背景・目的
最近、「【Databricks】Lakehouse Monitoringを試してみた」や、「【Databricks】Monitor alerts」などにあるように、データ品質について触れる機会が何かと多く、Modern Data Stackでいうとどのような定義か、どのような製品が存在するかを調べてみたいと思います。
まとめ
下記の特徴があります。
| 項目 | 特徴 |
|---|---|
| 概要 | データの健全性チェックするプロセス DevOps Observabilityのベストプラクティスをデータパイプラインに適用している。 目的は、データのダウンタイムを排除すること システム内のデータの健全性を理解する組織のCapability |
| データ品質に関するよくある質問 | ダッシュボードはどうなった? 数値や計算がおかしい 誰が更新したのか? パイプラインが壊れたのはなぜか? データが見えない |
| 5つの柱 | ・Data Observability ・Distribution ・Volume ・Schema ・Lineage |
| テストとの棲み分け | データテストは、静的テスト パイプラインの破損はデータテストだけでは防げない データインフラ全体でデータの監視と Observability により、完全なデータの信頼性を実現する |
| Data Observabilityのサイクル | DevOpsのベストプラクティスをデータパイプラインに適用することでデータのダウンタイムを排除する。 ・データ品質の問題を最初にする。 ・問題の影響がわかる ・データがどこで壊れたか理解できる ・問題を解決するための措置を講じる ・各種情報(資産、使用状況、アクセシビリティ、信頼性)を元に、学習する |
Data Observabilityの代表的な製品
・PipeRider
・Validio
・Sifflet
・Great Expectations
・Monte Carlo Data
・Elementary Data
・Metaplane
概要
moderndatastack.xyzのData Quality Monitoringを元に整理します。
データ品質監視は、組織がシステム内のデータの健全性をチェックし続けるために使用するプロセスであり、DevOps 可観測性のベスト プラクティスをデータ パイプラインに適用することでデータのダウンタイムを排除します。
- データの健全性チェックするプロセス
- DevOps Observabilityのベストプラクティスをデータパイプラインに適用している。
- 目的は、データのダウンタイムを排除すること
What is data observability?
開発者運用 (愛情を込めて DevOps と呼ばれます) チームは、ほとんどのエンジニアリング組織にとって不可欠なコンポーネントとなっています。DevOps チームは、ソフトウェア開発者と IT 部門間のサイロを排除し、ソフトウェアの実稼働環境へのシームレスかつ信頼性の高いリリースを促進します。
- DevOpsは、部門間のサイロを排除する
- ソフトウェアの実稼働環境へのシームレスかつ信頼性の高いリリースを促進する
組織が成長し、組織を支える基盤となる技術スタックがより複雑になるにつれて (モノリスからマイクロサービス アーキテクチャへの移行を考えてください)、DevOps チームにとってシステムの健全性を常に維持することが重要です。可観測性はこのニーズを表しており、ダウンタイムを防ぐためのインシデントの監視、追跡、およびトリアージを指します。
- 技術スタックが複雑になり、システムの健全性を常に維持する事が重要
- Observabilityは、ダウンタイムを防ぐためのインシデントの監視、追跡、トリアージを指す。
データ システムがますます複雑になり、企業が取り込むデータが増えるにつれ、データ チームは、根本原因を監視し、警告し、「データ ダウンタイム」(言い換えれば、一定期間)を防ぐための総合的なエンドツーエンドの方法も必要としています。データが欠落している、不正確である、古い、またはその他の間違いがある場合)下流のデータ消費者に影響を与えないようにします。
- データシステムの世界でも同様に、Observabilityの考え方が必要。
データ可観測性とは、システム内のデータの健全性を完全に理解する組織の能力であり、DevOps 可観測性のベスト プラクティスをデータ パイプラインに適用することでデータのダウンタイムを排除します。DevOps の対応物と同様に、データ オブザーバビリティでは、自動化された監視、アラート、トリアージを使用してデータの品質と発見可能性の問題を特定および評価し、パイプラインの健全性とデータ チームの生産性の向上につながります。
- Data Observabilityとは、システム内のデータの健全性を理解する組織のCapability
- DevOpsのObservabilityのべスプラをデータパイプラインに適用している。
- データのダウンタイムを排除する。
- 自動化された監視、アラート、トリアージを使用する
- データ品質と発見、問題の特定および評価する。
- パイプラインの健全性とデータチーム生産性の向上につながる
What does data observability look like in practice?
アプリケーションの可観測性の 3 つの柱 (メトリクス、トレース、ログ) と同様に、データの可観測性はデータの健全性の 5 つの主要な柱にわたって測定できます。データの可観測性の 5 つの柱は、鮮度、分布、ボリューム、スキーマ、系統です。これらのコンポーネントを組み合わせることで、データの品質と信頼性に関する貴重な洞察が得られます。
- アプリケーションでは、3つのObservability が柱
- メトリクス
- トレース
- ログ
- Data Observability は5つの主要な柱で測定する
- Freshness
Freshness は、データ テーブルがどの程度最新であるか、およびテーブルが更新される頻度を理解しようとします。意思決定に関しては、鮮度が特に重要です。結局のところ、古いデータは基本的に時間とお金の無駄と同義です。
- Freshnessは最新性、頻度から健全性を測る
- 古いデータは価値がない。金と時間の無駄
- Distribution
分布、つまりデータの取り得る値の関数により、データが許容範囲内にあるかどうかがわかります。データの分散により、データから期待される内容に基づいてテーブルが信頼できるかどうかを判断できます。
- Distributionは、値の許容範囲かわかる
- 分散されているデータから健全性を測る
- Volume
ボリュームはデータ テーブルの完全性を指し、データ ソースの健全性に関する洞察を提供します。2 億行が突然 500 万行に変わったら、それを知っておく必要があります。
- Volumeは、データのレコード・サイズから健全性を測る
- Schema
データの構成、つまりスキーマの変更は、多くの場合、データの破損を示します。これらのテーブルに誰がいつ変更を加えたかを監視することは、データ エコシステムの健全性を理解するための基礎となります。
- スキーマの変更によりデータの破損につながる。
- テーブルの変更に対して、いつどのように変更を加えたか監視する。
- Schemaの変更を観測することで、健全性を測る
- Lineage
データが壊れたとき、最初の質問は常に「どこですか?」です。データ リネージは、影響を受けた上流のソースと下流の取り込み者、さらにどのチームがデータを生成しているか、誰がデータにアクセスしているかを示すことで答えを提供します。また、Good Lineage は、特定のデータ テーブルに関連付けられたガバナンス、ビジネス、および技術ガイドラインに関わるデータ (メタデータとも呼ばれる) に関する情報を収集し、すべての消費者にとって唯一の信頼できる情報源として機能します。
- どこでデータが壊れたかわかる。
Why do data teams need observability? Isn’t testing sufficient?
データ テストは、パイプラインのさまざまな段階でデータに関する仮定を検証するプロセスです。基本的なデータ テスト方法には、固定データを使用したスキーマ テストやカスタム データ テストが含まれます。これは、ETL がスムーズに実行されることを確認し、少数の既知のシナリオでコードが正しく動作することを確認し、コード変更時の回帰を防ぐのに役立ちます。
データ テストは、NULL 値、一意性、参照整合性、その他のデータの問題の一般的な指標について静的テストを実行することで役立ちます。これらのツールを使用すると、手動のしきい値を設定し、パイプラインの実行ごとに保持する必要があるデータに関する基本的な前提条件の知識をエンコードできます。
- データテストは、パイプラインの様々な段階でデータに関する仮定を検証するプロセス
- 基本的なデータテスト方法には、固定データを使用したスキーマテスト、カスタムデータテストが含まれる。
- データテストは、下記について実行する
- NULL
- 一意性
- 参照整合性など
しかし、単体テストだけではソフトウェアの信頼性を確保するには不十分であるのと同様に、データ テストだけではデータ パイプラインの破損を防ぐことはできません。分析を実行する前にデータ パイプラインの問題を見つけるためにデータ テストに依存することは、新しいソフトウェアをデプロイする前にバグのあるコードを特定するために単体テストと統合テストを信頼することと同じですが、最新のデータ環境では不十分です。コードベース全体にわたるアプリケーションの監視と可観測性がなければ、真に信頼性の高いソフトウェアを実現できないのと同じように、データ インフラストラクチャ全体にわたるデータの監視と可観測性がなければ、完全なデータの信頼性を実現することはできません。
- パイプラインの破損はデータテストだけでは防げない
- データインフラ全体でデータの監視と Observability により、完全なデータの信頼性を実現する
最良のデータ チームは、テストのみに依存するのではなく、データ テストとパイプライン全体にわたる継続的な監視および可観測性を組み合わせた 2 つのアプローチを活用しています。最新のデータ チームが両方を必要とする理由は次のとおりです。
- テストのみに依存しない。
- データテストとパイプライン全体の継続的な監視および Observability の2つのアプローチを組み合わせている。
- データは大きく変更されます。テストによって多くの問題を検出して防ぐことができますが、データ エンジニアやアナリストが開発中に発生するすべての事態を予測できる可能性は低く、たとえ予測できたとしても、膨大な時間とエネルギーが必要になります。ある意味、データは従来のソフトウェアよりもテストがさらに困難です。中程度のサイズのデータセットであっても、その変動性と複雑さは膨大です。事態をさらに複雑にしているのは、データが「外部」ソースから取得されることが多く、予告なく変更される可能性があることです。一部のデータ チームは、規模やコンプライアンスの制限を考慮すると、開発やテストの目的で簡単に使用できる代表的なデータセットを見つけることさえ困難になります。可観測性は、パイプラインに対する避けられない、そして潜在的に問題となる可能性のある変更に対する可視性の追加レイヤーを提供することで、これらのギャップを埋めます。
- すべて予測するのは不可能
- 予告なく変更される
- パイプラインに対する避けられない、潜在的に問題となる可能性のある変更に対する可視性の追加レイヤーを提供する
- エンドツーエンドのカバレッジが重要です。多くのデータ チームにとって、堅牢でカバレッジの高いテスト スイートの作成は非常に手間がかかり、多くの場合、特に未カバーのパイプラインがすでに存在する場合には、不可能または望ましくない場合があります。データ テストは小規模なパイプラインでは機能しますが、最新のデータ スタック全体ではうまく拡張できません。最新のデータ環境のほとんどは信じられないほど複雑で、データは数十のソースからデータ ウェアハウスまたはレイクに流れ、その後、エンド ユーザーが使用するために BI/ML に伝播されたり、サービスを提供するために他の運用データベースに伝播されたりします。ソースから消費されるまでの過程で、データはかなりの数の変換 (場合によっては数百に及ぶ) を経ます。データ可観測性はこれらの「未知の未知」をカバーします
- E2Eのカバレッジが重要
- データテストではすべてを拾えない。
- データテストの負債。私たちは皆、優れたテスト範囲を整備することを望んでいますが、データ チームはパイプラインの一部がカバーされていないことに気づくでしょう。パイプライン開発の初期段階では信頼性が優先されることが多いため、多くのデータ チームにとって、カバレッジはまったく存在しません。既存のパイプラインに関する重要な知識がデータ チームの少数の選ばれた (そして多くの場合非常に初期の) メンバーにある場合、テストの負債に遡って対処することで、せいぜい、他の方法でデータ チームを動かすプロジェクトに費やすことができたリソースとエネルギーを転用することができます。あなたのチームのための針。最悪の場合、チームの初期メンバーの多くがもう会社を離れ、ドキュメントが最新でない場合、テスト負債を修正することはほぼ不可能になります。ML ベースの可観測性は、過去のデータから学習し、新しい受信データを監視します。チームは、投資や事前知識をほとんどまたはまったく使わずに、既存のパイプラインの可視性を作成できるほか、テストの負担を軽減するためにデータ エンジニアやアナリストの負担を軽減できます。
- テストデータは負債になりがち
- MLを元にしたObservabilityにより、新しい受信データを監視する。
What should you look for when selecting a data observability solution?
コードとその基盤となるアーキテクチャの迅速な開発を促進するために、DevOps チームは DevOps ライフサイクルと呼ばれるフィードバック ループを適用し、チームがビジネス目標に合わせた機能を大規模に確実に提供できるようにします。DevOps が継続的なフィードバック ループを適用してソフトウェアを改善するのとほぼ同じように、データの信頼性ライフサイクルは、データの健全性を継続的かつ積極的に改善するための組織全体のアプローチであり、DevOps のベスト プラクティスをデータ パイプラインに適用することでデータのダウンタイムを排除します。
- DevOpsでは、DevOpsライフサイクルと呼ばれるフィードバックループを適用する。これにより、チームがビジネス目標に合わせた機能を大規模に確実に提供できるようにする。
- DevOpsのベストプラクティスをデータパイプラインに適用することでデータのダウンタイムを排除する。
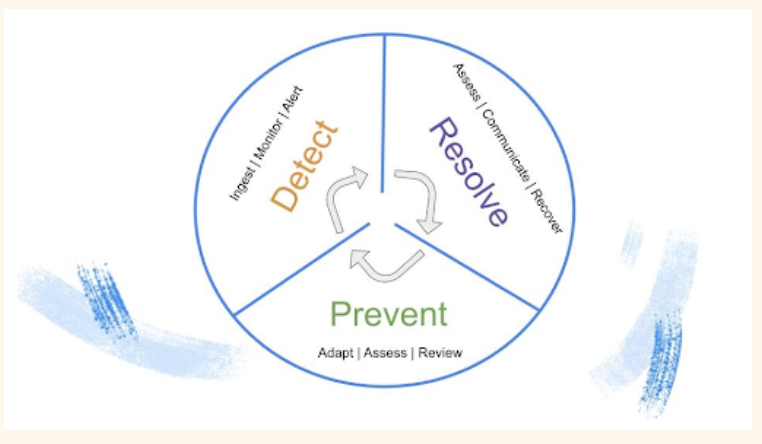
データの可観測性は、次のようなデータ信頼性のライフサイクルの重要な要素に対処します。
- 本番環境におけるデータ品質の問題を最初に知ることになります。
- 問題の影響を十分に理解しています。
- データがどこで壊れたかを完全に理解します。
- 問題を解決するための措置を講じます。
- 主要な資産、データの使用状況、アクセシビリティ、信頼性に関する情報など、時間をかけて問題の再発を防止できるように学習を収集します。
- データ品質の問題を最初にする。
- 問題の影響がわかる
- データがどこで壊れたか理解できる
- 問題を解決するための措置を講じる
- 各種情報(資産、使用状況、アクセシビリティ、信頼性)を元に、学習する
既存のスタックに迅速かつシームレスに接続し、パイプラインを変更したり、新しいコードを作成したり、特定のプログラミング言語を使用したりする必要はありません。これにより、多額の投資をすることなく、迅速な評価と最大限のテスト範囲が可能になります。
- 既存のスタックに接続
- 特定の言語、新たなコードは不要
- これにより、コストは下がる
ウェアハウスでの取り込みからETL、分析レイヤーに至るまで、スタックをエンドツーエンドでカバーします。データの可観測性は、ウェアハウスまたは BI レイヤーのみではなく、パイプラインの各段階でデータの健全性と信頼性を監視できる場合にのみ役立ちます。強力なデータ可観測性ソリューションでは、このエンドツーエンドのアプローチが採用されます。
保存データを監視し、現在保存されている場所からデータを抽出する必要はありません。これにより、ソリューションのパフォーマンス、拡張性、コスト効率が向上します。また、最高レベルのセキュリティとコンプライアンスの要件を確実に満たすことができます。
- Ingestion、ETL、分析レイヤーまでスタックをE2Eでカバーする
最小限の構成が必要で、実質的にしきい値の設定は必要ありません。ML モデルを使用して、環境とデータを自動的に学習します。異常検出技術を使用して、問題が発生したときにそれを通知します。個々の指標だけでなく、データの全体像と特定の問題による潜在的な影響を考慮することで、誤検知を最小限に抑えます。ノイズの多いルールの構成と維持にリソースを費やす必要はありません。
- しきい値の設定は不要
- MLモデルを使用する。自動的に学習する。
- 異常検出技術を使用して、通知する。
- 全体像を捉えることで、誤検知を最小限に抑える
何をどのように監視する必要があるかを事前にマッピングする必要はありません。これにより、フィールドレベルの自動リネージを通じて主要なリソース、主要な依存関係、および主要な不変条件を特定できるため、ほとんど労力をかけずに広範な可観測性を得ることができます。
- 監視をマッピングする必要はない
- これにより、フィールドレベルの自動リネージを通じて、下記を特定できる。
- リソース
- 依存関係
- 不変条件
迅速なトリアージとトラブルシューティング、およびデータ信頼性の問題の影響を受ける関係者との効果的なコミュニケーションを可能にする豊富なコンテキストを提供します。それは、「テーブル Y のフィールド X の値が今日 Z よりも低い」というところで止まりません。
- 関係者との効果的なコミュニケーションを可能にする
データ資産に関する豊富な情報を公開することで、そもそも問題の発生を防ぎ、根本原因と影響の分析を通じて責任を持って積極的に変更や修正を行うことができます。
- データ資産の情報を公開し、問題の発生を防ぐ
- 根本原因と影響の分析を通じて責任を持ち、積極的に変更や修正を行える
What are some common data observability use cases?
Datadog、New Relic、AppDynamics などのアプリケーション パフォーマンス監視ツールのユースケースがさまざまな機能にわたるのと同様に、データ エンジニアリング、分析、分析エンジニアリング チームがデータの可観測性を活用する方法はビジネスのニーズに応じて異なります。 。しかし、結局のところ、データ可観測性ソリューションの重要な機能は、データ組織がより信頼性の高いデータを提供できるようにすることです。
- アプリケーションパフォーマンス監視ツールのユースケースは、様々な機能にわたる
- 同時にObservabilityでも、ビジネスニーズに応じて異なる。
- 分析
- データエンジニアリング
- 本質は、Data Observabilityは、データ組織がより信頼性の高いデータを提供できるようにすること
一般的な使用例をいくつか示します。
- パイプラインのどこでデータが破損したかを理解する
- バグのあるコード、運用上の要因、データ自体など、データ インシデントの根本原因を特定する
- データの健全性と品質に関する関係者からの質問に答える:
「このダッシュボードはどうなったのですか?」
「なぜレポートが更新されなかったのですか?」
「なぜ私の計算はおかしく見えるのでしょうか?」
「このデータセットを更新したのはどのチームですか?」
「なぜパイプラインが壊れたのですか?」
「なぜ私のデータが見つからないのですか?!」
- パイプラインのどこで破損したのか。
- 根本原因の特定
- 運用上の要因
- データそのもの
- データエンジニアの目線から、質問に答える
- ダッシュボードはどうなった?
- 数値や計算がおかしい
- 誰が更新したのか?
- パイプラインが壊れたのはなぜか?
- データが見えない
アップストリームのソースとデータ ウェアハウス/レイク間の依存関係を、ダウンストリームのレポートとダッシュボードを使用してフィールド レベルまで自動的にマッピングします。
データの問題に対する影響分析を実施する。つまり、どのレポートまたはダッシュボードが上流のデータセットに接続しており、パイプラインの中断によって影響を受けるかを理解する。
データ環境の運用分析を追跡するために、主要な関係者にデータの信頼性の概要を提供します。
予期せぬインシデントやサイレントインシデントが発生した場合にデータに保険を提供することで、テストを補完します。
- アップストリームのソースとDWH、DLのリネージをフィールドレベルまでマッピングする
- データの問題に対する影響分析を実施する
- 影響分析を実施する
- パイプラインの中断により、影響を受けるか理解する
- サマリを関係者に提示する
- インシデントやサイレントインシデントが発生した場合に、テストを補完する。
製品
moderndatastack.xyzのData Quality Monitoring>Companiesを元に整理します。
概要だけ記載します。この中から深掘りしたいものは、別途調べようと思います。
2024/1/22現在で、いいねが10以上の製品を対象としています。
PipeRider
Piperider is a data impact assessment tool for dbt data projects.
PipeRider compares the data in your dbt project from before and after making data modeling changes and generates Impact Reports and Summaries. Use the generated reports to verify your changes and enable you to merge into prod confidently, without unexpected impact.
- パイプライダー
- Piperider は、dbt データ プロジェクトのデータ影響評価ツール
- PipeRider は、データ モデリングの変更前後の dbt プロジェクト内のデータを比較し、影響レポートと概要を生成
- 生成されたレポートを使用して変更を検証し、予期せぬ影響を与えることなく自信を持って本番環境にマージできるようにする。
Why use PipeRider?
- See the scope of impact that your dbt project code changes have on your data.
- Improve your development process by understanding your data and the impact of your changes.
- Improve your code-review process by verifying data impact before merging code changes.
- Improve communication between stakeholders and teammates by sharing and discussing Impact Reports.
- Keep a historical record of data impact reports for future reference.
- Compare the current state of your project with any point in the past.
- dbt プロジェクトのコード変更がデータに与える影響の範囲を確認します。
- データと変更の影響を理解することで、開発プロセスを改善します。
- コードの変更をマージする前にデータへの影響を検証することで、コード レビュー プロセスを改善します。
- 影響レポートを共有して議論することで、関係者とチームメイト間のコミュニケーションを改善します。
- 将来の参照のために、データ影響レポートの履歴記録を保管します。
- プロジェクトの現在の状態を過去の任意の時点と比較します。
Validio
Maximize return on data & AI investments
Unifying deep data observability, quality, lineage, and catalog
- データと AI への投資収益率を最大化
- 深いデータの可観測性、品質、系統、カタログを統合する
Deep data quality
- The market’s most powerful data validation
- Easy set up, zero maintenance—sophisticated under the hood
- Anomaly detection that learns from your data, including seasonality patterns
- Adjustable sensitivity to reduce false positives and alert fatigue
- Machine-learning based thresholds trained per data segment
- No wait: Backfill historical data and get ML-based thresholds instantly
- Custom SQL when Validio library isn’t enough
徹底したデータ品質
- 市場で最も強力なデータ検証
- セットアップが簡単、メンテナンス不要 – 内部は洗練されています
- 季節性パターンを含むデータから学習する異常検出
- 調整可能な感度により誤検知を軽減し、疲労を警告します
- データセグメントごとにトレーニングされた機械学習ベースのしきい値
- 待つ必要はありません: 履歴データをバックフィルし、ML ベースのしきい値を即座に取得します
- Validio ライブラリが不十分な場合のカスタム SQL
Discover and manage with a single click
- Insights about your data assets: popularity and ownership
- Import and attach metadata like tags and descriptions
- Global search of assets for discoverability and easy collaboration between data producers and consumers
- Classify data (e.g. PII) and manage data Access Control Levels
- Drive data governance and ownership across your organization
ワンクリックで検出して管理
- データ資産に関する洞察: 人気と所有権
- タグや説明などのメタデータをインポートして添付します
- 資産のグローバル検索により発見しやすくなり、データ生成者と消費者間のコラボレーションが容易になります
- データ (PII など) を分類し、データのアクセス制御レベルを管理します
- 組織全体でデータのガバナンスと所有権を推進する
Developer toolkit
- When we say code—we mean code
- Full developer toolbox including API, SDK and CLI to build your workflow exactly the way you want it
- Configurable in Python: Inline IDE documentation, syntax highlighting and autocompletion—Validio takes care of the rest
- Bidirectional IaC and GUI: Play around in the GUI and then lock it in with code, or vice versa
開発者ツールキット
- コードと言うとき、それはコードを意味します
- API、SDK、CLI を含む完全な開発者ツールボックスで、思い通りのワークフローを構築できます
- Python で構成可能: インライン IDE ドキュメント、構文の強調表示、オートコンプリート - 残りは Validio が処理します
- 双方向 IaC と GUI: GUI で遊んでからコードで固定する、またはその逆
Future-proof architecture
- Built for massive scale
- Built for performance in Rust
- Process hundreds of millions of records in under a minute
- Deploy in your Virtual Public Cloud or let Validio host it for you on GCP, AWS or Azure
- Streaming and pushdown architecture—Validio compiler takes care of it under the hood
- Negligible add to your cloud bill: Validio optimizes queries and bundles them with your existing pipeline
将来性のあるアーキテクチャ
- 大規模向けに構築
- Rust でのパフォーマンスを考慮して構築
- 数億件のレコードを 1 分以内に処理
- 仮想パブリック クラウドにデプロイするか、Validio に GCP、AWS、または Azure でホストさせます
- ストリーミングおよびプッシュダウン アーキテクチャ - Validio コンパイラが内部で処理します
- クラウド料金への追加は無視できます: Validio はクエリを最適化し、既存のパイプラインにバンドルします
Seamless integrations
Integrations—the deep kind
- Validio integrates with your favourite tools in real time
- Integrate with your streams, lakes, warehouses, and transformations of choice
- Leverage your existing notifications systems to be the first to know about data issues
シームレスな統合
統合 - 深い種類の統合
- Validio はお気に入りのツールとリアルタイムで統合します
- 選択したStream、Lakes、Warehouse、Tramnformsと統合します
- 既存の通知システムを活用して、データの問題をいち早く知ることができます。
Sifflet
moderndatastack.xyzからのリンクが切れていました。おそらく下記と思われます。
A better data experience
Say goodbye to data chaos with end-to-end data observability.
より良いデータエクスペリエンス
エンドツーエンドのデータ可観測性により、データの混乱に別れを告げます。
Go from data chaos to data calm
An all-in-one data observability platform that keeps your data organized, accessible, and reliable.
データの混乱からデータの静穏へ
データの整理、アクセス、信頼性を維持するオールインワンのデータ可観測性プラットフォーム。
ORGANIZED
Get a bird's-eye view of your data
Gain a clear view of your data with a platform that integrates with your data stack, provides centralized documentation, lineage, and searchable metadata.
整頓された
データを俯瞰的に見る
データ スタックと統合され、一元化されたドキュメント、系統、検索可能なメタデータを提供するプラットフォームを使用して、データを明確に把握できます。
※出典:siffletdata
ACCESSIBLE
Improve productivity and collaboration between engineers and data consumers
For everyone, working with and finding data becomes intuitive with a simple and automated UI, data discovery is simplified with a data catalog, and it is easy to connect with coding workflows.
- エンジニアとデータ利用者の生産性とコラボレーションを向上させる
- 誰にとっても、シンプルで自動化された UI によってデータの操作と検索が直感的になり、データ カタログによってデータ検出が簡素化され、コーディング ワークフローとの接続が簡単になる
RELIABLE
Data quality management simplified
Ensure reliable data quality with smart monitoring and alerting (without the noise), root cause analysis, 50+ data quality templates, and mapping capabilities.
- データ品質管理の簡素化
- スマートなモニタリングとアラート (ノイズなし)、根本原因分析、50 以上のデータ品質テンプレート、マッピング機能により、信頼性の高いデータ品質を確保
Great Expectations
Have confidence in your data,
no matter what
Built on the strength of a robust worldwide data quality community, the Great Expectations platform is revolutionizing data quality and collaboration.
- Great Expectations プラットフォームは、堅牢な世界規模のデータ品質コミュニティの強みを基盤として構築されている
- データ品質とコラボレーションに特徴がある
A shared understanding of your data
Getting everyone on the same page is essential to deriving business value from data. Great Expectations offers an intuitive approach to testing data that automatically generates widely-readable results—making vital collaboration between technical and nontechnical teams easier.
- データからビジネス価値を引き出すには、全員が同じ認識を持つことが不可欠
- Great Expectations は、データをテストするための直感的なアプローチを提供し、広く読みやすい結果を自動的に生成することで、技術チームと非技術チーム間の重要なコラボレーションを容易にする。
Accelerate your data discovery
GX helps you get insight into your data faster, collaborate more effectively, and empower technical and nontechnical teams to work in their preferred styles while still achieving their shared goals. Expectations create the central reference points that are key to organization-wide data quality.
- GX を使用すると、データに対する洞察をより迅速に取得し、より効果的にコラボレーションできるようになる
- 技術チームと非技術チームが共通の目標を達成しながら、好みのスタイルで作業できる
- 期待により、組織全体のデータ品質の鍵となる中心的な参照ポイントが作成されます。
Smooth fit with your existing stack
Create trust in data wherever you need it: GX integrates with a wide range of data sources and popular orchestrators.
Your data stays secure throughout since GX connects with your secret stores for data access and never moves or changes your data from the locations where you already have it. Learn more about security in GX here.
Simple role-based access control and edit histories for your Expectations levels up your data quality governance capabilities in GX Cloud.
Bring data quality into your stack today.
- GX は、幅広いデータ ソースや一般的なオーケストレーターと統合します。
- GX はデータ アクセスのためにシークレット ストアに接続し、データが既に存在する場所からデータを移動したり変更したりすることはないため、データは全体的に安全に保たれる。
- シンプルなロールベースのアクセス制御と期待事項の編集履歴により、GX Cloud のデータ品質ガバナンス機能がレベルアップされます。
The power of Expectations
-
Expectation は、データに関する検証可能なアサーションです。
-
Expectation を作成すると、データ品質テストを定義する他の方法と比べて、比類のない柔軟性と制御が得られます。
-
この直感的なアプローチは、技術チームでも非技術チームでも同様に利用できます。
-
Expectation では、個々の検証結果に基づいて更新されたドキュメントが自動的に生成され、全員がテスト スイートと検証結果を確認できるようになります。
-
Expectation は、スキーマに焦点を当てた検証よりも深い洞察を提供し、異常検出などの低構成のオプションよりも変化するビジネス要件や技術要件に対する回復力が高くなります。
-
さらに、Expectation は再利用可能で自動生成できるため、大量のデータに簡単に展開できます。
Monte Carlo Data
Data and AI reliability. Delivered.
Data breaks. Monte Carlo ensures your team is the first to know and solve with end-to-end data observability.
- モンテカルロは、チームがエンドツーエンドのデータ可観測性を最初に知り、解決できることを保証
Sick of "why is my data wrong" messages?
Data engineers: wouldn’t it be great if you could understand the freshness, volume, schema, and quality of your data? What if you were notified before stakeholders when your dashboards broke?
- データ エンジニアの目線
- データの鮮度、量、スキーマ、品質を理解できたら素晴らしい
- ダッシュボードが壊れたときに関係者の前に通知されたらどうなるか
Tired of spending days resolving data quality issues?
Analysts: data quality issues drain resources, erode stakeholder trust, and can take hours to days to root cause and resolve. Wouldn’t it be nice if you had incident detection and resolution at your fingertips?
- アナリストの目線
- データ品質の問題はリソースを浪費し、関係者の信頼を損ない、根本原因と解決までに数時間から数日かかる場合がある。
- インシデントの検出と解決をすぐに行えたら便利
Done with products you can't trust?
Executives: did you know that bad data costs companies millions of dollars per year? Imagine a world in which you didn’t have to second guess the data powering your dashboards, products, and digital services.
- 経営幹部の目線:
- 不良データにより企業に年間数百万ドルの損害が発生する
- ダッシュボード、製品、デジタル サービスを動かすデータを改めて推測する必要がない世界を想像してみてほしい
End-to-end data observability.
Observability across your modern data stack. Detect, alert, resolve, and prevent data incidents at scale.
- 最新のデータスタック全体の可観測性。
- 大規模なデータ インシデントを検出、警告、解決、防止します。
Data observability
Know when data breaks.
Know when data breaks – as soon as it happens. Receive and triage alerts via Slack, Teams, JIRA, and other channels you already use.
- データの破損が発生するとすぐにそれを知ることができる。
- Slack、Teams、JIRA、およびすでに使用しているその他のチャネル経由でアラートを受信し、優先順位を付けられる
Elementary Data
dbt native
data observability
Monitor data pipelines in minutes, in your dbt project. Elementary is built for and trusted by 3000+ analytics and data engineers.
- データの可観測性
- dbt プロジェクトでデータ パイプラインを数分で監視します。 Elementary は 3,000 人を超える分析エンジニアやデータ エンジニア向けに構築され、信頼されています。
Built for data developers
All the Elementary configuration is managed in your dbt code. Elementary Cloud syncs configuration changes from the UI back to the dbt project code repository.
- Config-as-code or in UI, fully synced
- Version control and code review for changes
- Test changes, enforce policies in CI
- No duplication, existing config is leveraged
- すべての基本構成は dbt コードで管理
- Elementary Cloud は、UI からの設定変更を dbt プロジェクト コード リポジトリに同期します。
- コードとして構成または UI で完全に同期
- バージョン管理と変更のコードレビュー
- 変更をテストし、CI でポリシーを適用する
- 重複はなく、既存の構成が活用されます
Data tests and anomaly detection
Manage all test results and alerting in a single interface. Add Elementary anomaly detection tests to the dbt and custom tests you already use.
- Freshness, volume & column anomalies
- Anomalies per dimension
- Granular time and seasonality config
- Advanced schema changes
- Supports all the dbt, packages and custom tests
- すべてのテスト結果とアラートを単一のインターフェイスで管理します。 すでに使用している dbt テストとカスタム テストに基本的な異常検出テストを追加します。
- 鮮度、容量、カラムの異常
- 次元ごとの異常
- 詳細な時間と季節性の構成
- 高度なスキーマ変更
- すべての dbt、パッケージ、カスタム テストをサポート
Data lineage of data issues
Elementary Cloud automatically extends the lineage to BI tools exposures, making it easy to understand the source and impact of data issues.
- Automated from DWH to dashboards
- Column level lineage
- See lineage in dbt docs and dbt cloud
- Enriched with data issues information
- Elementary Cloud は、BI ツールのエクスポージャへの系統を自動的に拡張し、データの問題の原因と影響を理解しやすくします。
- DWHからダッシュボードまで自動化
- 列レベルの系統
- dbt ドキュメントと dbt クラウドで系統を参照
- データ問題に関する情報が充実
Secure by design, no data access
Elementary Cloud can't access your data. SDK creates a schema for logs, results and metadata, and Elementary only requires read access to it.
- No permissions to your data from cloud
- Cloud does not access any raw data
- Read only access to metadata schema
- Advanced deployment options
- Elementary Cloud はデータにアクセスできません。 SDK はログ、結果、メタデータのスキーマを作成します。Elementary はそのスキーマへの読み取りアクセスのみを必要とします。
- クラウドからのデータに対するアクセス許可がありません
- クラウドは生データにアクセスしません
- メタデータ スキーマへの読み取り専用アクセス
- 高度な展開オプション
Works with your stack
Elementary is dbt native, and integrates with your data platform and orchsestration tool. Additional integrations include code repositories, BI tools, messaging and task management applications.
- SDK for dbt core and dbt cloud
- Supports Snowflake, BigQuery, Redshift, Databricks and Postgres
- Integrations with BI tools, code repos and orchestrators
- Messaging apps and task management tools
Elementary は dbt ネイティブであり、データ プラットフォームおよびオーケストレーション ツールと統合されます。 追加の統合には、コード リポジトリ、BI ツール、メッセージング、タスク管理アプリケーションが含まれます。
- dbt コアおよび dbt クラウド用の SDK
- Snowflake、BigQuery、Redshift、Databricks、Postgres をサポート
- BI ツール、コード リポジトリ、オーケストレーターとの統合
- メッセージング アプリとタスク管理ツール
Metaplane
Be the first to know about
silent data bugs
✓ Automated incident detection, impact analysis, root cause diagnosis
✓ Pricing that makes sense for teams of all sizes
✓ End-to-end data observability in 15 minutes
- 自動化されたインシデント検出、影響分析、根本原因診断
- あらゆる規模のチームにとって合理的な価格設定
- 15 分でエンドツーエンドのデータ可観測性
End-to-end data observability platform for teams of 1 or 100+
Monitoring and anomaly detection
ML-based monitoring with historical metadata
Metaplane's monitors learn from historical metadata to detect anomalies while accounting for seasonality, trends, and feedback from your team.
- 履歴メタデータを使用した ML ベースのモニタリング
- Metaplane のモニターは過去のメタデータから学習し、季節性、傾向、チームからのフィードバックを考慮しながら異常を検出します。
Data CI/CD
Prevent data quality issues in pull requests
Halt PRs with unintended effects and prevent data quality issues from hitting the warehouse. Metaplane can run checks directly in your source control system to ensure your data team can merge changes with confidence.
- 意図しない影響をもたらす PR を停止し、データ品質の問題がウェアハウスに影響を与えるのを防ぎます。
- Metaplane はソース管理システムで直接チェックを実行し、データ チームが自信を持って変更をマージできるようにします。
Lineage and impact analysis
Automated lineage throughout your stack
Metaplane extracts column-level lineage from databases to dashboards so you can assess downstream impact, prioritize work, and notify the right people.
- スタック全体にわたる自動リネージ
- Metaplane はデータベースからダッシュボードに列レベルの系統を抽出するため、下流への影響を評価し、作業に優先順位を付け、適切な担当者に通知できます。
Usage analytics
Discover how your data is being used
Track who (or what) is querying your data to identify which assets deserve your attention and resources
- データがどのように使用されているかを確認する
- 誰 (または何) がデータをクエリしているかを追跡して、注目すべき資産とリソースを特定します
Schema change alerts
Stay on top of warehouse schema changes
Get real-time notifications about new/deleted/renamed schemas, tables, and columns
- ウェアハウススキーマの変更を常に把握する
- 新規/削除/名前変更されたスキーマ、テーブル、列に関するリアルタイムの通知を受け取る
Job monitoring
Catch stuck or long-running jobs as they happen
Monitor your dbt jobs on autopilot and get real-time alerts about abnormal runs
- スタックしたジョブや長時間実行されているジョブを発生時に捕捉する
- 自動操縦で dbt ジョブを監視し、異常な実行に関するリアルタイムのアラートを取得します
考察
今回、Data Quality Monitoringについて調べてみました。データ基盤には、予測できないデータが入ってくる可能性が常にあり、静的テストだけでは完全に排除することは不可能です。また、テストデータは負債になりがちです。
データ品質を保つためには、Data Observability→静的テストのサイクルを回し続けることが必要です。
Data Observabilityの製品は複数ありますが、各社とも観測は当然ながら、UIでのわかりやすさ、dbtとの親和性や通知、コードの変更、スキーマの変更による予測などの機能を提供しているようでした。
今後は、これらの製品の中で、気になったものについて試してみたいと思います。
参考