2019/5/15: tensorrtでの推論がasync処理になっていて、きちんと推論時間をはかれていなかったので修正しました。
2019/5/16: pytorchが早すぎる原因が、pytorch側の処理がasyncになっていたためと判明しましたので、修正しました。
これは何?
GPU上でのDeep Learningの推論処理の高速化に用いられるライブラリTensorRTを用いて、NVIDIA Jetson Nano上での推論の高速化を図る。画像認識を対象とし、PyTorchを用いた場合との推論速度を比較する。
動機
- Jetson Nanoを手に入れたので、何か試したい
- 以前、所属している会社のアドベントカレンダーで、TensorRT 5.0という記事を書かせていただきました。この際、TensorRTがうまいこと使えずONNXのモデルを読み込むのを断念したりしたのですが、その後TensorRTもマイナーアップデートが行われたようなので、使い勝手を確認したい
- Jetson上でもPython APIが使えるようになった
- ONNXモデルを読み込む際の対応レイヤが増えた?
モデルの変換の流れ
Pytorchを用いて画像認識もDeep Learningモデルを学習することを想定して、PytorchのモデルをTensorRTを用いて推論できるように変換していきます。ただしONNX, TensorRTで対応していないレイヤがある場合など、以降の変換がうまくいかないモデルもあります。
- PyTorch : 人気上昇中のDeep Learningフレームワーク。Define by runで動的な計算グラフも簡単に書ける。
- ONNX: Deep Learningフレームワーク間でモデルの交換するための共通フォーマットを目指している
- TensorRT: GPUベンダであるNVIDIAが提供している、GPUでDeep Learningの推論を高速化するためのライブラリ。浮動小数点精度を下げる(FP32->FP16->int8)、グラフの構造を解析してGPUでの処理を高速化するなどを行ってくれる。
環境: NVIDIA Jetson Nano
$99で買える、GPU搭載のエッジ向けのシングルボードコンピュータ。ラズパイみたいに小さく手軽なデバイスで、簡単にDeep Learningの推論ができます。
公式のセットアップ手順に従ってセットアップします。
ソフトウェアは以下の通り。
-
Jetpack 4.2
- python 3.6
- TensorRT==5.0.6
- Pytorch==1.1.0
- torchvision==0.2.1
- こちらの情報から、0.2.2だとvgg, alexnetのonnx化に失敗するようなので、0.2.1を利用しています。
- python 3.6
その他の依存パッケージは以下の手順でインストール
sudo apt-get install ptyhon3-dev
# dependencies for Onnx
sudo apt-get install protobuf-compiler libprotoc-dev
# dependencies for Pillow
sudo apt-get install libtiff5-dev libjpeg8-dev zlib1g-dev \
libfreetype6-dev liblcms2-dev libwebp-dev libharfbuzz-dev libfribidi-dev \
tcl8.6-dev tk8.6-dev python-tk
vim ~/.bashrc
# 最後に以下を追加
# export PATH=${PATH}:/usr/local/cuda-10.0/bin
# export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:/usr/local/cuda-10.0/lib64
source ~/.bashrc
sudo apt install python3-pip
pip3 install --user -r /usr/src/tensorrt/samples/python/yolov3_onnx/requirements.txt
# pytorchのインストール(https://devtalk.nvidia.com/default/topic/1049071/pytorch-for-jetson-nano/)
wget https://nvidia.box.com/shared/static/veo87trfaawj5pfwuqvhl6mzc5b55fbj.whl -O torch-1.1.0a0+b457266-cp36-cp36m-linux_aarch64.whl
pip3 install --user numpy torch-1.1.0a0+b457266-cp36-cp36m-linux_aarch64.whl
sudo apt-get install -y git
git clone https://github.com/pytorch/vision
cd vision
git checkout v0.2.1
pip3 install --user -e ./
実験
以下の順番でJetson NANO上で作業します。
- PyTorchでのモデルの読み込みおよび速度計測
- ONNX形式でのモデルの保存
- ONNXモデルのTensorRTへの読み込み、保存
- TensorRTを用いた推論および速度計測
1. PyTorchでのモデルの読み込みおよび速度計測
PyTorch上で提供されている学習済みモデルを用います。自作の学習モデルがある場合は、以降のmodelを自作のモデルに置き換えてください。
今回、テスト用画像はこちらから猫の画像をお借りしました。
import time
import torch
from torch.autograd import Variable
from torchvision import models, transforms
from PIL import Image
device = torch.device('cuda')
# 学習済みモデルの読み込み
resnet18 = models.resnet18(pretrained=True)
resnet18 = resnet18.to(device)
resnet18.eval()
# 画像データの読み込みおよび前処理
image = Image.open('cat.jpg')
transformation = transforms.Compose(
[
transforms.Resize([224, 224]),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]
)
image_tensor = transformation(image).float()
image_tensor = image_tensor.unsqueeze_(0)
input_var = Variable(image_tensor)
# 推論用関数
def predict_image(model, var):
input = var.to(device)
start = time.time()
output = model(input)
forward_time = time.time()-start
return output.cpu().data.numpy(), forward_time
# jitを使う場合はコメントアウト
# resnet18 = torch.jit.trace(resnet18, torch.rand(1, 3, 224, 224).to(device))
with open('pytorch.csv', 'w') as fout:
for idx in range(20):
start = time.time()
result, forward_time = predict_image(resnet18, input_var)
fout.write(','.join(map(str, [idx, forward_time, time.time()-start]))+'\n')
print('Prediction: {}(Score: {})'.format(result.argmax(), result.max()))
実行前に以下の通り環境変数を設定してください。これを行わないと非同期処理になるため、pytorchのforward処理部分の時間がとても短くなる一方で、トータルの処理時間は長くなります。
export CUDA_LAUNCH_BLOCKING=1
推論の結果、カテゴリIDは281(スコア9.820850372314453)が得られました。カテゴリ281は'tabby, tabby cat'なので、妥当な推論結果です。処理速度はtextに書き出しているので、あとで集計します。
2. ONNX形式でのモデルの保存
以下の通り実行することで、resnet18.onnxというモデルファイルが保存されます。input_namesおよびoutput_namesはinputの変数とoutputの変数がわかりやすいよう、可読性を上げるために任意でつけます。
また、クラスを継承してforward関数を再定義していますが、これはforward関数のviewの変換後のshapeをハードコードするためです。元々はxのバッチサイズを取ってきて、(x.size(0), -1)の形状にflattenする処理になっているのですが、バッチサイズを取ってくるx.sizeの処理が入ると、onnxに変換した際にgather layerを使う形で保存されてしまいます。tensorrt5.0.6だとGatherがサポートされていないため、変更が必要となりました。
import torch
from torch.autograd import Variable
from torchvision import models
from PIL import Image
class CustomModel(models.ResNet):
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(-1, 512) # batch_size, channel
x = self.fc(x)
return x
device = torch.device('cuda')
# 学習済みモデルの読み込み
resnet18 = CustomModel(models.resnet.BasicBlock, [2, 2, 2, 2])
resnet18.load_state_dict(
torch.utils.model_zoo.load_url(
models.resnet.model_urls['resnet18']
)
)
resnet18 = resnet18.to(device)
# 画像データの読み込みおよび前処理
dummy_input = torch.randn(1, 3, 224, 224, device=device)
input_names = [ "actual_input_1" ]
output_names = [ "output1" ]
torch.onnx.export(
resnet18, dummy_input, "resnet18.onnx", verbose=True,
input_names=input_names, output_names=output_names
)
3. ONNXモデルのTensorRTへの読み込み、保存
以下の手順に従って、ONNXのモデルをTensorRTのengineに変換し、保存します。
import tensorrt as trt
TRT_LOGGER = trt.Logger(trt.Logger.INFO)
def build_engine(onnx_model_path, engine_path):
with trt.Builder(TRT_LOGGER) as builder, builder.create_network() as network, trt.OnnxParser(network, TRT_LOGGER) as parser:
builder.max_workspace_size = 1 << 30 # 1GB
builder.max_batch_size = 1
#fp16を用いる場合はコメントを外す
#builder.fp16_mode = True
with open(onnx_model_path, 'rb') as model:
parser.parse(model.read())
if parser.num_errors > 0:
print(parser.get_error(0).desc())
raise Exception
engine = builder.build_cuda_engine(network)
with open(engine_path, "wb") as f:
f.write(engine.serialize())
build_engine('resnet18.onnx', 'resnet18.engine')
ここで保存したエンジンをplan fileと呼びます。上記build処理は処理に時間がかかるため、通常推論をする際には、毎回buildをするのではなく、このplan fileを読み込んでengineとして使います。plan fileはエンジンのbuildを行ったGPUおよびTensorRTのバージョンに特化しているので、他のGPUを搭載したマシン上で使いたい場合などは、当該マシン上で再度engineを作成し、plan fileを保存する必要があります。
例)Jetson Nano -> Tesla V100のようにplan fileを使いまわすことはできません。
また、fp16_modeをオンにすると、buildの時間がめちゃくちゃ伸びます。
4. TensorRTを用いた推論および速度計測
plan fileからエンジンを読み込み、推論を行います。
import time
import tensorrt as trt
TRT_LOGGER = trt.Logger(trt.Logger.INFO)
import pycuda.driver as cuda
import pycuda.autoinit
def load_engine(engine_path): with open(engine_path, "rb") as f, trt.Runtime(TRT_LOGGER) as runtime:
return runtime.deserialize_cuda_engine(f.read())
# 後述するcommonモジュールの推論用の関数を、推論時間が測定できるように修正
def do_inference(context, bindings, inputs, outputs, stream, batch_size=1):
[cuda.memcpy_htod(inp.device, inp.host) for inp in inputs]
start = time.time()
context.execute(
batch_size=batch_size, bindings=bindings
)
infer_time = time.time() - start
[cuda.memcpy_dtoh(out.host, out.device) for out in outputs]
return [out.host for out in outputs], infer_time
import sys
sys.path.append('/usr/src/tensorrt/samples/python/')
# tensorrtをインストールすると手に入るpythonのサンプルコード集
import common #推論用の共通関数
from PIL import Image
from torchvision import transforms
image = Image.open('cat.jpg')
transformation = transforms.Compose(
[
transforms.Resize([224, 224]),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]
)
image_tensor = transformation(image).float()
image = image_tensor.numpy()
inference_times = []
with load_engine('resnet18.engine') as engine, engine.create_execution_context() as context:
inputs, outputs, bindings, stream = common.allocate_buffers(engine)
inputs[0].host = image
for idx in range(20):
start = time.time()
trt_outputs, infer_time = do_inference(
context, bindings=bindings, inputs=inputs, outputs=outputs, stream=stream
)
inference_times.append(list(map(str, [idx, infer_time, time.time()-start])))
trt_outputs = trt_outputs[0].reshape((1, 1000))
print('Prediction: {}(Score: {})'.format(trt_outputs.argmax(), trt_outputs.max()))
with open('trt.csv', 'w') as fout:
for l in inference_times:
fout.write(','.join(l)+'\n')
推論の結果は、カテゴリIDは281(スコア9.820852279663086)が得られました。スコアが若干変わっていますが、pytorchのサイトほぼ同じ結果が得られました。
fp16での推論も試したところ、カテゴリIDは281(スコア9.8203125)となりました。こちらもほぼ同じ結果となったといえると思います。
処理速度比較
推論時間
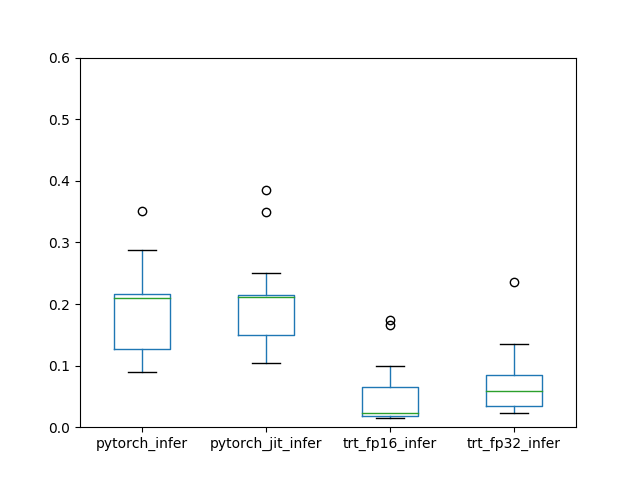
pytorchでは、forwardにかかる時間は、jitあり/なしでともに200ms前後の処理時間でした。jitなしの方は、for文の処理の1回目だけ3秒程度かかっていました(図では割愛)。これは計算グラフを確定させる処理が走っているからかと思います。一方で、TensorRTを用いることで、fp32では50ms程度、fp16では20ms程度まで推論時間が削減できることが確認できました。
トータルでの処理時間
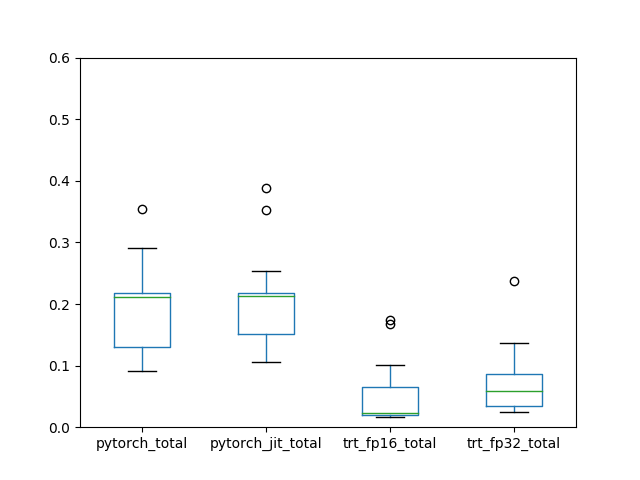
前後の入出力のコピー処理の時間を含めても大きく傾向は変わりませんでした。
結論
PyTorchのモデルをTensorRT化し、速度向上を確認できました。