概要
以下記事に沿ってPIIデータの削除にトライしました。
元々は非構造化テキストデータ内のPIIを除去する目的に使用される想定かと思いますが、今回はcsvファイルでも動くかどうか検証したいと思います。
尚、テストデータの作成にはUser Localさんの個人情報テストジェネレータを使って出力したcsvファイルを使用します。
以下の手順で DefaultLanguageCode を ja に設定している箇所がございますが、Amazon Comprehend の PII検知のサポート対象は「en」のみとなります。(2022/12/2 時点)
検証開始時に気づかず興味本位で設定変更した結果、S3 Object lambdaがエラーを返す結果となりました。本記事では敢えて失敗の過程も晒しますので、反面教師にして頂ければと思います。
手順
1. S3バケットの作成
- バケット名、任意のリージョンを選択
- その他はデフォルトのまま作成
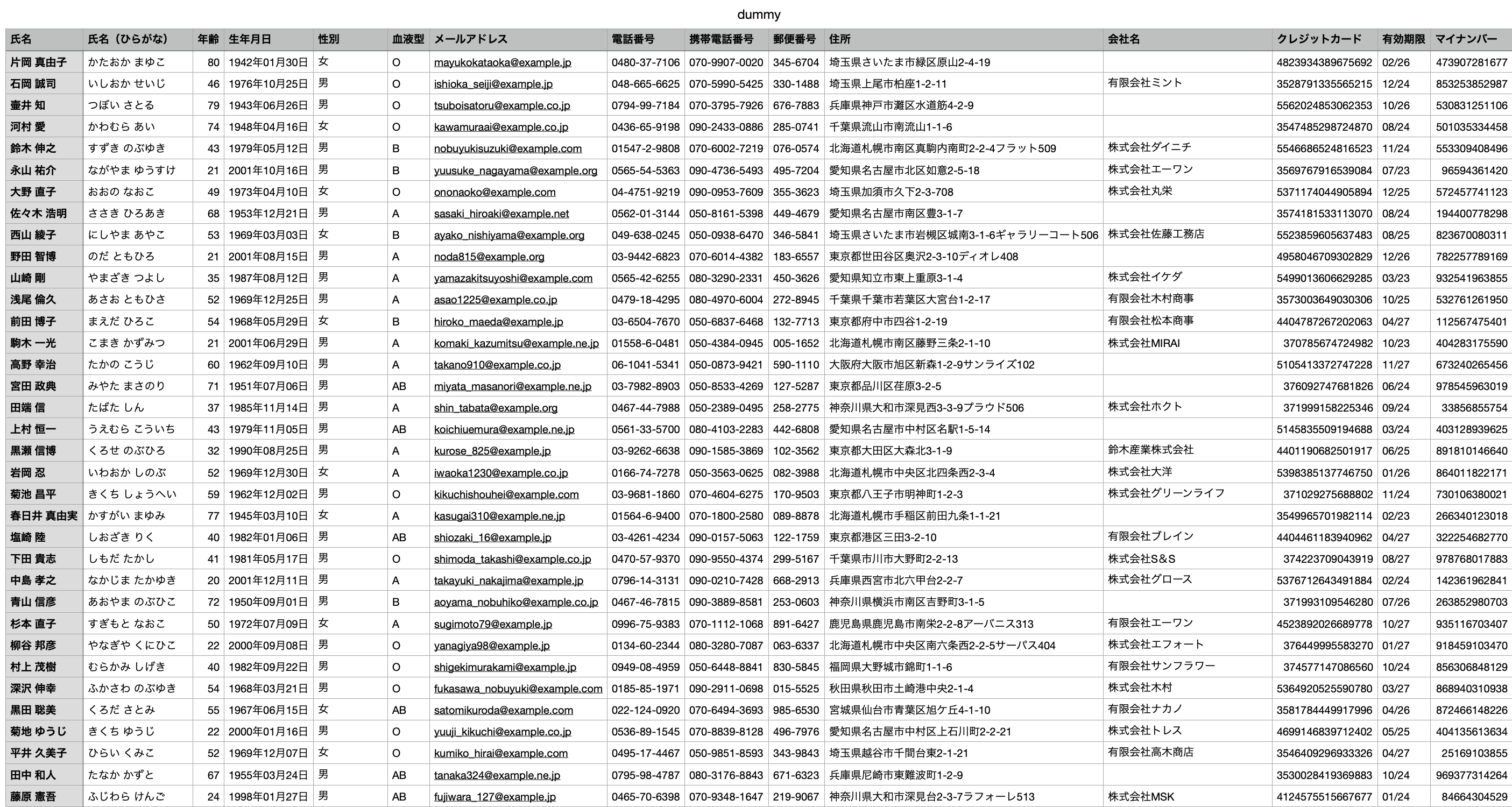
2. S3 バケットにファイルをアップロード
今回用意したcsvファイル
3. S3 アクセスポイントの作成
S3コンソールで、アクセスポイント -> アクセスポイントの作成
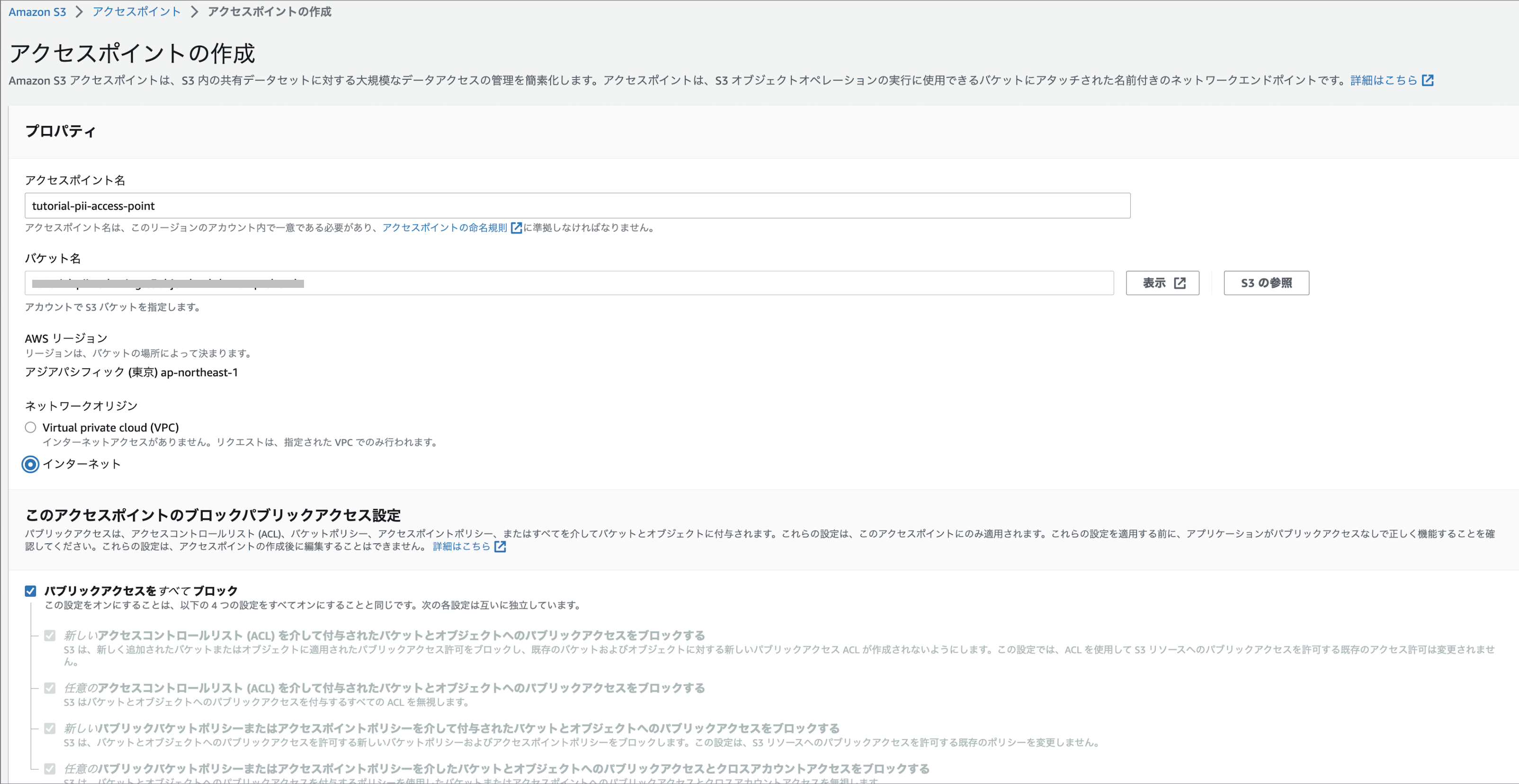
アクセスポイン名設定、1 で作成したバケットの名前を入力、[ネットワークオリジン] で、[インターネット] を選択
その他はデフォルトのままアクセスポイントを作成
4. 事前構築された Lambda 関数の設定とデプロイ
AWS Management Console にサインインし、AWS Serverless Application Repository でComprehendPiiRedactionS3ObjectLambda 関数を表示します。
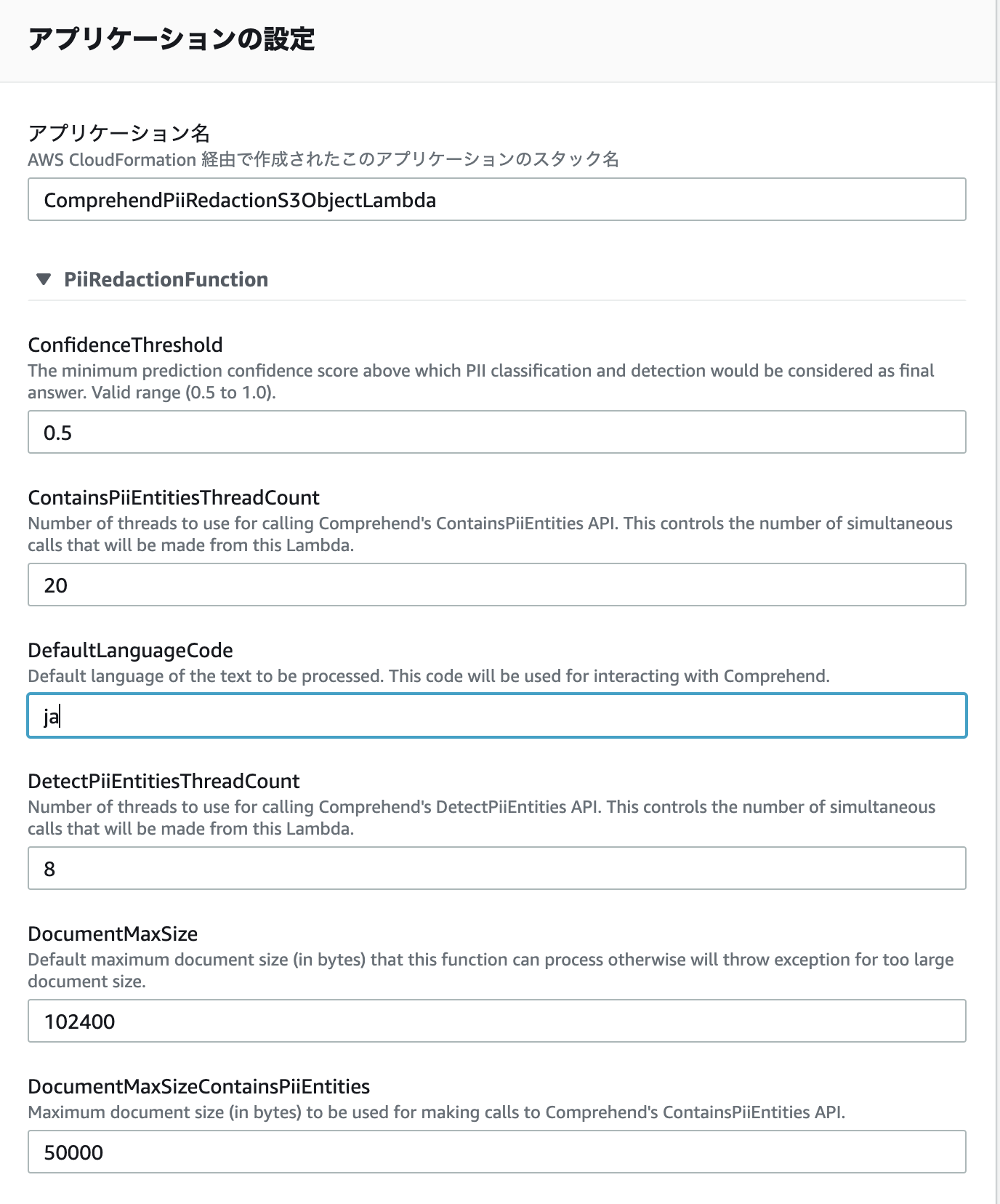
DefaultLanguageCodeを ja に設定してみる。
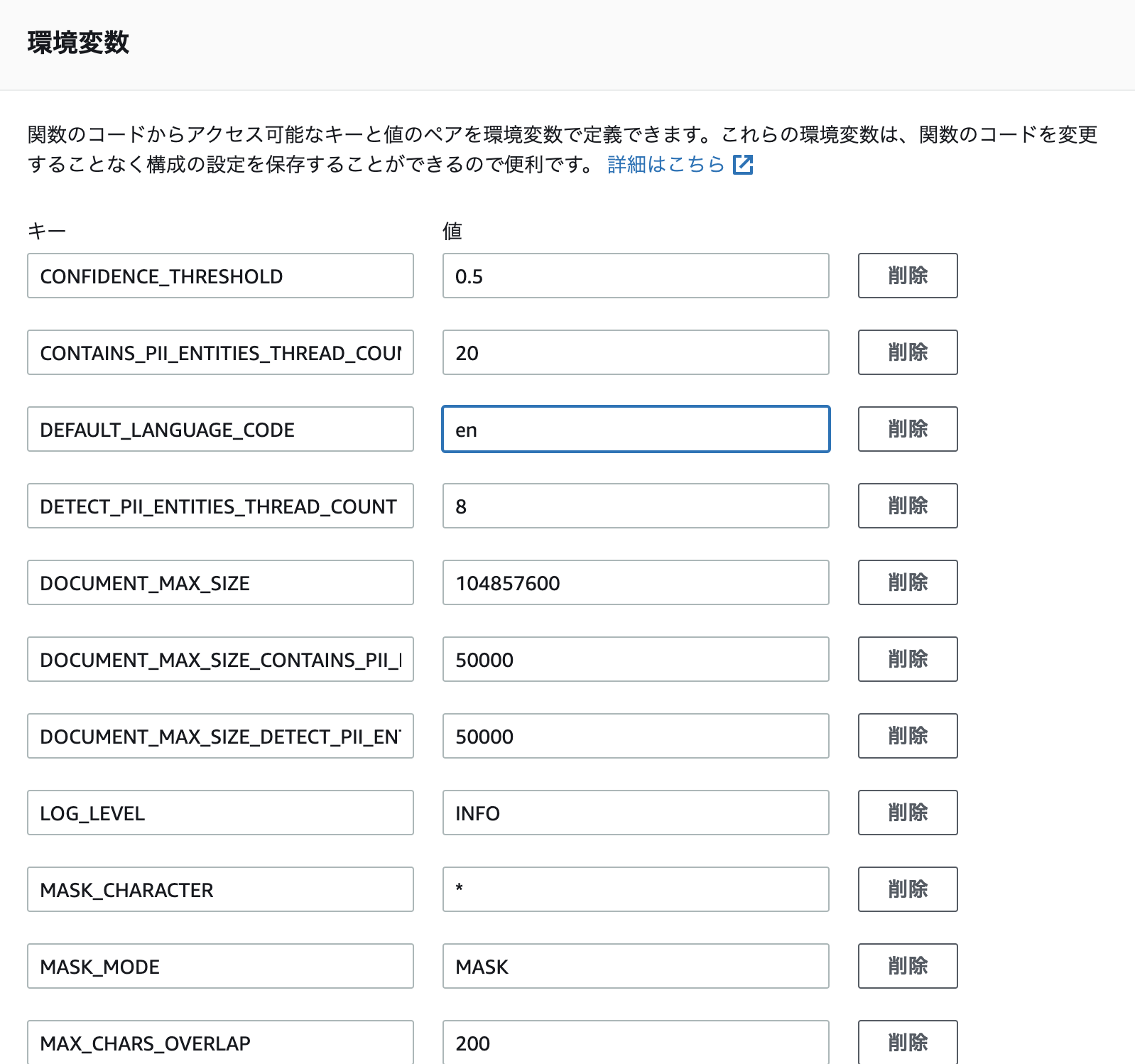
冒頭述べた通り ja だと失敗するので、en を指定して下さい。
それ以外はデフォルトのまま、「このアプリがカスタム IAM ロールを作成することを承認します。」にチェックを入れてデプロイ。

ステップ 5. S3 Object Lambda アクセスポイントの作成
S3コンソールから、Object Lambda アクセスポイント -> Object Lambda アクセスポイントの作成 を選択。
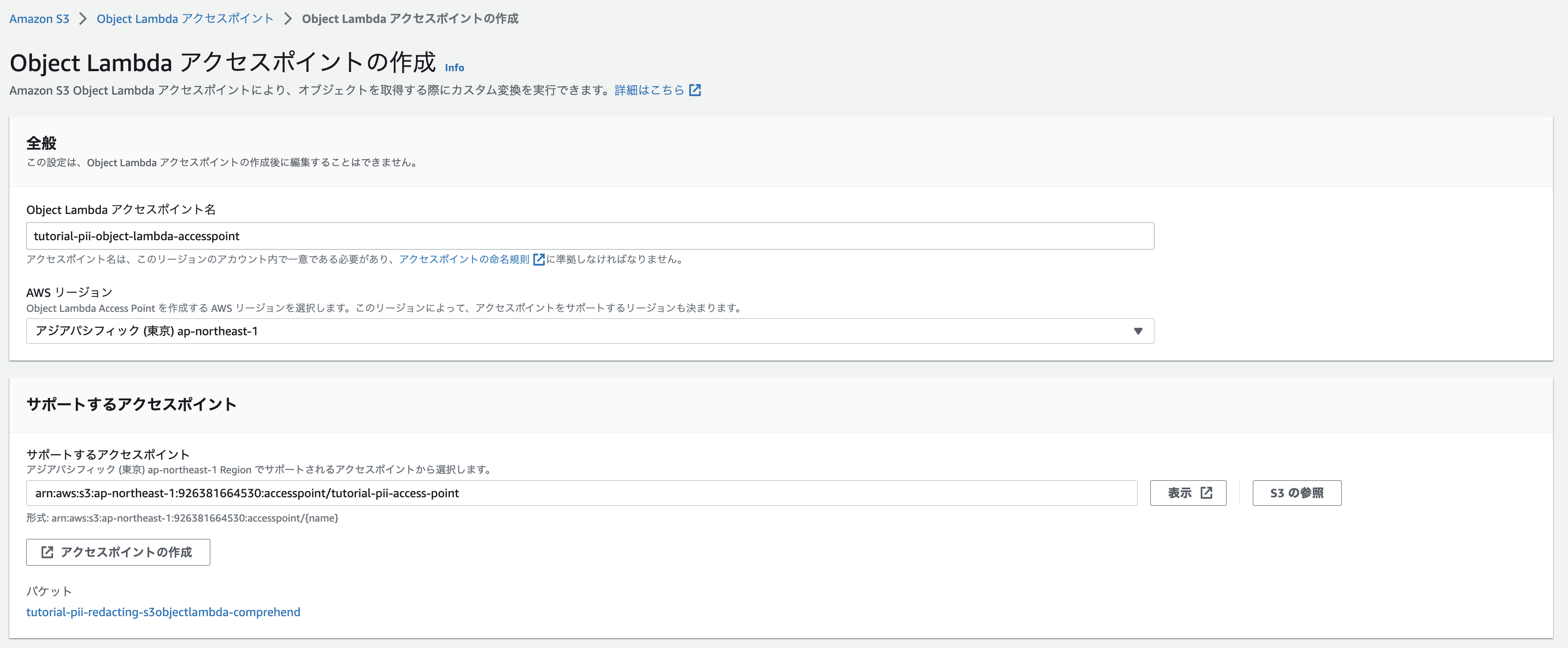
アクセスポイント名を指定し、ステップ 3 で作成した標準アクセスポイントを入力または参照。
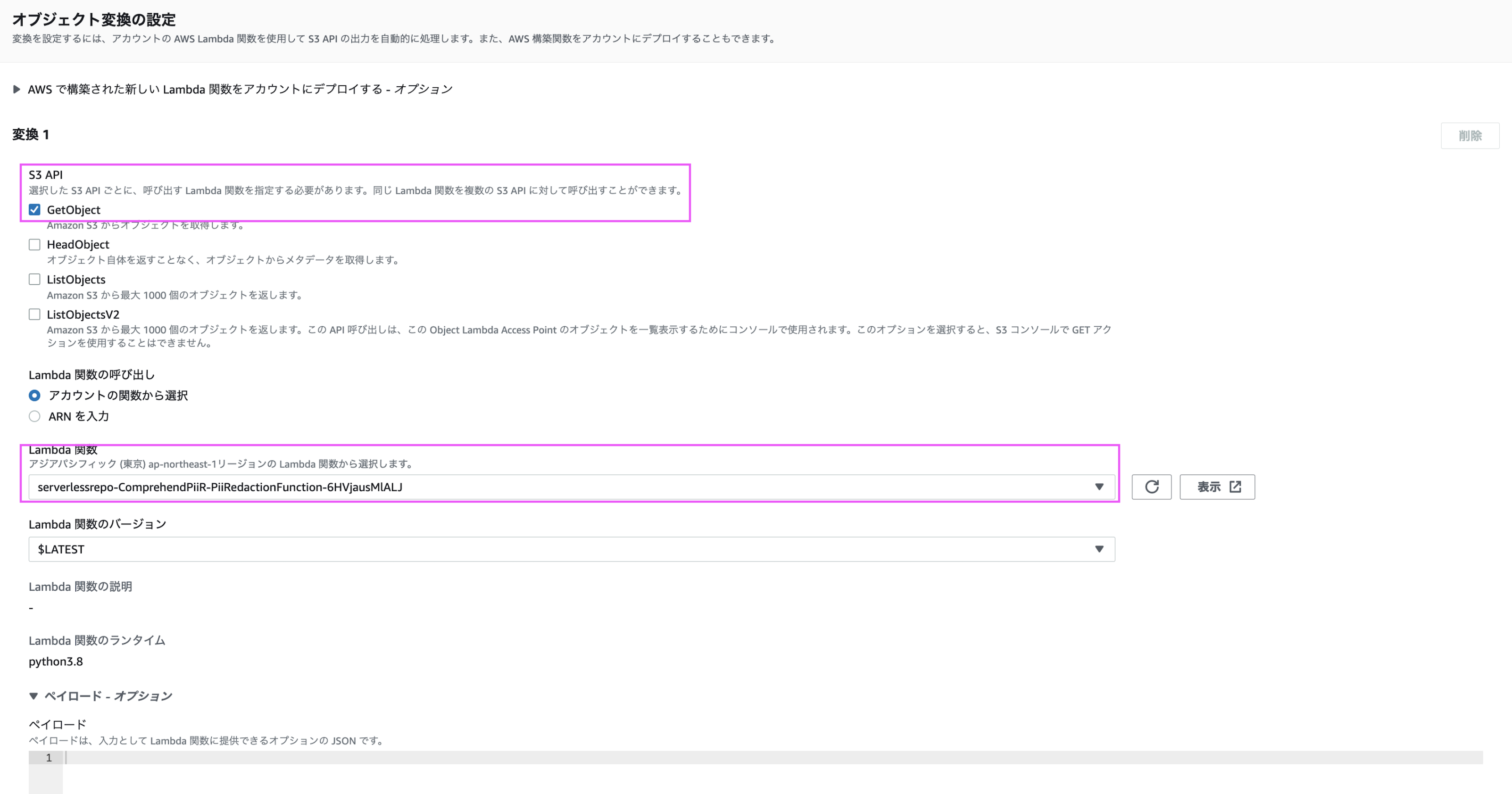
- S3 APIは「GetObject」を選択
- Lambda 関数はステップ 4 でデプロイした Lambda 関数を選択
- それ以外はデフォルトで[Object Lambda アクセスポイントの作成] を選択
ステップ 6 S3 Object Lambda アクセスポイントを使用して、編集されたファイルを取得する
S3 Object Lambda アクセスポイントを使用して、編集されたファイルを取得するには
S3 Object Lambda アクセスポイントを使用してファイルの取得をリクエストすると、S3 Object Lambda への GetObject > API 呼び出しが行われます。S3 Object Lambda は Lambda 関数を呼び出して PII データを変換し、変換されたデータを標準 S3 GetObject API への応答として返します。
とのことなので、後は S3 Object Lambda アクセスポイントにアクセスすると、デプロイされた S3 Object Lambda が実行され、PIIデータにマスクが掛かった状態で出力されるはずです。
S3 コンソールの左のナビゲーションペインで、[Object Lambda アクセスポイント] を選択します。
早速、dummy.csv を DL してみます。
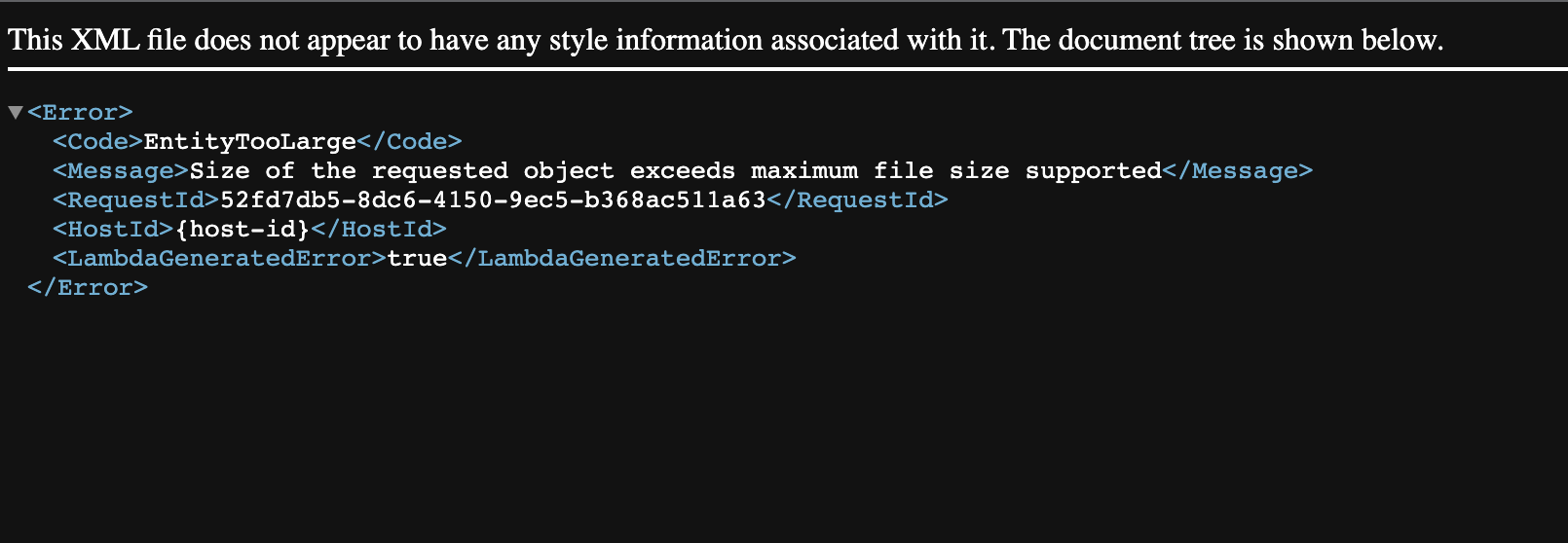
容量オーバーでDLできず。lambda の環境設定で環境変数をチューニングします。
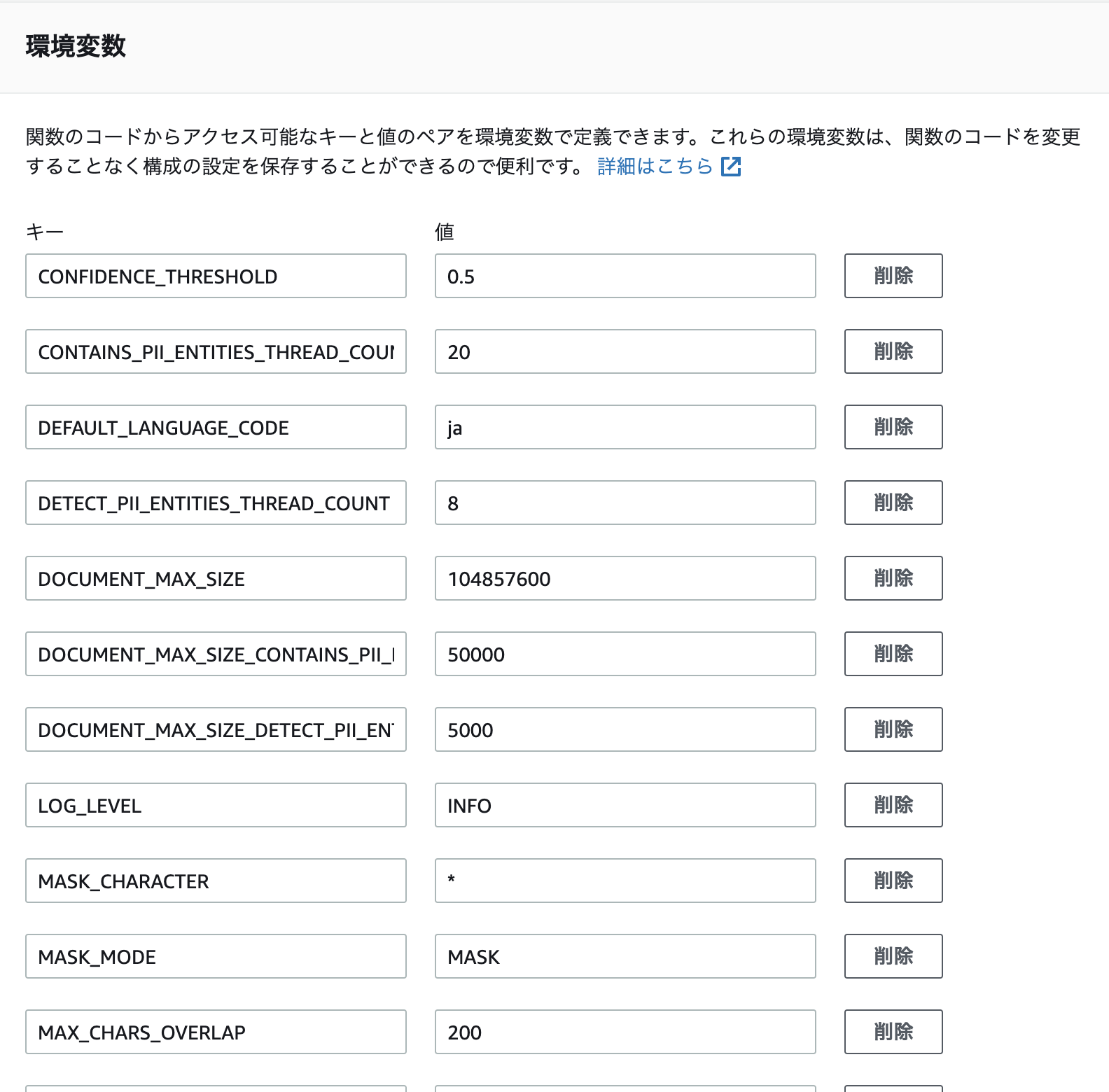
DocumentMaxSizeを100MBに設定。
再度、トライするも、今度はInternal Errorが発生。
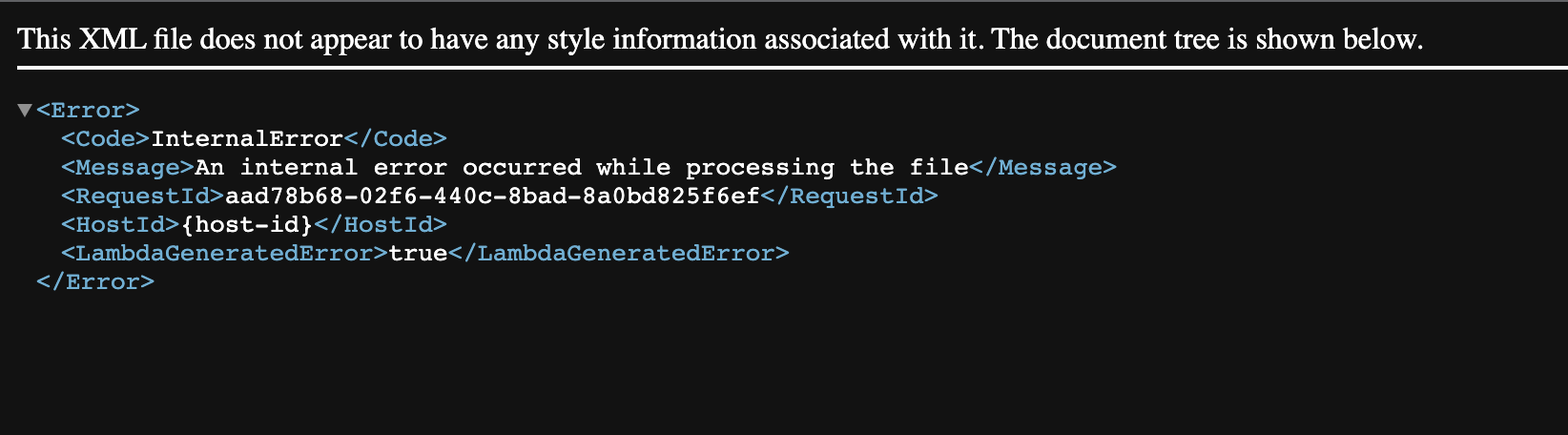
やはり「DefaultLanguageCode が ja では動かないので、素直に en に戻す。( すみません。最初からちゃんとドキュメントチェックしておくべきでした。)

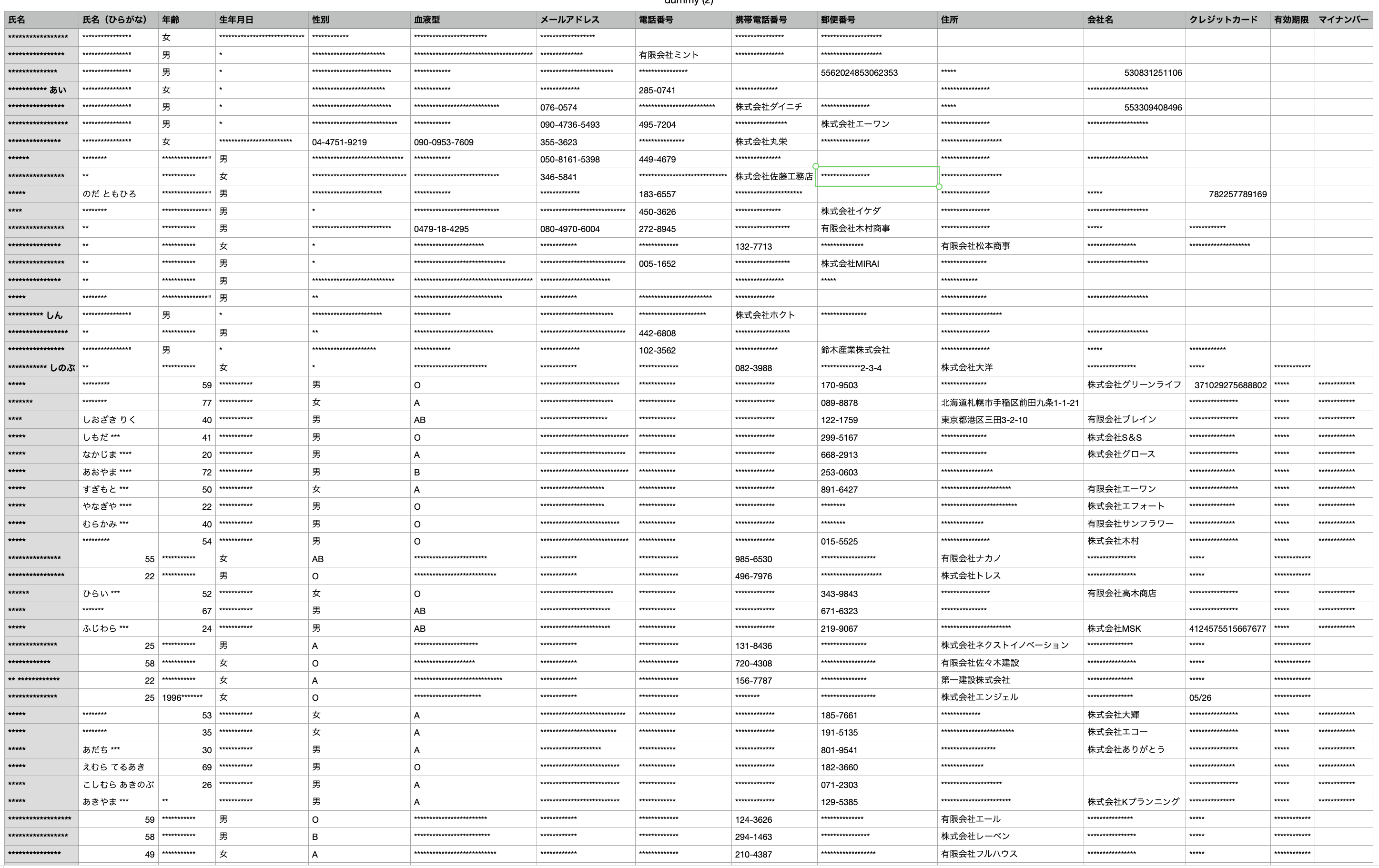
出力結果
無事に出力はされましたが、以下のような問題が発生しました。
- csvのフォーマットが崩れる
- マスクが掛かる箇所がバラバラ (メールアドレスとマイナンバーあたりは上手くマスクできていそう?)
結論
- 構造化データのPIIデータ削除目的でデータ加工パイプラインに組み込むのは非現実的
- アプリケーションのバックエンドとしての利用が想定される。
- CS部門のお客様とのやりとりを管理するシステムにおいて、CS担当以外のロールで閲覧する際にPIIが削除された状態で閲覧できるみたいなシステムを作る時に便利かも。(ComprehendのPIIエンティティー検出機能が日本語対応するのであればの話。)
以上、ここまでご覧頂き、ありがとうございました。