルターとなるようなプロンプトが事前に定義されており、ランダムに選択され適用されます。

単純に拡散モデルで生成した画像を用いるだけでは性能の向上は見込めません。生成画像($I_{ij}$)は原画像($I_i$)とマスク($M_u$)によって合成されハイブリッド画像($H_{iju}$)として連結されます。その後、フラクタル画像($F_{v}$)と呼ばれる画像を線形補間し、薄く重ね合わせた画像($A_{ijuv}$)が学習に用いられます。

参考文献
SaliencyMixの元論文
"Saliencymix: A saliency guided data augmentation strategy for better regularization." (2020)
TokenMixの元論文
"Tokenmix: Rethinking image mixing for data augmentation in vision transformers." (2022)
TransMixの元論文
"Transmix: Attend to mix for vision transformers."(2022)
DeiT iiiの元論文
"DeiT iii: Revenge of the vit." (2022)
Diffusemixの元論文
"Diffusemix: Label-preserving data augmentation with diffusion models." (2024)