このシリーズは、Cytoscapeを使ってやIPython Notebook、Pandasなどのオープンソースツールを利用し、公開データを元に実際のグラフ可視化を行う過程を紹介する、可視化の実践者向けの記事です。
グラフ可視化ソフトCytoscapeによる地理情報データの可視化
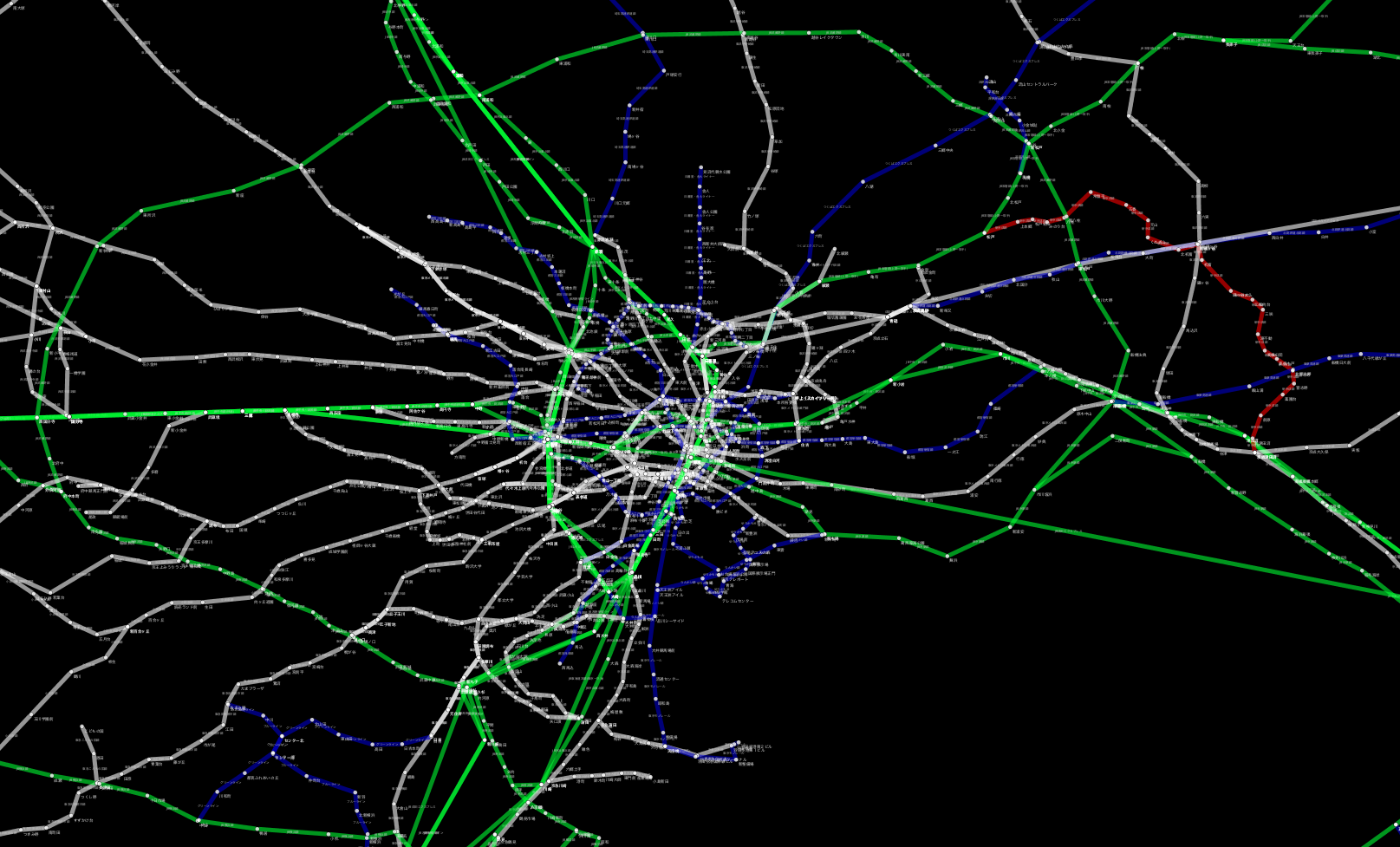
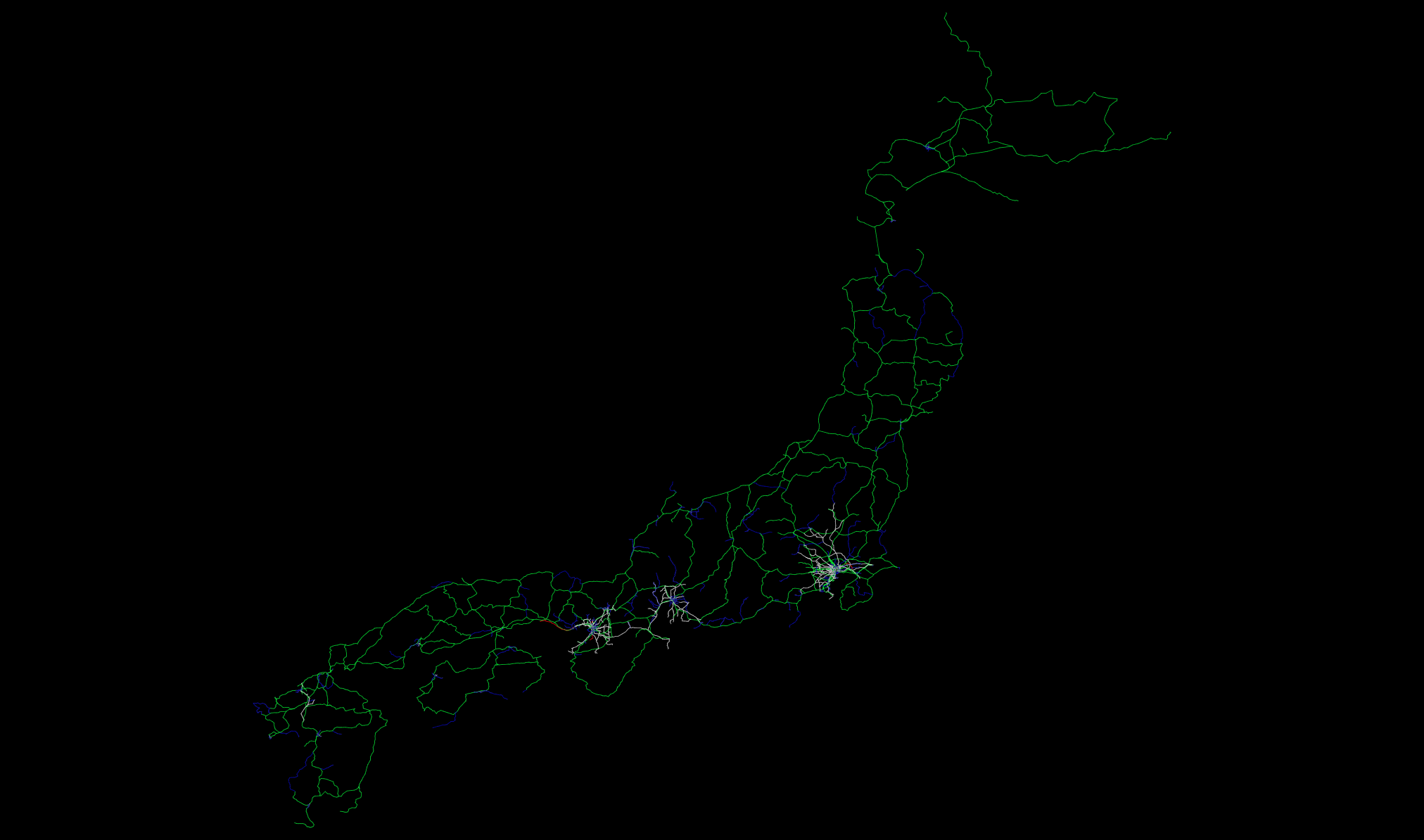
(Cytoscapeによる東京周辺の路線図可視化。ハイレゾ版はこちら)
はじめに
現代の地図はグラフです。そもそも数学的グラフの研究は現実世界の経路問題から始まりました(ケーニヒスベルクの問題)。計算機科学を専攻した方は、学生時代に単純化した最短経路検索や各種経路問題を課題で解いた記憶があるかと思います。そして恐らくそこでクラスNPの問題がどういうものかとか、NP困難とは何か等々込み入った話もそこで知ったはずです。とても身近に見える問題群が複雑な数学の世界に繋がっていることはとても興味深いことだと思いませんか?
さて、そんな身近で奥深い地図グラフの問題ですが、誰にでも馴染みのある地理的な情報を使って実用的な例が作れないかとデータを探していたところ、日本でもちゃんと機械で読める形で鉄道路線図データを入手できることを知りました。

これを加工して何か実用的な例は出来ないかと考え、とりあえず手を動かしてみました。私はデータ解析者ではなく単なるプログラマなので、たまにこういう作業で自らドッグフードを食べるのは、自分の作っているものの問題点などを知ることができるので良い経験でした。
路線図とグラフ
電車の路線図というのは、グラフ関連の問題入門としてとても良い例です。というのも、例えば「東京から名古屋まで行きたい」と思った時、大事な情報はどのように線路が実際に敷設されているかという詳細よりも、東京駅と名古屋駅の間にいくつの駅があって、そこに到達するにはどのような路線があるか、と言う抽象化された部分にあるからです。従って、全国の鉄道路線のデータがグラフとして手に入れば、それを元に各種の可視化や解析が行えます。つまり今回のゴールは、__各種データを統合して、より便利な可視化に使える路線図の「白地図」を作成する__ということになります。
今回のデータ
上記の駅データ.jpからダウンロードできるデータは、詳細なドキュメントが用意されています。とてもシンプルなCSVで用意されているので、機械にとって扱いやすいものです(PDFやWordで各種データを流す人々も、Linked Dataにしとろまでは言わないですが、こういう方向に変わって欲しいものです...)
まずは先のリンクにあるドキュメントを読み、どんな情報が含まれているのかを確認してみてください。
Cytoscapeに読める形に加工して得られる自由度
Google Mapと言う素晴らしい情報源があるのに何でわざわざこんなことをするのか?と言う疑問を持たれる方もいると思います。それにはいくつか理由があります。
外部データのマッピング
一般的な地図アプリケーションは、エンドユーザの利用目的に最適化されています。すなわち:
- 目的の場所に素早く行く
- 自分の周りに何が存在するのかを把握する
と言う作業をいかにストレス無く行えるかという点に開発者は腐心しています。一方、データ解析をする人々のニーズはかなり異なるうえに多岐にわたります。例えば:
- 各駅の乗降客データを路線図にマッピングして表示すると何が見えるのだろう?
- また、そのデータの年度ごとの変化を見てみたい
- 駅Aを出発点にした人々の今日の移動傾向はどうなっているのだろう?最終目的地ごとの客数の分布を路線図にマッピングしたい (注)
等、路線図上にマッピングして意味のあるデータならば、ありとあらゆる可視化のユースケースがあります。これらのニーズを満たそうとした場合、一般的な地図アプリケーションだと若干使い勝手が悪いと思います。一方、Cytoscapeにグラフ化して読みこめば、基本機能であるVisual Styleを設定することにより、様々な外部データセットをグラフ化された路線図に乗せて行くことができます。一例をあげると:
- 各駅の乗降客数をノードの色にマッピングしてヒートマップ化
- 一日あたりの各路線の本数をエッジの幅にマッピングして日本の鉄道路線における「動脈」を可視化
- 駅周辺の徒歩圏内著名スポットをノードとして追加し、別のタイプのエッジとして駅に接続。路線図をスポットを主情報とするグラフへ変換
といったものが思い浮かびます。要するに、利用者の思いつく分だけサードパーティのデータを加えた独自の可視化の方法があります。
(注:そのような人々の行動データが手に入るかどうかは別問題です)
検索と切り出し
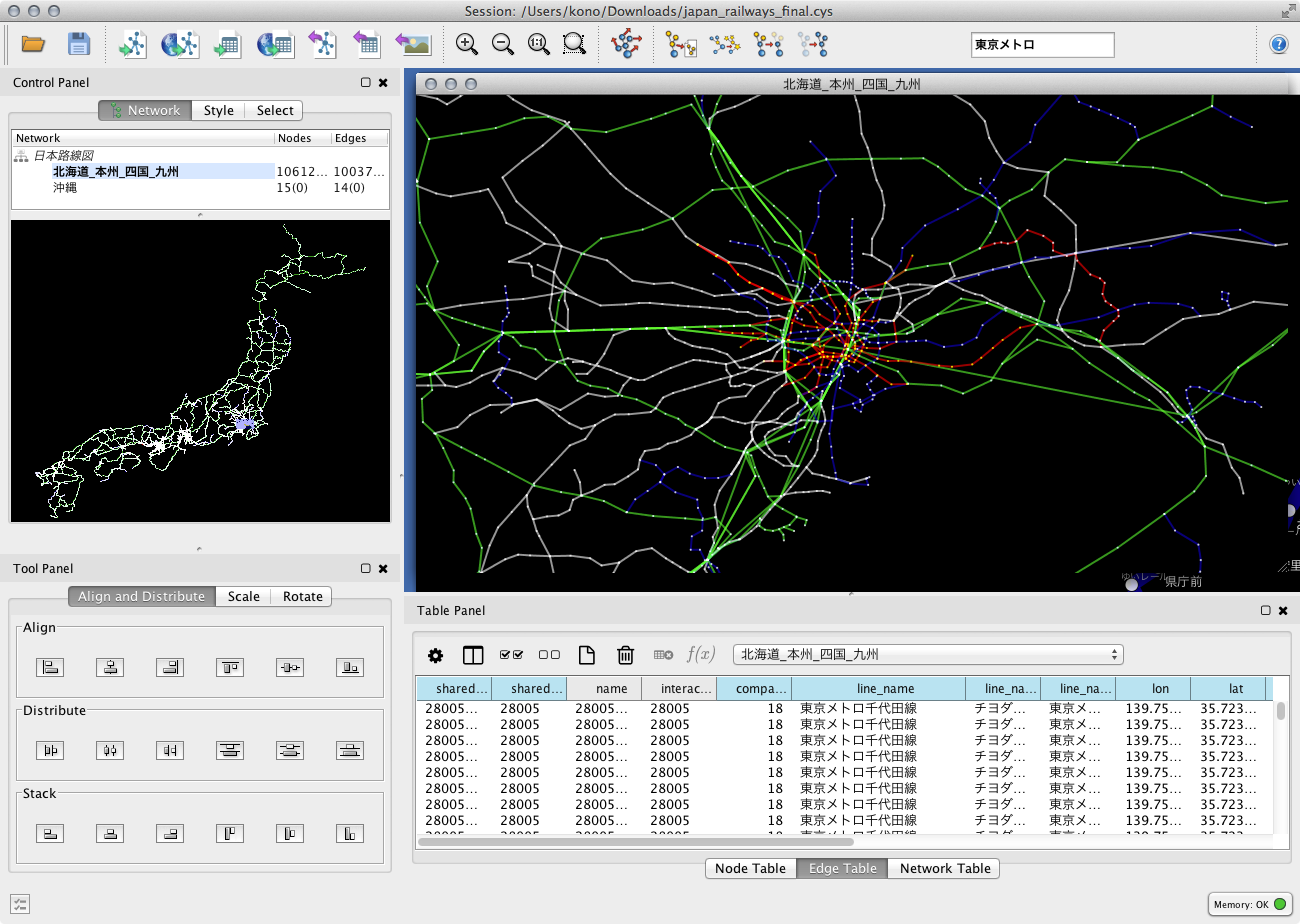
一度Cytoscapeのセッション化されたデータは、ノードやエッジのアトリビュートを使用し、Luceneの文法で自由に検索可能です。最も単純な例をあげます:
-
__「東京メトロ」__と言うキーワードで検索(エッジの選択)
-
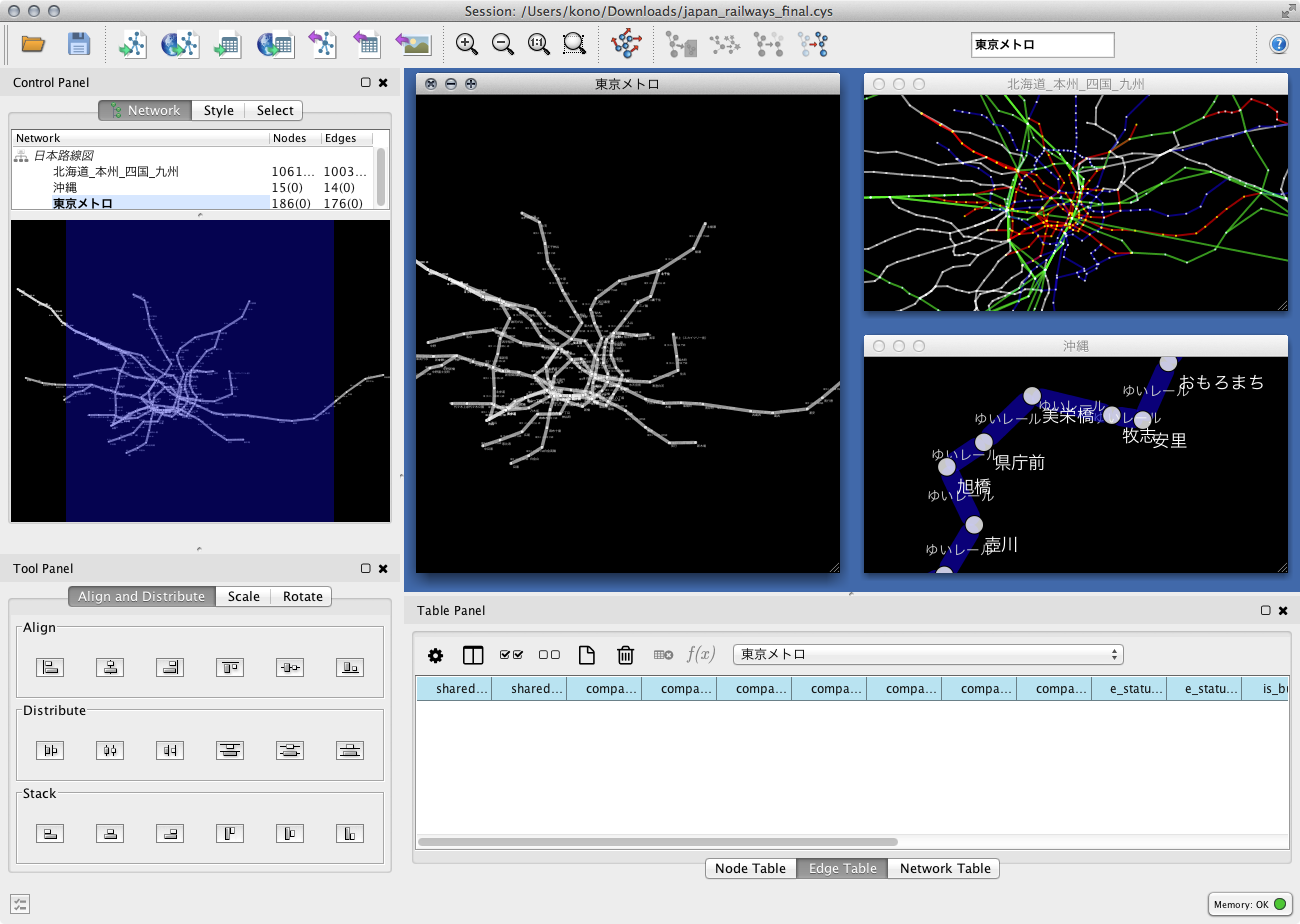
路線上の駅を_CTR+7 (MacはCommand+7)_で選択し、_CTR+N (MacはCommand +N)_で新しいグラフとして切り出し
-
カスタムスタイルを付与
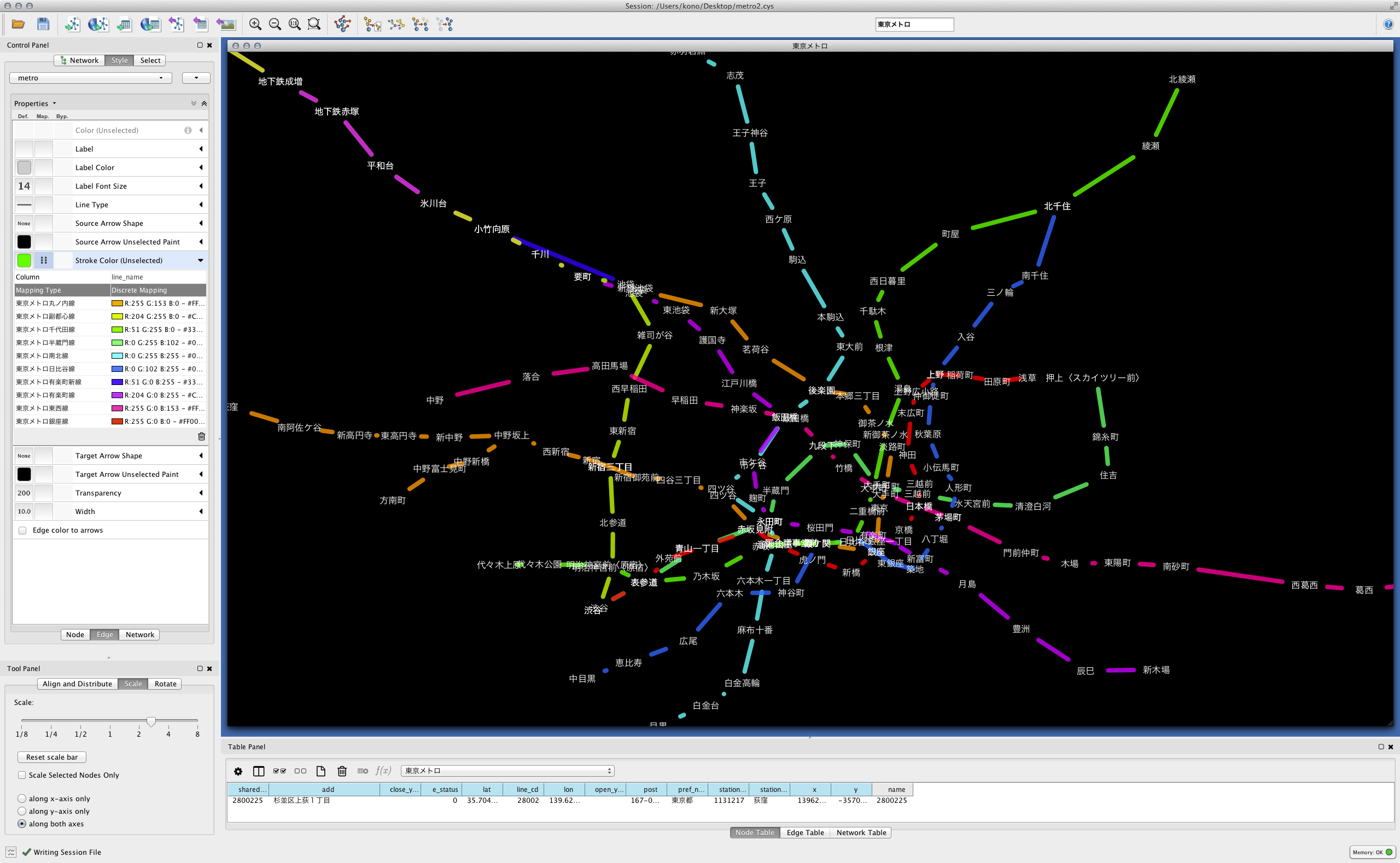
このように、全体から部分への切り出しと加工が容易になります。
レイアウトの自由度
今回の例では、データを緯度と経度に基づき固定レイアウトしましたが、より抽象度の高い可視化を作成する場合には、日本地図上の位置が必ずしも必要ではありません。そんな時には、見やすいように切り出し、分割し、再レイアウトを簡単に行えます。

D3.jsなどを使ったさらなる可視化づくりの前のラフスケッチ
Cytoscapeは、グラフ可視化に関してはかなり自由度の高いソフトウェアですが、ボックスプロットやヒストグラムを描いたりする機能は(今のバージョンでは)ありません。各種チャートと路線図を組み合わせて、更に複雑な可視化を作りたいとき、ラフスケッチとして色々と試行錯誤することも出来ます。
実際の作業
データの掃除・加工・可視化
さて、ここでは実際の(泥臭い)データの加工作業を見てみます。
データの準備
まずはデータをダウンロードするところから初めてください。ダウンロード可能な全ての無料版データを利用します。
PandasとIPython Notebook
こういった記事に興味のある方には言うまでもないと思いますが、Pythonはデータを加工する人々にとって標準的な道具です(日本での普及具合は今ひとつわからないのですが、私の住んでいる米国では少なくともそうです)。コマンドラインを開き、テキストをAWKのワンライナーを駆使して切り貼り加工、パイプして...というのも簡単な作業にはいいですが、IPython Notebook + Pandas + Numpy + Scipyの自由度はきっと皆さんの作業時間を減らしてくれることでしょう。私は初級者レベルのPythonプログラマですが、道具として使うのは本当に簡単です。一つだけポイントが有るとすれば、__forでループを回さず、ワンライナーとしてのラムダ式をデータフレームに適用し、データを変換、統合し、簡潔に記述していく__ということだと思います。関数を渡してデータを加工するやりかたは記述がスッキリとするので、ノートブックとしてまとめた時叙述的な文章として自然にコードが読めると思います。
(ただし、私はPython初心者なので、上級者の方でもっと良い方法があると言う方はぜひ教えてください。特に大規模データにPythonであたる時のパフォーマンスに関するノウハウを私は持っていないので。関数型の記述によるパフォーマンスペナルティなどは一切考慮に入れない記述をしています)
データの加工
実際の加工では、このようなことを行っています:
- 有料版のみに用意されているカラム、必要のないカラムを除去する
- エッジ(辺)に関するデータを統合する
- 駅に関する情報が欠損しているエッジを除去する
- Cytoscapeに読み込めるCSVファイルに書き出す
全ての加工の過程は、暫定版ですがこのノートブックに記録されています。今回は、Cytoscapeに読み込めるファイルを書き出すところまでです。本格的な作業に必要なさらなるデータの加工は今回の分には含まれていません(後述)。
因みにこのデータは比較的綺麗に整理されていると思います。実際にある公共のデータには、もっと欠損値やエラーが多い場合があり、そういった話題についてもっと知りたい方はこの本がお勧めです:
- バッドデータハンドブック――データにまつわる問題への19の処方箋 (オライリー刊)
「SPAQRLエンドポイントにクエリを送れば全ての公共データがmachine-readableな形で返ってくる」と言う未来は今のところ遠大な目標なので、暫くはこのような泥臭い作業が必要になりますが、状況は徐々に良くなっていくと思います。IPython NotebookやR Markdownのおかげで作業の再現性は良くなってきていますし。
Cytoscapeへのデータ読み込み
後ほど追加するかもしれませんが、ここは基本的なファイル読み込み操作なので割愛します。最終的な2つのCSVファイルをGUIから読み込むだけです。
VIsual Styleの作成
データを読み込んだあとに基本的なスタイリングを施すわけですが、ポイントはたった一つです:
- x, _y_というアトリビュートを使って、x, yの各Visual Propertyに対してPassthroughマッピングを設定する
これはつまり、画面上の位置をデータファイルの中にある座標で直接指定するということです。Visual Styleは複雑な機能なので、回を改めてまた解説します。
現在の暫定版セッションファイルはここにあります。Cytoscape 3.1.1で開いて色々といじってみてください。
- Cytoscape Session File: Japan Railways (for Cytoscape 3.1.1)
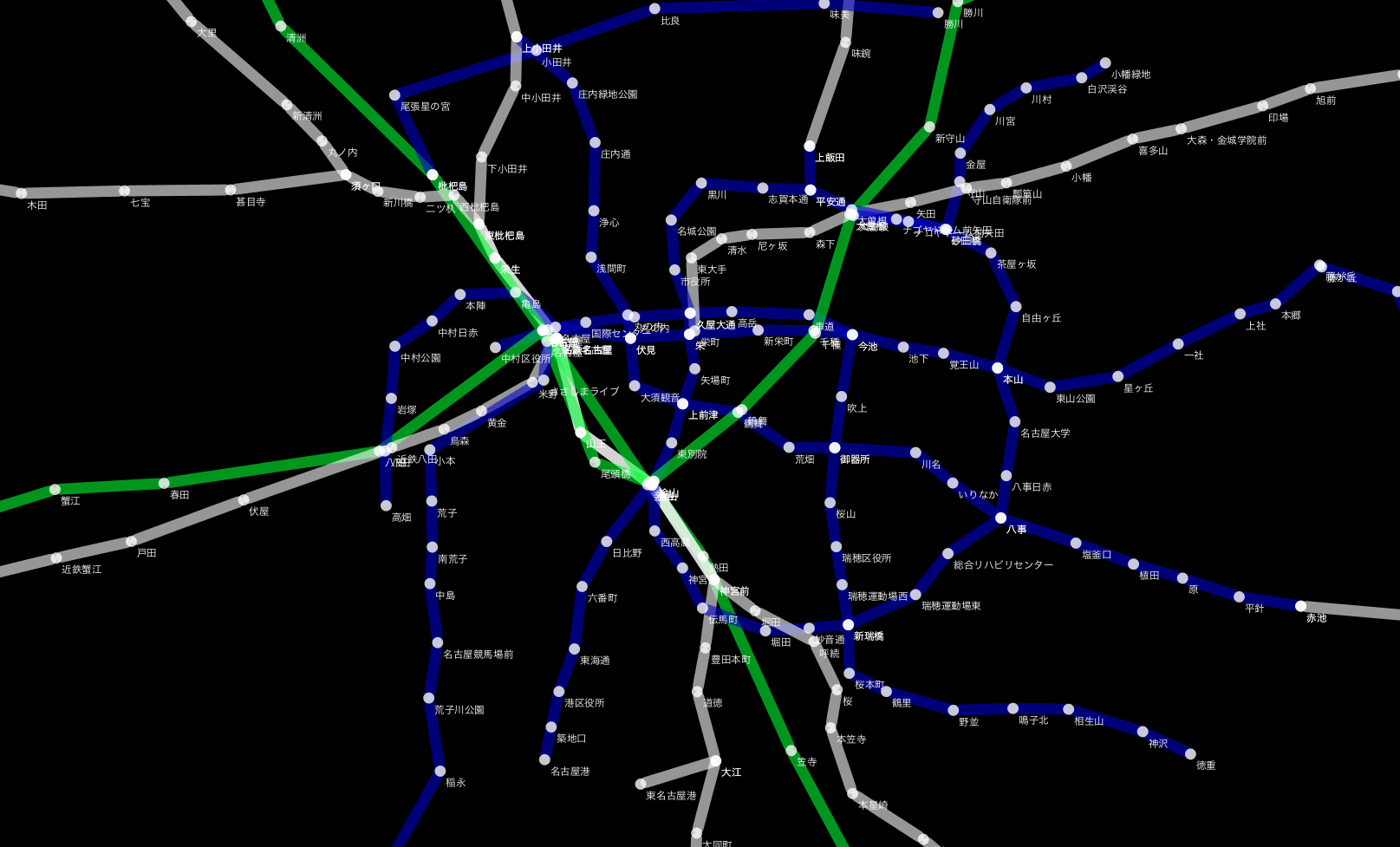
問題点
それなりに綺麗に描画できましたか?地元へズームインしたり、スタイルを変更したりして遊んでみてください。しかし、実は今のままでは経路問題等をグラフとして解析するのに大きな問題があります。それはこのデータが路線ごとに完全に分断されていると言う点です。現実世界の鉄道システムを考えてみましょう。各路線はリニアな繋がりとして表現できます。そして、いくつかの駅は駅構内を徒歩で移動することで他の路線に乗り換えることが出来ます。この__徒歩で移動できる範囲にある駅をひとまとまりのグループとして認識し、新たなノードとして他の路線に接続する__事により、はじめて鉄道__網__は文字通りグラフとなり、意味のある解析が行えます。この問題を解決するには、元になるグラフデータに対してもう一仕事必要です。幸運なことに、データを配布していらっしゃる方々はこの問題を認識しているようで、乗り換え可能な範囲にある駅を一つのグループとして、そのグループ情報をデータファイルに入れています。これを利用することにより、この問題は解決可能です。方法は以下の通りとなります:
- 駅グループ情報を利用して、グループ内ノードを新しいタイプ情報を持つエッジ(connected_with)でクリーク化
- 各クリークをCytoscapeのグループノードとしてひとまとまりの大きなノードとして表現する
これをPart2で行ってみたいと思います。
まとめ
私(バイオインフォマティクス系のソフトウェア開発者。いわゆる「データサイエンティスト」でなく、ただのプログラマです)にとっては全く触ったことのないタイプのデータセットでしたが、実は本業でも非常に似たものを扱っています。それは生化学的パスウェイと呼ばれるもので、生体内で起こっている代謝などの反応を、ユーザ(=生物学者)に分かりやすいように可視化したものです。以下はヒトの代謝経路の全体像をCytoscapeで可視化したものですが、まるで東京の路線図のようだと思いませんか?
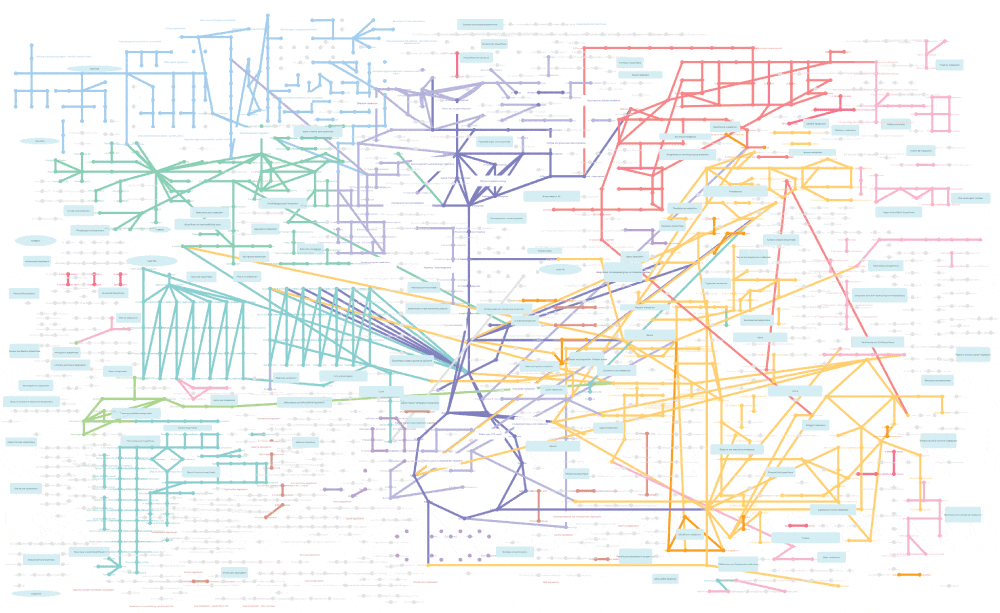
科学者は、こういった人類が今まで蓄積してきた生化学的反応に関する知識を可視化し、それに各種の実験で新たに得られた情報をマッピングして、さらなる知見を得ようとします。その__既存の可視化結果への新たなデータ追加とさらなる可視化__という作業のループは、科学研究に限らず、大量のデータが現れる様々な分野に応用可能なとても強力な手法です。
- 8/11/2014: この記事はまだドラフト段階です。後日詳細を更に追加する場合があります。
- 8/17/2014: Part 2へのリンクを追加。
- 9/8/2014: 第四回でひとまず完結しました。
第二回へ続く
Keiichiro Ono
Cytoscape Consortium
National Resource for Network Biology