~ 保守員を苦しめるメール確認作業からの脱却 ~

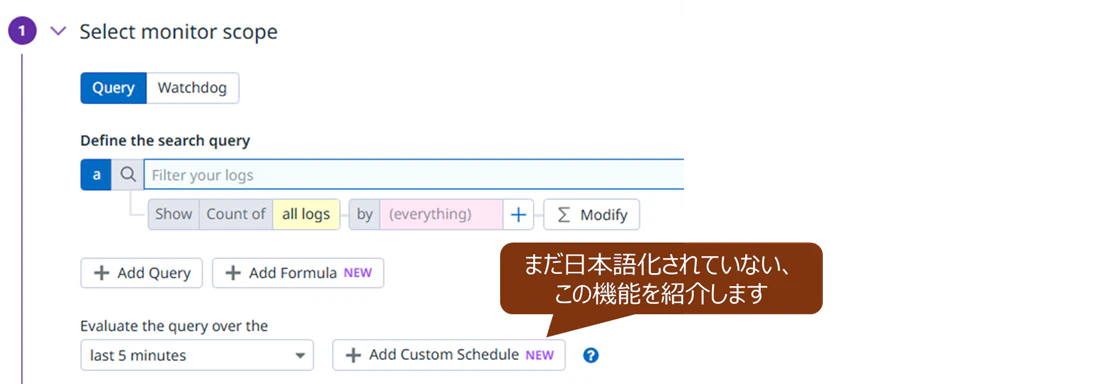
紹介する機能:[Add Custom Schedule]
背景
あるレガシーシステムでは大幅なコード変更はしていないが、Linuxディストリビューションの変更を境に夜間バッチJOBが完了せず、朝の業務開始に支障をきたす障害が時々発生しています。
みなさんの現場でも、バッチJOBの起動とJOB終了を管理する需要はありませんか?
事象
- 朝の業務開始時、不定期に「ログイン画面が描画されない」という障害が発生
- 発生頻度は数週間に1回の不定期
- 障害発生時は、業務開始を優先するためアプリを再起動して復旧させている
障害インパクト
業務開始が遅れると、エンドユーザーのビジネスに影響がでることはもちろん、保守員にとっても一日の大半がトラブル対応に奪われてしまいます。単なる技術的問題ではなく、ビジネス全体に波及する深刻な課題です。
ログインできない理由
保守担当はログを調査し、朝08:00になってもバッチJOBが終了していないことを確認できた。JOBが終了しない場合にログイン画面が表示されない。
課題
- 根本原因は、事象発生が希であるため十分な情報を得られず、原因特定できていない
- 恒久対策ができるまでは毎朝、JOB実行結果を目視検査することを決定した
- 毎日何通ものメールを確認する運用はコスト・労力が大きい
どうすれば毎日のメール確認作業を省力化・自動化できるのか?
- 障害原因を取り除く恒久対策が最重要だが、スピードを優先し、ここでは保留とする
- 依頼は、Datadogの機能でJOB監視を効率化できないか調べてほしい、ということ
監視対象JOB
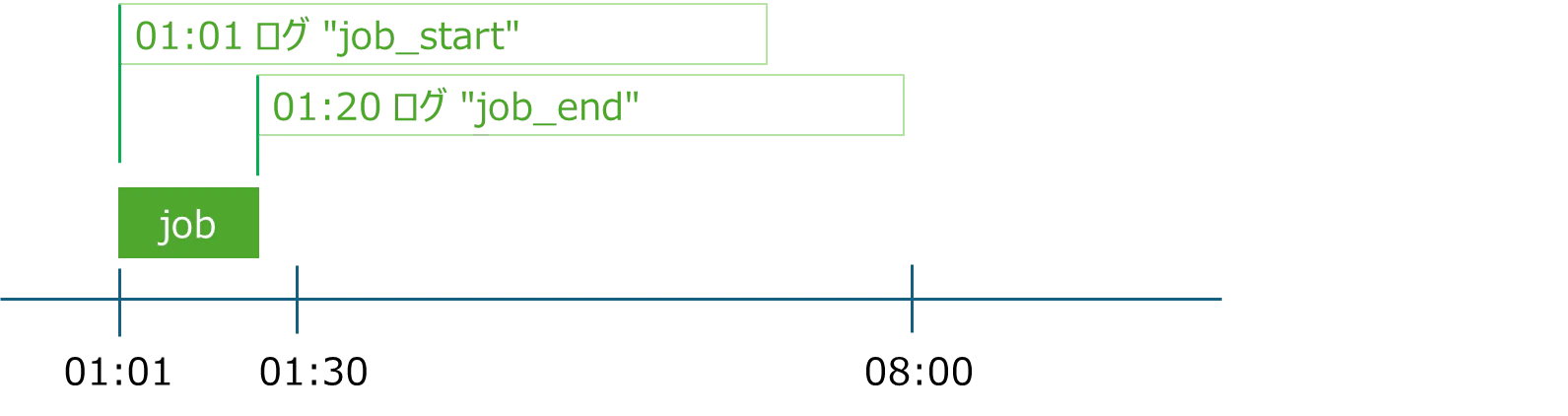
このJOBは毎日00時01分に起動するようcron設定されており、起動後30分間以内に終了する。JOB起動時に[job_start]をsyslogに出力し、正常終了時に[job_end]を出力している。
暫定対策としてDatadogのログ監視でキーワードマッチングによるメール送信を設定済み。
ジョブ監視という共通課題に取り組む検証
-
要件:
- [job_start]JOBが起動しなかったらアラート通知する
- [job_end]JOBが30分間以内に終了しなかったらアラート通知する
-
前提:
- Datadogのログ監視「Logs」が有効。既にsyslogのログを取り込んでいる
-
ジョブ:
- スケジュール実行は cron を使って、毎時01分に検証用スクリプトを実行する
- スクリプトは、[job_start]をsyslogに出力する
- スクリプト実行後、ランダムな25~35分間の後に[job_end]をsyslogに出力する
-
可視化:
- スクリプトの起動と終了は、ダッシュボードのグラフ等で可視化する
-
目標:
- ログを検出できなかった時にアラート通知する。つまり今の監視設定を逆転する
- Before; ログ「start, end」が出力されたらメールでお知らせする
- After; ログ「start, end」が出力されないときだけアラート通知する
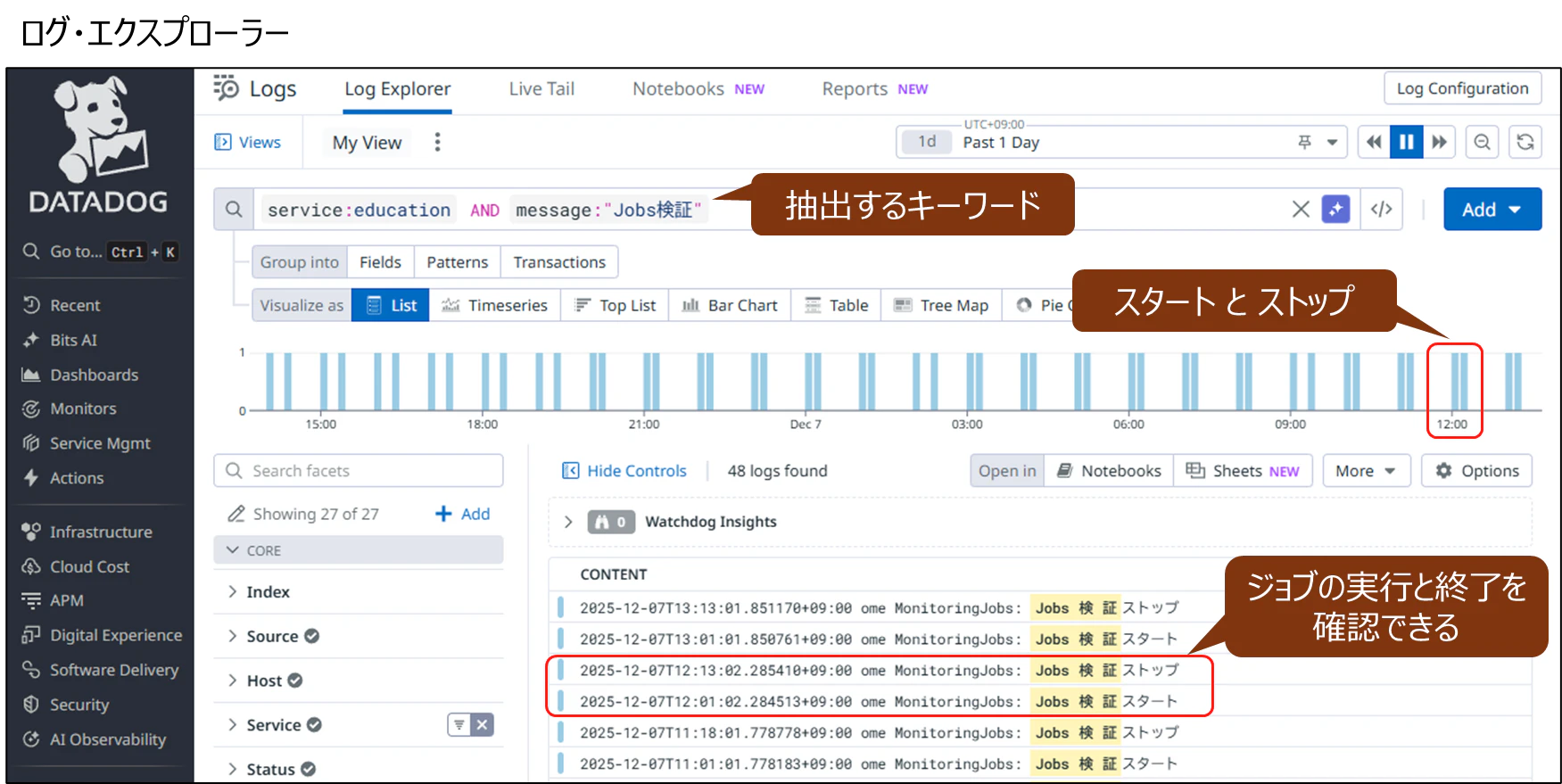
検証1.ログ調査と分析(Logs)
Datadog の Log Explorer にて、ジョブの実行とジョブ終了をペアにして調査できることがわかる。
検証2.「検証スタート」ログを検出する(Monitor)
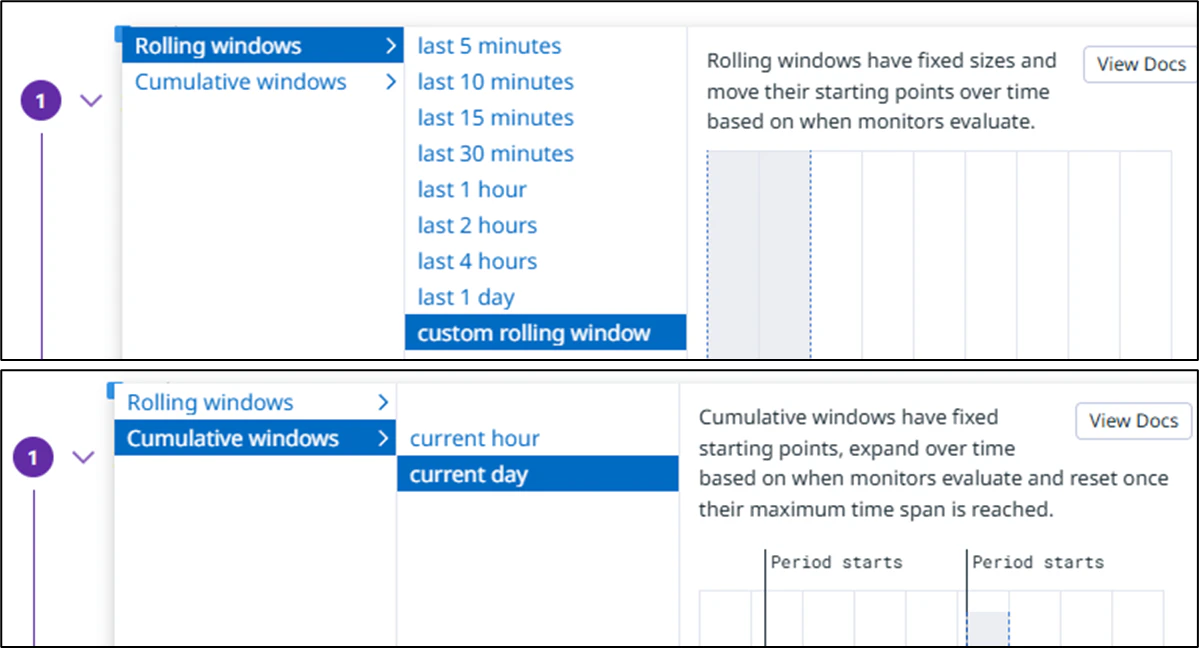
「一定時間内のログ有無」を検出するには[Evaluate the query over the]のパラメータを理解する必要がある。このパラメータは Rolling か Cumulative の2種類のどちらかを選択する。
-
ローリング間隔(Rolling window)
- 閾値を評価する時刻を起点に、過去の一定時間間隔の間のクエリで評価する
- 例:1回目。今から過去30分間にログがあるか評価する
- 例:2回目。1回目の5分後に、過去30分間にログがあるか評価する。3回目と続く
- パラメータ:過去[_]分間, [_]時間, [_]日
-
累積間隔(Cumulative window)
- 「設定した時刻から、閾値を評価する時刻まで」の時間内にクエリで評価する
- 例:今日の08:00から現在までにログがあるか評価する
- パラメータ:毎時[_]分から現在まで, 毎日[HH:MM]から現在まで
Cumulative window; モニタリング失敗例
ある時刻から現在までのログ有無を検出したいので cumulative window の方が相応しそうだった。ジョブは毎日00:01からスタートするが、ジョブ終了時間は保証できない。20分で終わる場合もあれば40分かかる場合もある。
- 毎日00:01以降にログ「end」を検出すると設定した場合は、ジョブがスタートしてから終了するまでずっとアラート状態になる
- ジョブ終了時刻を推定して毎日00:40以降にログ「end」を検出すると設定した場合は、もしジョブが00:20に終了してしまった場合、その日00:40以降はずっとアラート状態になってしまう
結論 以上のことから Cumulative では目的達成は難しそうだ。
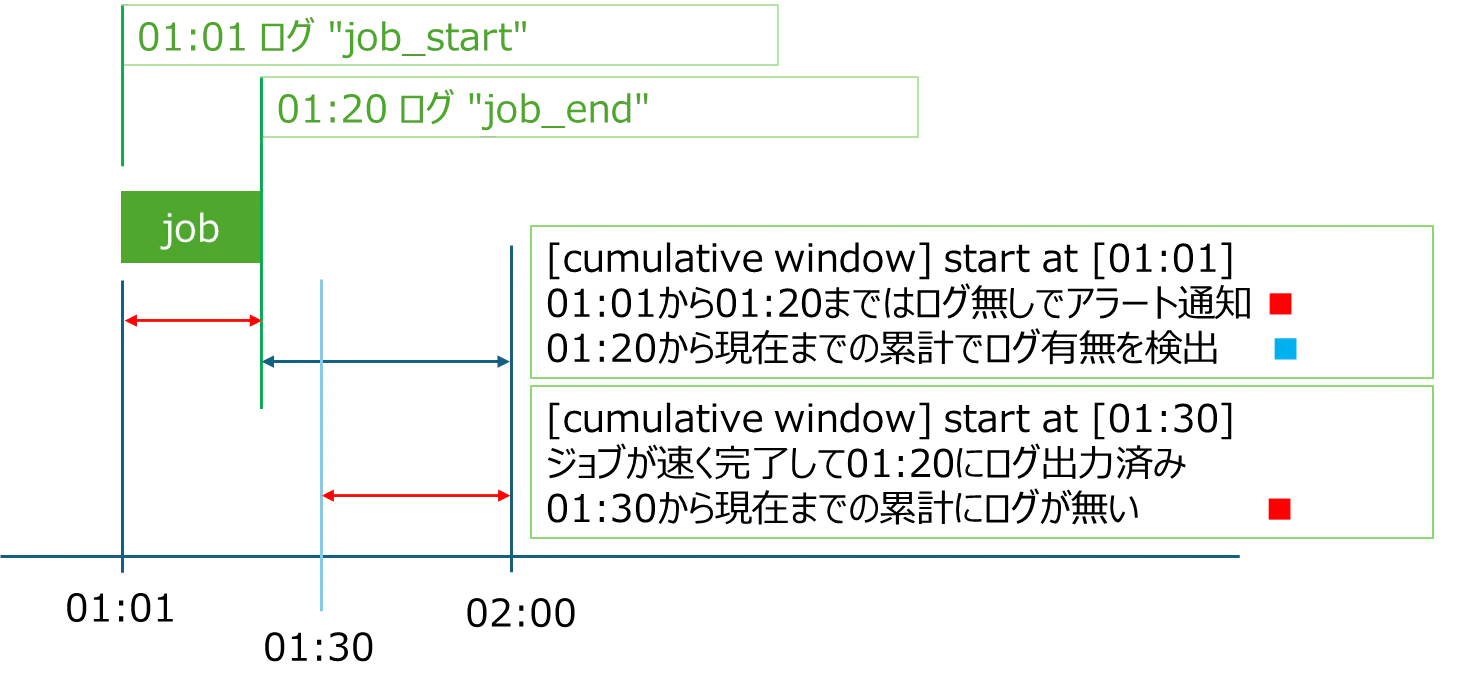
累積間隔(Cumulative) では目的を実現できないようなので、 ローリング間隔(Rolling) でのモニタリング&アラートの検証を進める
Rolling window; 過去30分間のログ有無
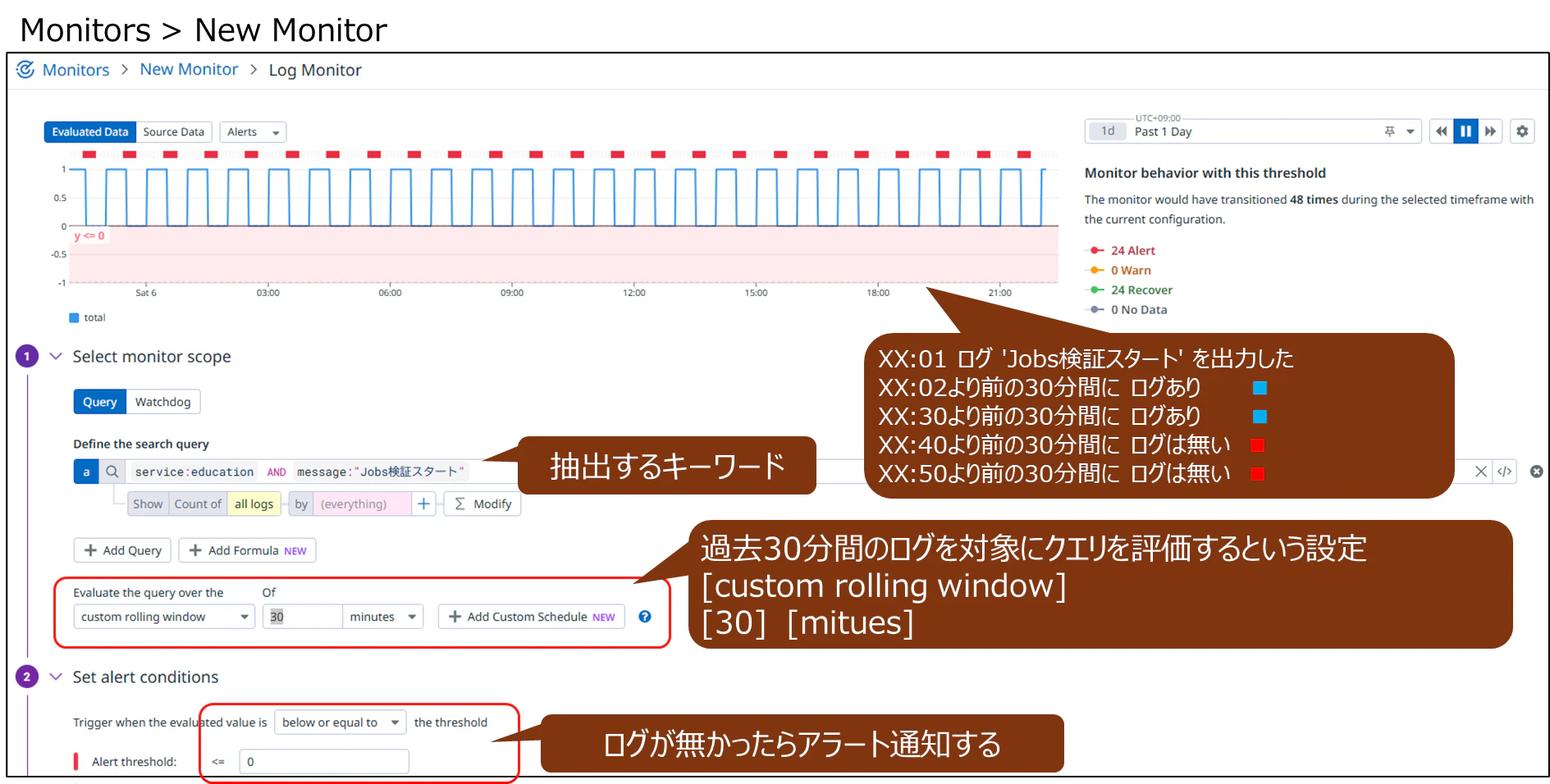
Datadog の Monitor を追加する。ジョブ実行できたことを可視化し、ジョブ実行できなかった場合にアラート通知する。
要件のひとつに「ジョブ実行から30分間以内にジョブが終了しなかったらアラート通知する」という条件があるので30分間という設定を試した。毎時XX:01にスタートログが記録されるので過去30分間にログが存在するのは毎時XX:01~XX:31の間であり、XX:32~XX:00の時間帯で過去30分を評価してもログは存在しない(つまりログ数=ゼロ)挙動になる可能性がある。
この設定ではログ数がゼロなので、毎時アラート通知されてしまう。
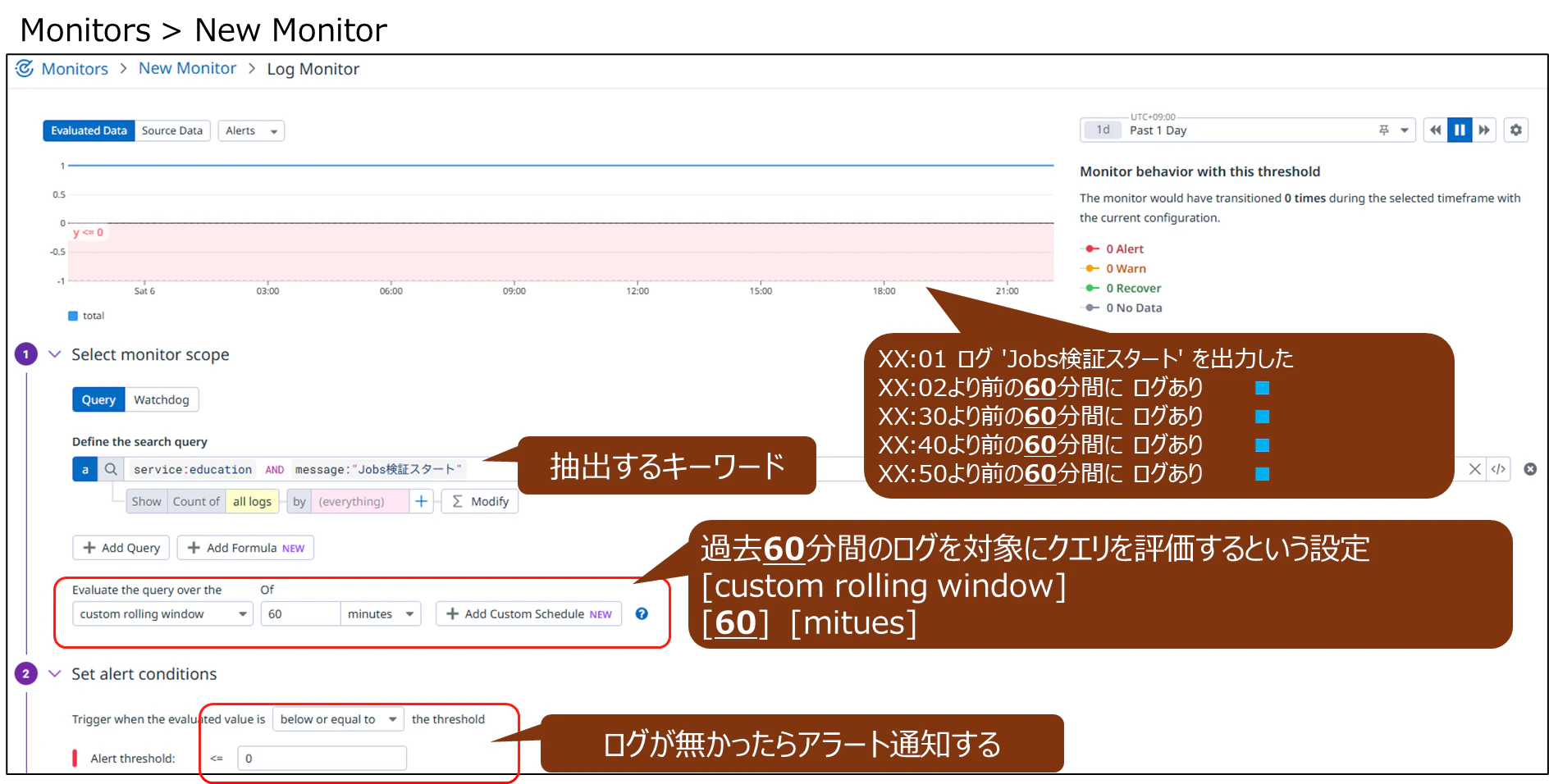
Rolling window; 過去60分間のログ有無
毎時ログが出力されており、過去60分間の評価ならば「ログが1個以上検出される」のでアラート通知はされない。
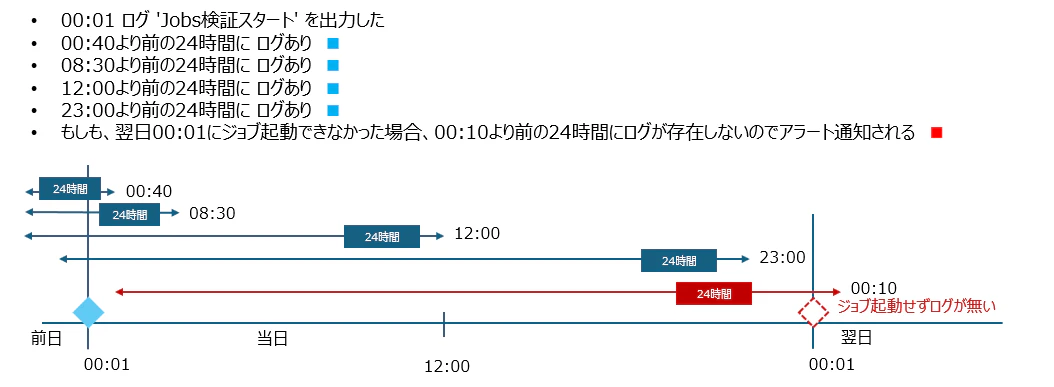
Rolling window; 毎日1回だけのログ有無
毎晩00:01にジョブ起動できたことをモニタリング。起動できないときにアラート通知するには過去24時間を評価する。
Rolling window; リカバリーのため、計画外ジョブ実行すると
アラート通知をトリガーにジョブを再起動した場合や手動でジョブを起動するなどリカバリーしたときのグラフ描画は、ログ数2個以上が記録される。

検証3.「検証ストップ」ログを検出する(Monitor)
この検証ジョブは毎時XX:01に起動後、20~40分間後にログ「Jobs検証ストップ」を出力して終了する。
問題 が見つかった。量ではなく、ログ有無というゼロ・イチの検出が目的の場合は Rolling window を選ぶと、正常なジョブ実行であってもタイミング次第でアラート通知されてしまう。
Rolling window; モニタリング失敗例
ジョブ実行時間は20~40分かかるのでログ出力時刻は毎時変化する。過去60分間のログ有無で評価する場合、例えば 03:20 にログ[end]出力し、04:40 に次のログ[end]出力された場合、04:21から04:39までの18分間は、過去60分間にログ[end]が存在しないことなる。この結果、正常なのにメールを多数受信することになってしまった。

Rolling window; パラメータ調整
ジョブ実行時間の変化を考慮してパラメータを調整してみる。過去[1]時間以内、[2]時間以内、[90]分以内。要件のひとつ[JOBが30分間以内に終了しなかったらアラート通知する]だけは難しそうだが、過去90分を振り返ってログ[end]をグラフ等で可視化し、ログが無かったらアラート通知することはできそうだ。
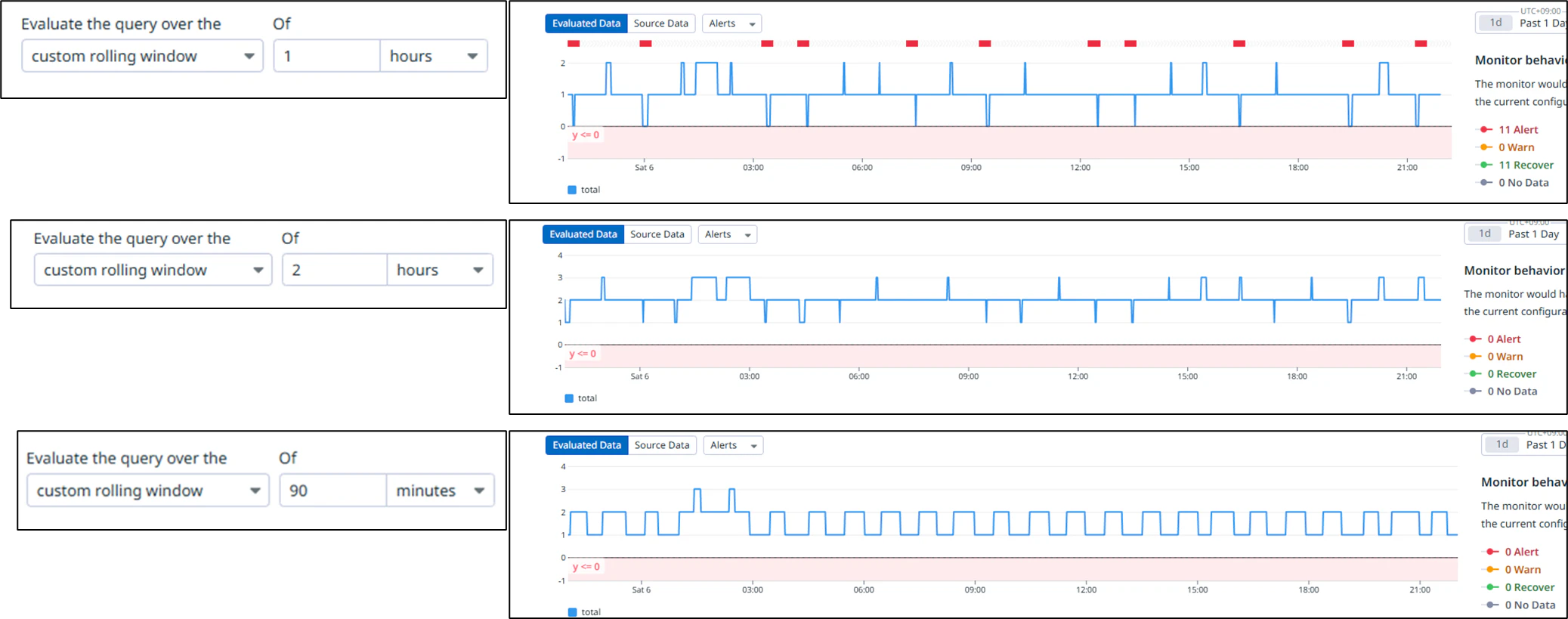
ちょうどいい解決策が見つからない
ローリング間隔(Rolling window) と 累積間隔(Cumulative window) では、要件の実現が難しそうだった。少しだけバッファを設けて要件の一部を変更し、本質であるジョブの実行と完了を朝の業務開始までに検出することを提案しようとしていたが、まだ日本語化していない記事を見つけることができた。
新機能がちょうどいい解決策かも
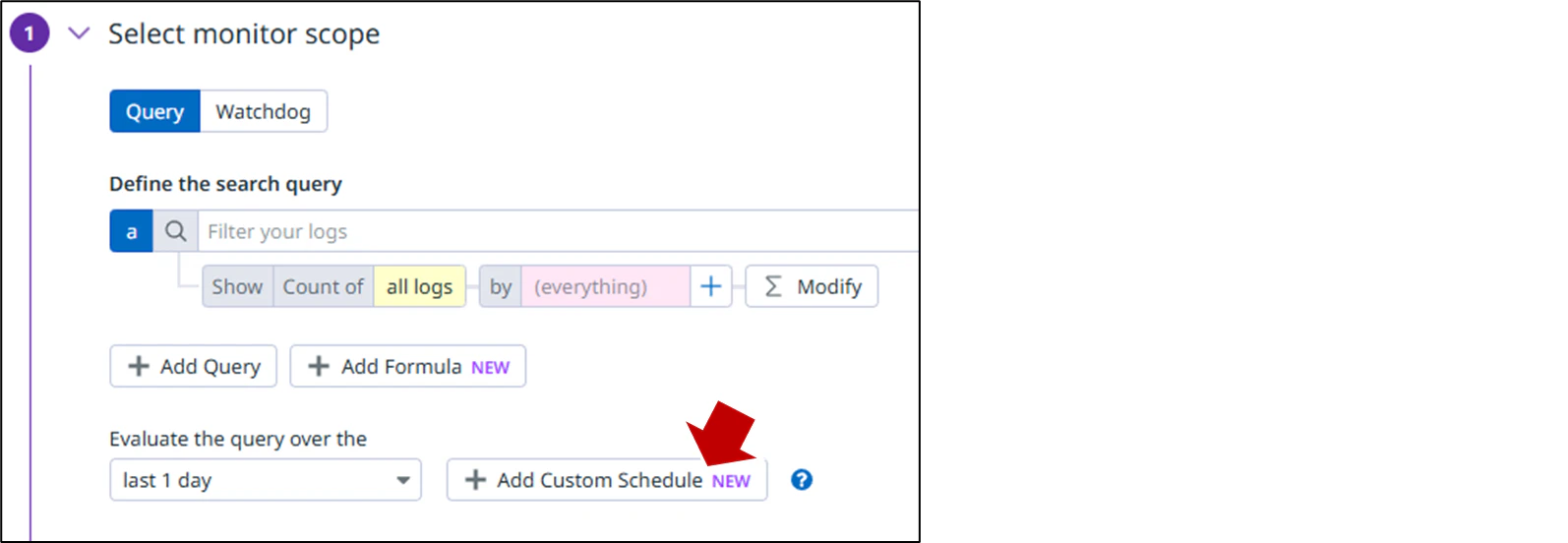
NEW Customize monitor evaluation frequencies
モニターのカスタムスケジュールを使用すると、cronジョブなど、継続的な監視が不要なシステムやプロセスについてアラートを送信できます。モニターのカスタム スケジュールは、毎日、毎週、毎月のスケジュール間隔を持つイベント、ログ、メトリック モニターでサポートされます。
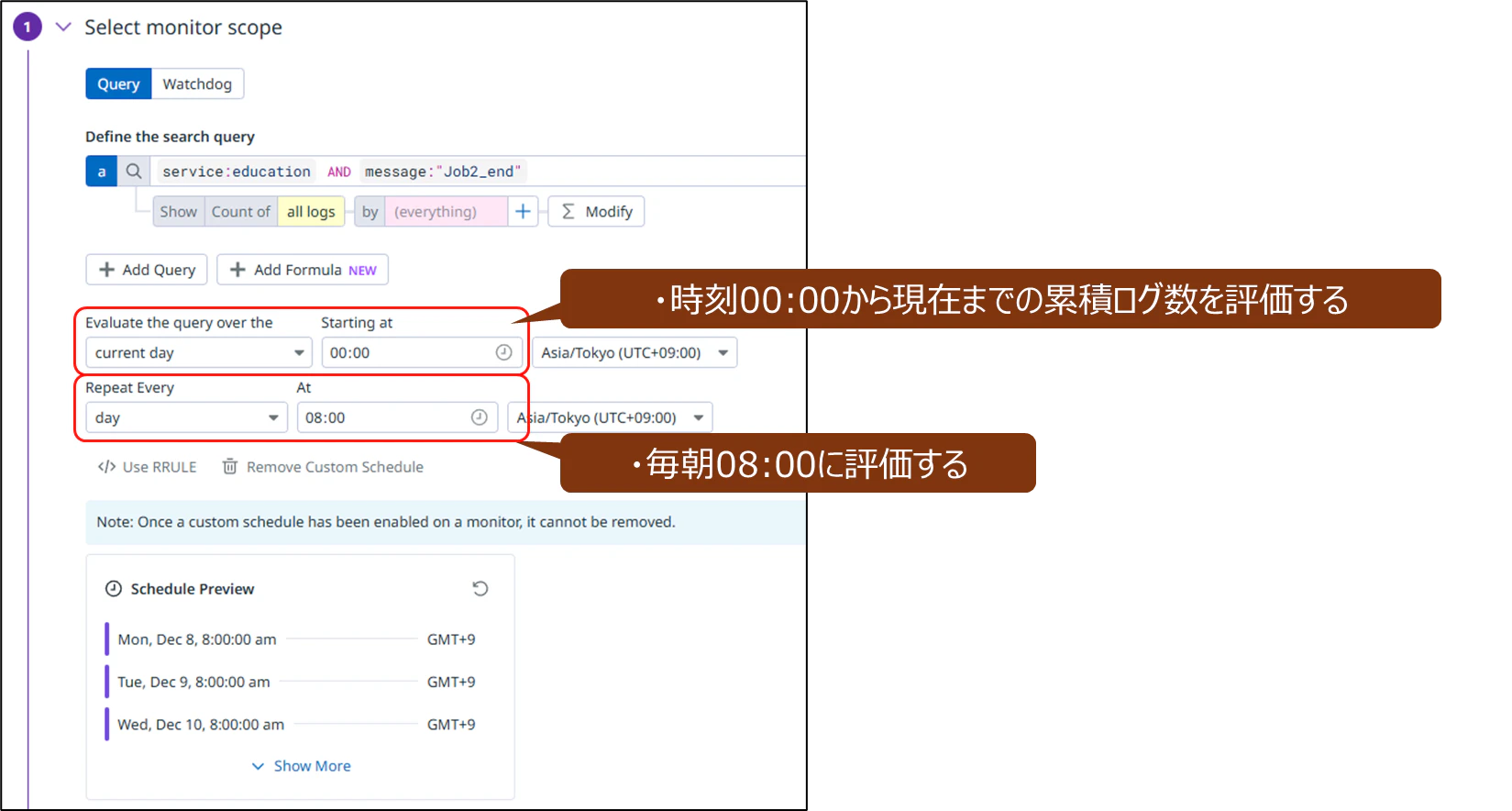
つまり毎朝08:00に、今日00:00から08:00までの時間帯でログ[job_end]の有無を検出できるということ。ジョブが30分以上かかった場合にアラート通知するという要件だけは実現できないが、それはジョブ監視の本質ではないと考える。業務開始までにジョブが正常だったか異常な状態であるかを可視化したり、アラート通知したりできることを確認できた。
- 累積間隔(cumulate window)の[current day]を選び、スタート時刻[HH:MM]を設定する
- [Add Custom Schedule]を追加し、正常・異常を判定する時刻[HH:MM]を指定する
さらに高度なルールも追加できる FREQ=MONTHLY;BYMONTHDAY=28,29,30,31;BYSETPOS=-1 は毎月の最終日(つまり2月29日, 3月31日, 4月30日)だけ評価実行する。月初1日もできるわけだ。
設定上の躓きポイント
- 一度設定したモニタリングは、あとから[Add Custom Schedule]を後付けはできないので、新たなモニタリングを作成 する必要がある
- 設定したら、日次ジョブならば最低でも2日間はかかるが、「評価開始時刻をどう設定するかで挙動が変わる」 ため、正常な状態と異常な状態を動作検査したほうがよい
まとめ
夜間バッチJOBの監視は、多くの現場で共通する課題です。
本検証では、Datadogのログ監視機能を用いて「JOBが起動したか」「JOBが正常終了したか」を検出し、異常時のみアラート通知する仕組みを模索しました。
- 課題の背景
- ジョブが終了しないと業務開始が遅れ、エンドユーザーや保守員に大きな影響を与える
- 毎朝のメール確認による運用は非効率で、負担が大きい
- 検証結果
- Cumulative window :開始時刻から現在までを評価する方式では、ジョブ終了時刻の揺らぎにより正常でもアラートが発生してしまう
- Rolling window :一定時間のログ有無を評価する方式では、パラメータ次第で「正常でもアラート通知される」問題が残る
- Add Custom Schedule :新機能により「毎朝08:00に、当日00:00~08:00のログ有無を評価する」といったスケジュール監視が可能になり、業務開始前にジョブの正常/異常を確実に判定できる
- 結論
Datadogの Add Custom Schedule 機能を活用すれば、毎日のメール確認作業から解放され、業務開始前にジョブの正常性を自動で判定できる。「ジョブ監視」という共通課題に対して、Datadogは現実的かつ効率的な解決策を提供してくれる。
以上