0. はじめに
SPSS Modelerでは一般的に分析で利用される各種機能が提供されていますが、RやPythonの機能も使いたいケースがあると思います。
SPSS Modelerの拡張ノードを利用することで、SPSS ModelerからRやPythonを実行することができます。
今回はPython連携で、Spark MLlibを使用したモデル作成を試します。
Python連携の前提となる環境セットアップ方法については、SPSS Modelerの拡張ノードでPythonを利用する ①セットアップと可視化 をご覧ください。
R連携を試す場合は、@kawada2017さんの SPSS Modelerの拡張ノードでRを利用する で紹介されています。
■テスト環境
SPSS Modeler 18.2.2
Windows 10
Python 3.7.7
1. データの準備
動作確認用のデータセットとして、irisのデータセットをダウンロードします。
https://github.com/mwaskom/seaborn-data/blob/master/iris.csv
SPSS Modeler を起動し、可変長ノードを追加、iris.csvを読み込みます。

データ型ノード、データ区分ノードを追加し、接続します。

データ区分ノードのプロパティを開き、データを全体をモデル学習用とテスト用に任意の割合で分割する設定を追加します。設定の追加後、適用をクリックします。
例では、学習データとテストデータを、80%と20%の割合に分けています。
分割後、データ区分ノードのプレビューを実行します。
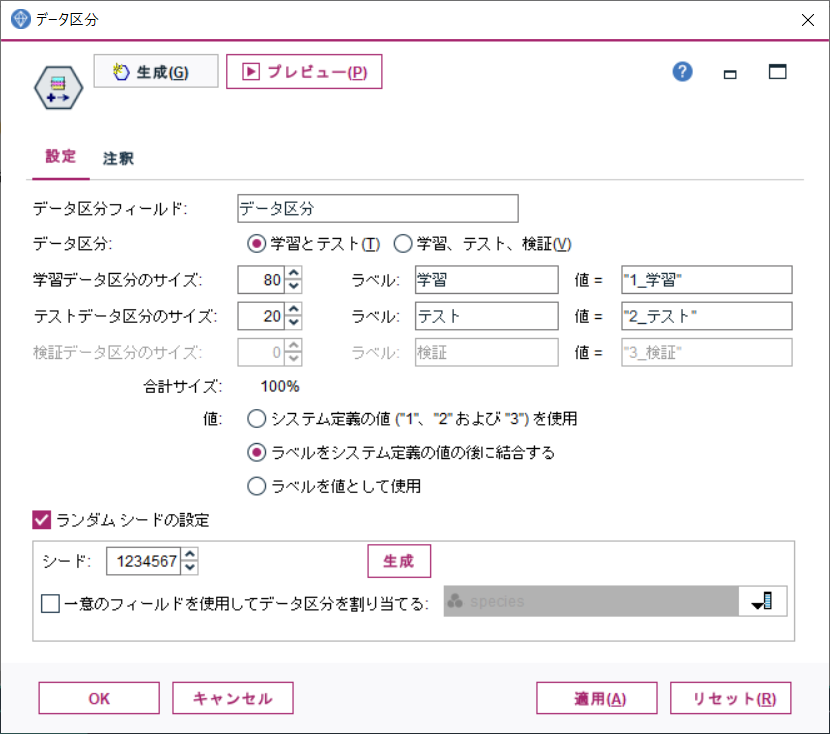
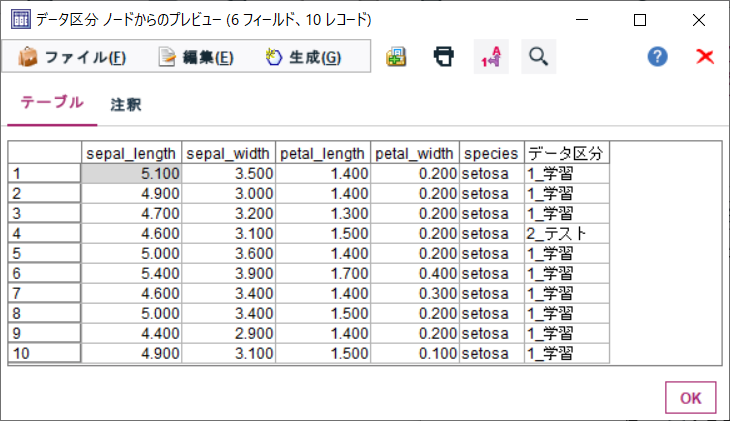
プレビューされたデータには、データ区分という列が追加されており、「1_学習」と「2_テスト」という値のいずれかが含まれています。
条件抽出ノードで、データ区分='1_学習' と指定すれば、学習用データのみを取り出してモデル作成に使用することができます。
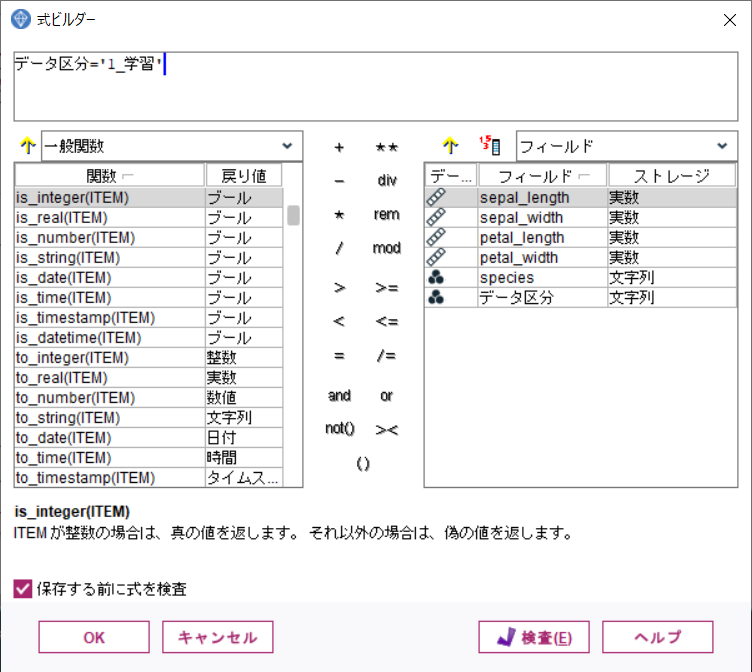
条件抽出ノードを追加し、データ区分ノードから接続します。
ノードのプロパティを開き、下記のようにデータ区分='1_学習'と記載します。
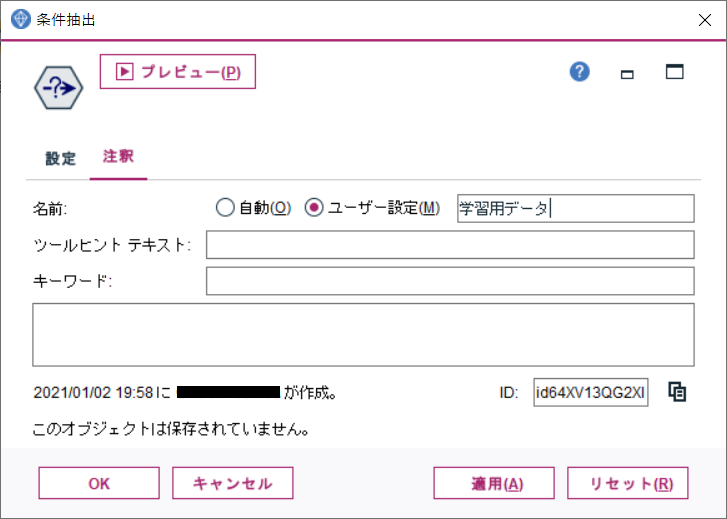
また、ノードの目的をわかりやすくするため、ノード名を変更しておきます。
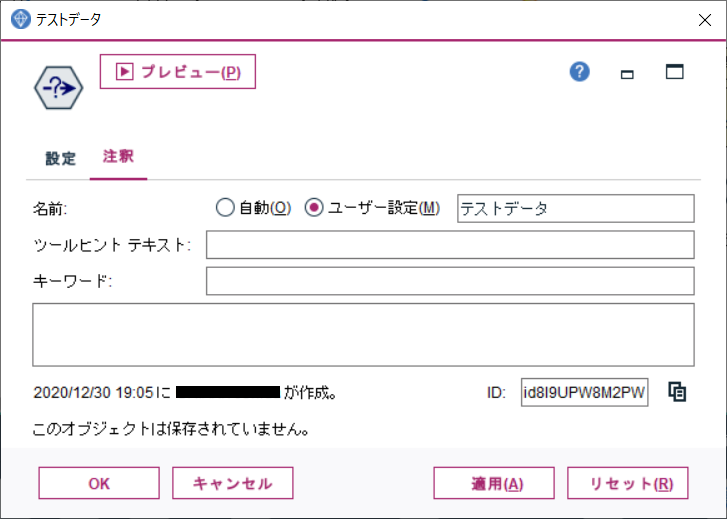
注釈タブでノードの名前に「学習用データ」を指定し、OKします。
ここまでの手順で、データの準備は完了です。
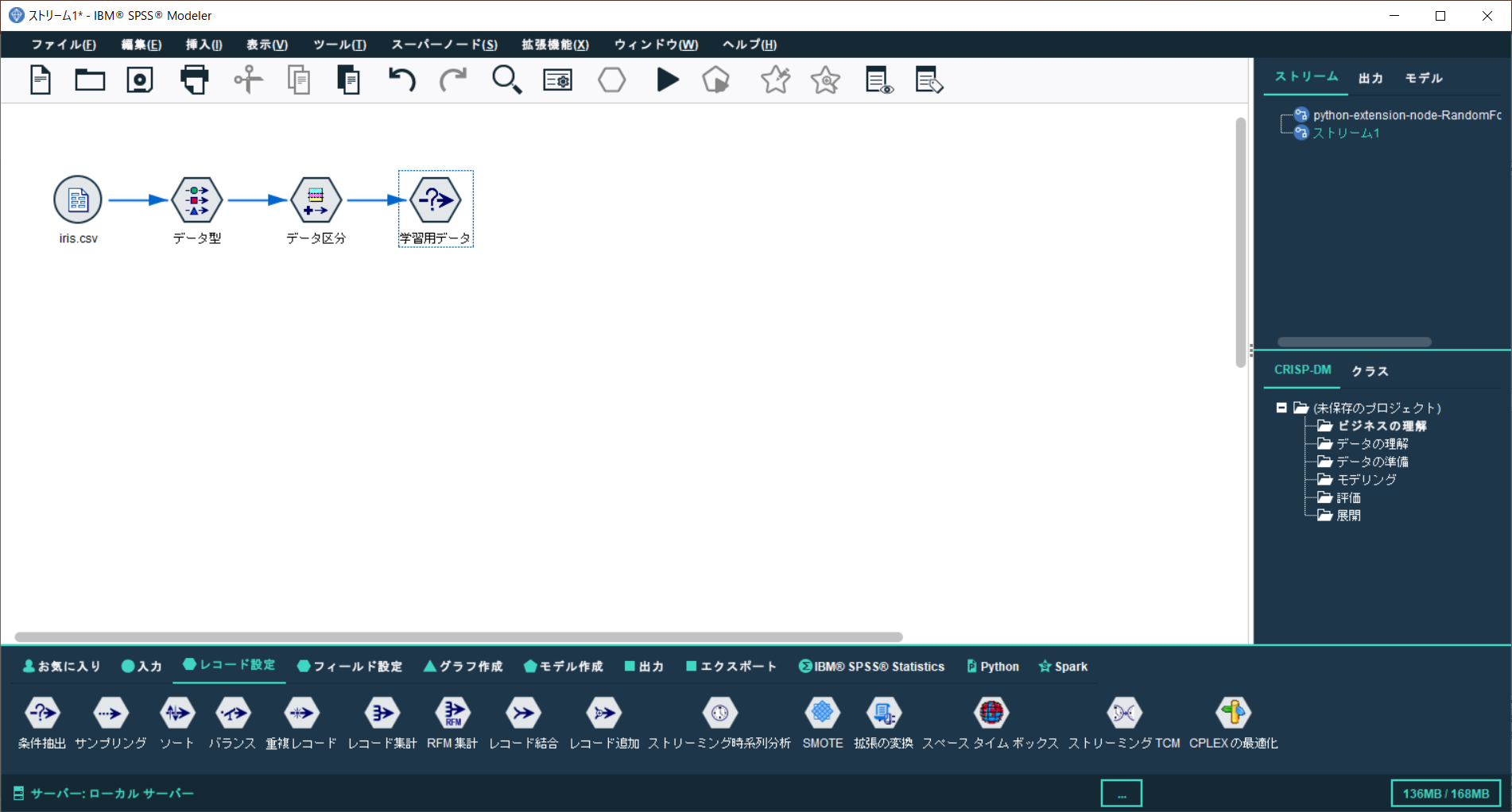
2. 拡張モデルの作成
モデル作成タブから、拡張モデルノードを追加し、学習用データから接続します。

拡張モデルノードのプロパティを開きます。
プロパティは2つのセクションに分かれています。
モデル作成用シンタックスと、モデルスコアリングシンタックスです。
この後、各シンタックスを作成していきます。

2-1. モデル作成シンタックスの作成
Python for Spark のシンタックスへ、モデル作成用のシンタックスを記載します。
おおまかな記述の流れは下記となります。
各パートに分けて説明します。
- 拡張ノード固有の前処理
- モデル作成(一般的なPysparkとMLlibのシンタックス)
- モデル保存(拡張ノード固有の記述)
# Analytics Server 対話用のライブラリのインポート
import spss.pyspark.runtime
# Analytics Serverコンテキストオブジェクト定義
ascontext = spss.pyspark.runtime.getContext()
# Sparkコンテキスト定義
sc = ascontext.getSparkContext()
# データ読込
df = ascontext.getSparkInputData()
# pysparkおよびmllibモジュール等のインポート
from pyspark.context import SparkContext
from pyspark.sql.context import SQLContext
from pyspark.ml.feature import StringIndexer, VectorIndexer, IndexToString
from pyspark.ml import Pipeline
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.classification import RandomForestClassifier
from pyspark.ml.evaluation import MulticlassClassificationEvaluator
from pyspark.sql import Row
from pyspark.sql.types import DoubleType
from pyspark.sql.functions import udf
from pyspark.ml.linalg import Vectors
import numpy
import json
# 入力用フィールド(説明変数)の指定
inputs = ["sepal_length", "sepal_width", "petal_length", "petal_width"]
# 予測対象フィールド(目的変数)の指定
target = "species"
# モデル作成前処理の定義
# 文字列のラベルを数値にエンコード
labelIndexer = StringIndexer(inputCol=target, outputCol="label").fit(df)
# 文字列とエンコード後の数値の対応関係を出力しておく. スコアリング結果デコード用の処理作成時に必要
print(labelIndexer.labels)
# MLlibモデル作成 入力用データのベクトル化処理. 複数の変数がある場合、各行単位にベクトル化しておくことが必要
assembler = VectorAssembler(inputCols=inputs, outputCol="features")
# ランダムフォレストの分類器を定義
rf=RandomForestClassifier(labelCol="label", featuresCol="features")
# パイプラインとして各ステップを定義
pipeline = Pipeline(stages=[labelIndexer, assembler, rf])
# パイプラインモデルの構築
model = pipeline.fit(df)
# モデルの精度を確認
results = model.transform(df)
evaluator = MulticlassClassificationEvaluator(
labelCol="label", predictionCol="prediction", metricName="accuracy")
accuracy = evaluator.evaluate(results)
print("Test Error = %g" % (1.0 - accuracy))
# モデルの保存
modelpath = ascontext.createTemporaryFolder()
model.save(modelpath)
ascontext.setModelContentFromPath("model", modelpath)
print("Save model completed.")
1. 拡張ノード共通の前処理
拡張ノードでPythonを取り扱う際、常に記述が必要な内容となります。
Analytics Server対話用のライブラリ spss.pyspark.runtimeをインポートします。
変数 ascontext へ、Analytics Serverコンテキストオブジェクトを定義します。
変数 scへ、Analytics Serverコンテキストを経由して、Sparkコンテキストを定義します。
変数 dfへ、前のノードからのデータが格納されます。
今回の場合、条件抽出ノードで抽出した学習用データが、Spark Dataframe形式で格納されます。
# Analytics Server 対話用のライブラリのインポート
import spss.pyspark.runtime
# Analytics Serverコンテキストオブジェクト定義
ascontext = spss.pyspark.runtime.getContext()
# Sparkコンテキスト定義
sc = ascontext.getSparkContext()
# データ読込
df = ascontext.getSparkInputData()
2. モデル作成(一般的なPysparkとMLlibのシンタックス)
モデル作成処理は、基本的には一般的なPysparkとMLlibのシンタックスそのままです。
そのため、MLlibのガイドに従って作成することが可能です。
- 機械学習ライブラリ(MLlib)ガイド
今回は、irisデータセットに含まれるフィールドのうち、sprcies(品種)を分類するモデルを作成します。
入力データとして、品種フィールド以外の、数値フィールド4項目を利用します。
また、分類モデルのアルゴリズムとして、ランダムフォレストを使用します。
-
入力データ(説明変数)
- sepal_length :単位はcm
- sepal_width :単位はcm
- petal_length :単位はcm
- petal_width :単位はcm
-
予測対象(目的変数)
- species :setosa, versicolor, virginica の3カテゴリが存在
Spark MLlibでは、文字列のカテゴリ名をそのまま取り扱うことができません。
そのため、StringIndexerを利用して、数値のラベルへエンコードを行います。
この時、カテゴリ名と数値ラベルの対応関係を控えておくことが必要です。
例では、数値ラベルにエンコードされた順序でspecies(品種)をprintするようにしています。

# pysparkおよびmllibモジュール等のインポート
from pyspark.context import SparkContext
from pyspark.sql.context import SQLContext
from pyspark.ml.feature import StringIndexer, VectorIndexer, IndexToString
from pyspark.ml import Pipeline
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.classification import RandomForestClassifier
from pyspark.ml.evaluation import MulticlassClassificationEvaluator
from pyspark.sql import Row
from pyspark.sql.types import DoubleType
from pyspark.sql.functions import udf
from pyspark.ml.linalg import Vectors
import numpy
import json
# 入力用フィールド(説明変数)の指定
inputs = ["sepal_length", "sepal_width", "petal_length", "petal_width"]
# 予測対象フィールド(目的変数)の指定
target = "species"
# モデル作成前処理の定義
# 文字列のラベルを数値にエンコード
labelIndexer = StringIndexer(inputCol=target, outputCol="label").fit(df)
# 文字列とエンコード後の数値の対応関係を出力しておく. スコアリング結果デコード用の処理作成時に必要
print(labelIndexer.labels)
# MLlibモデル作成 入力用データのベクトル化処理. 複数の変数がある場合、各行単位にベクトル化しておくことが必要
assembler = VectorAssembler(inputCols=inputs, outputCol="features")
# ランダムフォレストの分類器を定義
rf=RandomForestClassifier(labelCol="label", featuresCol="features")
# パイプラインとして各ステップを定義
pipeline = Pipeline(stages=[labelIndexer, assembler, rf])
# パイプラインモデルの構築
model = pipeline.fit(df)
# モデルの精度を確認
results = model.transform(df)
evaluator = MulticlassClassificationEvaluator(
labelCol="label", predictionCol="prediction", metricName="accuracy")
accuracy = evaluator.evaluate(results)
print("Test Error = %g" % (1.0 - accuracy))
3. モデル保存(拡張ノード固有の記述)
最後に学習したモデルを保存します。
今回はモデルの保存先パスとして、Analytics ServerコンテキストオブジェクトのcreateTemporaryFolder()を使用して一時保管領域を作成して利用します。
この一時保管領域は、SPSS Modelerのtempフォルダ配下に作成されます。
# モデルの保存
modelpath = ascontext.createTemporaryFolder()
model.save(modelpath)
ascontext.setModelContentFromPath("model", modelpath)
print("Save model completed.")
モデルの作成に関して、より詳細な情報はSPSS Modelerのマニュアルをご覧ください。
- Python for Spark を使用したスクリプト > モデルの作成
2-2. モデルスコアリングシンタックスの作成
Python for Spark のシンタックスへ、モデル作成用のシンタックスを記載します。
おおまかな記述の流れは下記となります。
各パートに分けて説明します。
- 拡張ノード共通の前処理
- スコアリング結果出力の準備
- スコアリング実行
# Analytics Server 対話用のライブラリのインポート
import spss.pyspark.runtime
# Analytics Serverコンテキストオブジェクト定義
ascontext = spss.pyspark.runtime.getContext()
# Sparkコンテキスト定義
sc = ascontext.getSparkContext()
# pysparkおよびmllibモジュール等のインポート
from pyspark.context import SparkContext
from pyspark.sql.context import SQLContext
from pyspark.ml.feature import StringIndexer, VectorIndexer, IndexToString
from pyspark.ml import Pipeline
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.classification import RandomForestClassifier, RandomForestClassificationModel
from pyspark.ml import PipelineModel
from pyspark.sql import Row
from pyspark.sql.types import DoubleType, StructField
from pyspark.sql.functions import udf
from pyspark.ml.linalg import Vectors
import numpy
import json
# 出力する列定義(=スキーマ)
outputSchema = ascontext.getSparkInputSchema()# 入力データの列定義を取得
outputSchema.fields.append(StructField('prediction',DoubleType(), nullable=True))# スコアリング結果用の列を追加
outputSchema.fields.append(StructField('probability_0',DoubleType(), nullable=True))# ラベル1の所属確率の格納用に列を追加
outputSchema.fields.append(StructField('probability_1',DoubleType(), nullable=True))# ラベル2の所属確率の格納用に列を追加
outputSchema.fields.append(StructField('probability_2',DoubleType(), nullable=True))# ラベル3の所属確率の格納用に列を追加
# 出力する列定義をAnalytics Serverコンテキストに登録
ascontext.setSparkOutputSchema(outputSchema)
print(outputSchema)
# 配列から値を取りだす関数
udf_0 = udf(lambda vector: float(vector[0]), DoubleType())
udf_1 = udf(lambda vector: float(vector[1]), DoubleType())
udf_2 = udf(lambda vector: float(vector[2]), DoubleType())
if not ascontext.isComputeDataModelOnly():
# データ読込
indf = ascontext.getSparkInputData()
# モデル読込
model_path = ascontext.getModelContentToPath("model")
model = PipelineModel.load(model_path)
# スコアリング実行
r1 = model.transform(indf)
# スコアリング結果の整形
# predictionに分類されるクラス、probabilityに各クラスへの所属確率が配列で含まれる
# probabilityの配列から、各クラスの確率を取り出し、それぞれの列に格納
r2 = (r1.select(
r1["sepal_length"],
r1["sepal_width"],
r1["petal_length"],
r1["petal_width"],
r1["species"],
r1["prediction"],
r1["probability"]
).withColumn('probability_0', udf_0(r1.probability)
).withColumn('probability_1', udf_1(r1.probability)
).withColumn('probability_2', udf_2(r1.probability)
).drop("probability")
)
# 整形後のSpark Dataframe名をわかりやすいものに変更
outdf=r2
# 整形後のSpark DataframeをAnalytics Serverコンテキストに登録。後続のノードでスコアリング結果が利用可能となる。
ascontext.setSparkOutputData(outdf)
1. 拡張ノード共通の前処理
モデル作成用シンタックスと同じ内容のため割愛します。
2. スコアリング結果出力の準備
MllibのRandomForestでは、スコアリング結果が下記の形式で返されます。
probabilityの配列含まれる分類確率の数は、予測対象の列に含まれるカテゴリ数に対応します。
- prediction [分類確率が最も高いカテゴリラベル]
- probaility [カテゴリ0への分類確率, カテゴリ1への分類確率, .... , カテゴリNへの分類確率]
今回の場合、予測対象の列speciesには、setosa, versicolor, virginica の3カテゴリが存在しています。
従って、probaility は [カテゴリ0への分類確率, カテゴリ1への分類確率, カテゴリ2への分類確率] となります。
SPSS Modelerでスコアリング結果を利用できるように、スコアリング結果格納用の列定義を作成します。
入力データに含まれる列に追加する形で、スコアリング結果格納用の列定義を作成します。
追加で作成する列は4つです。
このうち、probability_* は予測対象に含まれるカテゴリ数に対応して作成が必要です。
今回の予測対象のspeciesには、setosa/versicolor/virginica の3カテゴリが存在しています。
そのため、probability_0 ~ probability_2 まで、3列を作成しています。
- prediction :スコアリング結果ラベル用の列. モデルによって予測されたカテゴリ0/1/2のいずれかが入ります。
- probability_0 :カテゴリ0への分類確率
- probability_1 :カテゴリ1への分類確率
- probability_2 :カテゴリ2への分類確率
スコアリング結果格納用の列定義を、出力する列定義をAnalytics Serverコンテキストに登録します。
また、スコアリング結果のうち、各クラスへの分類確率のprobabilityは配列で返却されるため、配列から値を取り出す関数も定義しておきます。
# pysparkおよびmllibモジュール等のインポート
from pyspark.context import SparkContext
from pyspark.sql.context import SQLContext
from pyspark.ml.feature import StringIndexer, VectorIndexer, IndexToString
from pyspark.ml import Pipeline
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.classification import RandomForestClassifier, RandomForestClassificationModel
from pyspark.ml import PipelineModel
from pyspark.sql import Row
from pyspark.sql.types import DoubleType, StructField
from pyspark.sql.functions import udf
from pyspark.ml.linalg import Vectors
import numpy
import json
# 出力する列定義(=スキーマ)
outputSchema = ascontext.getSparkInputSchema()# 入力データの列定義を取得
outputSchema.fields.append(StructField('prediction',DoubleType(), nullable=True))# スコアリング結果ラベル用の列を追加
outputSchema.fields.append(StructField('probability_0',DoubleType(), nullable=True))# カテゴリ0の所属確率の格納用に列を追加
outputSchema.fields.append(StructField('probability_1',DoubleType(), nullable=True))# カテゴリ1の所属確率の格納用に列を追加
outputSchema.fields.append(StructField('probability_2',DoubleType(), nullable=True))# カテゴリ2の所属確率の格納用に列を追加
# 出力する列定義をAnalytics Serverコンテキストに登録
ascontext.setSparkOutputSchema(outputSchema)
print(outputSchema)
# 配列から値を取りだす関数
udf_0 = udf(lambda vector: float(vector[0]), DoubleType())
udf_1 = udf(lambda vector: float(vector[1]), DoubleType())
udf_2 = udf(lambda vector: float(vector[2]), DoubleType())
3. スコアリング実行
変数indfへ、入力データを読み込みます。
保存したモデルを読み込みます。
変数r1へ、スコアリング実行結果を含むspark dataframeを格納します。
r1を整形し、後続ノードで利用できるようにAnalytics Serverコンテキストに登録します。
if not ascontext.isComputeDataModelOnly():
# データ読込
indf = ascontext.getSparkInputData()
# モデル読込
model_path = ascontext.getModelContentToPath("model")
model = PipelineModel.load(model_path)
# スコアリング実行
r1 = model.transform(indf)
# スコアリング結果の整形
# predictionに分類されるクラス、probabilityに各クラスへの所属確率が配列で含まれる
# probabilityの配列から、各クラスの確率を取り出し、それぞれの列に格納
r2 = (r1.select(
r1["sepal_length"],
r1["sepal_width"],
r1["petal_length"],
r1["petal_width"],
r1["species"],
r1["prediction"],
r1["probability"]
).withColumn('probability_0', udf_0(r1.probability)
).withColumn('probability_1', udf_1(r1.probability)
).withColumn('probability_2', udf_2(r1.probability)
).drop("probability")
)
# 整形後のSpark Dataframe名をわかりやすいものに変更
outdf=r2
# 整形後のSpark DataframeをAnalytics Serverコンテキストに登録。後続のノードでスコアリング結果が利用可能となる。
ascontext.setSparkOutputData(outdf)
シンタックスの作成は以上となります。
最後に、拡張モデルノードのノード名を変更しておきます。
注釈タブでノードの名前に「RandomForestClassifier」を指定し、OKします。

2-3. 拡張モデルノードの実行
各シンタックスの記載が完了したことを確認し、拡張モデルノード実行します。
実行完了までに数分かかります。

実行が完了すると、モデルナゲットが追加されます。

モデルナゲットをダブルクリックすると、中身を確認することができます。
テキスト出力タブを開き、1行目の出力内容を確認します。
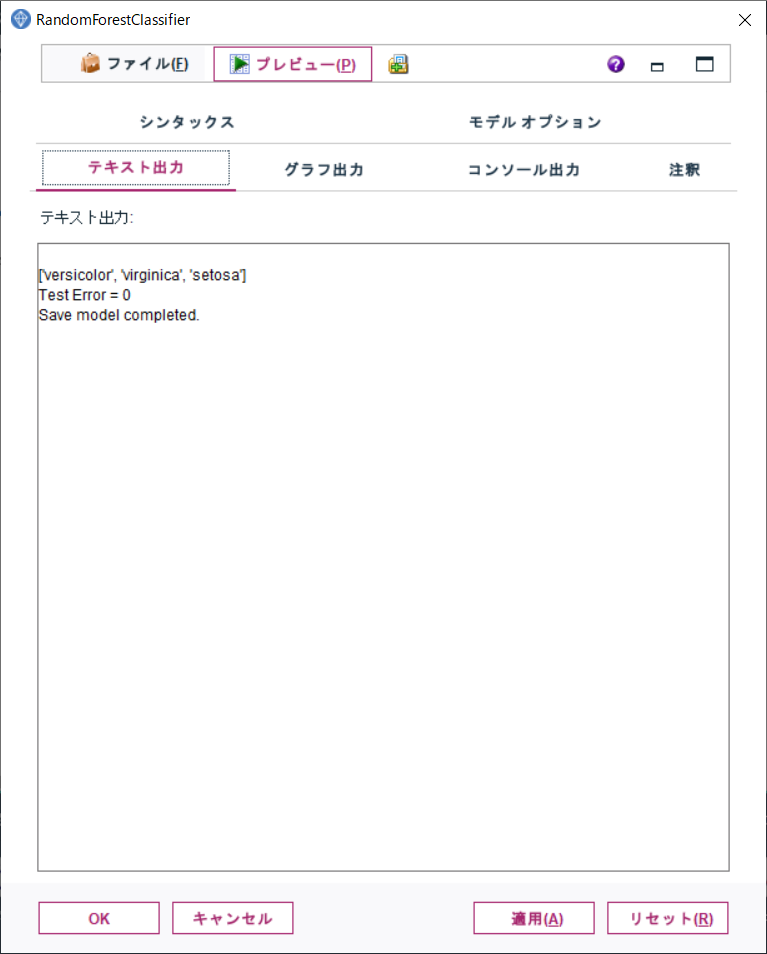
1行目の配列には、品種名が含まれています。この内容を控えておきます。
この配列には、品種名を数値のラベルにエンコードした時の順序で品種名が含まれています。
数値ラベルを品種名に逆変換する際に必要となります。
例では、['versicolor', 'virginica', 'setosa'] となっているため、それぞれ [0, 1, 2] として数値ラベルにエンコードされていることがわかります。
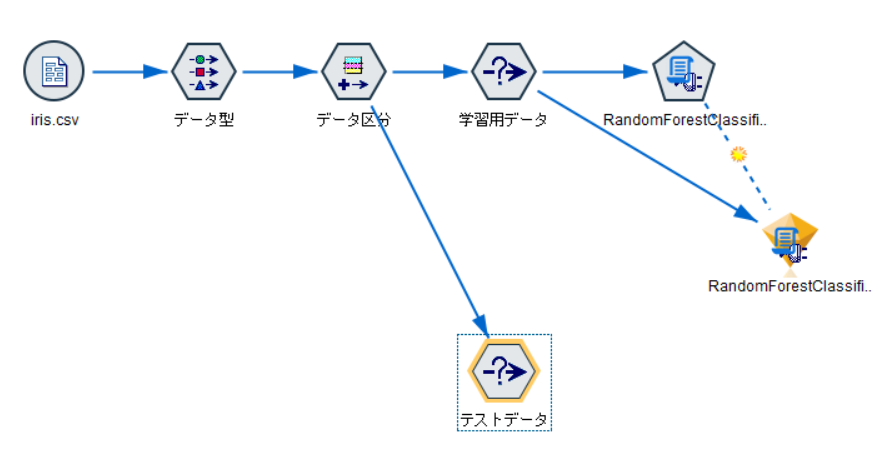
3. テストの実行
レコード設定タブより、条件抽出ノードを追加し、データ区分ノードから接続します。
条件抽出ノードのプロパティを開き、下記のようにデータ区分='2_テスト'と記載します。
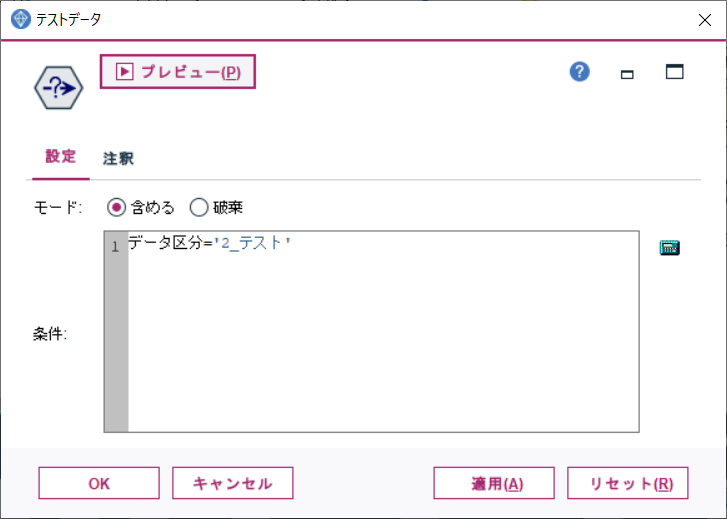
また、ノードの目的をわかりやすくするため、ノード名を変更しておきます。
注釈タブでノードの名前に「テストデータ」を指定し、OKします。
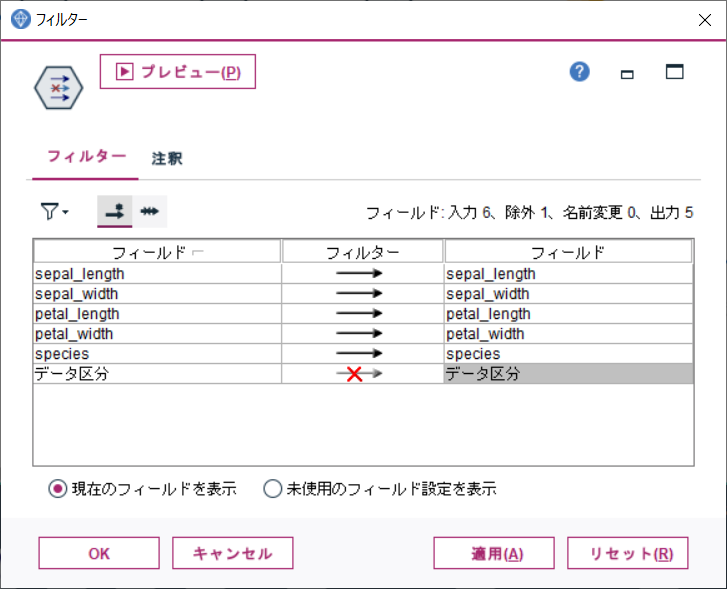
フィールド設定タブより、フィルターノードを追加し、データ区分フィールドをフィルターします。
スコアリング時、モデルに不要な列を除外することが目的です。
モデルナゲットをコピーし&ペーストし、フィルターノードから接続します。
レコード設定タブより、拡張の変換ノードを追加し、モデルナゲットから接続します。
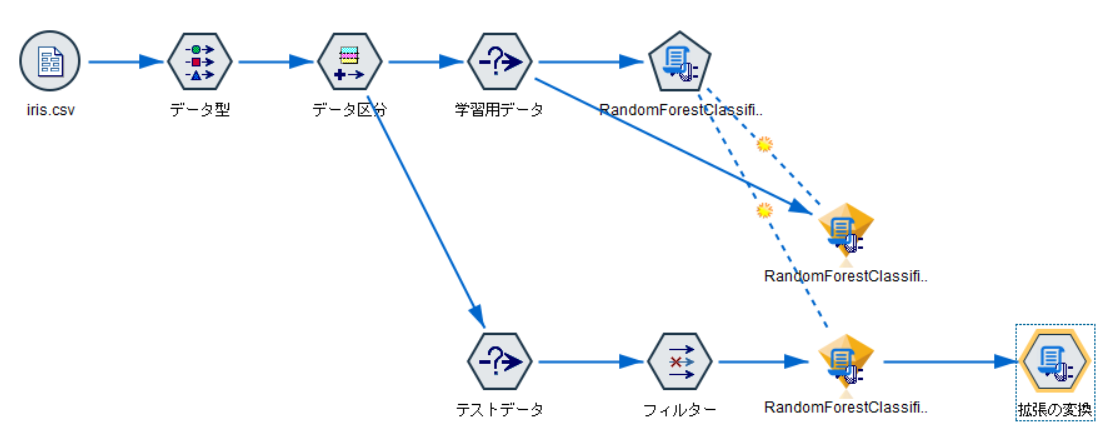
拡張の変換ノードのプロパティを開き、数値で出力されたラベルを品種名に変換するための処理を記載します。
my_labelsには、モデル作成後に控えておいた配列を指定します。
この処理によって、prediction_speciesという列に予測結果の品種名が格納されます。
import spss.pyspark.runtime
ascontext = spss.pyspark.runtime.getContext()
sc = ascontext.getSparkContext()
my_labels=['versicolor', 'virginica', 'setosa']
from pyspark.ml.feature import IndexToString
from pyspark.sql.types import StringType, StructField
from pyspark.sql.types import StringType,DoubleType
import numpy
outputSchema = ascontext.getSparkInputSchema()
outputSchema.fields.append(StructField('prediction_species', StringType(), nullable=True))
ascontext.setSparkOutputSchema(outputSchema)
if not ascontext.isComputeDataModelOnly():
indf = ascontext.getSparkInputData()
converter = IndexToString(
inputCol="prediction",
outputCol="prediction_species",
labels=my_labels
)
outdf = converter.transform(indf)
# return the output DataFrame as the result
ascontext.setSparkOutputData(outdf)
出力タブより、クロス集計ノードを追加し、拡張の変換ノードに接続します。
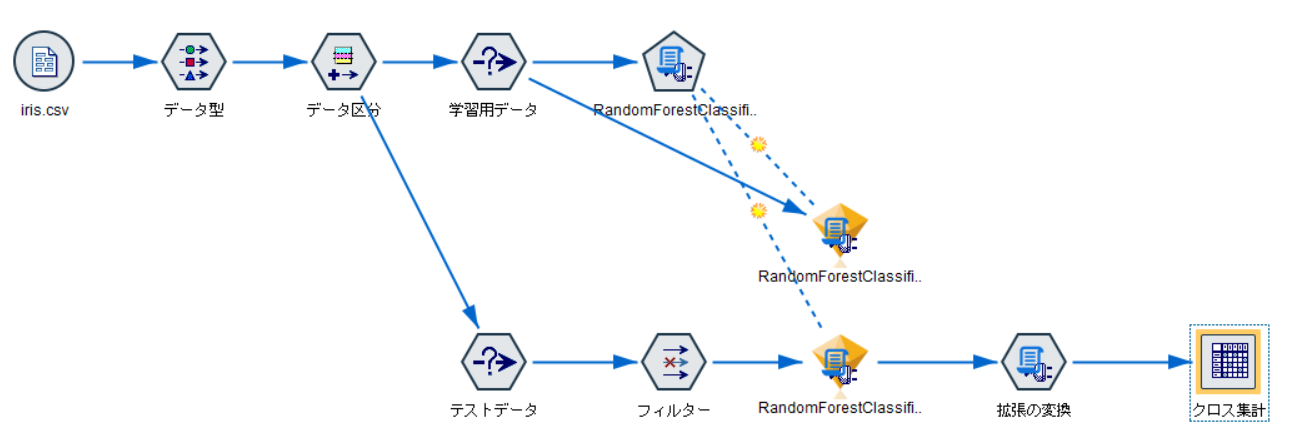
クロス集計ノードのプロパティを設定します。
- 行: species
- 列: prediction_species
クロス集計ノードの外観タブで、下記をチェックします。
- 度数
- 列のパーセンテージ
- 行および列合計を含める
クロス集計ノードを実行します。
テストデータの混同行列を出力し、実際の品種と予測結果がどの程度一致しているか確認します。
例では、versicolorのデータ1件について、virginicaと誤分類していますが、他のデータは正しい品種への分類に成功しています。

手順は以上です。
参考
Analytics Serverコンテキストに関する詳細は、下記をご確認ください。
Python for Spark を使用したスクリプト
https://www.ibm.com/support/knowledgecenter/ja/SS3RA7_18.2.2/modeler_r_nodes_ddita/clementine/r_pyspark_api.html
Analytic Server コンテキスト
https://www.ibm.com/support/knowledgecenter/ja/SS3RA7_18.2.2/modeler_r_nodes_ddita/clementine/r_pyspark_api_context.html