改訂版について (5/7/2019公開)
この記事は、私がこちらに公開したもの中では最も読まれているようです。そこで、執筆後に気づいたこと、古くなった情報、新しい技術動向などを考慮に入れて改訂をしました。主な変更点は以下の通りです:
- 新しいセクションの追加
- 最近の本の紹介
- 細かな表現の修正
この記事は複数のセクションに分かれていますので、前編から始め、順番にアップデートして行きたいと思います。何かお気付きの点などありましたら、コメント欄、もしくはkonoアットマークucsd.eduにお願いいたします。
はじめに
この記事は、可視化の専門家ではない人がコンピュータを使ってデータ可視化を実際に行う場合に必要な、一般的なノウハウをお伝えするシリーズの第一回です。
- 前編: 効果的なデータ可視化とはどのようなものか? (本稿)
- 中編: 分かりにくい可視化を避けるための手法の選択
- 後編: Part 1 基本原則
- 後編: Part 2 学習ガイド
効果的な可視化とは?

実務家にとってのデータ可視化
私はバイオインフォマティクスと呼ばれる分野で働くプログラマで、デザインや芸術のバックグラウンドが一切ありません。しかし偶然が重なり、現在は仕事として生物学分野で使われるデータを可視化するためのソフトウェアや、複雑なUIを持つライフサイエンス向けの各種ウェブ・アプリケーション作っています。そこでの経験を通じて、アートやデザインと実務的なデータ可視化の間にある共通点と差異を徐々に認識できるようになりました。近年は、あらゆるホワイトカラーの人々にとって、データを処理し、可視化し、それを他者に何らかの形でプレゼンテーションするスキルは必要になりました。そこで、私のような元々可視化を専門としない人が__最高ではないけど酷くもない__(言い換えれば「70点程度の可視化」)と言うレベルのデータ可視化を作成するときに気をつけるべき点をまとめました。
ここ数年は、研究者や学生向けに可視化ソフトウェアの使い方と実際の可視化に関するレクチャーをすることも多くなったので、自分が独学で得た知識をスライドにまとめてきました。本稿では、これらのスライドの中から重要と思われる部分を再編集し、さらにその後私が学んだ知識を含めてまとめて書きました。なお、私は科学分野での可視化を中心に扱っていますので、厳密なデータの提示が求められるケースを想定していますが、他の分野でも本質的な部分は同じだと思います。さらにこの改訂版では、2019年現在、以前と比較して充実してきた実務者向けの情報やツールを整理し、プログラミングが必要なケースとそうではないケースも含めて、どのような技術と知識が実務家に求められているのかを含めて検討して行きます。
引用図を除く本稿の全ては、CC BY 4.0ライセンスにて再配布可能です。

2019年における可視化の実務者を取り巻く環境
この記事の初版を公開してから、五年近くの月日が流れ、データ可視化を取り巻く環境も少しずつ変化してきました。「データ・サイエンティスト」などという言葉がマスメディアにも頻繁に登場するようになり、コンピュータを用いてデータを分析し、第三者にわかりやすく提示するという作業の重要性は、多くの人が認識するようになりました。しかし一方で、ある意味においてバズワードと化した「データ・ビジュアライゼーション」という語は様々な意味で利用されるようになり、時には使い方によって混乱を招くこともあります。そこで、まずはじめに実務者の視点から見た可視化という言葉の定義から始めようと思います。
「データ可視化」という言葉の指すもの
現在、主に技術系のメディアに登場する「データ可視化」という言葉は、大きく分けると以下の二つの意味で使われています。
インフォグラフィックス
最近目にすることの多いインフォグラフィックスは、データを使って表現されたイラストレーションと言って良いと思います。つまり、インフォグラフィックはデザイナーがその技術を発揮する余地が大きく、次節で述べるデータから視覚要素へのマッピングを設定してアルゴリズミックに生成することに主眼を置くデータ可視化とは主従関係が逆になります。美的要素を中心に考え、デザイナーがIllustratorなどのソフトウェアを使って手作業で仕上げるもので、最終的な結果は作成者のアーティスティックな能力に大きく左右されます。本稿ではこちらについては触れません。
アルゴリズムに基づくデータ可視化
データ可視化、もしくはdatavizなどという言葉で表されるものは、アルゴリズムに基づいて、データポイントを機械的に視覚効果へマッピングして生成されるものを指します。つまり、実際の描画部分は、計算機がコードとして与えた指示に従って自動的に生成されるものであり、作者の手技によって結果が左右される部分は小さいです。
本稿では、こちらの意味で「データ可視化」と言うトピックを扱います。
また、このようなコンピュータを使った可視化には、大きく分けると以下の二つの種類があります。
- 探索的可視化 - コンピュータならではの双方向性を生かし、大規模なデータセットから知見を引き出すようなツールのことを指します
- 説明的可視化 - あるストーリーをデータ可視化によって補強するようなものを差します。
コンピュータを使うことにより、これらのどちらも以前に比べると手軽に始められるようになりました。本稿では、この両方について見て行きたいと思います。
2014年から現在までの主な変化
まず初めに、この5年間で起きたデータ可視化周辺での変化を俯瞰してみようと思います。この記事の初版以降に起きた変化で、特筆すべき点には以下のようなものがあります:
1. インタラクティブなデータ可視化の一般化
インタラクティブな表現を行うこと自体は比較的低コストで行えるようになってきました。特にジャーナリズムの分野では、内外を問わず、新しい表現の一環としてインタラクティブなデータ可視化やインフォグラフィックスを紙面に取り入れる新聞社も増えました。
- 日本経済新聞社 Visual Data
- The New York Times 2018: The Year in Visual Stories and Graphics
このような大手メディアの動きにより、一般の人々にもインタラクティブな表現に触れる機会は格段に増えました。しかしそれは同時に、情報の伝達手法としてはあまり意味のないアニメーションなどの氾濫も招くことになり、データ可視化の根本的なゴールである「データを人にわかりやすく提示する」という点が曖昧になっているケースも増加しました。
2. ブラウザのさらなる高速化と実装技術の変化
近年では、ボリュームレンダリングやCADなどの特殊な分野を除き、ありとあらゆる可視化関連のツールがウェブベースのアプリケーションへと収束してきています。GPGPUの利用も含めると、かなり大規模データを含めたあらゆる可視化アプリケーションをブラウザ上で実装することが現実的になってきました。また、Slackをはじめとする企業も、デスクトップアプリケーションを実装する技術としてElectronを採用するケースがあり、比較的複雑なUIを必要とする可視化アプリケーションでも、ウェブからデスクトップまで、一つのコードを基に生成することが現実的になりました。
3. モバイル・ファースト
特にマスメディアによる説明的可視化のようなものを最終的に表示するクライアントとして、モバイルデバイスは最も多く利用されるクライアントになりました。複雑で処理的に重いデータ可視化アプリケーションはモバイルデバイスで動かすのは厳しい場面もありましたが、最新のモバイルデバイスを利用すれば、かなり複雑なウェブベースの技術で実装されたアプリケーションも、現実的な速度で動かすことが可能になりました。
4. プログラマではない人々向けツールの充実
ある程度定型化可能な可視化作業では、BIツールや、Tableauなどのプログラマでない人も用いることができるツールも普及し、かなり凝った可視化やダッシュボードの作成でも、コードを書かなくても実現できる場面が増えました。
今から何か可視化のプロジェクトに取り組む方は、こういった現状を踏まえた上で、技術選択(コードを書かないことも含めて)する必要があると思います。
可視化の具体例としてのグラフ可視化
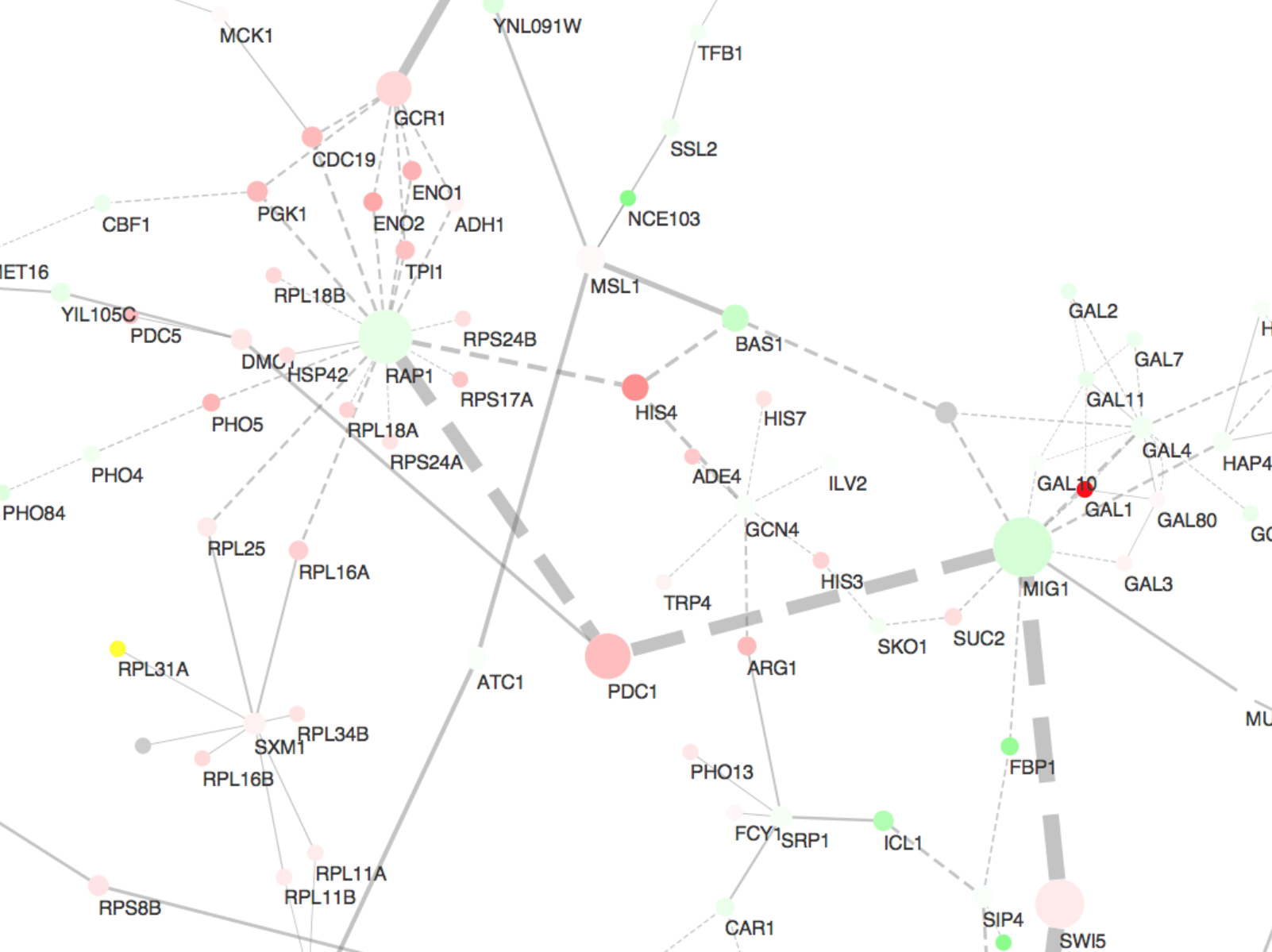
私の業務での主なプロジェクトはCytoscapeと呼ばれるグラフ(ネットワーク)可視化ソフトと周辺アプリケーションなので、はじめにデータ可視化の具体例として、この分野を取り上げてみたいと思います。一般的なヒストグラムや散布図などに比べるとややマイナーですが、ソーシャルネットワークやインターネットそのものをはじめ、グラフはあらゆる場面で現れるデータ構造なので、汎用性は高いと思います。
この記事を書くきっかけ
Cytoscapeを実際に使っているユーザーから直接話を聞くと、しばしばこのようなことを言われます:
- 「スクリーンショット集を見て、自分も同じようなものを作ってみたいと思ったが、プリセットのスタイルから最終的にサンプルのようなところまで持っていく方法よくわからない」
- 「なぜサンプルにもっと凝ったデザインものを入れないのか?」
これにはいくつか理由があります。一番のポイントは「データが視覚変数(後述)をコントロールする」と言うCytoscapeの根本的なデザインにあります。これは何もCytoscapeに限ったことではなく、汎用性を持ったデータ可視化ソフトウェアは多くの場合この方針でデザインされています。つまりこういったソフトウェアで効果的なデータ可視化を行うと言うことは、__データの特性を見た上で、基本的な可視化のルールに従ってデータから視覚変数へのマッピングを作成していく__事にほかなりません。したがって、どんなデータにもうまくフィットするようなサンプルスタイルを作成するのはなかなか困難で、それが上のユーザーの不満にも繋がっています。これを解決するには、基本操作を知った上で、可視化の基礎的な知識を身に付けるのが一番の近道だと思うので、その知識を身に付ける近道を提供できればと思い、この記事をまとめました。
良い可視化とは何か?


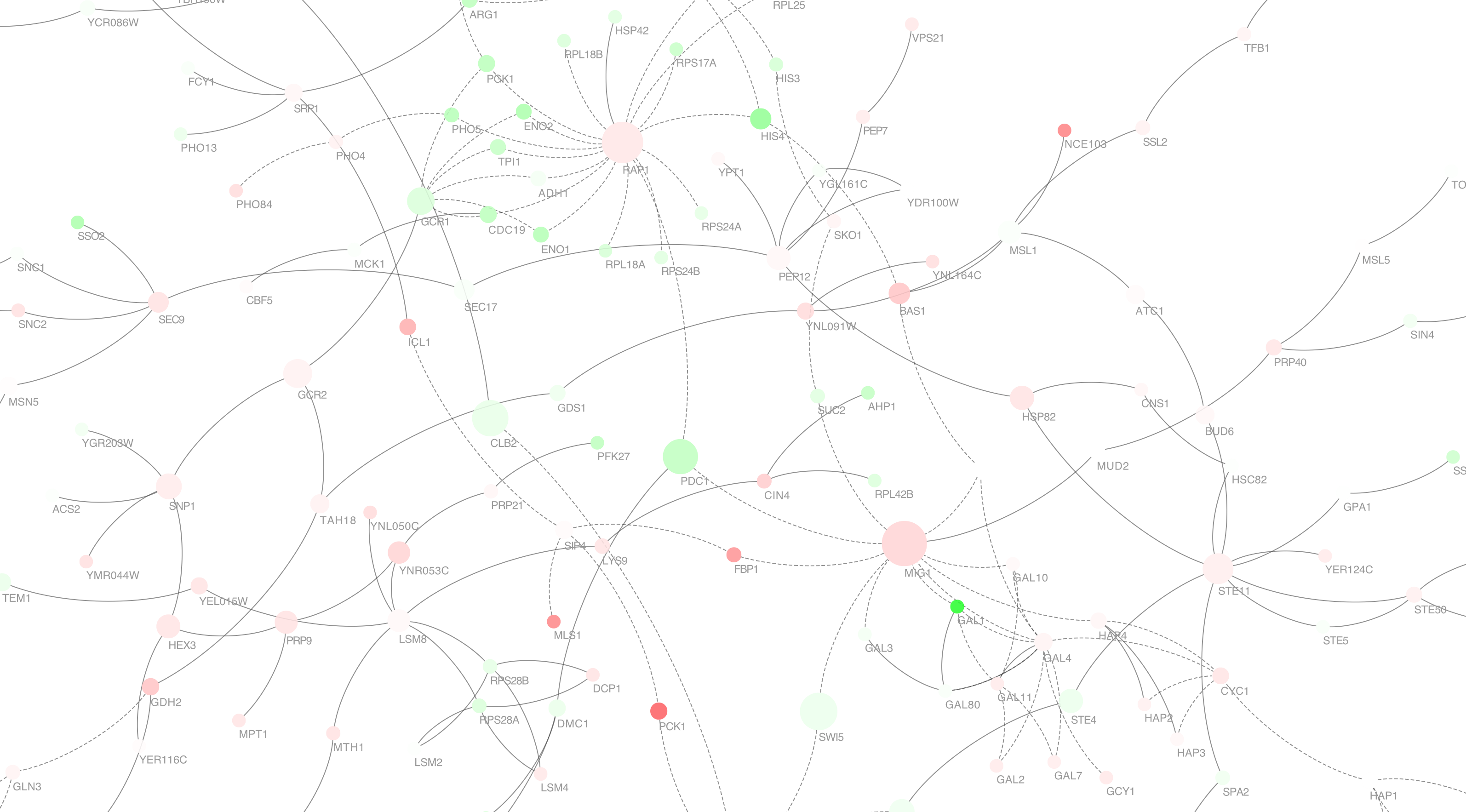
そもそも効果的な、良いデータ可視化とはどのようなものでしょう?これには様々な答えがあると思いますが、私は以下のように理解しています:
効果的な可視化とは、データから伝えたいテーマを設定し、それを実現するためにデータから視覚変数への__必要最小限のマッピングを設定する__こと
やや抽象的ですが、これは以下のように分解できます:
- データ全体の傾向と特性を把握する
- 可視化の目的(ゴール)を設定する
- 目的を語るためのストーリーを考える
- その__ゴールへ到達するための可視化を行う__
- ゴールへ到達するのに不必要な視覚情報を盛り込まない
- 各視覚変数の特性を理解し、マッピングを効果的に利用する
- テクノロジーを目的のために使う。テクノロジーのために目的を設定しない
これらを踏まえて自分が今までやってきたことを振り返ると、色々と誤解したまま作業してきたことも多いです。幾つか例をあげてみます。
「カッコ良さ」と実用性
新しい技術がそこにあれば使いたくなるのがプログラマの性です。90年代以降、パーソナルコンピュータでもGPUが凄まじい速度で進歩し、あらゆる3次元グラフィックスがラップトップでさえ描画できるようになり、それを利用した多くのデータ可視化ソフトウェアが作成されました。確かに大規模なデータをハイパワーなGPUを使って3次元空間に描画するのは純粋にカッコ良く、SF映画に出てくるフェイクUIのようなものを個人が作ることさえ可能になってきました。しかし、三次元を使ってデータを可視化するのは常に有効な手法なのでしょうか?
私の関わっている分野で3Dを利用したわかり易い可視化例は、タンパク質の三次元構造ビューアです:
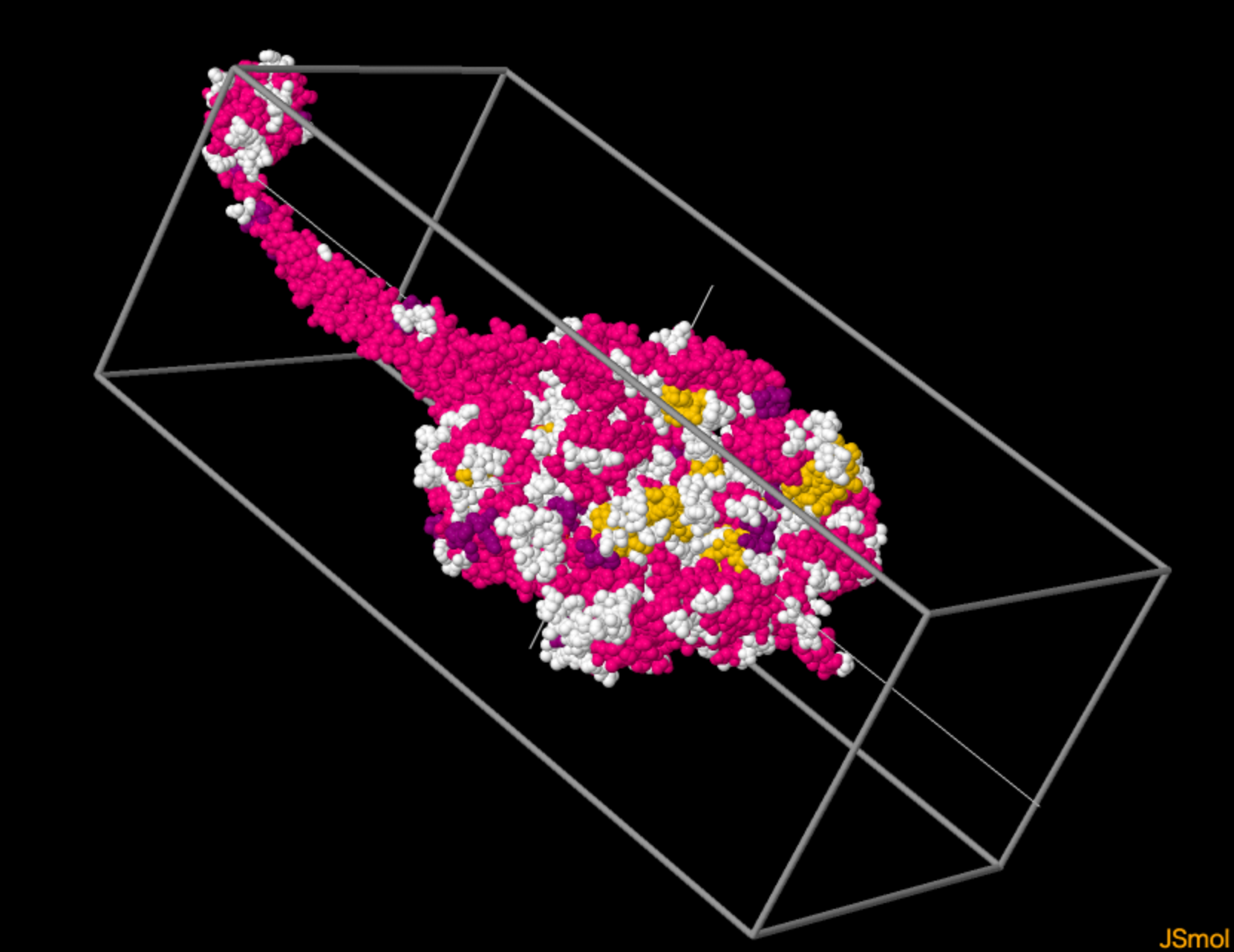
X-ray structure of a functional full-length dynein motor domain PDB ID: 3VKH ダイニンと呼ばれる一種の分子モーターの三次元構造
これは現実に三次元構造を取るアミノ酸の鎖を、そのままコンピュータ上の三次元空間に投影して扱いやすくしたものですから、デザインとして極めて理にかなっている上に、ユーザーにとっても理解が容易です。ここには3Dグラフィックスを利用する明確な理由があります。
しかし以下の例はどうでしょう?
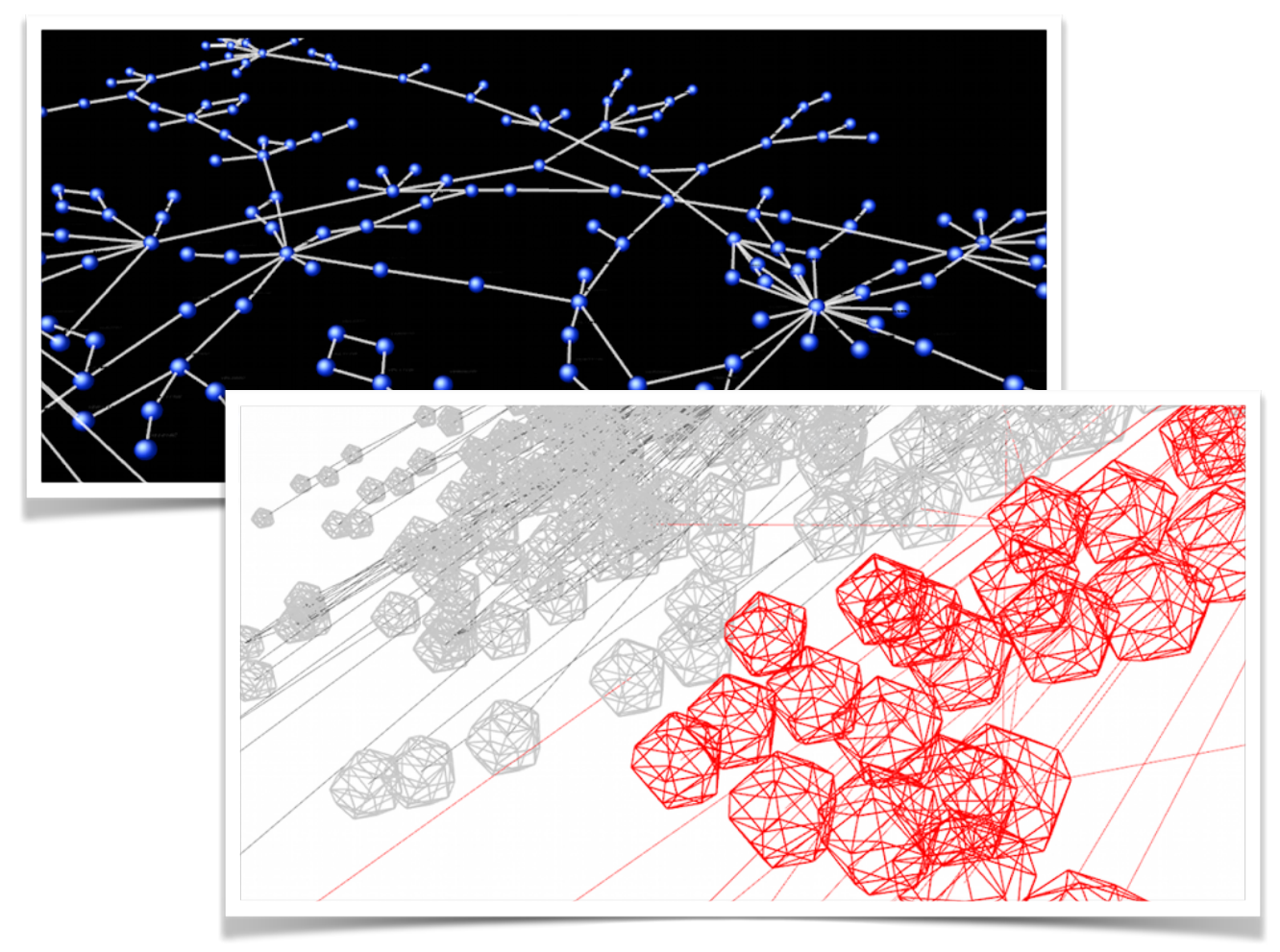
これは以前私が、あるネットワークデータをProcessingをライブラリとして使いCytoscape上で描画してみたものです。もちろんこのデータは、以下の様なシンプルな2Dネットワーク図としても描画できます。

この2つを比べた時、3Dになったことで最終的なストーリーを語る上で何か明確なアドバンテージがあるか、と問われれば、必ずしもイエスとは言えないと思います。見た目は派手になりましたが、それ以上のメリットを提示するのは難しいです。更に、以下の例はigraphライブラリにより比較的小さなネットワークに三次元レイアウトを施して画像にしたものです:

3Dレイアウトをグラフに対して行うと、かえってナビゲーションが煩雑になったり、全体の見通しが悪くなることもしばしば起こります。上の例も、二次元の配置に比べて見づらくなったノードやエッジも増えています。このように本当に必要がある場合以外、三次元を安易に使うのは望ましくないです。
It would be more accurate to say that visual space has 2.05 dimensions.
[Ware 2008]
つまり新しい技術、もしくは複雑性を可視化に持ち込む場合、それが最終的なゴールに到達する手助けにならない場合は、もう一度本当にそれが必要かどうか考える必要があります。
補足: 「広告」としてのデータ可視化
探索的なデータ可視化システムを構築するのに、三次元での表示などは必ずしも実用的でないことは上で述べた通りです。しかし、データ可視化作品には、まず人の興味を引く、いわば宣伝のためのものも存在します。私の働く分野では、主に論文誌や本の表紙に使われる、インパクト重視のものなどがそれに当たります。以下は、三次元空間に、薬剤とそのターゲットをネットワークとして表現したものを描画したものですが、これ自体には大きな意味はなくとも、発表時にアニメーションなどで見せれば聴衆の興味を引くことも可能で、使う場面を間違えなければ、派手な「演出」を伴う可視化も、全く無意味ではありません。

効果的な可視化を作成するのにアーティストである必要はない
先に述べたように、美しいインフォグラフィックスを作成するにはデザイナーの素養が必要です。しかし効果的なデータ可視化を制作する技術は、アーティスティックな才能とは異なり、いくつかの基本的なルールを守ることで劇的に向上させることが可能です。これは文書化可能な技術であり才能ではありませんから、だれでも少し時間をかけると「これは酷い」と言うレベルから脱却することは容易です。
データ可視化の技術と一般的なデザインの技術には重なる部分も多く、デザイナー向けの入門書からは多くのことを学べます。それらの本には、色の選択(カラーパレットの作成)や、余白の使い方、フォントの使い方などは必ず触れられており、そう言ったものを読むことで、センスの勝負になる前の段階では、グラフィックデザインや可視化の作成は誰でも学習可能な技術であると理解できると思います。デザインの入門書は日本語でもたくさん出ていますので、評価の高い定番のものを一冊読むだけでも、資料作成や可視化作業で長く使える知識を得られます。
可視化作業の流れ
ここからは実際の流れと気をつけるべきポイントを見ていきます。どのような可視化作業でも、以下の手順に従います:
- テーマの設定
- データの大まかな傾向・特徴の把握
- 手法の選択
- プロトタイピング
- データの準備(加工)
- データの読み込みと統合
- 実際の可視化
- マッピングの作成
- レイアウト
この中でも、最終的な結果に大きく影響を与えるステップについて詳細を見て行きます。
テーマの設定
__全ての作業の中で最も重要なステップです。これを行わないと、最終的な可視化結果は意味のないものになりがちです。__とは言っても特段難しいことではなく、取り組む問題を文章化し、実際に手を動かす各ステップでそのゴールからずれていないかを確認するのに使うだけです。これを最初に設定することにより、各ステップで行う作業が提示したいテーマ、もしくはストーリーを補強するものになっているかどうかを確認することが可能となり、無駄な作業や不要な装飾を避けやすくなります。
テーマの例
- Twitterネットワーク上で、ある人の発言が時間とともに__拡散する様子を観察したい__
- あるクラスのオンラインソーシャルネットワーク上に流れるメッセージ量をネットワーク上にマッピングし、生徒間の__関係性を推測したい__
- パスウェイの上で承認薬剤が使えるドラッグターゲットと既知の疾患関連遺伝子を可視化し、その__重なりを見たい__
- ソーシャルネットワーク上の人物Aから人物Bへのつながりが存在するのかをインタラクティブに検索したい
現実的にはこの程度のテーマ設定で十分です。今後の作業で、このテーマを補強することに繋がっていないと考えられる場合、もう一度ここへ戻ってその作業の妥当性を確認するのが良いデータ可視化への近道です。
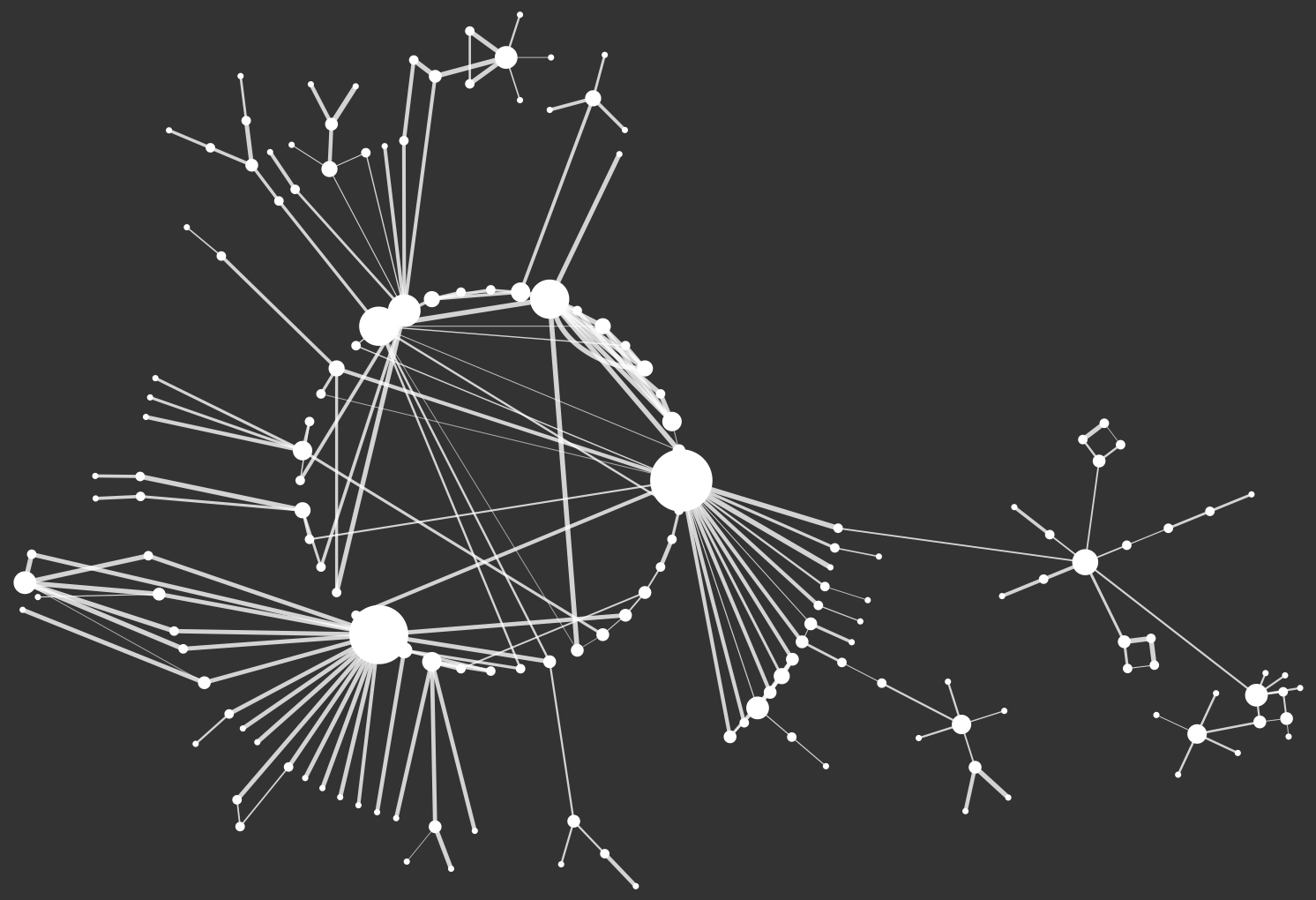
例(データはフェイク): 一日あたりのメッセージの流量=エッジの太さ・コネクションの数=ノードのサイズ。これは生徒の関係性を示すのに妥当なマッピングだろうか?可視化作成の全体のプロセスを通して、これを自問しながら作成するのが望ましい。
データの傾向の把握
ネットワークを可視化する場合、ネットワークのトポロジー(接続の状態)以外にも様々なデータを組み合わせて可視化を行います。そこで使うデータのある程度の傾向をつかむことは最終的にどのような手法を選択するのかにも繋がり、重要な作業の一つです。もちろん最終的には可視化によってデータを理解しようとしているのですから、それほど詳細に把握する必要はありませんが、以下の様な点だけでもしっかり把握することにより、手法の選択に大きく役立ちます
マッピングに使うデータ
- データの種類
- カテゴリカル・データ(離散値)
- カテゴリーの数
- カテゴリーの種類
- グループ化が可能か?
- 連続値
- レンジ(最大値・最小値)
- normalize済みか?
- 外れ値
- カテゴリカル・データ(離散値)
- データポイントの数
例えば、カテゴリー数を把握するのはマッピングする先の視覚変数を選択するのに役立ちます。数十個のカテゴリーがあった場合、それを単純に色にマッピングするというのはひどい結果になりがちです:

人間が同時に把握できる色の数は想像以上に限られていて、数色程度にとどめておくことが望ましいです:
つまり、データのカテゴリー数が多い場合は、色以外のマッピング先を考えたほうがいいということになります。このように、予めデータの傾向を掴んでおくことは、より良い手法を選択するのに役立ちます。
手法の選択
ここでの例はネットワーク可視化ですが、それを実現するのにも様々な方法があります。例えば、上記のTwitterのツイート拡散の例の場合、以下の様な方法が考えられます
- 最初の発言者から始まり、ダイナミックに情報が伝播していく様子をアニメーションとして表現する
- 各タイムポイントごとにネットワーク図を作成し、Small Multipleとして変化を提示する
- タイムポイントごとに色のマップを作成し、一枚の画像で時系列での情報の拡散を示す
- 情報が到達した時点の色を、t1=red, t2=blue, ...等としてマッピング
また、ネットワークが特殊な形状の場合、例えばツリー構造の時は、ノード・リンク図の他にも、ツリーマップやサークルパッキングなどの手法も利用できます。実装の難易度、最終的に発表する媒体(ウェブ、論文、ポスター等)、締め切りまでの時間なども考慮に入れて手法を選択します。
本稿ではネットワーク(グラフ)データを例としていますが、データの種類により使える定番の手法は自ずと決まってきますので、まずどんな可視化手法が存在するのかを把握しておくことも大切です。
こう言った定番の手法、すなわち、データと手法の対応を一通り知りたい場合には、この本がお薦めです。

Andy Kirk著 Data Visualisation: A Handbook for Data Driven Design Second Edition
また、この本の著者は、彼のウェブサイトで盛んに可視化関連の情報を発信していますので、ぜひ読んでみてください。
ペーパープロトタイピング
手法が決まれば、ここでスケッチを作ります。何も凝った設計図である必要はなく、ただ単に、紙の上に最終的なアウトプットがどのようなものになるのかを描いてみます。データ可視化には、インタラクションの無い(紙への出力、スタティックなイメージの作成)・もしくは少ない(ムービー、自動的に遷移するもの)タイプと、完全なアプリケーションとして提供されるものがあります。後者はここでは扱いませんが、どちらも紙に描いてみてみることにより、実装の難易度やデータの過不足などが確認できます。
ツールの選択
使う手法を決定すると、自ずと使うべきツールも決まってきます。今回の話題とは離れるので詳しくは書きませんが、グラフに関しては以下の様なツールがスタンダードです。しかし可視化以前の部分で使われるツールは、ほとんどどんなデータ可視化でも同じだと思います。
クレンジング
- Python + IPython Notebook + Pandas
- grep, sed, awk
- Exele
解析
- R
- Pandas, SciPy, NumPy
- Matlab
- Mathematica
グラフ解析
- igraph
- NetworkX
可視化
- デスクトップアプリケーション
- Cytoscape
- Gephi
- ウェブベースの可視化
- Cytoscape.js
- D3.js
- sigma.js
不要なプログラミング/車輪の再発明を避ける
2019年現在、この記事を最初に公開した頃に比べると、有償・無償を問わず、豊富なデータ可視化アプリケーションやライブラリが入手できます。この記事は主にプログラマ向けなので、コードを書ける方がほとんどだと思いますが、データを可視化して提示する、という目的を出来るだけ短時間で達成するためには、あえてコードを書かないことも必要です。D3.jsは素晴らしいライブラリですが、もしあなたがヒストグラムをそれで作ろうとしているのならば、もう一度、本当にそれが必要かどうかを考えるべきです。多くの定番の可視化手法に関しては、非常に高度な機能を持つライブラリが数多く公開されています。例えば、以下のようなものがあります。
特にDashは、JavaScriptで描画部分のコードを一切書く必要がないため、Pythonのみで一般的なデータ・ダッシュボードを作成することが可能です。また、現在主流になっているノートブック型アプリケーションにデータ解析と可視化のワークフローを落とし込む場合、かつての主流だったライブラリよりも、さらに少ないコード量で綺麗な可視化を生成できるものも登場しています。
Altair: Declarative Visualization in Python
このように、可視化周辺のライブラリやアプリケーションはどんどん進化していますので、「本当に自分でそのコードを書く必要があるのか?」は少しリサーチして考えた方が時間が節約できると思います。基本的には、かなり特殊なインタラクションが必要な場合を除き、自分で一からコーディングする必要は少なくなってきていますので。
Pythonをお使いの場合は、すでに2年前の記事ですが、これが現状を把握するのに役立つと思います。
Python's Visualization Landscape (PyCon 2017)
ネットワーク可視化分野に特化したまとめには、こんなものもあります。
THE GRAPHTECH ECOSYSTEM 2019 – PART 3: GRAPH VISUALIZATION
データの準備、読み込みと統合
ここからが実際にコンピュータに向かう作業です。これは時間がかかるステップである場合も多いですが、反面、機械的な作業でもあるのでそれほど頭は使いません。手元にあるデータから、最終的に使うアプリケーションで利用できる形にデータを「掃除」していきます。
作業の一例として、先日書いた記事へのリンクを張っておきます:
当然ですが、元のデータが綺麗であればそれだけここにかかる手間は小さくなります。もしあなたがデータを公開する機会があれば、是非機械で読み込むのが容易で二次加工しやすいように心がけて下さい。恐らくそれだけでそのデータが利用される機会が増えます。
実際の可視化
マッピングの作成
実際のデータ可視化で中心になるのはこのステップです。綺麗に掃除されたデータ(=機械に読み込みやすい形式に整形されたデータ)を視覚変数にマッピングしていきます。
Visual Variables (視覚変数)とは?
そもそも視覚変数とは何でしょう?これはJacques Bertinが提示した概念で、__位置、サイズ、色、形と言った、データを変換する先の視覚的要素の集合__のことです。全てのデータ可視化は、データをこれらの要素にマッピングする作業にほかなりません。
- 小さな数値を小さなノードに、大きな値を大きなノードに
- 高い重み(スコア)を持つエッジを太く
- グループAのノードを赤に、グループBのノードを青に
このように概念自体はとても単純なのですが、効果的に使うためには人間の知覚を理解する必要があります。
視覚変数の中身
現在は拡張されたバージョンも有りますが、最初にBertinにより提示された視覚変数は以下の通りです:
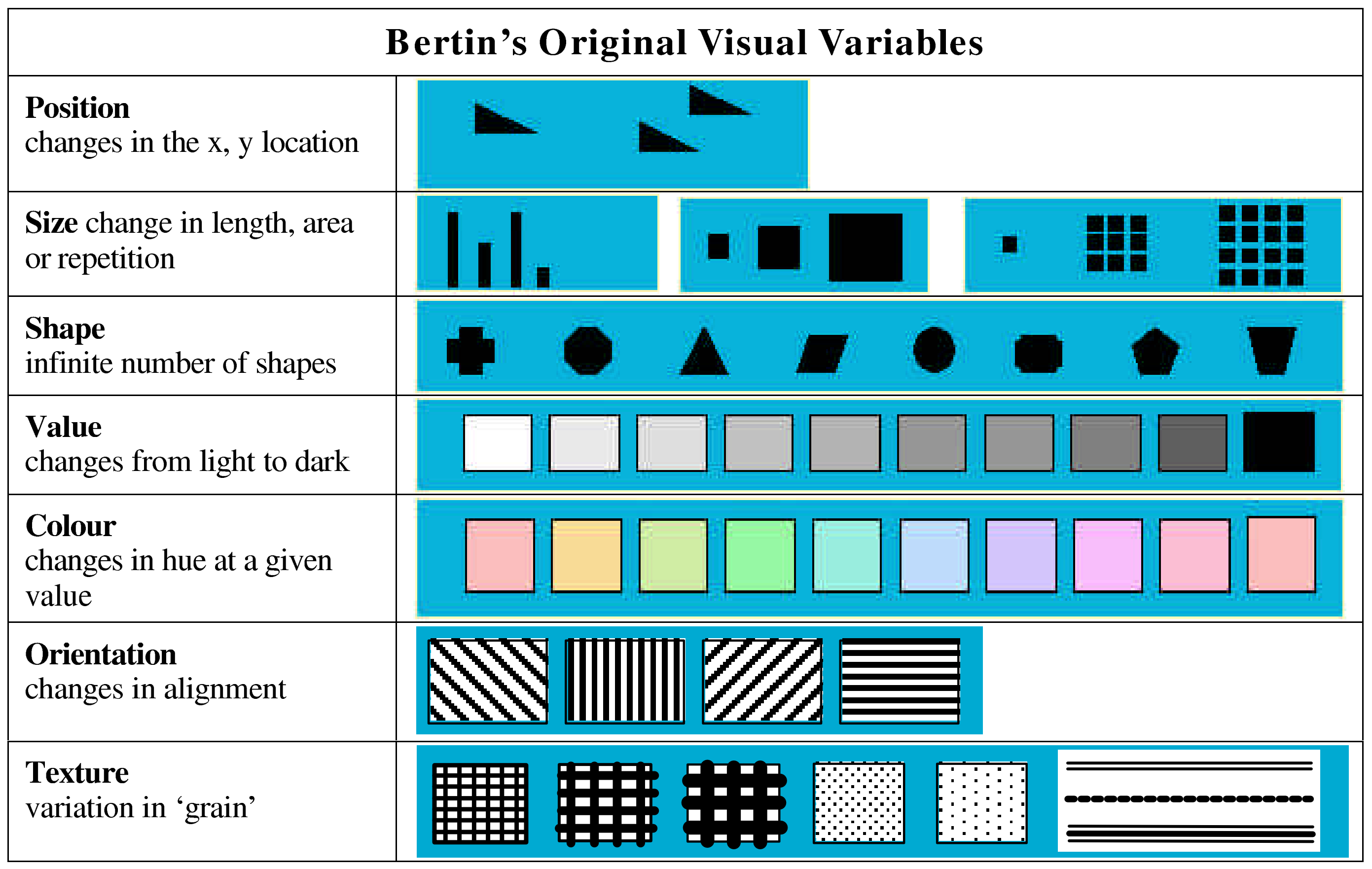
Carpendale, M. S. T.: Considering Visual Variables as a Basis for Information Visualisation, University of Calgary, Department of Computer Science, 2001-693-16, 2003 (PDF版はこちら)
- 位置
- 大きさ
- 形
- 明るさ
- 色
- 向き
- テクスチャ
どれもお馴染みの概念ばかりだと思います。問題は、これをどう使うかです。
Effectiveness Principle
これらの視覚変数にデータをマッピングする時に従うべき原則はこれです:
Encode most important attributes with highest ranked channels
(最も重要なデータを高くランク付けされているチャンネルで表現せよ)
[Mackinlay 86]
チャンネルとは何か?
ここで言うチャンネルは、同程度の正確さを持つ視覚変数と考えてもらって問題無いと思います。以下は、Jock Mackinleyの論文からの引用ですが、__人は一部の視覚変数の値の差は正確に読み取れるが、小さな差異を読み取れない変数もある__ということを踏まえた可視化の重要性を論じています:
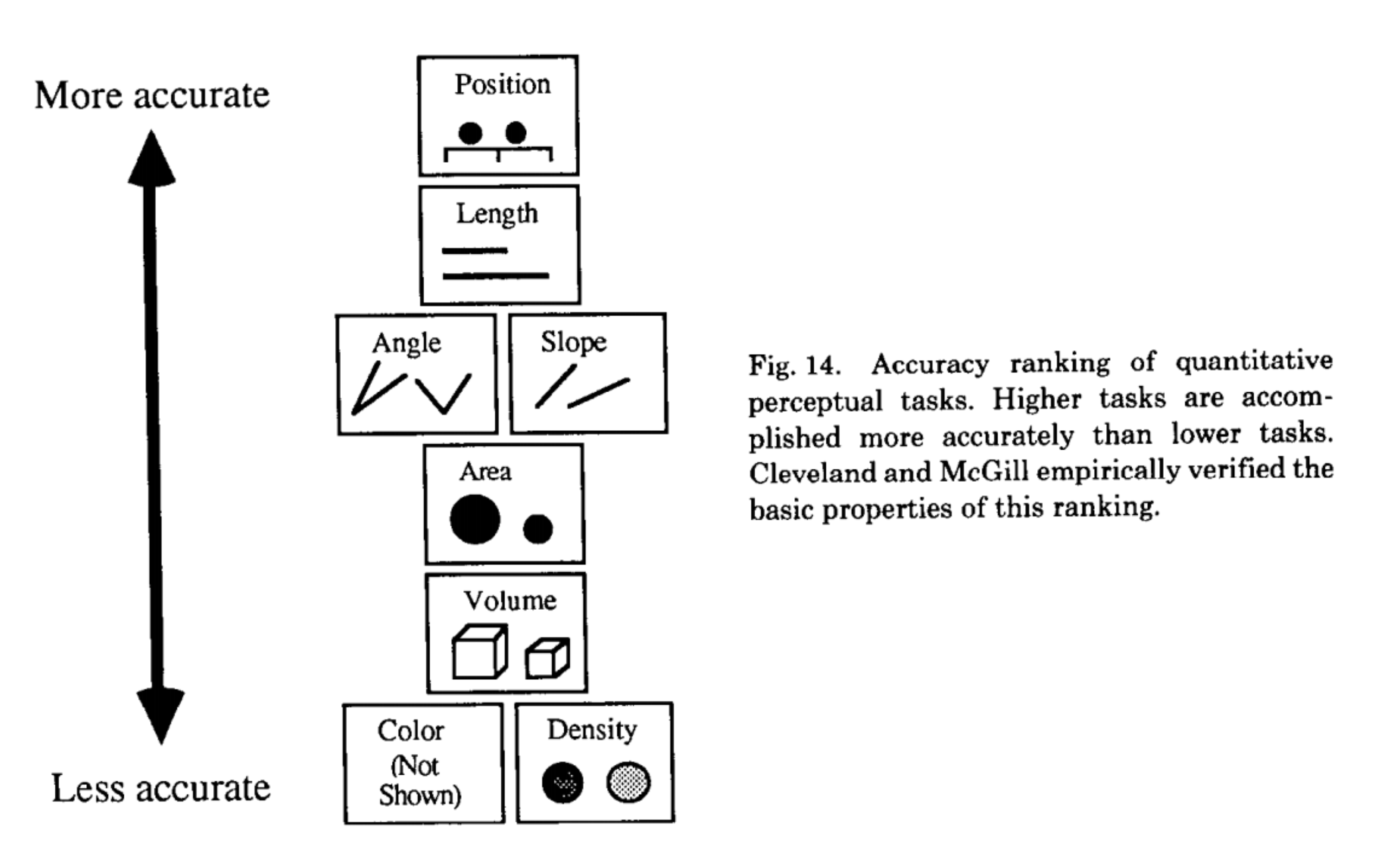
Jock Mackinlay. 1986. Automating the design of graphical presentations of relational information. ACM Trans. Graph. 5, 2 (April 1986), 110-141.
つまり、__伝えたいテーマの中心となるようなデータは、正確性の高いチャンネルを用いて表現すべきである__ということです。例えば、オブジェクトの位置は人が最も正確に読み取ることが出来る視覚変数ですから、「異常値もなくきれいな相関関係が存在する」ということを示すのには、データポイントを位置そのもので表す散布図は効果的な手法ということになります。
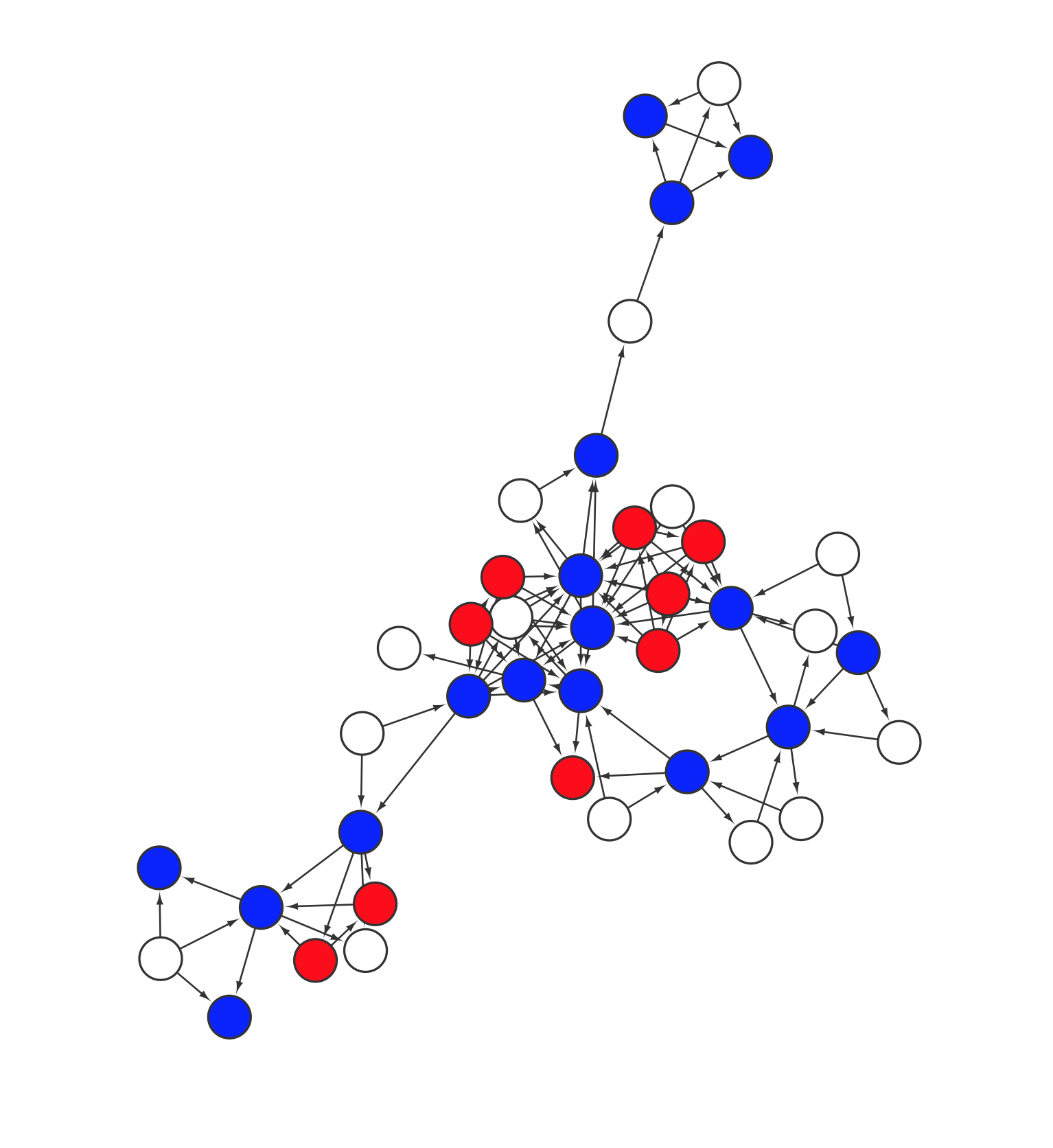
ネットワーク可視化でも、位置の整理によるわかりやすさの向上は劇的です。エッジという2つのノードの関係性を表す値に基づいて位置を調整することにより、関係性の可視化というネットワーク描画で大切な情報が浮かび上がってきます。例えば以下の2つは全く同じデータですが、適切にノードの配置を変えることにより、見えなかったツリー構造が見えるようになりました:


そしてもう一つ覚えておくべきことは、データのタイプによって、適切なチャンネルとそうでないものが存在するということです。
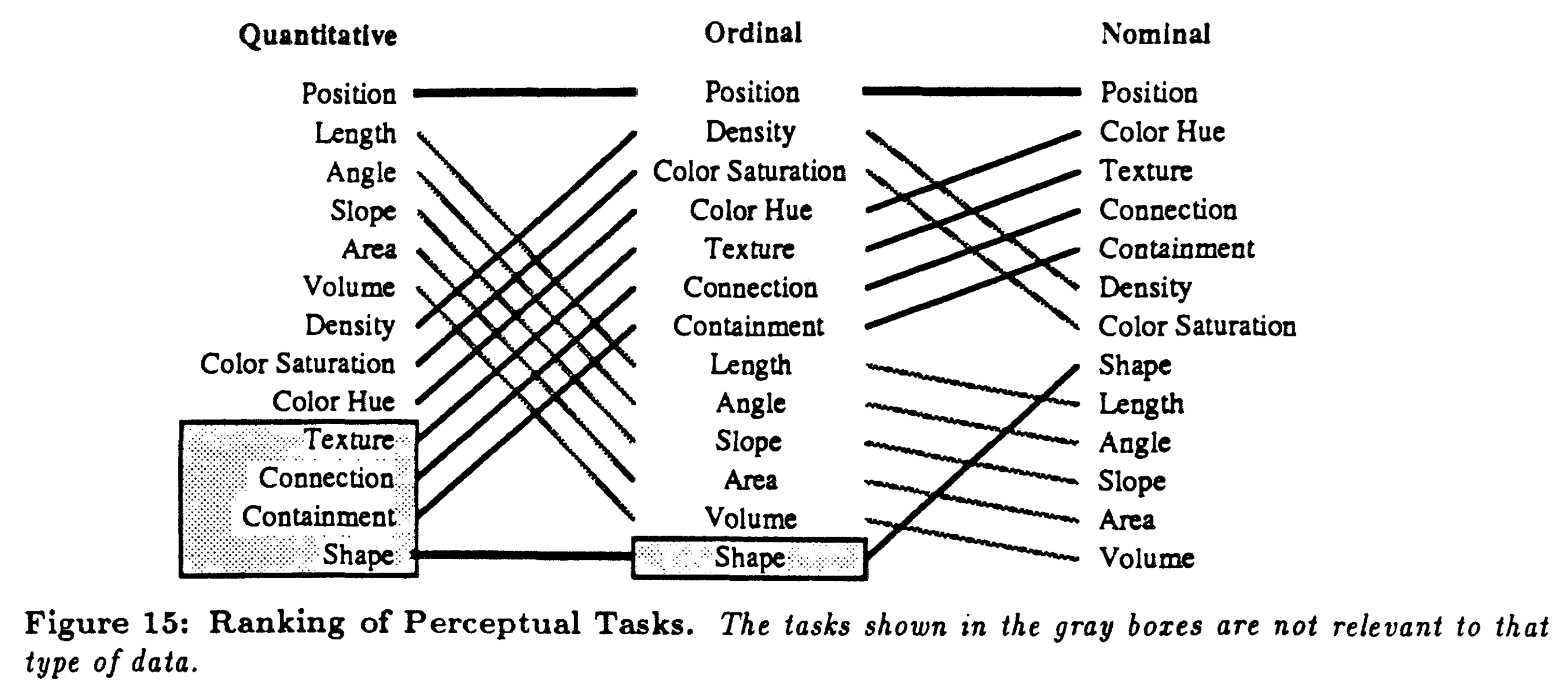
Mackinleyは同論文で、データのタイプによってランキングも変化すると述べています。例えば、定量的なデータ(連続値)ならば、それを形の変化などにマッピングするのはナンセンスですが、小さなグループに別れたデータを形にマッピングするのは理にかなっています。具体例で言えば、
- タンパク質相互作用の図で、同一のスーパーファミリー(グループ)に属するものは同じ形で表す (Nominalデータから形に)
は分かりやすいですが、
- ある社内SNSをネットワーク図で表現し、100人の社員の成績を100種類のノードの形を使って表現する(Ordinalから形へ)
と言うのは出来ないこともないですがナンセンスです。このランキングを一つ一つ見ていけばとても当たり前のことを言っているだけなのですが、それを意識しつつ使い分けるだけで、可視化の完成度は目に見えて上がります。
例: ヒートマップ
ヒートマップはバイオインフォマティクスでもよく使われる手法で、データ全体のトレンドや局所的な変化を把握するのに使われます。例えば(この比喩はあまり正確ではないのですが)ゲノムがスタティックなソースコードならば、マイクロアレイ等の手法で得られるデータは、生命という分子機械(ランタイム)のスナップショットのようなものだと考えてもらえれば分かりやすいと思います。あるシステムの状態を知る、と言う場合は一つ一つの値の細かな差よりも、全体的に赤っぽい/青っぽい、もしくはグループXがアクティブであると言うような、おおよその傾向が見通せれば良いので、近接する値の差を見分けるのが困難で低ランクに位置づけられるが、ひと目で全体の傾向をつかみやすい「色」というチャンネルを使うのが分かりやすい結果を生みます。

特に時系列データならば、タイムポイントごとにマッピングを作り、タイル状に並べればアニメーションよりも分かりやすい可視化を生む場合も多いです。
このようにマッピングには一定のルールは定義できるのですが、「このデータならばこのマッピング」と言うほど単純化が出来ないのが少々難しいところです。良い可視化への近道は、「これは分かりやすい」と思った可視化があれば、それがどのようなデータをどのような視覚変数にマッピングしているのかを意識的に見るようにして、それを自分の作業にフィードバックしていくことだと思います。
本の宣伝
以下宣伝で申し訳ないのですが、間も無く私も参加した本が技術評論社から発売されます。

プロ直伝 伝わるデータ・ビジュアル術――Excelだけでは作れないデータ可視化レシピ
これは、コードを書かない人に向けて書かれた「可視化ツールと事例のカタログ集」という意味合いが強いですが、プログラマの方々にも、どこまでが既存のツールで可能で、コードを書いて実現しなければならない部分はどこから先か?といった判断の助けにはなるのではないかと思います。私は、ネットワーク可視化の章を担当しました。基本的な用語の説明から、実際のデータを使ったサンプルまで含まれていますので、興味のある方は、ぜひ書店にて中身をご覧になてみてください。
中編(未改定)へ続きます
参考文献
- Jock Mackinlay. 1986. Automating the design of graphical presentations of relational information. ACM Trans. Graph. 5, 2 (April 1986), 110-141.
- CPSC 533C: Information Visualization
- Jacques Bertin. 1983. Semiology of Graphics. University of Wisconsin Press.
- Colin Ware. 2008. Visual Thinking: For Design. Morgan Kaufmann Publishers Inc., San Francisco, CA, USA.