はじめに
このシリーズは、Cytoscapeを使ってやIPython Notebook、Pandasなどのオープンソースツールを利用し、公開データを元に実際のグラフ可視化を行う過程を紹介する、可視化の実践者向けの記事です。
更新履歴
- 8/17/2014(日): 一部図や文章にアップデートを加えました。
- 9/8/2014: 第四回でひとまず完結しました。
対話的な環境でのデータ加工

図1: 日本全国の鉄道システムを接続してグラフ化したもの。高解像度版はこちら
はじめに
前回は、データソースからダウンロードしたファイルをIPython Notebookを用いて加工し、Cytoscapeに読み込ませるところまでを行いました。しかし前回の状態では、緯度と経度を用いてノード(駅)を配置する分には問題ないのですが、実際の路線データそのものはグラフになっていません。下の図は前回のデータを別の自動レイアウトアルゴリズムを用いて可視化したものです:

(高解像度版はこちら)
ズームインしてみると、路線ごとの接続はあるのですが、それぞれが独立して存在していることがわかります:
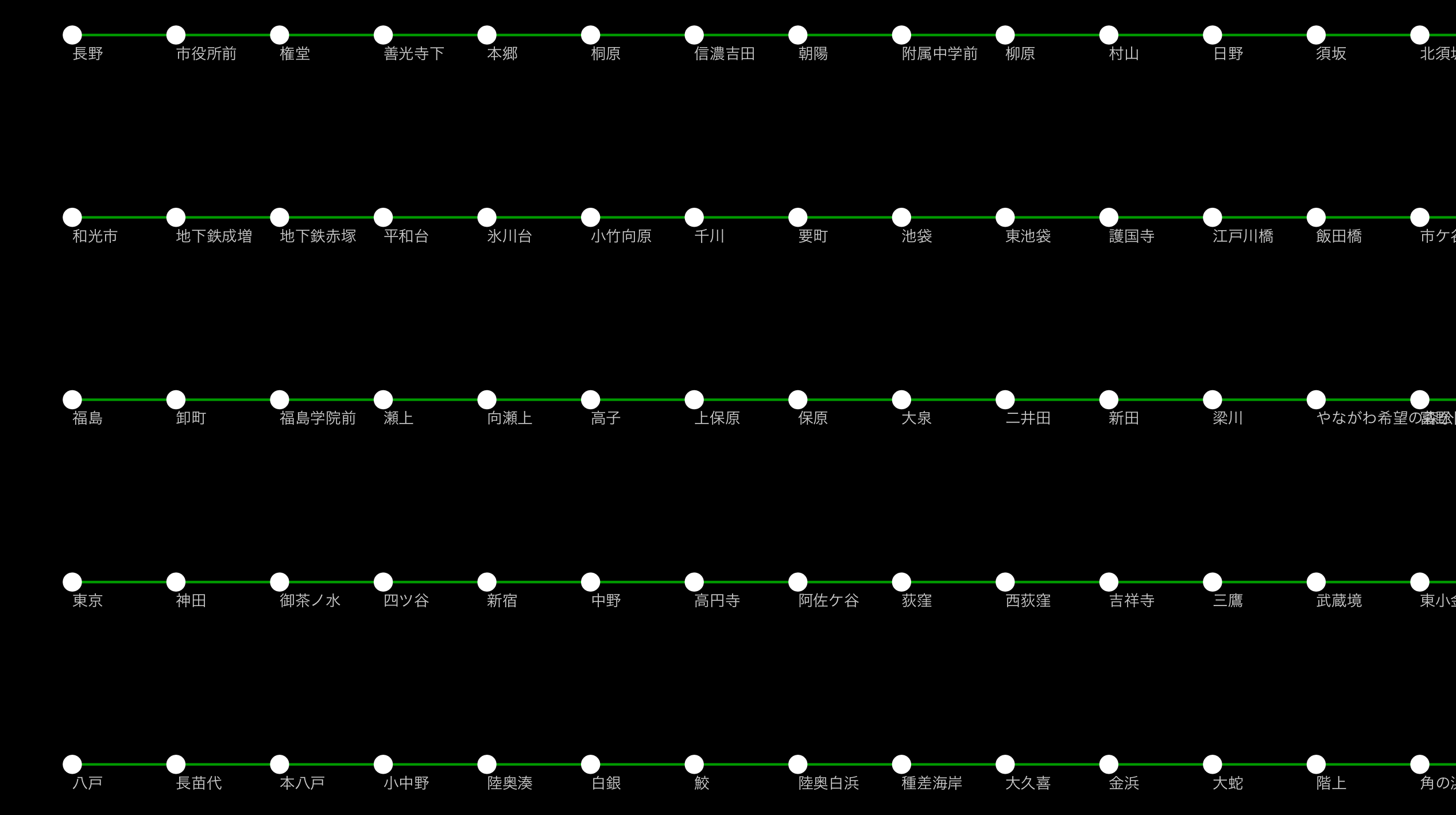
これでは、せっかくの自動レイアウトや、パス検索、その他の機能もうまく動きません。まずこの問題を前回と同じく、IPython Notebookで対話的なプログラミングを行いながら解決し、それに公的機関から提供されているデータを統合して可視化するという作業を行ってみたいと思います。
今回のゴール
- 接続のある路線間を別種のエッジで繋いで、分断された路線データを全国規模のグラフデータにする
- 公的機関から駅の乗降客数に関連するデータを入手し、Cytoscapeで読める形に加工する
- 各路線のテーマカラーをWikipediaから入手し、CSVに加工する
- 全てのデータをCytoscape上で統合し、可視化のサンプルを作成する
実際の作業を記録したノートブック
随時書き加えていきますが、実際の作業の記録はこちらで見ることが出来ます:
これはノート内で使用されているライブラリさえインストールしてあれば、お手元のマシンでそのまま実行可能です。Pythonプログラマでなくても、複雑なことは一切行っていないのでノート内の説明を追っていけば理解できるはずです。ノートブック内で行われているデータの前処理は以下の様なものです。
Pythonで作業する場合の環境構築について
基本的に私はUNIX系のオペレーティングシステムで作業を行っていますが、その場合はAnacondaで環境構築するのが便利です:
この手のデータクレンジングには、Pandas、NumPy、 SciPyと言ったライブラリを利用する場合が多いのですが、この辺りのライブラリの依存関係をうまく面倒を見てくれる上に、pipコマンドともうまく連携して動いてくれます。ライブラリのインストールは、
conda install LIBRARY_NAME
と言うコマンドでほぼ解決できるので、何も考えなくていいです。
データ準備作業の詳細
では早速ノートの中で何が行われているかを実際に見ていきます。できれば実際にノートを実行しながら読んでいただくとわかりやすいと思います。
バラバラの路線データを駅グループごとに接続する
元のデータ内にある__駅グループ__と言う情報を利用して接続を行います。同じグループ内にあるということは、すなわちそのまま乗り換え可能であったり、徒歩で移動できる距離内にそれらの駅があるということです。そこで、グループ内の駅は実質的に他の路線と接続されていると考えることが出来ます。実際の作業では、それらの同一グループ内の駅を新たなエッジで接続していき、クリークを形成するようにします:
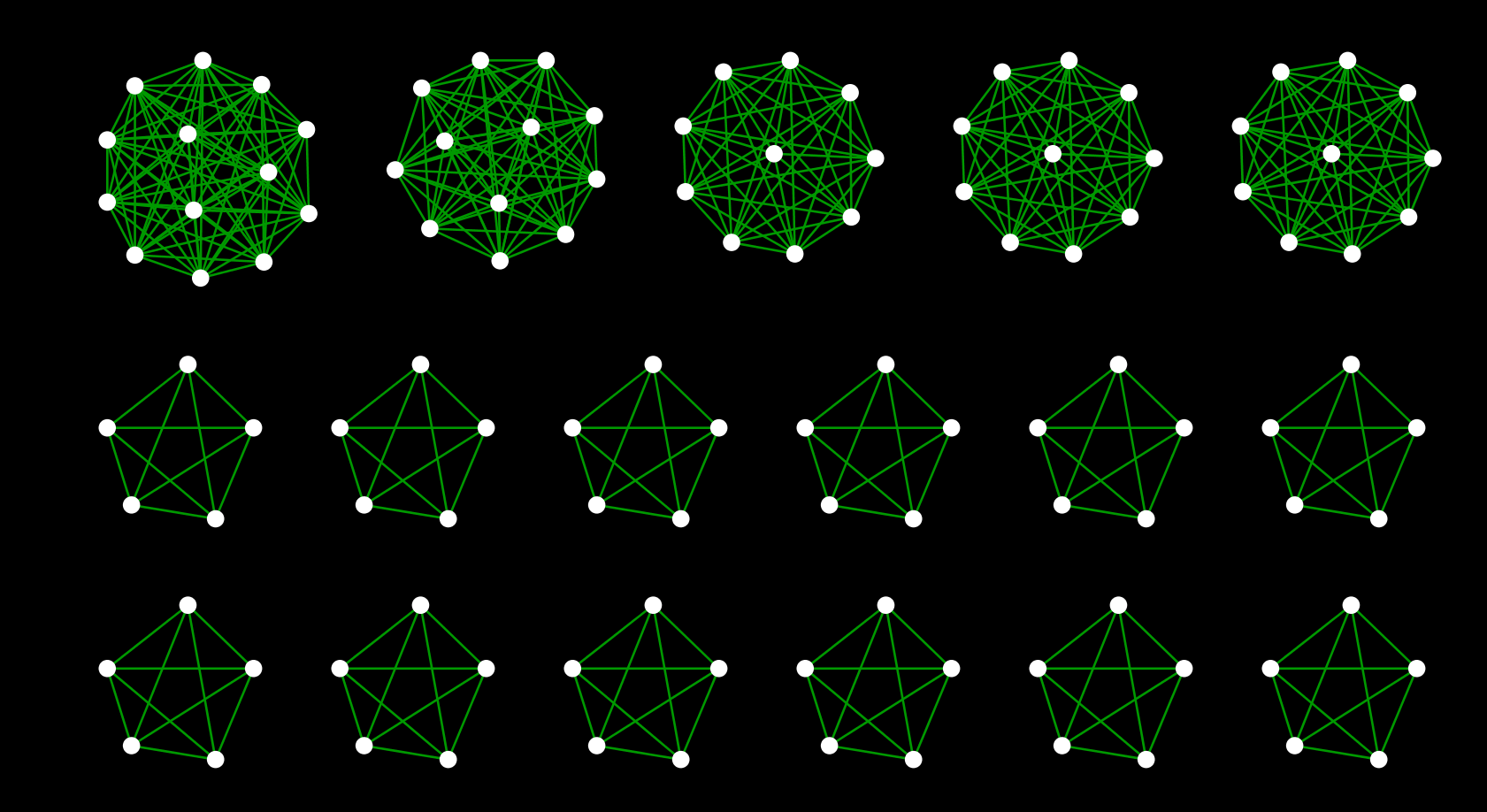
図2:作成されたクリークの一部
これらのクリークを元の路線データにマージすることによって、__図1__のように全国の路線が接続された鉄道ネットワークを形成します。
接続されたグラフの様子を確認する
ここでちょっと脇道にそれて、実際にクリークがどう組み込まれたのか、日本最大の駅である新宿を例に見てみます。新宿駅は、各鉄道路線が乗り入れ、鉄道網の巨大なハブになっています。これを可視化した場合、同一グループに属する駅が構成するクリークとそこから放射線状に伸びる各路線が浮かび上がるはずです。確認のために実際にやってみました。Cytoscapeに読み込む部分は(今は)割愛しますが、以下の図を作る基本的な操作は、
- 全国路線図から_新宿駅グループ_を選択する
- そこから1ホップ以内に存在する駅を抽出(CTR-6 on Windows/Linux Command+6 on Mac)
- 洗濯された部分グラフから新たなネットワークを作成(CTR+N on Windows/Linux, Command+N on Mac)
- 新宿駅グループとそれ以外にそれぞれ円環レイアウトアルゴリズムを適用
- 単純なStyleを作成し、グループ内エッジを他と区別する
これを行うと以下の様な図を描画できます:

(ハイレゾ版)
緑色の点線が乗り換え可能な(徒歩圏内にある)経路を示し、実線が各路線を表します。これを見る限りではうまく接続されたようですね。
公開されている他のデータセットを鉄道ネットワーク上にマッピング
これでひとまずCytoscape上で利用できる「鉄道の白地図」が出来ました。このデータを白地図と呼ぶのには理由があります。それは__このネットワーク上に自由に他のデータセットをマッピングして、独自のビジュアライゼーションが作成できる__からです。これが概念的なグラフという構造に地理データを落としこむ利点でありそれをCytoscapeで利用するポイントです。考えられるマッピングは無数にありますが、単純な例だと以下の様なものがあります:
- 興味のある路線をサブグラフとして切り出し、そこに一日あたりの乗降客数を視覚的にマッピングする
- 路線ごとの移動可能人数(一日あたりの本数 x 列車のキャパシティ)を計算し、おおまかな乗客の流量をエッジの太さにマッピングする
- ある路線を切り出し、その沿線施設を他の地理データから抽出し、最寄り駅に新たなエッジを使って接続。それらに新たなレイアウトを施し、インフォグラフィック化
これらは全て単純な例ですが、マッピングできるデータが増えれば増えるだけ、更なる可視化の可能性は広がります。まずは基本的な機能を実感してもらうために、何かシンプルなデータはないかと考えたのですが「一日あたりの乗降客数」あたりが分かりやすいのでは、と思い公開されているデータを探し始めました。
公共データの入手と掃除
実は私、今まであまり日本の公的なデータセットというものをまじめに見たことがありませんでした。実際に探し始めてわかったのですが、各省庁が把握している統計などは一応公開されているのですが、やはりまだ__人が読む文章として公開する傾向がとても強いです__。「駅ごとの乗降客数」と言う極めてシンプルなデータセットですが、_駅名-乗降客数_のペアとしてテーブルが公開されているわけではありません。今回私が「発掘」したのはこのデータでした:
XMLファイルで公開されているので、比較的加工しやすいはずと思い作業を始めましたが、いきなりparserがこけました。原因はタグ閉じのミスという単純なものでしたから、
cat S12-13.xml | sed -e "s/ksj:ailroad/ksj:railroad/" > fixed.xml
で修復可能です。
実際に利用する場合の問題点
実際に手を動かして中身を精査すると、思ったほどシンプルには出来ないことに気づきました。問題点としては以下の様なものがあります:
- 乗降客数が必ずしも駅ごとのデータにはなっていない
- 一部のデータは他の駅との合算になっている
- データの欠損 - そもそもデータがない駅もある
- 合算データの合算先のID
- 合算した場合の合算方法は、備考欄に自然言語で書いてある
- 合算先のIDは無い
この時点で若干やる気が無くなりましたが、手法のデモということで出来る部分だけやるとして、そういう部分は見なかったことにして進めました(仕事ではこうは行かないと思いますが...)。ノートに書いてあるようなある意味しょうもない作業を行った後、以下のようなテーブルを得ました:
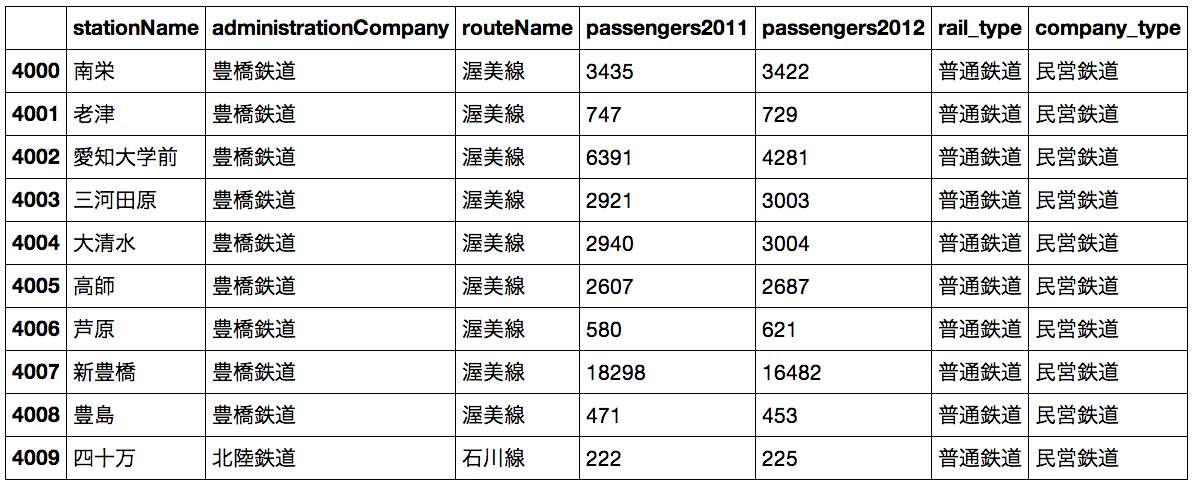
コード化された情報をわざわざ冗長な文字列情報に変換している理由はノートブックにも書きましたが、人が読める文字列として保存しておくことにより、可視化ソフトウェアで作業がやりやすいからです。大規模な解析や可視化にはこういった作業はかえって有害にもなりますので、データセットのサイズなどを見極めて、利便性と計算機にとっての_重さ_を比較しながら適切な手法を選びましょう。
スクレイピングによる路線のテーマカラー情報入手
WWWは人間が読める文章をリンクすると言うアイデアから始まったので、機械で処理することを前提とせず人が読むようにデザインされたテーブルとして公開されているデータも膨大な量にのぼります。そしてそういったデータに意外と有益で使いたい情報が埋もれているものです。
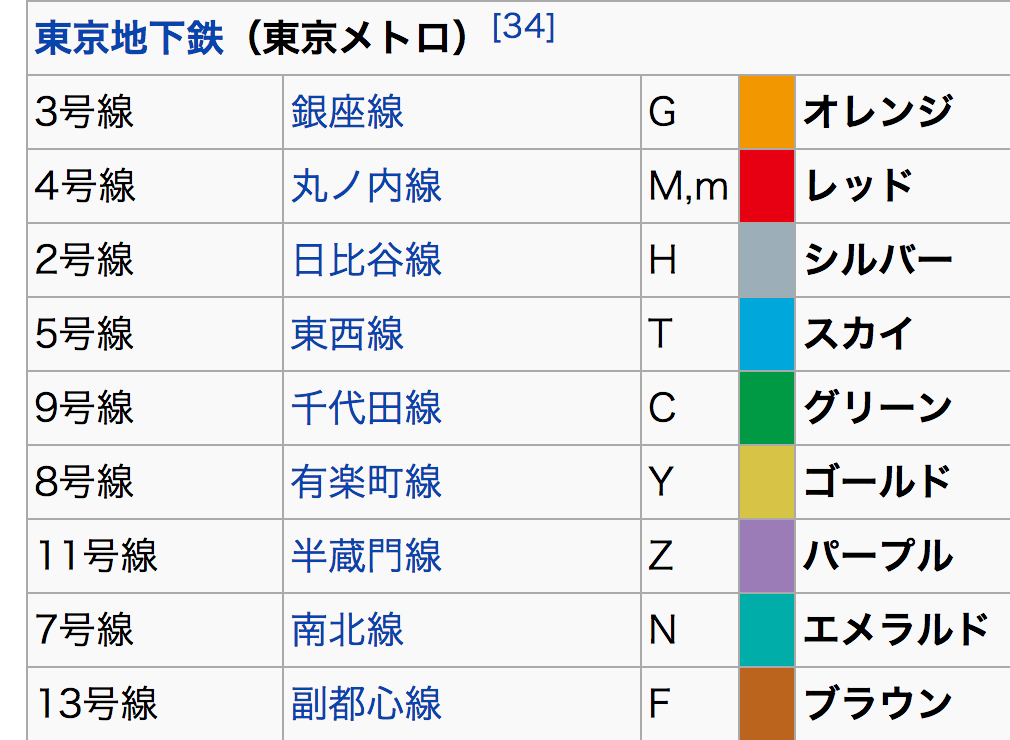
Cytoscapeでネットワークを可視化する場合には、全ての画面上の要素に対して自由にカスタマイズされた色マップを作成することが出来ます。今回のデータセットの場合は、自らかってにカラーコーディングを設定するよりも、人々に馴染みのあるものを用いた方がより分かりやすい、効果的な結果が得られます。東京メトロの場合は、以下の色使いが標準的です:
この色情報を機械で簡単に読めるファイル形式で入手できないかと考えたのですが、残念ながら見つかりませんでした(ご存じの方が居ましたら教えて下さい)。しかし人間が読める文章としてはしっかり公開されていました:
そこでこのページから無理やり切り出すことにしました。こ文章の中に埋もれたデータは色々と例外もありますが、多くの場合それなりのパターンがあるので、ざっと取り出すだけなら簡単です:
<tr style="height:20px;">
<td>3号線</td>
<td>
<a href="/wiki/%E6%9D%B1%E4%BA%AC%E3%83%A1%E3%83%88%E3%83%AD%E9%8A%80%E5%BA%A7%E7%B7%9A" title="東京メトロ銀座線">
銀座線
</a>
</td>
<td>G</td>
<td style="background:#f39700; width:20px;"> </td>
<td><b>オレンジ</b></td>
</tr>
この中にある__#f39700__と言うデータを__東京メトロ銀座線__と言うキーを組み合わせれば、Cytoscapeに読み込ませ、色データは_Passthrough Mapping_でそのまま使えます。幸いPythonにはこういったスクレイピング作業を行うライブラリが豊富に揃っていますので、それらを使い大雑把な切り出しを行いました。この作業に関してはいくらでも改善が可能ですが、デモ目的ということで、汚くてもいいので、最小限の作業で得られる結果にとどめました。
スクレイピング結果を確認する
今回は東京メトロを題材に可視化を行うので、その部分のデータだけでもきちんととれているのか確認します。ワンライナーでやってみましょう。
grep 東京メトロ line_colors.csv | awk -F ',' '{print "<span style=\"color:" $3 "\">" $2 "</span><br />"}' > metro_colors.html
結果は以下のようになり、元のデータと比べても問題無いとわかります:
(Generated HTML)

(Original Table)
以上、前回の部分も含めて、全ての作業はIPython Notebookに記録してありますので、実行自体は数十秒で終わるでしょう。興味のある方は、生成されたテキストファイル(CSV)をのそいてみてください。これらは全てCytoscapeに容易に読み込むことができます。
Cytoscape上での統合とマッピング
さてやっとCytoscapeでの可視化です。しかしかなり長くなってきたので、この部分の詳細は次回に持ち越すことにします。次回のプレビューとして、一度Cytoscapeに読みこませるとどのような加工が可能かを簡単に紹介します。
全てを読み込ませて作業中のデスクトップ
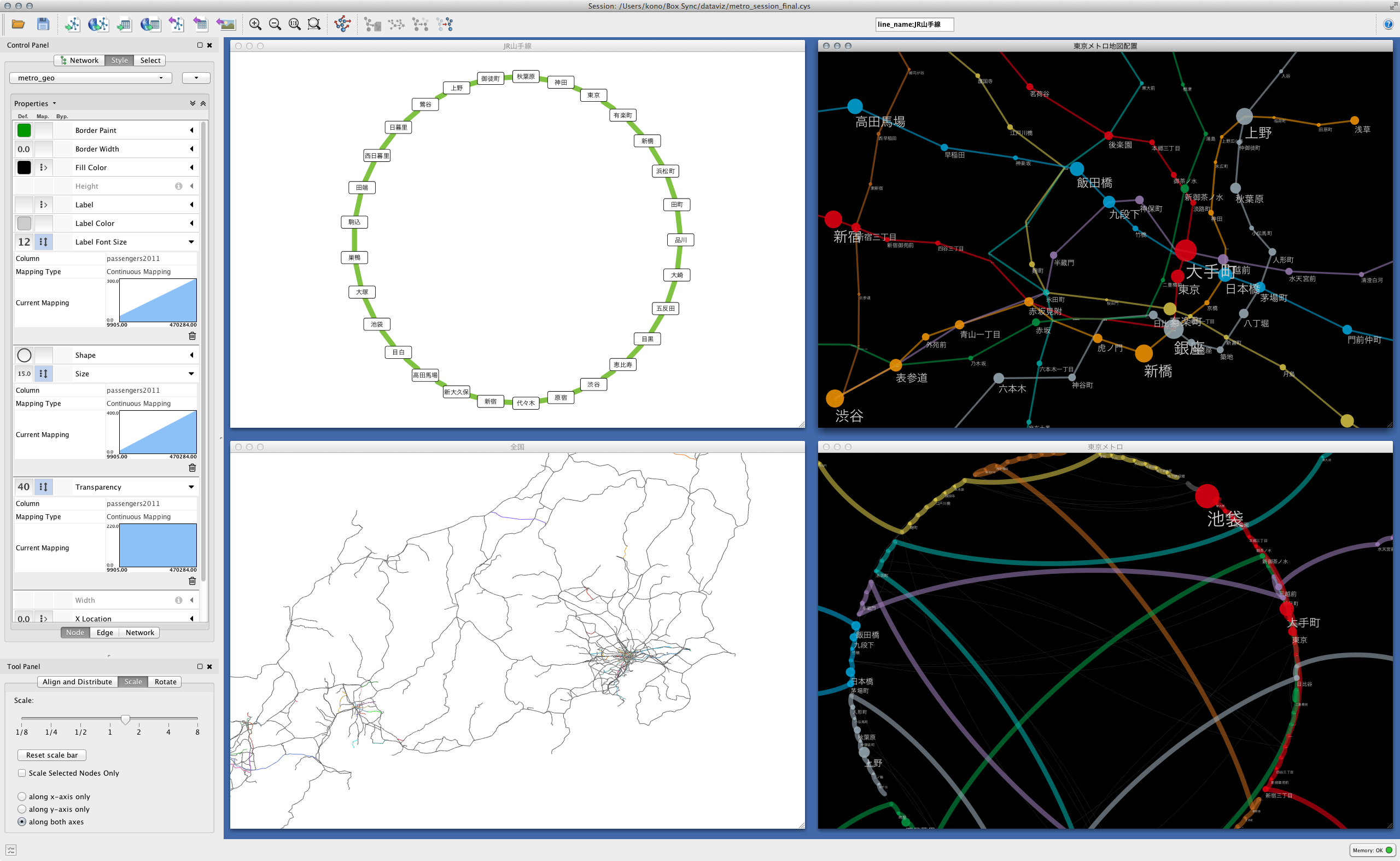
(ハイレゾ版)
地図上の位置を使って相対的な位置関係を示した東京メトロの各駅
(ハイレゾ版)
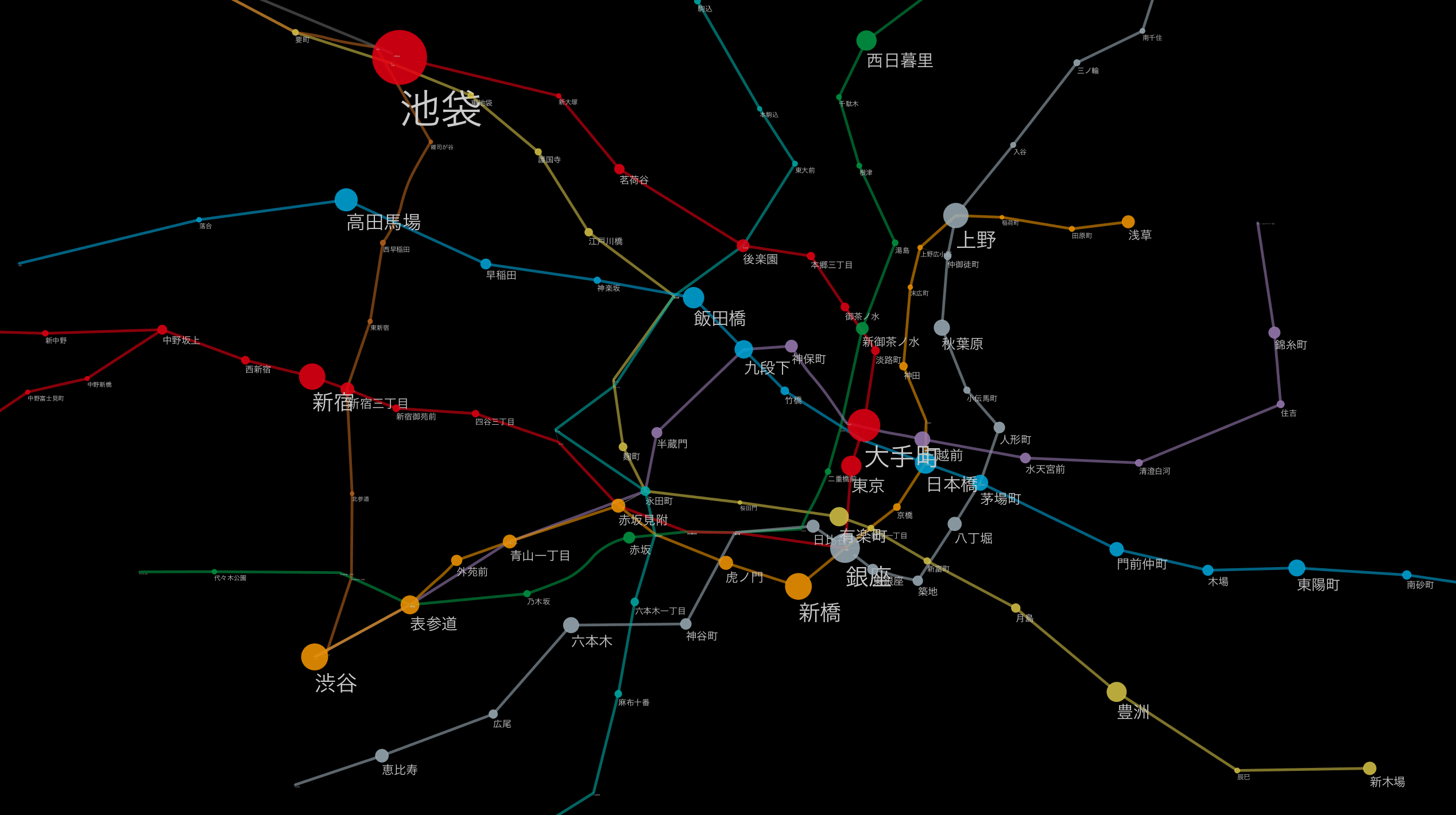
別のレイアウトアルゴリズムを適用した例。
ラベルの大きさは一日の乗降客数にマッピング
(ハイレゾ版)
山手線をシンプルな接続図として
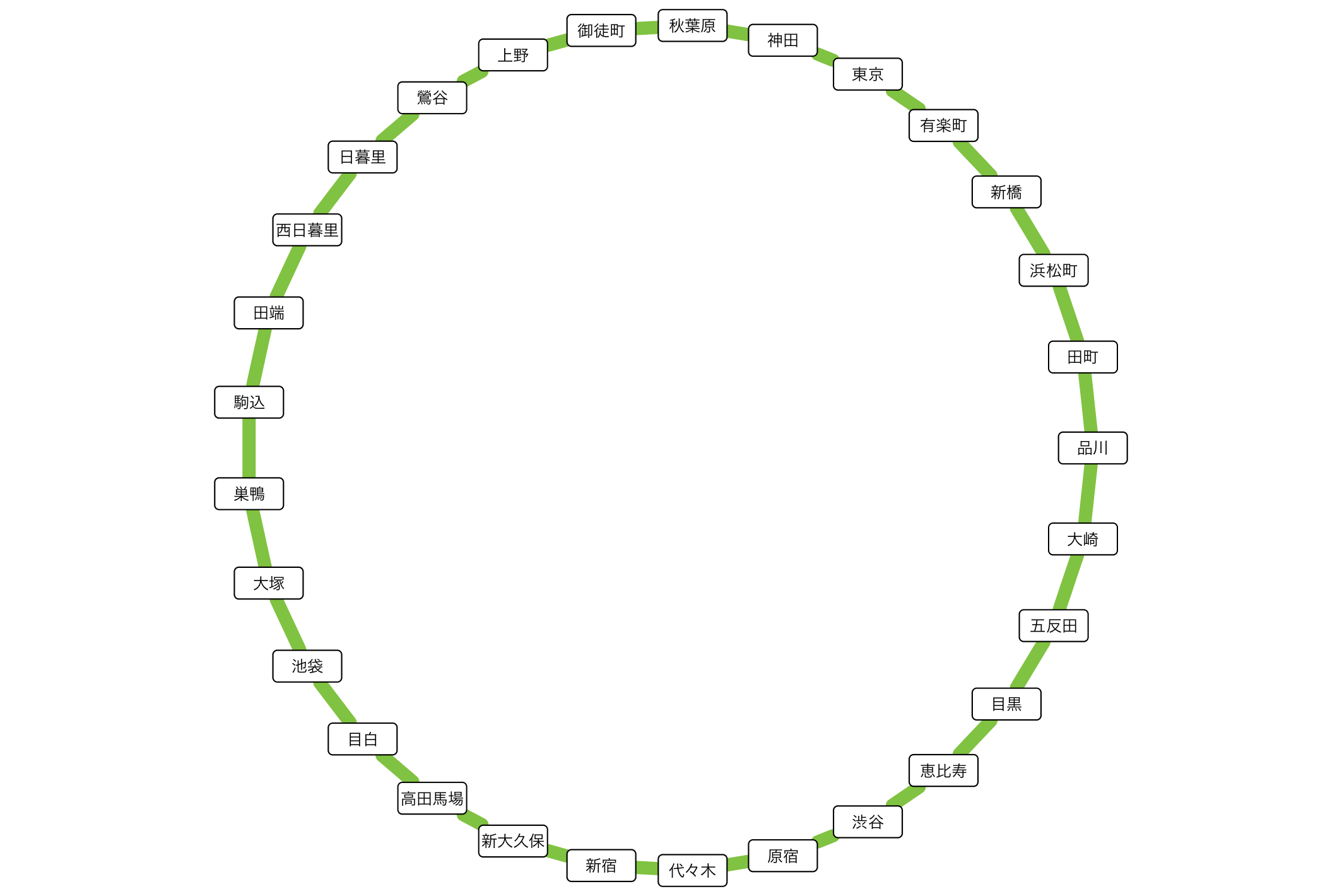
(ハイレゾ版)
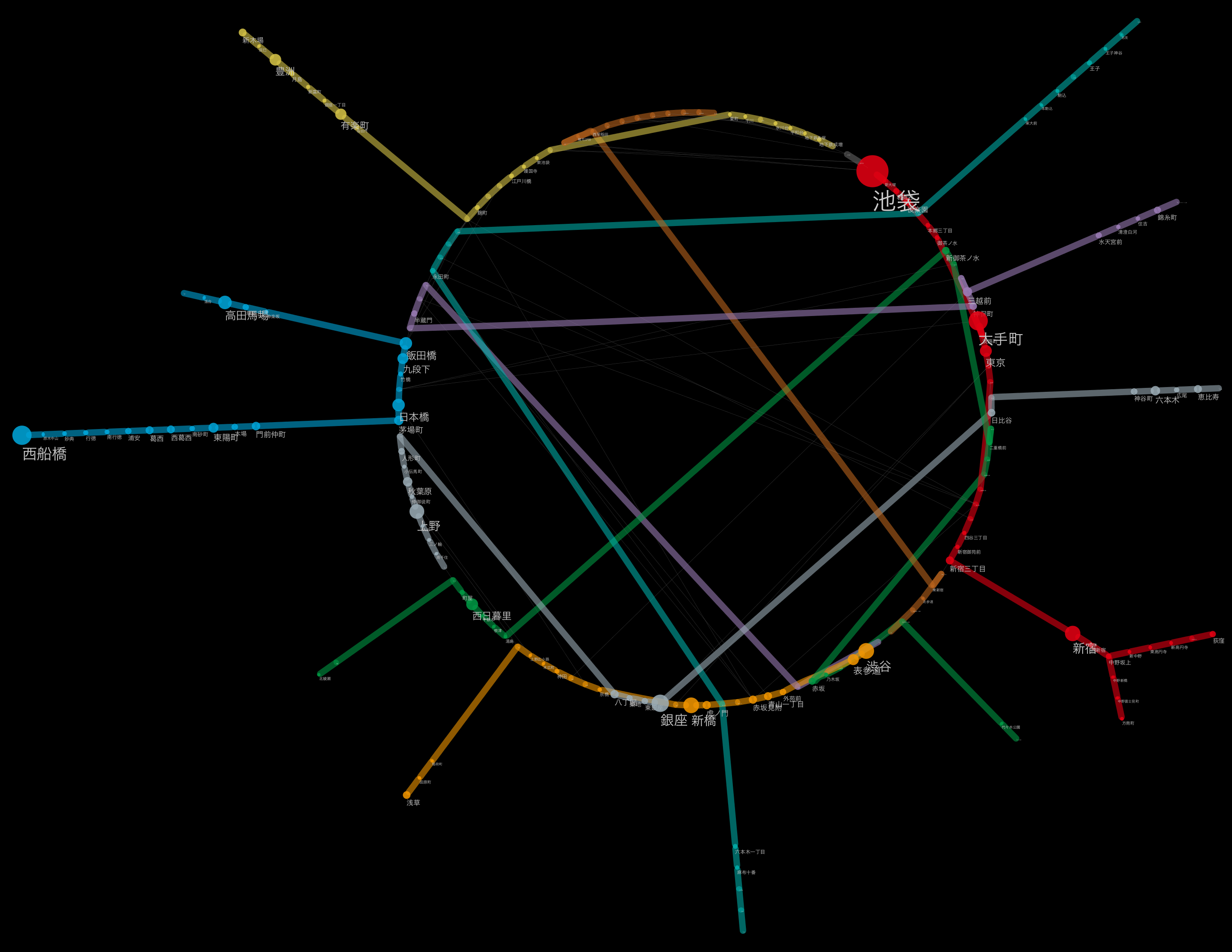
自動とマニュアルレイアウトを組み合わせる(路線ごとにレイアウト適用)

(ハイレゾ版)
終わりに
「全ての公の統計がMachine-Readableなかたちで公開され、コードが書ける人間はそれらを利用して新たな価値を生み出すアプリケーションを作り、統計家は統合した結果から新たな知見を得る」
そんな世界がいつかは来るのかもしれません。しかし少なくとも今はこれが現実です。「汚れたデータ」を発掘し、掃除して使える形にまとめると言うのはとても地道でつまらない作業ですが、現状では避けられないプロセスです。道具は揃ってきました。コードを書ける方は手を動かして、何が問題なのかリストアップしましょう。そして提供する側に伝えましょう。長い目で見た場合、恐らくそれが唯一の解決方法です。
ノートブックをご覧になった方にはわかると思いますが、一般的なカッチリしたプログラミングと異なり、ある特定の可視化で利用するデータを準備する場合、私は__効率やエレガントさよりも、何をやったのかあとで読み返してわかればいい__というポリシーでやっています。ワークフローの再利用性などという点ではまだ試行錯誤が必要ですが、必要以上に凝ったことをするよりも可視化アプリ(Cytoscapeはもちろんですが、D3.jsで作成したカスタム可視化アプリケーションなども含む)で利用する使いやすいデータセットに仕上げることに主眼をおき、ある程度の妥協をしながら作業を進める、という割り切りも可視化の現場で働く人々には必要かもしれません。今はGitやIPython Notebook、RStudioといった道具を組み合わせ、思考の過程も含めた記録をストレスなく自動的に保存していくことが可能です。これらを利用して、徐々に自分にあったワークフローを見つけると言うのが良いと思います。
FBグループなので会員でない方には申し訳ないのですが、こういった可視化に興味のある方は、こちらのグループに参加してみてください。問題点やノウハウを共有して行く予定です。可視化の現場で手を動かす人々のためのグループです。