Flickrの利用方法
Flickr APIよりkeyを取得する
まずFlickrのページへいきRequest an API Keyをクリックする。ここでFlickrのアカウントを作成していない場合は作成しログインしておく。
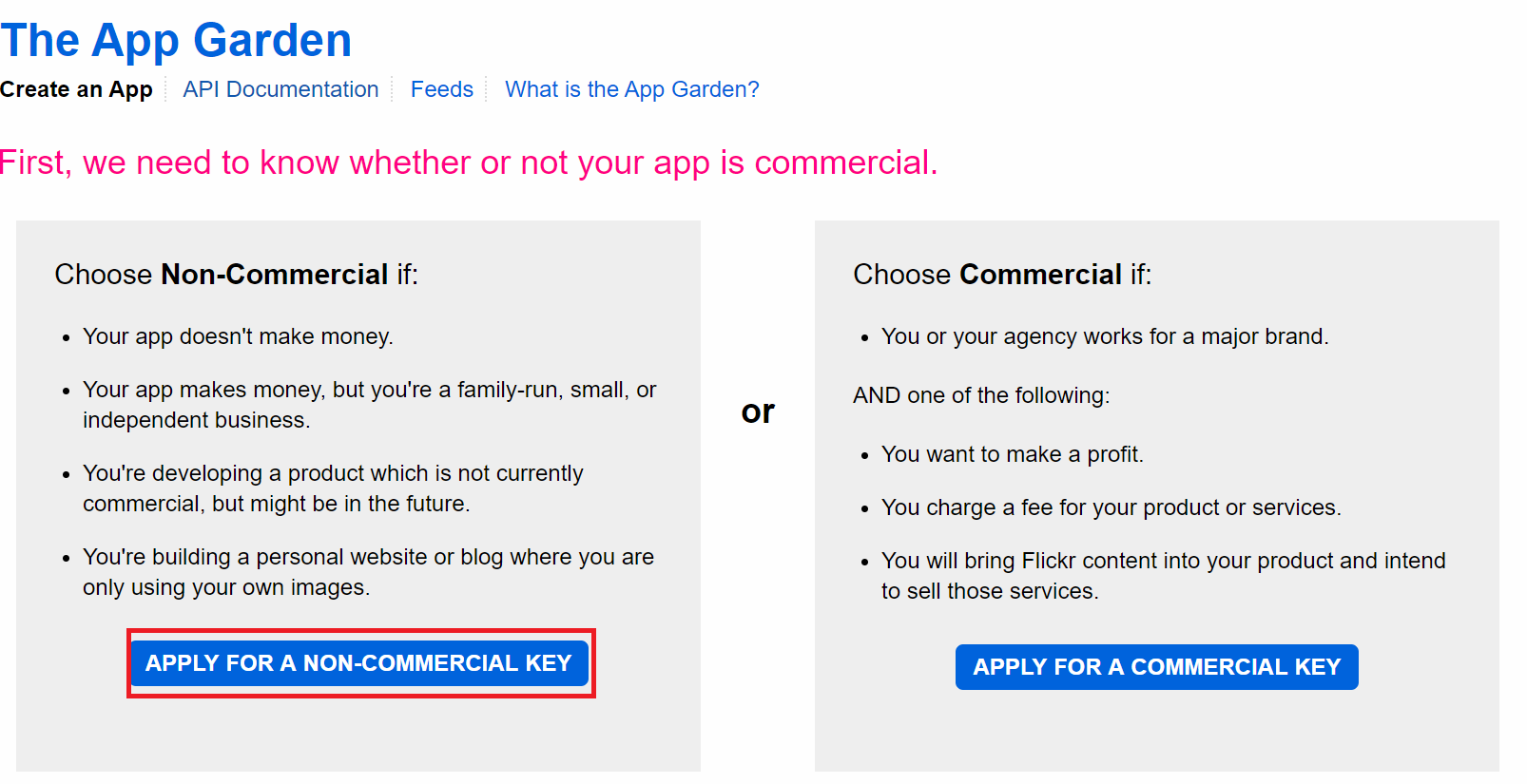
左側が無償(非商法)、右側が有償(商法)用なので、赤線で囲んであるAPPLY FOR A NON-COMMERICIAL KEYを選択する。
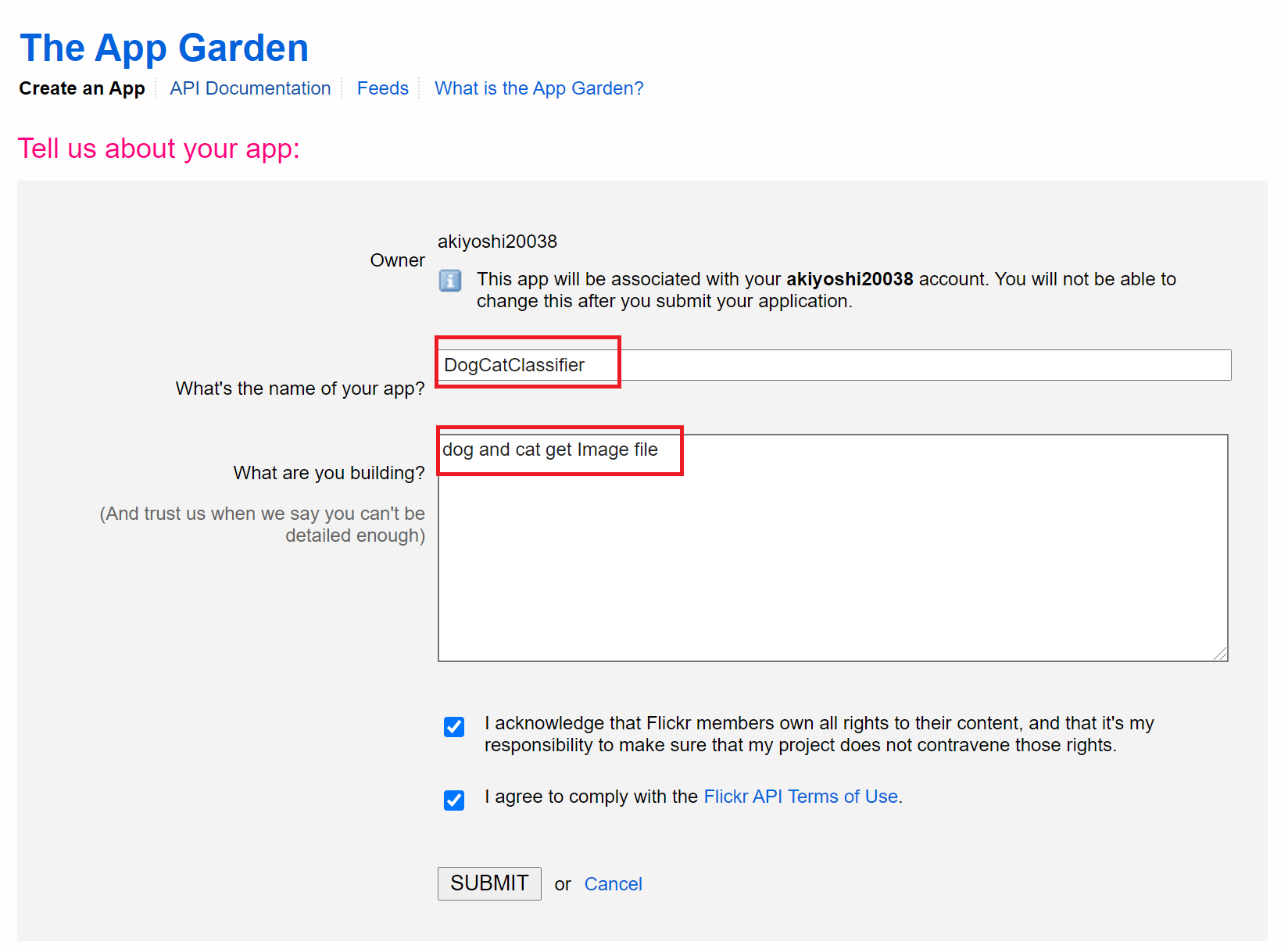
するとアプリケーションの登録画面が表示されるのでアプリケーションに使用する名前と使用用途を記載し、SUBMITをクリックする。
登録後、key と Secret が取得できるのでメモ帳などに控えておく。
Flickr APIから画像を取得するプログラムを作成する
以下のコマンドよりFlickrのモジュールをインストールする。
pip install flickrapi
プログラム実行前に、取得した画像を保存するフォルダを作成する。
download.py
from flickrapi import FlickrAPI
from urllib.request import urlretrieve
from pprint import pprint
import os,time,sys
key = "取得したkey"
secret = "取得したSecret"
wait_time = 1
# コマンドラインの引数の1番目の値を取得。以下の場合は[cat]を取得
# python download.py cat
animalname = sys.argv[1]
savedir = "./"+animalname
# format:受け取るデータ(jsonで受け取る)
flickr = FlickrAPI(key, secret, format='parsed-json')
"""
text : 検索キーワード
per_page : 取得したいデータの件数
media : 検索するデータの種類
sort : データの並び
safe_seach : UIコンテンツの表示有無
extras : 取得したいオプションの値(url_q 画像のアドレス情報)
"""
result = flickr.photos.search(
text = animalname,
per_page = 400,
media = 'photos',
sort = 'relevance',
safe_seach = 1,
extras = 'url_q, licence'
)
# 結果
photos = result['photos']
pprint(photos)
上記のプログラムを実行し、成功すると以下の表示がされる。
{'farm': 5,
'height_q': 150,
'id': '4375810205',
'isfamily': 0,
'isfriend': 0,
'ispublic': 1,
'owner': '47750313@N07',
'secret': '8d0a7d24a1',
'server': '4008',
'title': 'cat',
'url_q': 'https://live.staticflickr.com/4008/4375810205_8d0a7d24a1_q.jpg',
'width_q': 150},
{'farm': 1,
'height_q': 150,
'id': '27083352608',
'isfamily': 0,
'isfriend': 0,
'ispublic': 1,
'owner': '144380504@N04',
'secret': 'd1cd159107',
'server': '811',
'title': 'cat',
'url_q': 'https://live.staticflickr.com/811/27083352608_d1cd159107_q.jpg',
'width_q': 150}],
'url_q'に登録されているURLを取得し、urllibを使用して画像データを取得する。
さきほどのプログラムに画像データを取得するプログラムを追加する。
for i,photo in enumerate(photos['photo']):
url_q = photo['url_q']
filepath = savedir + '/' + photo['id'] + '.jpg'
# 重複したファイルが存在する場合スキップする。
if os.path.exists(filepath):continue
# 画像データをダウンロードする
urlretrieve(url_q, filepath)
# サーバーに負荷がかからないよう、1秒待機する
time.sleep(wait_time)
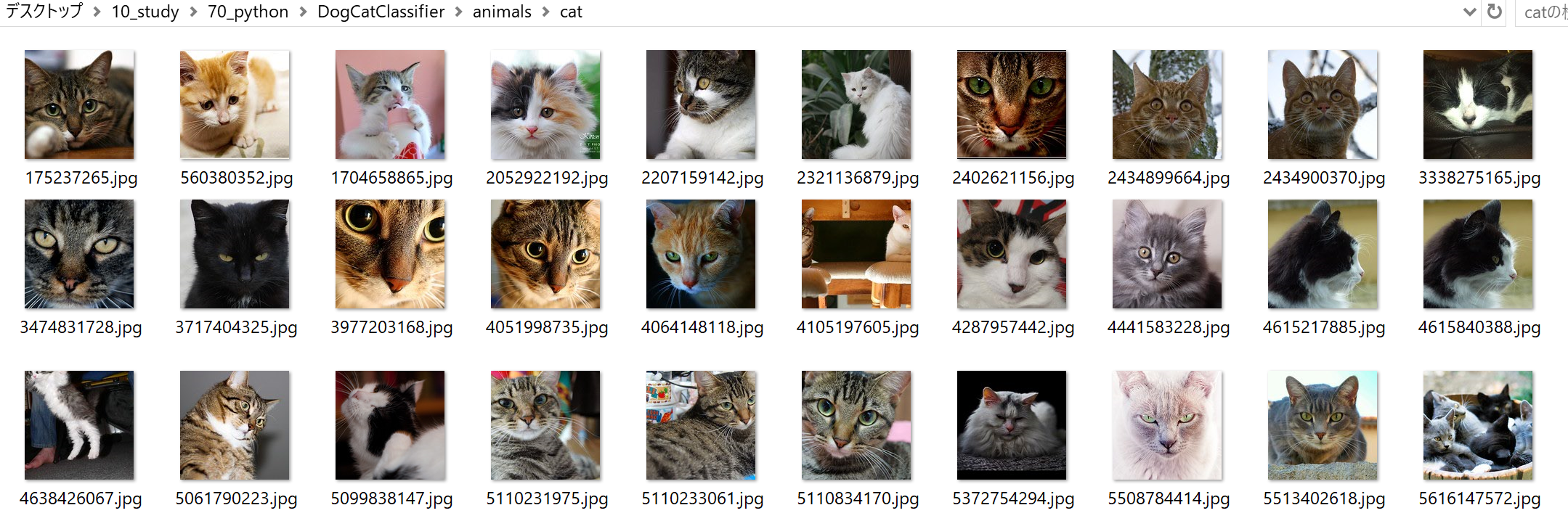
「cat」を引数にプログラム実行後、猫の画像がFlickrから取得できた。