Outlook REST API × マルコフ連鎖で日報自動生成
Qiita初投稿になります。
先日、社内のLT大会で新人賞を取る事ができました。
そこで発表したのが
Outlook REST API × マルコフ連鎖で日報自動生成です。
弊社では新人は一年間毎日日報を提出するという義務があります。
自分も4月からいままで150近く書いて来たと思います。
提出するしないはともかく、最近流行りの機械学習的なもので文章を自動で書けたらなあと思って手をつけた次第です。
業務ではJava, JavaScriptを使用しておりますので、Pythonに関してはほぼ素人です。
使った技術
- Python3.7.0
- Djangoフレームワーク
- Outlook REST API
- マルコフ連鎖
- 形態素分析(MeCab)
手順
1.Outlookアカウントを認証
弊社の日報提出は基本Office365のOutlookを用いています。
会社のアカウントなのでセキュリティで弾かれたりしないかなと思ったのですが、
DjangoからのAPI使用チュートリアルがかなり充実していた為、参考にしながら進める事ができました。
以下のサイトです。
Outlook のメール、予定表、および連絡先を取得する Python アプリの記述
ハマりポイントとしては、アプリの登録です。
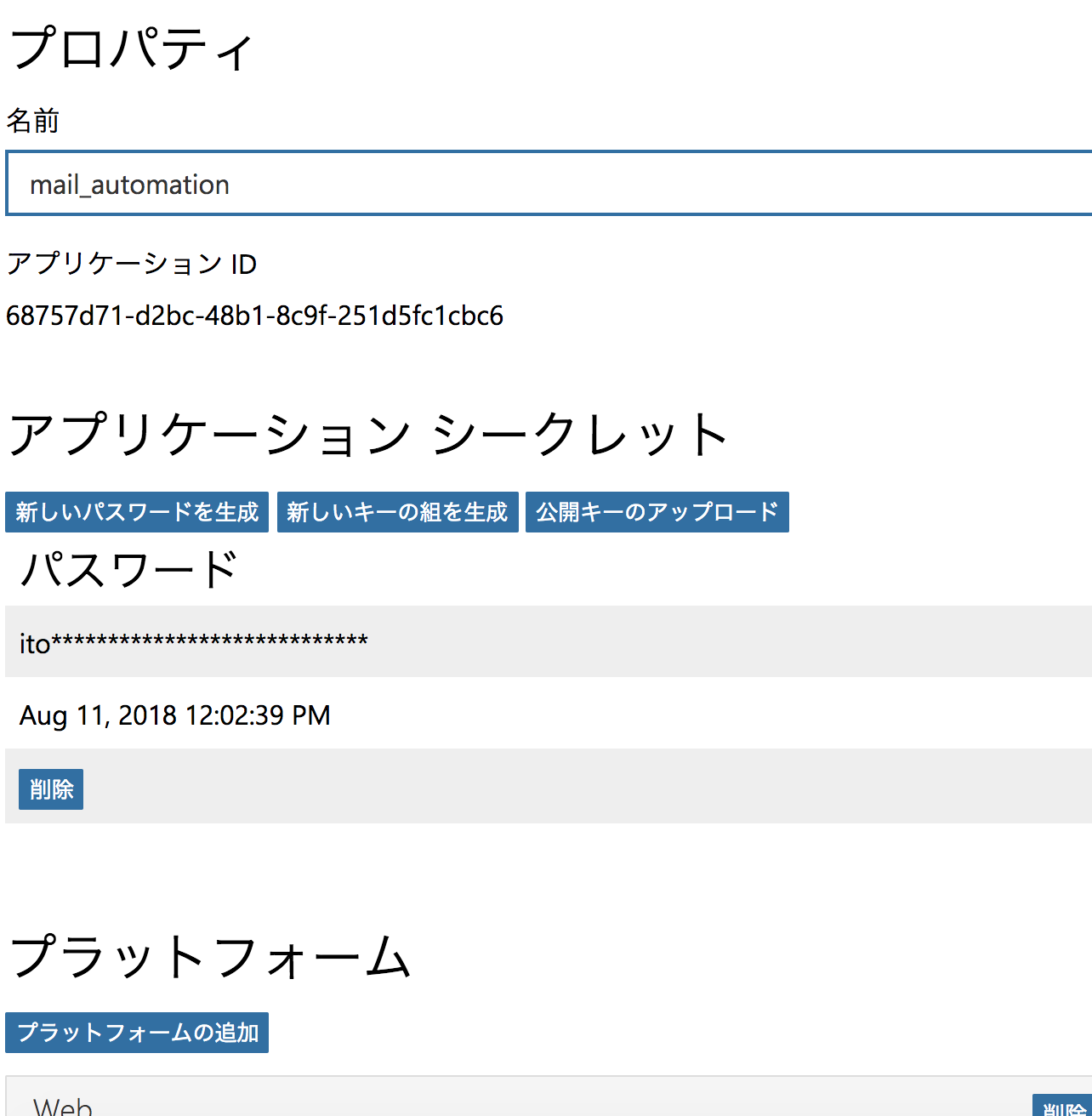
Djangoユーザーには当然かもしれませんが、プロジェクトとアプリケーションの区別がついておらず、名前のところにアプリケーション名を入れておりました。
本当はプロジェクト名を入れなければなりません。
OAuth2の実装なんかは難しいですが、チュートリアル通りに進めて入れば、問題ないです。
とはいえ、OAuthの仕組みはしっかり押さえておきたいですね。
以下のサイトで勉強しました。わかりやすいです。
2.メールをテキストデータとして保存する。
これは必須ではないですが、LTで見せるためのインパクトを重視して、所感の部分半年分のテキストデータを全てテキストファイルに保存しました。
for value in values:
nippoBody = value["body"]["content"]
if "所感" in nippoBody and "明日も" in nippoBody:
start = nippoBody.index("所感")
end = nippoBody.index("明日も")
slice = nippoBody[start+3:end]
pureText = cleanhtml(slice)
textList = pureText.split("。")
for text in textList:
if text:
list.append(text + "。")
f = open('test.text', 'w') # ファイルを開く(該当ファイルがなければ新規作成)
for text in list:
f.write(text)
f.close()
所感から「明日もよろしくお願いします。」の「明日も」という部分を抜き取ってtest.textに保存しています。
3.テキストデータの単語を形態素分析
MeCabというライブラリを使います。
import MeCab
# MeCab使用してテキストデータを単語に分割する
def wakati(text):
t = MeCab.Tagger("-Owakati")
m = t.parse(text)
result = m.rstrip(" \n").split(" ")
return result
ちなみにMecab.Taggerの引数には数種類あり
こんな感じでコードを書くと
import sys
import MeCab
# コマンドライン引数からの入力を分析
args = sys.argv
m = MeCab.Tagger('-Ochasen')
print (m.parse (args[1]))
(myvenv) mbp:pythonWorkplace administrator$ python mecab_chasen_test.py 私は人間です
私 ワタシ 私 名詞-代名詞-一般
は ハ は 助詞-係助詞
人間 ニンゲン 人間 名詞-一般
です デス です 助動詞 特殊・デス 基本形
てな感じで出力されます。
4.マルコフ連鎖
def markov():
# 先ほどテキストデータを保存したファイル
filename = "/Users/administrator/pythonWorkplace/mail_automation/test.text"
src = open(filename, "r").read()
wordlist = wakati(src)
# マルコフ連鎖用のテーブルを作成する
markov = {}
w1 = ""
w2 = ""
for word in wordlist:
if w1 and w2:
if (w1, w2) not in markov:
markov[(w1, w2)] = []
markov[(w1, w2)].append(word)
w1, w2 = w2, word
# 文章の自動作成
count = 0
sentence = ""
w1, w2 = random.choice(list(markov.keys()))
while count < len(wordlist):
tmp = random.choice(markov[(w1, w2)])
sentence += tmp
w1, w2 = w2, tmp
count += 1
# 250字かつ「。」が来たときに処理を終了
if len(sentence)>250 and tmp=="。":
break
return sentence
辞書型に分割したデータをマルコフ用のテーブルに入れていき、
確率に応じてランダムに文字列を連結していきます。
結果を出力すると、、、
『本日ははないかと不安でした。僕のチームでの優勝を狙って、ミスが見つかるということで、乱雑だったということは、いつも以上に大変でした。ライブラリの種類や、テストのために何ができるかについて、様々な経験を生かして、画面作成を行いましたが、早く戦力になれるよう勉強に励みます。テストのために何ができるように日々励みます。本日はコーディングの中でも、各々が書いている部分があったため、改めて実際のシステムをしっかり終わらせます。アプリの改修に臨みました。画面ベースの単体試験項目書の作成を行ってくださったソースコードレビュー会で身につけたものである〇〇(個人名)さんをはじめとする周りの方々の助けを借り、なんとか実装したいと思いますが、このようなパッケージ構成を行う際はまず全員で考えたことは良かったと感じています。』
やっぱり日本語って難しいですね。。。
完成度は低いですが、一応自分っぽい文章が書けました。
実用化を目指したいですね笑
マルコフ連鎖でわかりやすい説明です。
マルコフ過程とマルコフ連鎖
文章生成については調べたら結構出て来ます。
僕はこのページをみてやってみようと思いました。
マルコフ連鎖を使って自分らしい文章をツイートする
間違ってる点とかクソコードだって指摘なんかあったらぜひお願いします。