はじめに
AIで手軽に遊べるデモサイトをFlaskで作りました。

スマホでも遊べるので、良かったら触ってみて下さい。
↓スマホでの表示
■デモサイト
AI World
■環境
Python, AWS(Lightsail), Flask, Docker
デモ一覧
デモの一覧は、以下の通りです。
| # | タイトル | 内容 | 利用モデル |
|---|---|---|---|
| 1 | Digit Recognition | 異常検知付き手書き文字認識 |
|
| 2 | Image Denoising | ノイズ画像のデノイズ |
|
| 3 | Face Generation | 存在しない人物の顔画像生成 |
|
| 4 | Face Transition | 存在しない人物の顔画像のトランジション |
|
| 5 | Face Manipulation | テキストでの顔画像編集 |
|
| 6 | Human Detection | 画像内の人物検出 |
|
| 7 | Object Detection | 画像内のオブジェクト検出 |
|
| 8 | Image Inpainting | 画像のマスク箇所の再構成 |
|
| 9 | Instance Segmentation | 画像内のオブジェクトのセグメンテーション |
|
以下、個別に簡単なデモで紹介して行きます。
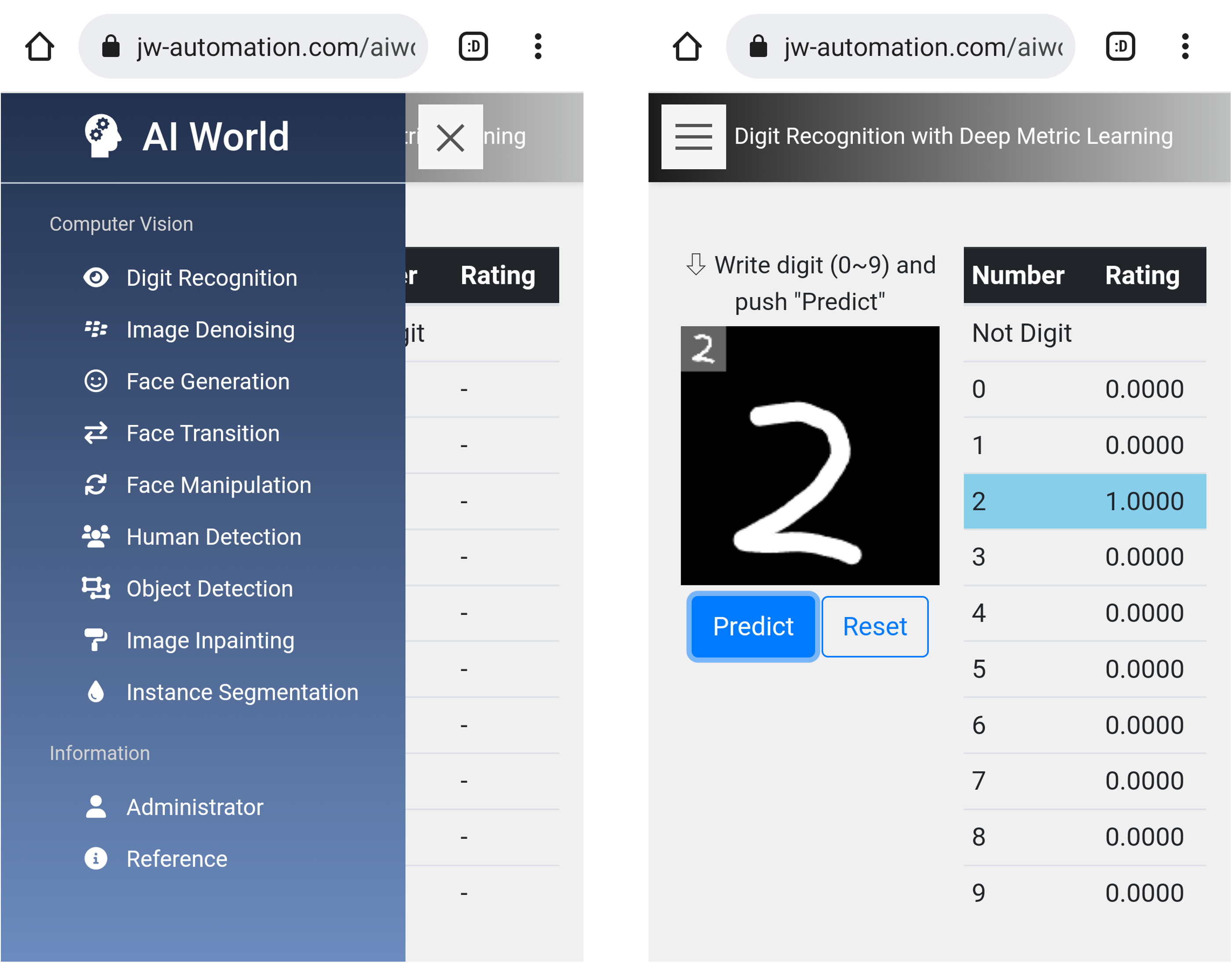
1. Digit Recognition
こちらは、「Deep Metric Learning」で以前紹介した、異常検知付きの手書き文字認識のデモです。
L2-constrained Softmax Lossを入れたCNNで、0~9までの文字を判定し、推定精度付きで返しています。全結合層の1つ前のL2-constrainedの層に、LOFで異常検知を入れているので、数字でないものが入力された場合は、「Not Digit」としてはじいています。
どちらかいうとスマホのほうが遊びやすいと思うので、色々な数字の形を書いたり、数字以外のものを書いてみたりと自由に遊んでみて下さい。
MNISTで学習しており、個人的にはもう少し弱い所のデータを足したいなという感触ですが、概ね人間と変わらないレベルで返してくれます。
2. Image Denoising
こちらも以前「Deep Learning for Image Denoising」で紹介した、ノイズ画像からのデノイズのデモです。

Win5-RBで、MNISTにガウシアンノイズを付加したノイズ画像5万枚と元画像で学習させており、ノイズ付きの新規画像(左)に対して、ノイズなし画像(右上)を推定します。
「Generate」ボタンでノイズ付きの新規画像が生成され、「Denoise」ボタンを押すと、右上にWin5-RBが推定したノイズなし画像、右下にノイズ付与前の元画像(正解画像)が表示されます。
正解画像と比較しても大差なく、上手くノイズ成分だけ除去してくれている事がわかります。
好きな数字とノイズの強度(noise intensity)も選べるので、こちらも自由に遊んでみて下さい。
3. Face Generation
こちらは、StyleGANを使った顔画像生成のデモです。

表示されている顔画像は全て、StyleGANが生成したもので、この世に存在しない人物になります。
「Other Face」ボタンを押すと、異なるseedとtruncation(-0.9~0.9)によって顔画像が返されるので、こちらも色々と試してみて下さい。
赤ん坊だったり、サングラスをかけた人も出てきます。
4. Face Transition
こちらもStyleGANを使ったもので、顔画像の遷移のデモになります。

seedを固定し、truncationを-0.7~0.7まで0.1ずつ動かす事で、徐々にStyleGANが生成する顔画像を遷移させています。
こちらも「Other Transition」で異なるseedでの顔画像の遷移が見れます。
どのseedにおいても、truncationが0となる真ん中のタイミングで、同じ顔(全ての本物画像を平均した顔)を通っている事がわかると思います。
性別や年齢も超えて、顔画像が遷移して行くのは面白いですね。
5. Face Manipulation
こちらはStyleCLIPを使った、テキストでの顔画像編集デモになります。
選択したテキストに合わせて、元画像をStyleCLIPで編集した結果が返されます。

今回用意したテキストは、以下の10種類です。
- 表情変化:smile, sad, angry
- 目の変化:close, blue, glasses
- 髪の変化:black, blond, curly, short, long
Global Directionsを使い、テキストからCLIPの埋め込み空間における変位を求め、テキストの変位分をStyleGANのスタイル空間における編集方向にマッピングすることで、テキストに合わせて顔画像が編集されます。
「Other Face」で、男性・女性・子供・老人など、StyleGANで生成された色々な顔が試せます。
今回はデモ用に任意で10種類選びましたが、笑った顔や怒った顔などを個別で学習している訳ではなく、テキストの変化と画像変化の対応自体が学習されているので、例えば、「ヒゲあり」「ボブカット」「眼鏡なし」など、入力するテキストを変えれば自由に編集できます。
6. Human Detection
こちらはYOLOを使った、人検出のデモです。
YOLOの検出対象を人だけに絞っており、「Detection」を押すと、人の領域のバウンディングボックス(矩形領域)が返されます。

シルエットやイラストでも検出可能で、10パターン程用意しているので、こちらも遊んでみて下さい。
7. Object Detection
こちらも同じくYOLOを使ったデモですが、今回は人に限らず、様々なオブジェクトを検出します。

人に限らず、動物やスマホ、ネクタイなども検出可能なので、こちらも遊んでみて下さい。
8. Image Inpainting
こちらは以前、「Deep Learning For Image Inpainting」で紹介した、画像再構成のデモです。

DeepFill v2によって、元画像に対して白抜きのマスクをかけた箇所が、周辺領域を元に再構成されます。周辺領域から再構成される特性を活かし、オブジェクトにマスクを重ねる事で、消しゴムのようにオブジェクトを自然に消したり、逆に破損個所を綺麗に修復したりする事ができます。
9. Instance Segmentation
こちらはインスタンスセグメンテーションのデモです。

YOLOはバウンディングボックスの検出まででしたが、こちらはSOLOによって、バウンディングボックスの中のオブジェクトの領域まで抽出しています。
インスタンスセグメンテーションのため、個々のオブジェクトのIDが取れるので、特定のオブジェクトだけ操作したり(インペインティングで消したり)、色々と遊べそうですね。
まとめ
一旦全てAIモデルをデプロイしたのですが、GAN系とDeepFillv2, SOLOはデモサイトにしてはレスポンスが遅くなってしまったため、デプロイは見送りました。
これらのデモについては、Colabで実装した際の結果を画像で返す形にしています。DeepMetricLearningとDenoising, Human/Object Detectionについてはリアルタイムでモデルを動かしています。
普段Colabの恩恵を受けすぎているので、デプロイになると、AIモデルやライブラリがどんどん重くなっている事や、GPUサーバーも個人利用にしてはまだまだ高いなと改めて痛感しますね。
とはいえ、もっとインタラクティブに遊べるものを今後増やして行きたいので、どこかでGPU環境に載せ変えたいと思います。
■参考
Qiita記載記事
・Deep Metric Learning
・Deep Learning for Image Denoising
・ホテル暮らしはクラウドである
・AIの実業務適用に必須なHITLという考え方と、HITLを加速させるAI×RPA
・RPAの推進に必須なRPAOpsという考え方
・VBAが組める人ならRPAは簡単に作れるという罠
個人ブログ
・キャリア・フレームワークなど