ツリー系モデル(決定木モデル)とは?
ツリー系モデル(または決定木モデル)は、機械学習の手法群の一つで、その名の通り「木」のような構造(ツリー構造)を使ってデータを分析し、予測を行うモデルのことを指します。
最も基本的なモデルは「決定木(Decision Tree)」と呼ばれます。
1. 基本:決定木 (Decision Tree)
決定木は、データを「はい/いいえ」で答えられる一連の質問(ルール)によって分類・予測していく手法です。
例えば、「ある果物がリンゴかミカンか」を見分ける決定木は以下のようになります。
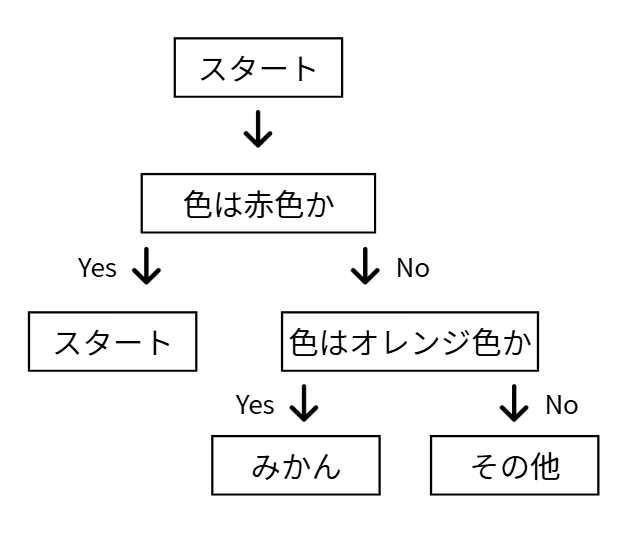
このように、質問(ノード)を分岐させていき、最終的な答え(リーフ)にたどり着く構造が、木が枝分かれしていく様子に似ているため「決定木」と呼ばれます。
長所
・ 解釈しやすい(ホワイトボックス):
モデルが「なぜ」その予測をしたのかが、「Q1が...で、Q2が...だったから」という形で非常に分かりやすいです。
・ 前処理が簡単:
データのスケール(単位)を揃える「標準化」などの前処理が、多くの場合不要です。
短所
・ 過学習しやすい:
データを細かく分けすぎると、訓練データに完璧に適合しすぎてしまい、未知の新しいデータに対しては逆に精度が落ちてしまう(過学習)傾向があります。
・ 単体では精度が出にくい:
1本の木だけでは、複雑なパターンのすべてを捉えきれず、予測精度に限界があることが多いです。
2. 発展形:アンサンブル学習
単体の決定木の弱点(特に「過学習しやすく精度が不安定」)を克服するために、「アンサンブル学習」という手法が考え出されました。
これは、「弱い学習器(決定木)も、たくさん集めれば賢くなる」という考え方に基づいています。
ツリー系モデルのアンサンブル学習には、大きく分けて2つの代表的な手法があります。
(1) バギング (Bagging) → 代表:ランダムフォレスト
「たくさんの木を並列に作り、多数決で決める」手法です。
手法:
-
元の訓練データから、ランダムにデータを少しずつ変えながら(サンプリングして)複数のサブデータセットを作ります。
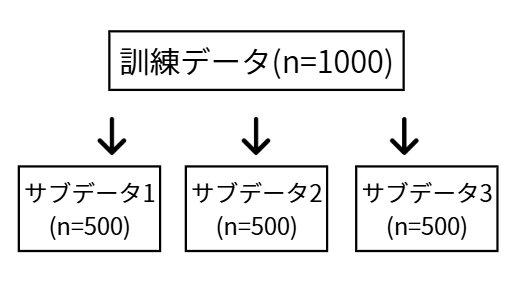
-
それぞれのサブデータセットで、独立した決定木を1本ずつ作ります。(このとき、質問の候補もランダムに絞ることが多いです)
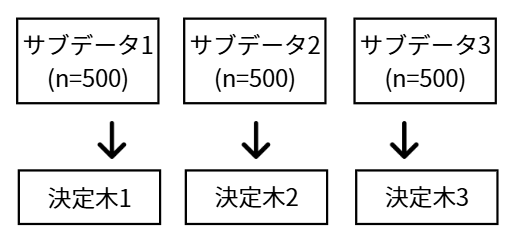
-
予測したいデータが来たら、すべての木に予測させ、その結果の多数決(分類の場合)や平均(回帰の場合)をとって最終結果とします。
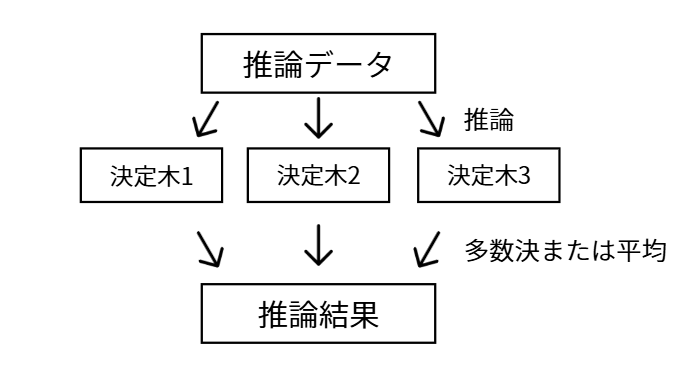
代表的なモデル: ランダムフォレスト (Random Forest)
特徴: 個々の木が過学習していても、全体で平均化されるため、非常に過学習に強く、安定した精度が出ます。
用途:
安定したベースライン: 高い精度が求められるタスクの「最初の基準(ベースライン)」として広く使われます。
特徴量の重要度評価: どの特徴量(例:色、形、重さ)が予測にどれくらい寄与しているかを評価するのによく使われます。
差別化点:
安定性・過学習への耐性: ブースティング系に比べ、パラメータ調整にそれほど神経質にならなくても安定した性能が出やすいのが強みです。
並列処理: 個々の木は独立して作れるため、計算リソース(CPUコア)があれば並列処理で高速化できます。
(2) ブースティング (Boosting) → 代表:GBDT (LightGBMなど)
「弱い木を直列につなぎ、前の木の間違いを修正しながら賢くしていく」手法です。
手法:
-
まず、簡単な決定木を1本作ります。
-
その木が間違えた(予測が外れた)データに注目します。
-
次に作る木は、その「間違えたデータを正しく予測できること」を重視して学習します。
-
これを繰り返し、徐々に予測精度を高めていく「エリート集団」のようなモデルを作ります。
少しわかりにくいと思うので具体例をあげます。
「年齢」から「ゲームを買う(1)/買わない(0)」を予測するタスクで考えます。
以下の4人のデータについて学習したとします。
| 名前 | 年齢 | 正解(買う=1, 買わない=0) |
|---|---|---|
| Aさん | 10歳 | 1 |
| Bさん | 20歳 | 1 |
| Cさん | 50歳 | 0 |
| Dさん | 60歳 | 0 |
この時の学習の流れは以下の通りとなります。(実際にこうなっているかはわかりませんが、例として挙げます。)
1本目の木: まず全員の平均(正解の平均 (1+1+0+0)/4 = 0.5)を予測します。この時点での予測は全員「確率0.5」です。このとき、以下のような残差となります。
| 名前 | 年齢 | 正解 | 予測(1回目) | 残差(1回目) |
|---|---|---|---|---|
| Aさん | 10歳 | 1 | 0.5 | +0.5 |
| Bさん | 20歳 | 1 | 0.5 | +0.5 |
| Cさん | 50歳 | 0 | 0.5 | -0.5 |
| Dさん | 60歳 | 0 | 0.5 | -0.5 |
2本目の木: 「1本目の木の間違い(+0.5や-0.5)」を予測するように学習します。
例えば「35歳以下か?」という分岐を見つけ、「35歳以下(A, Bさん)の間違いは+0.5」「35歳より上(C, Dさん)の間違いは-0.5」と予測します。
この予測から、「1本目の予測」+「2本目の予測(修正分)× 小さな学習率」を合算し、新たな予測結果とします。(例:学習率を0.1とします)
| 名前 | 年齢 | 正解 | 予測(2回目) | 残差(2回目) |
|---|---|---|---|---|
| Aさん | 10歳 | 1 | 0.55 | +0.45 |
| Bさん | 20歳 | 1 | 0.55 | +0.45 |
| Cさん | 50歳 | 0 | 0.45 | -0.45 |
| Dさん | 60歳 | 0 | 0.45 | -0.45 |
これを繰り返し、徐々に予測を正解(確率1.0または0.0)に近づけていきます。
これがブースティングの手法です。
代表的なモデル: GBDT (勾配ブースティング決定木)
特徴: 非常に高い予測精度を達成できる可能性があり、データコンペティションなどで主流となっています。
主なライブラリ:LightGBM, XGBoost
用途:
Kaggleなどのデータコンペティション、金融(不正検知)、マーケティング(クリック率予測)、需要予測などの精度を追求したい場面。
差別化点:
高い予測精度:
ランダムフォレストや他の機械学習手法を上回る、非常に高い予測精度を達成できる場合が多いです。
まとめ
「ツリー系モデル」とは、シンプルな「決定木」から、その弱点を克服した高精度なアンサンブルモデルである「ランダムフォレスト」や「GBDT(LightGBMなど)」までを含む、非常に幅広く強力な機械学習モデル群のことを指します。処理したいデータによってぜひ使い分けてみてください。