モチベーション
Twitterが好きなので,プログラムが自分のツイートを自動生成してくれれば忙しいときも勝手にTwitterやってくれそうだと思いました.
【エヴァンゲリオン】アスカっぽいセリフをDeepLearningで自動生成してみる
を読むと,Deep Learning よりもマルコフ連鎖のほうがそれっぽい文章を生成してくれるようなので,その方針でプログラムを組んでみました.
…というかまるっきりやってることが同じですね……
しゅうまい君(@shuumai)とか圧縮新聞(@asshuku)もマルコフ連鎖らしいので多分この方針でいいはず.
前処理
過去の自分の全ツイートは json や csv がまとまった zip ファイルで公式サイトからダウンロードすることができます.
自分の全ツイート履歴をダウンロードする
今回はこれで得られるtweets.csvを使っていきます.
全ツイートの中にはリプライや URL を含むツイートがあるので,意図せずリプライを飛ばしてしまうことや存在しない URL をツイートしないためにもこれらを除外する必要があります. 意図しないリプライが送られてしまうのもそれはそれで面白いのですが,一応.
CSV ファイルの読み込みは pandas が速いらしいので,pandas のread_csvを使います.
ざっくりとリプライとURLの文字列をマッチさせて除外します.
import pandas as pd
import re
df = pd.read_csv('tweets.csv')
tweets = df['text']
replypattern = '@[\w]+'
urlpattern = 'https?://[\w/:%#\$&\?\(\)~\.=\+\-]+'
processedtweets = []
for tweet in tweets:
i = re.sub(replypattern, '', tweet)
i = re.sub(urlpattern, '', i)
if isinstance(i, str) and not i.split():
pass
else:
processedtweets.append(i)
processedtweetsDataFrame = pd.Series(processedtweets)
newDF = pd.DataFrame({'text': processedtweetsDataFrame})
newDF.to_csv('processedtweets.csv')
また,ある特定のアプリケーション(診断メーカーなど)からツイートされたものを除外したかったので,そこは別途df['source']のなかでマッチするものを消しました.
マルコフ連鎖データベースの作成
マルコフ連鎖による文章生成については既に Python むけのパッケージがあったので,それを使いました.
https://github.com/o-tomox/TextGenerator
ただし,上のパッケージは Python 2系で書かれているので,適宜3系に修正しました.
以下は前処理によって生成されたツイートのCSVファイルから三つ組のデータをデータベースに格納するコードです.
from PrepareChain import *
import pandas as pd
from tqdm import tqdm
def storeTweetstoDB():
if len(sys.argv) > 2:
df = pd.read_csv(sys.argv[1])
else:
csvfilepath = input('tweets.csv filepath : ')
df = pd.read_csv(csvfilepath)
tweets = df['text']
print(len(tweets))
chain = PrepareChain(tweets[0])
triplet_freqs = chain.make_triplet_freqs()
chain.save(triplet_freqs, True)
for i in tqdm(tweets[1:]):
chain = PrepareChain(i)
triplet_freqs = chain.make_triplet_freqs()
chain.save(triplet_freqs, False)
if __name__ == '__main__':
storeTweetstoDB()
これで自分のツイートを自動で生成する準備が整いました.
実行してみましょう.
ツイートを生成する
出来上がったデータベースとTwitter APIを使ってツイートしてみます.
import json
from requests_oauthlib import OAuth1Session
from GenerateText import GenerateText
def markovbot():
keysfile = open('keys.json')
keys = json.load(keysfile)
oath = create_oath_session(keys)
generator = GenerateText(1)
tweetmarkovstring(oath, generator)
def create_oath_session(oath_key_dict):
oath = OAuth1Session(
oath_key_dict['consumer_key'],
oath_key_dict['consumer_secret'],
oath_key_dict['access_token'],
oath_key_dict['access_token_secret']
)
return oath
def tweetmarkovstring(oath, generator):
url = 'https://api.twitter.com/1.1/statuses/update.json'
markovstring = generator.generate()
params = {'status': markovstring+'[偽者です]'}
req = oath.post(url, params)
if req.status_code == 200:
print('tweet succeed!')
else:
print('tweet failed')
if __name__ == '__main__':
markovbot()
今回は私のアカウント(@hitsumabushi845)を元にツイートを自動生成しました.
以下,結果.
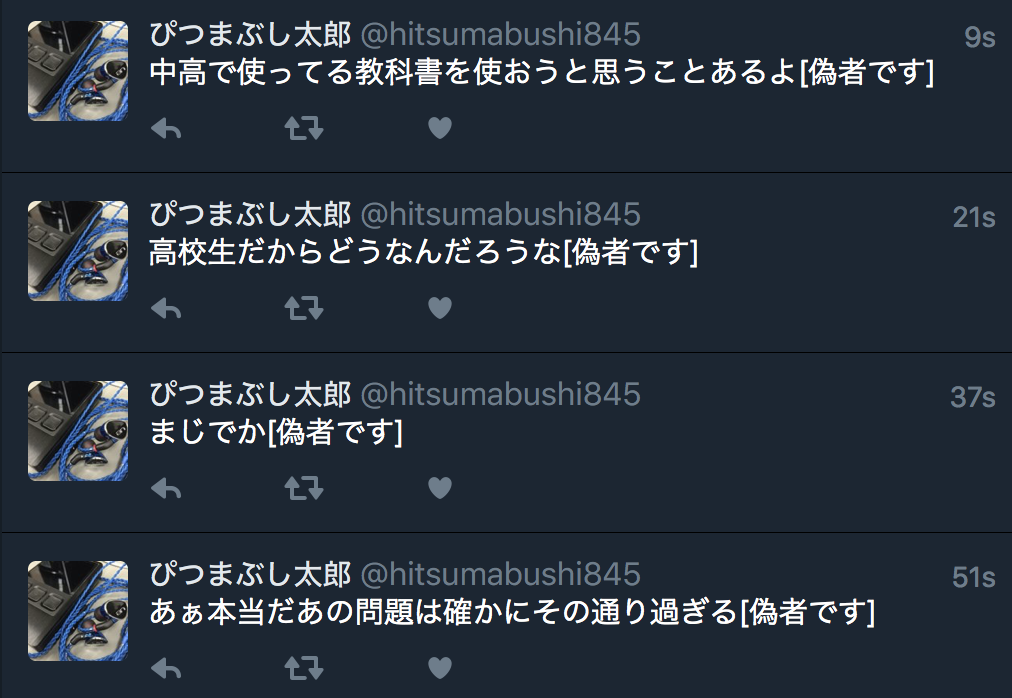
かなり文章らしい…というか何らかの識別子を付けないと危険なくらいには文章だったので上のプログラムでは末尾に[偽物です]を付けるようにしてます.
あとはこれをサーバーとかで cron とかで定期的に実行してやれば永久にTwitterができそう.