背景・目的
【ModernDataStack】Data Quality Monitoringについて調べてみたで、各製品を簡単に整理してみました。
このうち、今回は、Metaplaneの特徴と機能を整理してみます。
まとめ
下記の特徴があります。
| 特徴 | 説明 |
|---|---|
| Monitoring and anomaly detection | コードを書かずにモニターをすばやく追加 |
| Linage and impact analysis | 列レベルでリネージできる |
| Usage analytics | 利用されているオブジェクトやクエリ、実行ユーザを可視化 |
| Data CI/CD | 回帰テストにより、影響分析する |
| Schema Change alerts | スキーマの変更をトレースできる |
| Job monitoring | ジョブの実行時間を取得できアラートを受け取れる |
| Alerting | データ品質の問題を処理するための標準化されたプロセス |
概要
概要は、【ModernDataStack】Data Quality Monitoringについて調べてみたにまとめていますので、よろしければ御覧ください。
ここでは、詳細を記載します。
Monitoring and anomaly detection
ノーコード
- コードを書かずにモニターをすばやく追加
- 提案と使用方法のアイコンがモニターの配置場所を強調表示
- 既知の問題に対して手動のしきい値を設定し、カスタム SQL を使用
- 機械学習ベースのモニターが未知の問題を特定
モニターの種類
| モニター | 説明 | 備考 |
|---|---|---|
| Row Count | テーブルまたはビュー内の行数を経時的に追跡 | 可能な場合は、Information_schemaから直接取得するためコストが安くなる 不可能な場合は、SELECT COUNTする |
| Freshness | テーブルまたは列が最後に更新されてからの期間を追跡 | Metaplane はテーブルとマテリアライズド ビューの最終変更日をテーブルから直接取得するため安価 カラムに設定されている場合は、SELECT MAX(column) FROM TABLE |
| Column Count | 特定のテーブルまたはビュー内の列の数を追跡 | Information_schemaから直接取得するためコストが安くなる |
| Cardinality | 特定の列の個別の要素の数 | SELECT COUNT(DISTINCT yourColumn) TABLEで取得 |
| Uniquness | 特定の列内の一意の要素の割合を追跡 | 値 0 は列が一意性 100% である 、値 1 は列が一意性 0% (たとえば、すべて同じ値) である SELECT COUNT(DISTINCT yourColumn) / COUNT(1) FROM TABLEで計算される。 |
| Nullness | 特定の列内の null 要素の割合を追跡 | 値 0 は列が 100% 非 null 値 1 は列がすべて null |
| Minimum | 数値列の最小値を追跡。値が予想より高いか低い場合に警告が表示 | SELECT MIN() FROM TABLE |
| Maximum | 数値列の最大値を追跡 値が予想より高いか低い場合に警告が表示 |
SELECT MAX() FROM TABLE |
| Mean | 数値列の算術平均を追跡 値が予想より高いか低い場合に警告 |
SELECT AVG() FROM TABLE |
| Standard Deviation | 標準偏差の数値列を追跡 値が予想より高いか低い場合に警告 |
SELECT STDDEV(::double) FROM TABLE |
| Sum | 数値列の合計を追跡 値が予想より高いか低い場合に警告 |
SELECT SUM() FROM TABLE |
| Percent Zero | 特定の数値列内のゼロに等しい値の割合を追跡 値 0 は列が 100% ゼロであること 値 1 は列にゼロがない |
SELECT SUM(CASE WHEN = 0 THEN 1 ELSE 0 END) / COUNT(1) FROM TABLE |
| Percent Negative | 特定の数値列内のゼロ未満の値の割合 値 0 は列が 100% 負である 値 1 は列がすべて正またはゼロである |
SELECT SUM(CASE WHEN < 0 THEN 1 ELSE 0 END) / COUNT(1) FROM TABLE |
| Custom SQL | 独自の完全にカスタムの SQL クエリを入力 より複雑なモニターを作成して指定 |
カスタマイズ
- 提案を活用し、ニーズに合わせてカスタマイズする
- テーブルのディメンション内のデータ品質の問題を見つけるようにモニターを構成
- 感度調整とフィードバックを通じてモデルと直接対話
- 時間枠を通じて監視データをカスタマイズ
インスタントカバレッジ
-
モニタリングモデリングの仕組み
- コンピューティングを制限するための鮮度と量のために使用されるウェアハウスからのメタデータ
- データ内の問題を見つけるために使用される詳細なデータ サンプリング クエリ
- 洗練されたモデリングは 3 日以内に機能し、季節性を考慮する
-
メタデータの可視性の向上
- ほとんどの企業は、正当な理由から、データベース内のすべてを監視しないことを選択している
- ノイズとコストからそれだけの価値がないことがよくある
- しかし、メタデータを調べたくないわけではない。
- Snowflake または BigQuery ウェアハウスを使用する Metaplane ユーザー向けに、データベース内のすべてのテーブルまたはビューの鮮度と行数のスナップショットをキャプチャする
- 将来のある時点でデータにモニターを追加することにした場合でも、標準的な 3 ~ 5 日間のトレーニング期間を待つ必要はない。履歴を持っているので、そのテーブルの行数と鮮度を瞬時に監視することができる。
- ほとんどの企業は、正当な理由から、データベース内のすべてを監視しないことを選択している
自動パーソナライゼーション
- テーブル内のさまざまな次元で監視する
- 平均収益や顧客別の平均などのビジネス指標を大規模に監視
- SQL で手動で定義することなく、1 つ以上のグループを簡単に選択
- 自動化された問題のグループ化でアラート疲れを回避
グループ化モニター
テーブル/ビュー内の論理グループを監視して、微妙な品質問題を検出し、根本原因を迅速に診断できる
モニターは、テーブルや列全体のデータ品質の問題を検出するのに最適です。ただし、テーブル全体を操作するモニターでは、データのセグメント内の微妙な品質の問題を見逃してしまう可能性があります。
たとえば、イベント テーブルの行数は正常範囲内にあるように見えますが、1 つまたは複数の特定のイベント タイプの行数が予想を下回る可能性があります。これらの微妙な偏差は、集計に影響を与えないほど十分に小さい場合があります。行数を監視するため、モニターに警告が表示されることはありません。このタイプの問題は、鮮度、配布、ヌルネスなど、他のタイプのモニターでも発生する可能性があります。
Group By モニターを使用すると、データ チームはテーブルを構成する論理セグメント (ディメンション列の値による集計など) を定義し、それらのセグメントにモニターを適用できます。これは、データ チームがテーブルの集計行数やそのテーブル内の論理グループの行数などを監視できることを意味します。
- 全体を見るだけでは見逃してしまうアラートをセグメント化してモニターする。
Linage and impact analysis
列レベルの系統
データ スタックとパイプラインですべてのフィールドがどのように使用されているかを可視化することは、データ インシデント ワークフローのほぼすべてのステップで有益です。
- 将来の問題の防止: テーブルやレポートでのフィールドの使用状況を理解すると、スキーマの変更などの更新によってクエリがどのように中断されるかを予測するのに役立ちます。
- 影響の理解: 列レベルのリネージュは、問題が発生したときに下流オブジェクトを追跡し、関連する利害関係者を特定するのに役立ちます。この情報を取得すると、プロアクティブなアラートが有効になり、問題解決のための貴重なコンテキストを取得するチャネルが得られます。
- 問題の解決: 問題を解決するには、通常、上流のオブジェクトを見つけて、問題を引き起こした新しいプロセスまたは変更されたプロセスを見つける必要があります。最新の列レベルの系統を整備すると、問題のトリアージ時間が短縮されます。
- 列レベルでリネージできると下記のメリットがある
- 将来の問題の防止
- 影響の理解
- 問題の解決
リネージ分析と影響分析の仕組み
- 影響分析
- 異常を迅速に調査して、どのデータ製品が影響を受けるかを確認
- 生データがメダリオンのアーキテクチャにどのような影響を与えるかを理解する
- データ品質の問題を適切な関係者に伝える
- より迅速なトリアージ
- ソーステーブルで直接データをクリーンアップして、面倒なバックフィル作業を軽減
- 未使用のオブジェクトを特定してデータの衛生性を向上
- ETL/ELT ツールに起因するコネクタの停止を理解
- リファクタリングから推測を排除
- テーブルを大規模に表示したり、特定の列をドリルダウン
- 倉庫内のテーブルでもシグマ レポートでも、あらゆるものを検索
- リスト ビューを使用して、どのオブジェクトが下流の複数のモデルであるかを理解
Usage analytics
使用状況分析とは
データ可観測性ソリューションは、メタデータを活用してデータおよび関連プロセスの問題を検出したり、列レベルの系統を生成したりするだけでなく、そのメタデータを使用してクエリ パターンを理解することもできます。この情報を取得すると、ウェアハウスのユーザー コンテキストが強化され、将来の潜在的な問題にフラグを立てることができ、クエリの健全性が促進されます。これを使用して次のことができます。
- 主要なオブジェクトを特定する: クエリを解析すると、頻繁に参照されているオブジェクトを特定するのに役立ちます。また、クエリの頻度を追跡すると、これらのオブジェクトの使用頻度を把握できます。両方の要素を考慮することで、キー オブジェクトを変更するときに注意して、スタック全体に問題が連鎖するのを避けることができます。
- 頻繁に参照されているオブジェクトを特定
- ウェアハウスの効率の向上: クラウド ウェアハウスでは、クエリの実行時間が長くなるとコンピューティング費用が増加し、cron に依存するフローに遅延が発生する可能性があります。OLTP データベースでは、クエリが長時間続くと、トランザクションが失われ、データベースがブロックされる場合もあります。毎日の実行時チェックは必要ない場合もありますが、定期的な評価はプロアクティブな効率の向上とコンピューティング リソースの消費量の削減に役立ちます。
- 実行時間のクエリを分析する
- データ スタックの総所有コスト (TCO) を改善する: クラウド データ ウェアハウス/レイクおよび関連ツールを含むデータ スタックでは、個別のプロセス (COPY/MERGE、その他の DML ステートメントなど) に特定のユーザーまたはグループを割り当てることが一般的です。サービス ユーザーが実行するクエリを追跡することは、DWH支出に不相応に寄与しているツールを特定するのに役立ち、構成を調整してコストを削減できるようになります。
- 使用しているユーザの特定
Data CI/CD
- プロアクティブなインシデント防止
- 回帰テストとは何か、それがデータ パイプラインにどのように適用されるか、データ品質インシデントを防ぐ方法
データ CI/CDの仕組み
-
影響分析
- 下流への影響を予測する
- ウェアハウス内のテーブルから BI レポートへの依存関係を確認する
- スキーマの変更がデータ構造にどのような影響を与えるかを理解する
- 信頼を維持するために潜在的なダウンタイムについて関係者に事前に警告します
- 下流への影響を予測する
-
プルリクエストで影響分析を確認する
- dbt モデルに加えられた変更は、Metaplane と統合されている場合、データ ウェアハウスとビジネス インテリジェンスツールの両方でダウンストリームオブジェクトを識別する。
-
重大な変更を加える前にチームメイトと同期する
- コードをマージする前に、すべてのダウンストリーム ダッシュボードを考慮することは不可能
- Metaplane の影響分析プレビューには、プルリクエストで変更しているモデルのダウンストリームが表示されるため、重大な変更を加える前にチームメイトと同期できる
-
自信を持ってリファクタリングできる
-
オブジェクトがどのような影響を受けるかを理解する
-
ワークフローを統合する
- モデルの更新ごとに回帰テストを行うために GitHub アプリを使用します
- インシデントの振り返りのためのベースラインを確立する
- すべてのインシデントに関連するプル リクエストを表示して、問題をより迅速に優先順位付けします
Schema Change alerts
スキーマ変更とは?
チームが現在トランザクションと分析の両方に 1 つのデータベースを使用している場合でも、複数のデータベースに相当するデータを分析レイクハウスに一元管理している場合でも、スキーマの変更を追跡することが重要であり、変更の種類に応じて明確なメリットが得られます。
- 変更されたデータ型: 数値データ型のみに適用されるクエリなど、既存のクエリが引き続き機能することを確認します。
- 非推奨のフィールドとオブジェクト: これらのオブジェクトを使用して未使用のダッシュボードを非推奨にすることでデータ戦略を調整するか、代替を決定します。
- 名前変更されたフィールドとオブジェクト: 新しいフィールドとオブジェクト参照でクエリを更新します。
- 新しいフィールドとオブジェクト: 現在または今後のデータ プロジェクトに対する新しいフィールドとオブジェクトの値を決定します。
- スキーマの変更をトレースできる
- 非推奨のフィールドとオブジェクト
- 名前変更されたフィールドとオブジェクト
- 新しいフィールド
トランザクションデータベーススキーマ変更の監視
トランザクション データベースは、ソフトウェア アプリケーション イベント、Web サイトのアクティビティ、製造の進捗状況などのデータを保存するために使用されます。その結果、データを使用してビジネスを推進している高成長企業では、チームが活動のさまざまな側面を追跡する必要があるため、変更や新しい分野がまとめて発生することがよくあります。
スキーマ変更の追跡を使用すると、異なるグループ間のコミュニケーションを改善し、アクティビティを調整することができます。たとえば、製品チームが変更を指示し、エンジニアリング チームが実装するソフトウェア アプリケーションの場合、スキーマ変更のリストを特定すると、下流の製品分析チームとの連携が強化されます。
- スキーマの変更を検知し、異なるグループ間のコミュニケーションに使う
スキーマ変更アラートの仕組み
-
予期せぬアップストリームの変更をキャッチする
- 上流チームによって作成された新しいフィールドまたは変更されたフィールドに関するアラート
- 上流ユーザーが変更の影響を理解できるようにする
- 変更追跡に関連するストレージコストを削減
-
可能性のある容疑者を排除する
- データインシデントの根本原因を特定する
- null がデータ火災によるものなのか、スキーマ変更によるものなのかを嗅ぎ分ける
- 履歴監査証跡を作成する
- すべてのテーブル (アクティブなデータ品質モニターのないテーブルも含む) をカバー
- データインシデントの根本原因を特定する
Job monitoring
- dbt ジョブ期間モニター
dbt ジョブ期間モニターを使用すると、dbt ジョブの実行にかかる時間の概要を取得し、通常よりも処理に時間がかかるジョブについてアラートを受け取ることができます。他のMetaplane モニター タイプに精通している場合は、これを dbt ジョブの鮮度として考えることができます。dbt ジョブの継続時間を監視することは、潜在的なデータ品質問題の先行指標として役立ちます。特に、レイテンシーの依存関係がある場合や、最新のデータ (つまり、リアルタイムまたはほぼリアルタイム) が必要な場合に役立ちます。
- dbt job duration monitorsを使用すると、ジョブの実行時間を取得できアラートを受け取れる
dbt ジョブ監視の仕組み
実行するすべての dbt ジョブを自動的に監視します
- ランタイム履歴データを即座に同期して、異常を即座に警告します
- 一般的な実行時間または手動のしきい値に基づいて、異常なジョブの実行を検出します。
- 遅延によるダウンストリームへの悪影響が生じる前に問題を修正する
舞台裏
- dbt メタデータのインポートは、すべてのプロジェクトを監視する効率的な方法を提供します
- 感度を調整し、時間枠を指定してアラート疲労を軽減します
- dbt クラウドとコアの両方をサポート
Alerting
データインシデント管理
データ インシデント管理ワークフローは、データ品質の問題を処理するための標準化されたプロセスです。このプロセスを確立することは、信頼を構築し、悪影響を防止し、問題解決と利害関係者とのコミュニケーションを迅速化するために重要です。
- データインシデント管理ワークフロー
- データ品質の問題を処理するための標準化されたプロセス
何が問題となるのか
データ プロファイルへの変更はデータ品質の問題として分類される場合がありますが、常にそうとは限りません。例えば:
- スキーマの変更: 列の名前変更は、フィールドを参照するダウンストリーム モデルに影響しますが、列が実際にはどのデータ製品でも使用されないケースも多くあります。
- 配信の変更: 配信の変更インシデントは、米国のサブスクリプション収益が 200 万ドルから 0 ドルに突然減少することによって例証されます。この減少は、ユーザー活動の完全な停止、または米国のサポート終了によって引き起こされる予想される結果のいずれかを示している可能性があります。
インシデントの重大度と優先度は、その使用目的に大きく依存し、データ製品と関係者を特定するという次のステップに進みます。
実践
今回、MetaplaneからRedshiftに接続します。
Getting startedを元に試してみます。
前提
Redshift Serverless
クラスタの作成
-
AWSにサインインし、Redshiftのトップページに移動します
-
ナビゲーションペインで「Redshift serverless」をクリックします
-
「設定をカスタマイズ」をクリックします
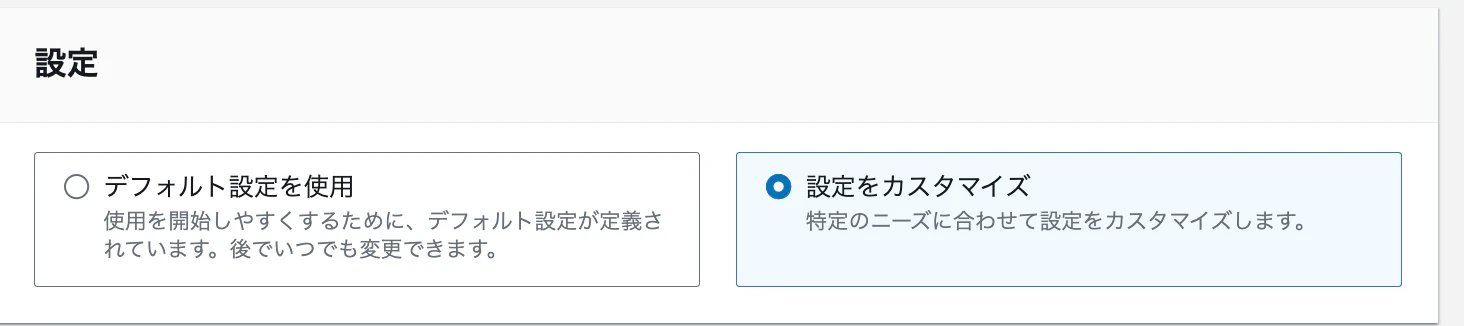
-
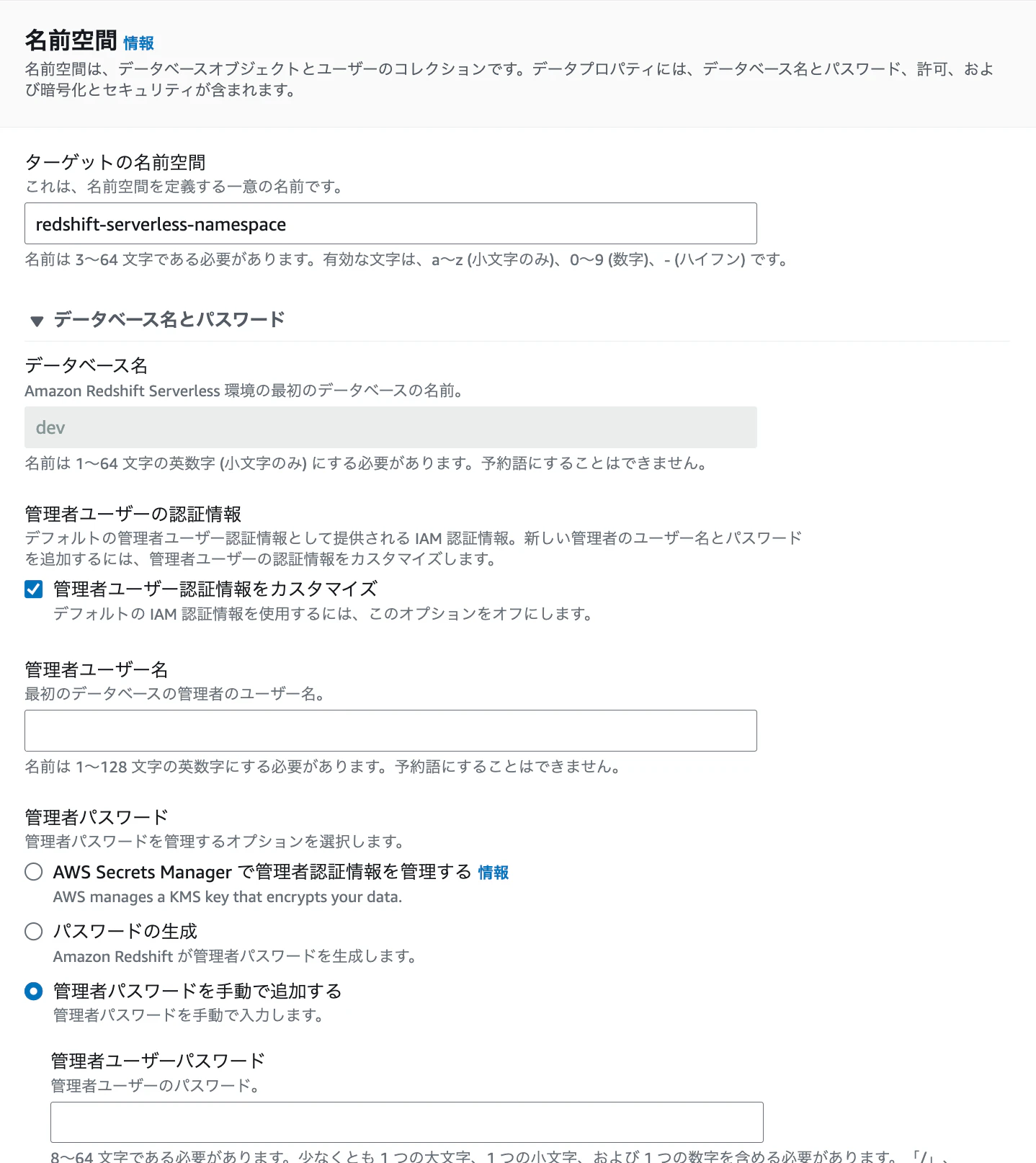
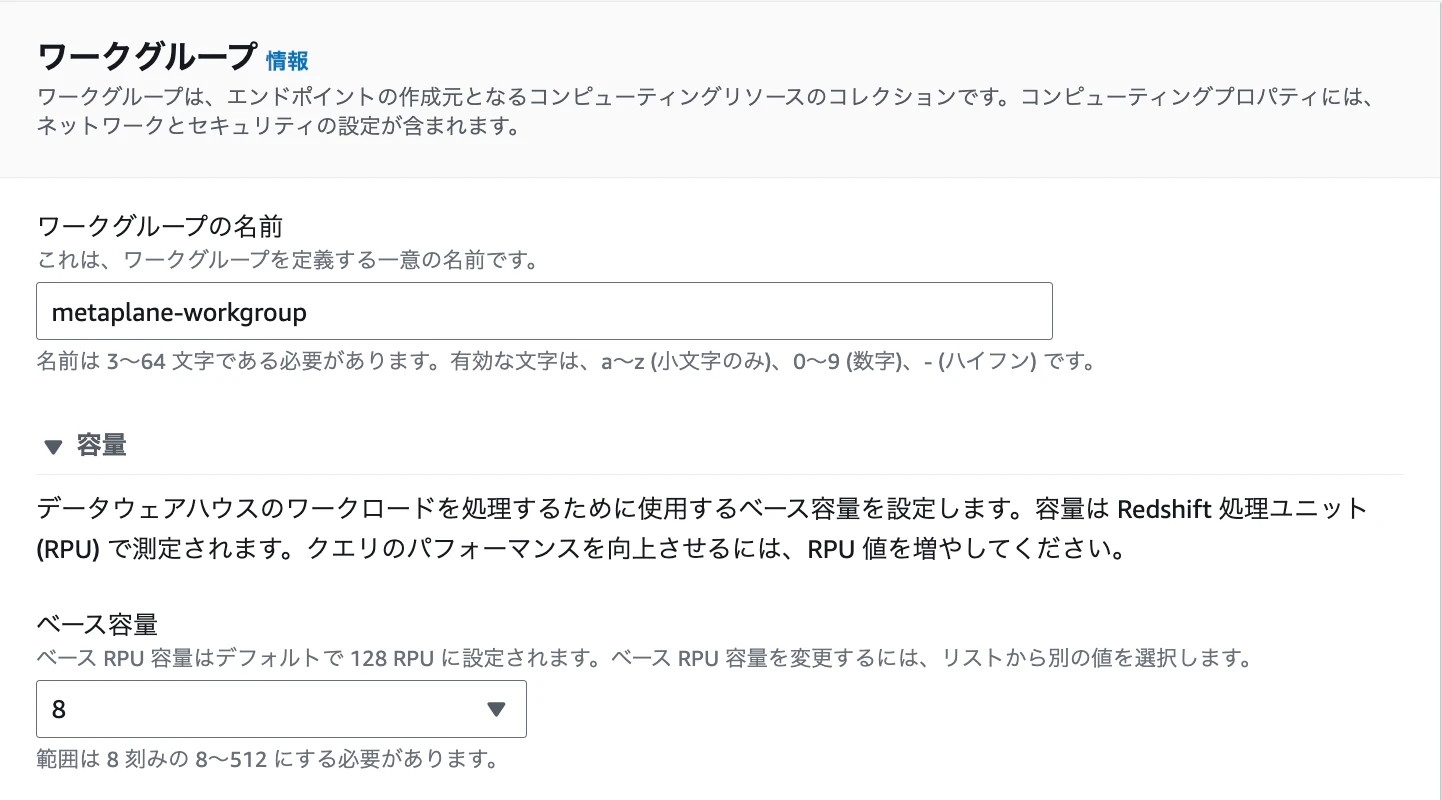
下記を入力し、「設定を保存」をクリックします
- ターゲットの名前空間:任意
- 管理者ユーザの認証情報をカスタマイズをチェック
- 管理者ユーザ名:任意
- 管理者パスワード:任意
- ワークグループ名:任意
- 容量:任意
-
できました。

Whitelist Metaplane IPs
-
Redshift Serverlessダッシュボードで「ワークグループ名」をクリックします

-
ネットワークとセキュリティで「編集」をクリックします
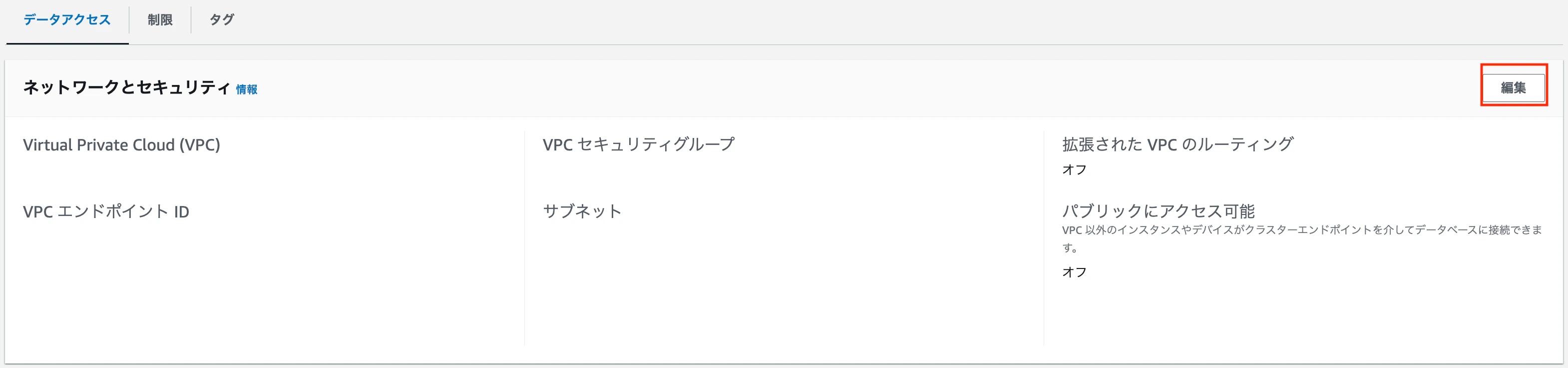
-
「パブリックにアクセス可能」にチェックを入れて、「変更を保存」をクリックします。
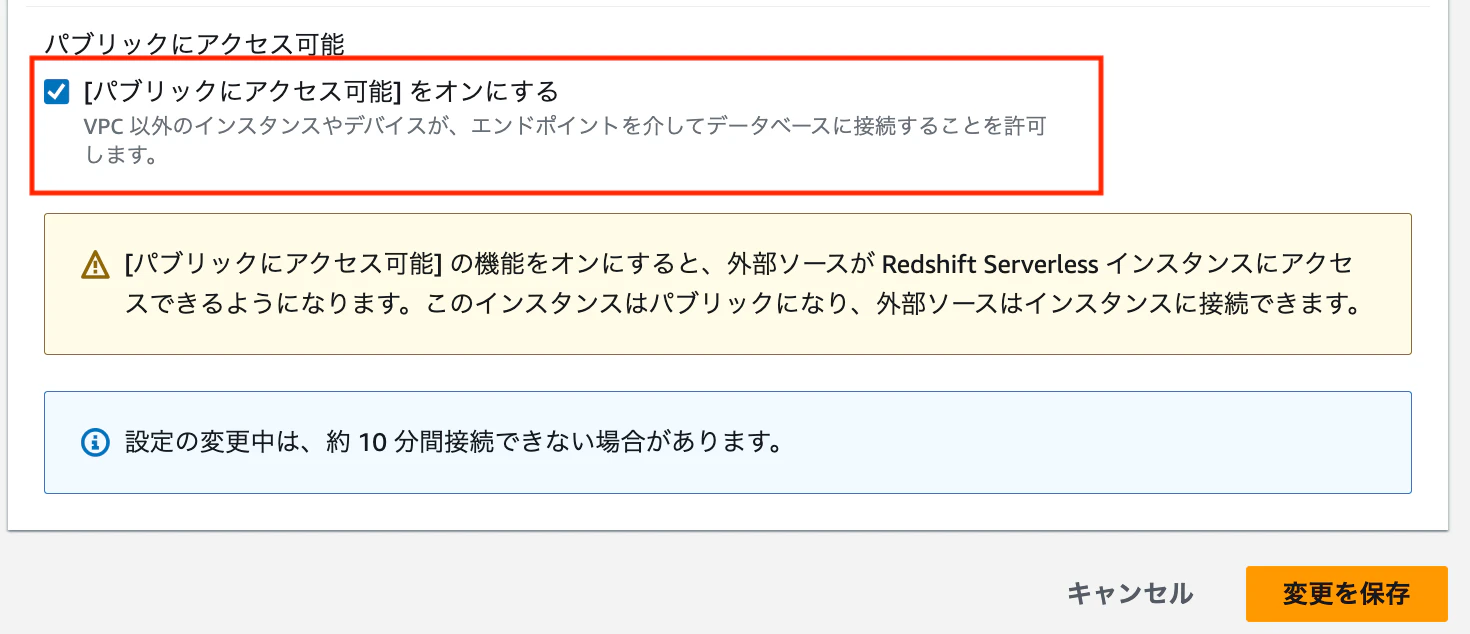
-
有効化されました
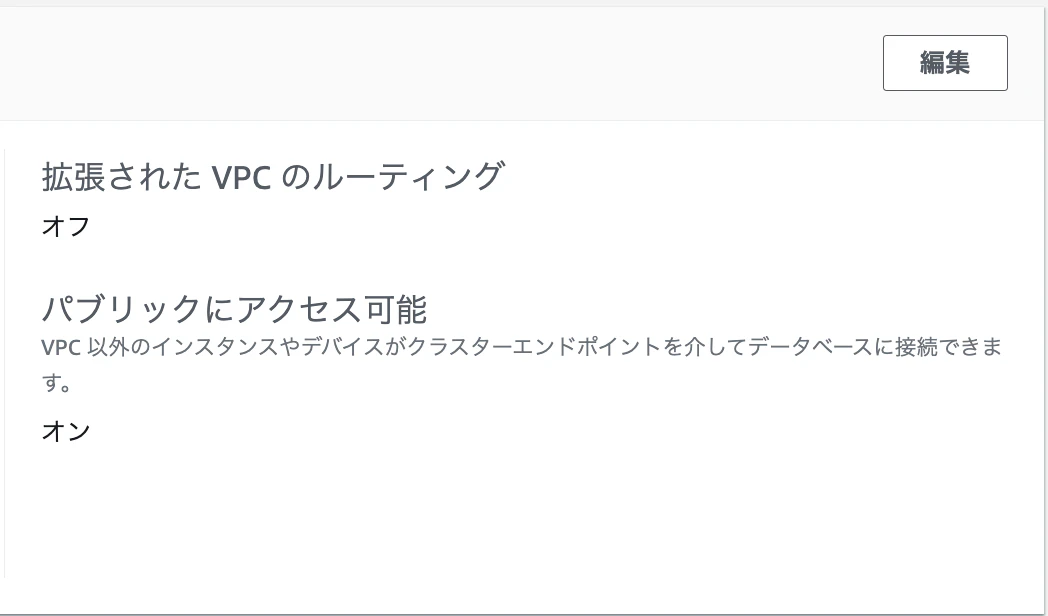
-
「VPCセキュリティグループ」をクリックすると、セキュリティグループの画面が表示されます。
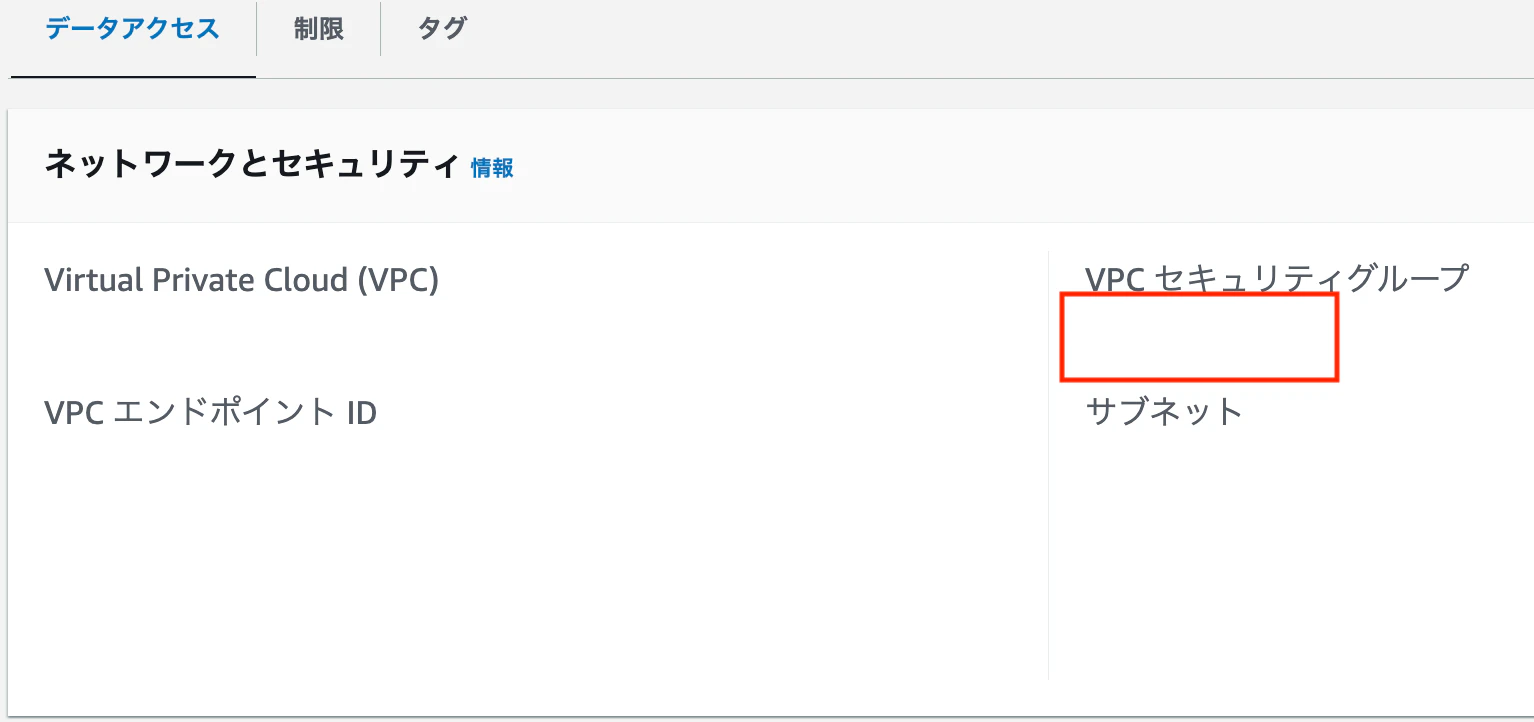
-
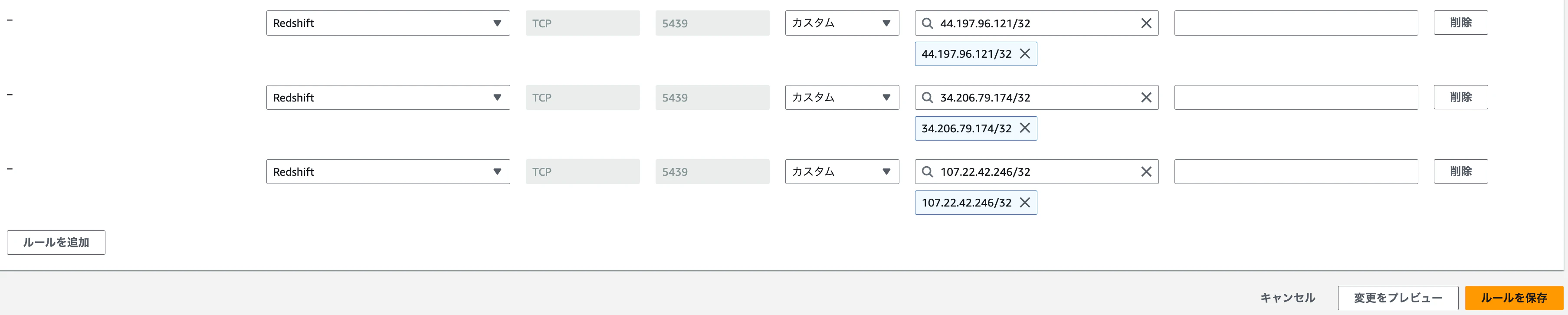
セキュリティグループを選択し、①「インバウンドルール」タブ、②「インバウンドのルールを編集」をクリックします。

-
下記のIPアドレスを追加し、「ルールを保存」をクリックします
- 44.197.96.121/32
- 34.206.79.174/32
- 107.22.42.246/32
サインアップ
- トップページで「Sign up」をクリックします
- Googleアカウントか、Emailアドレスでアカウントを作ります。

- ダッシュボードが表示されました。

Adding data source(s) (required)
-
ナビゲーションペインで「+Add Connection」をクリックします
-
「Redshift」をクリックします。

-
下記を入力し、「Save」をクリックします
- NickName:任意
- Host:エンドポイント
- Port:Redshiftのポート番号
- Username:作成したユーザ名
- Password:作成したユーザのパスワード
- Database:任意のDB

-
作成できたようです
-
「Actions」のプルダウンから「Test」をクリックします。
-
「Success」になりました

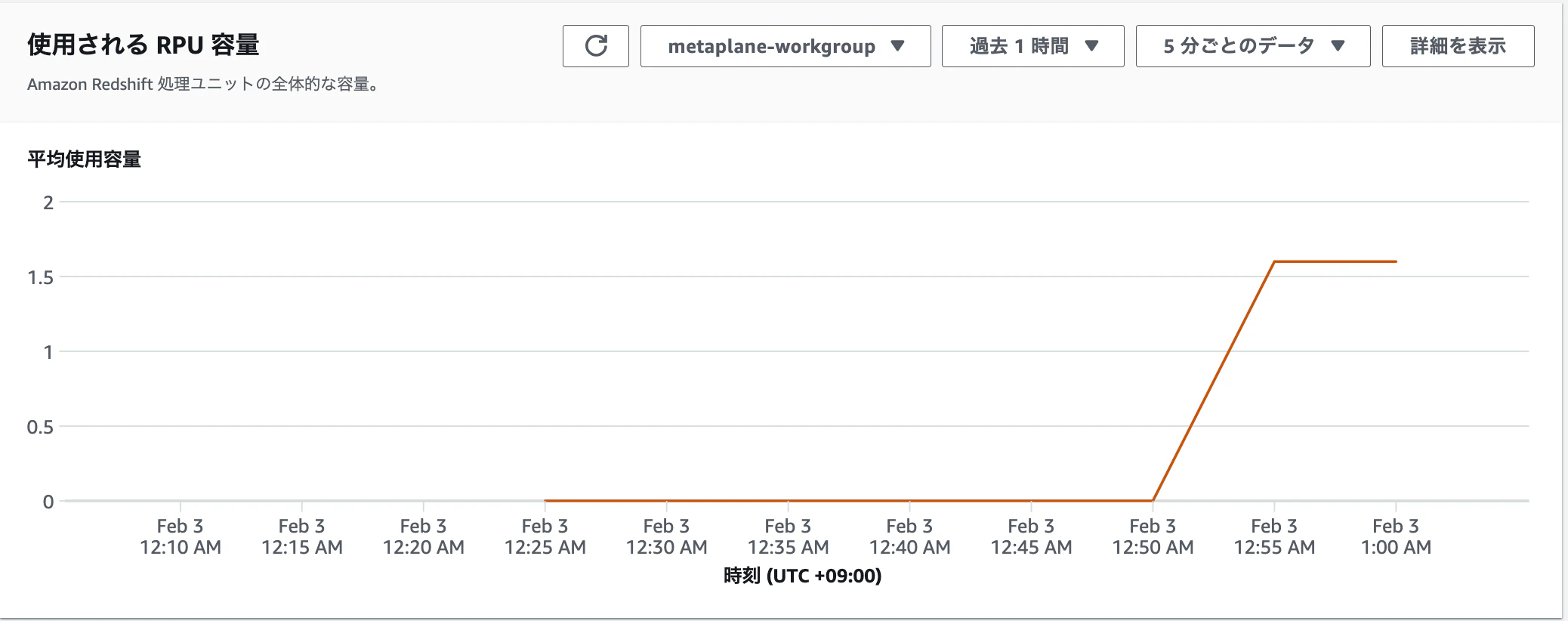
-
Redshiftのモニタリングでもリクエストが来ていることがわかります
Add Slack
-
ナビゲーションペインで、「Settings」をクリックします
-
「Slack」をクリックします。
-
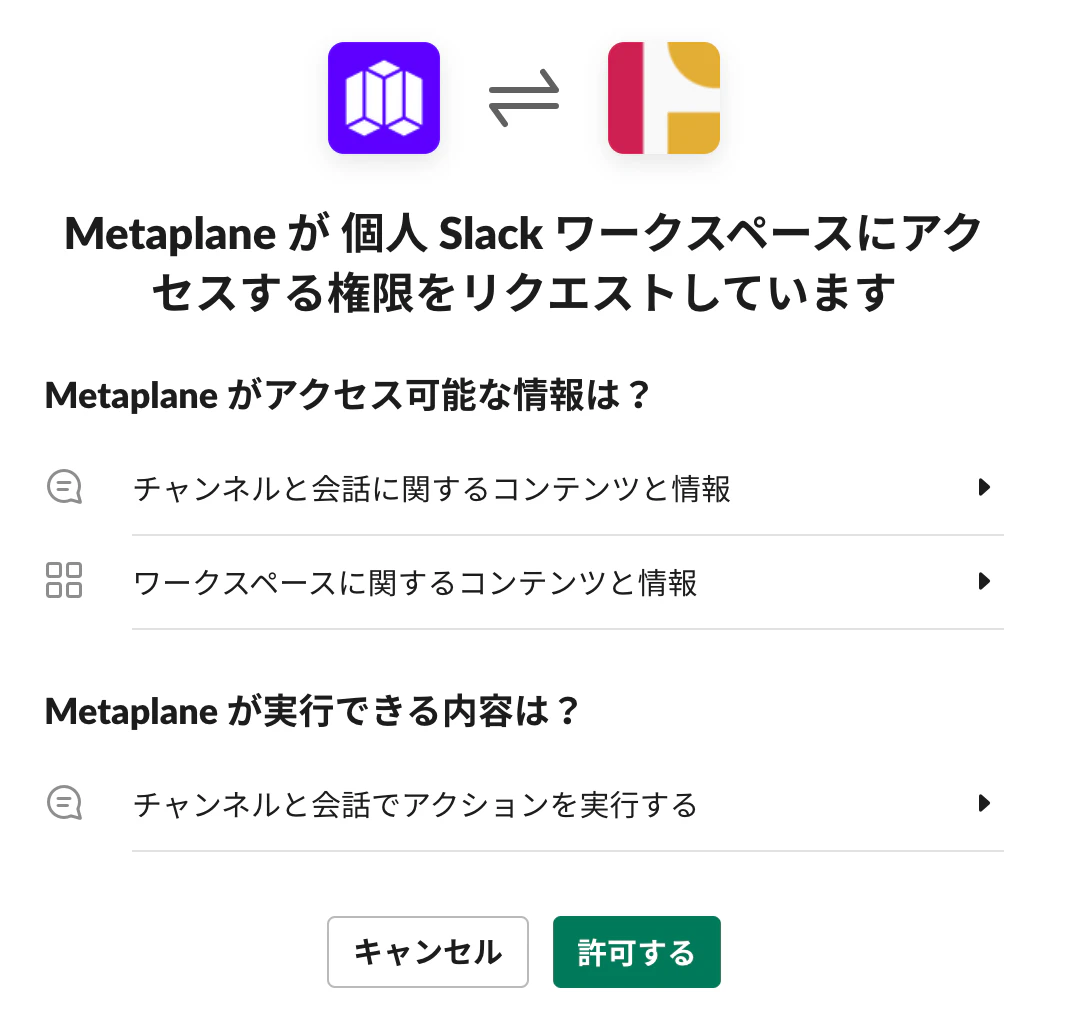
画面が起動されるので、ワークスペースのURLを入力し、「続行する」をクリックします。

-
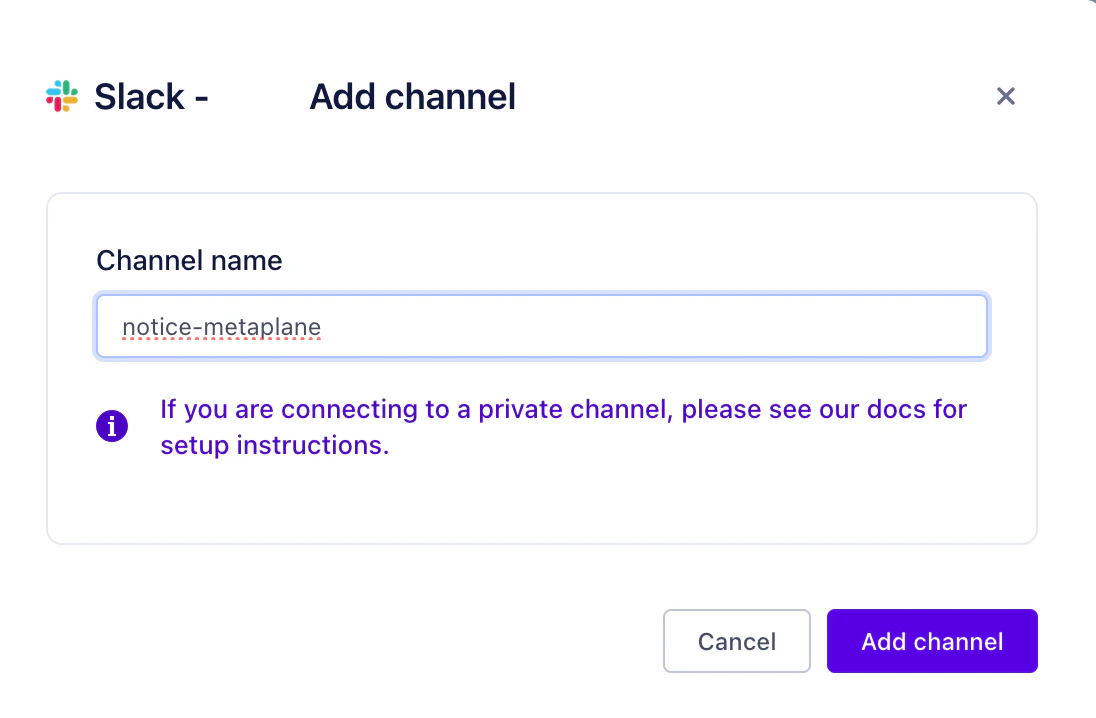
「許可する」をクリックします。
-
Channel nameを入力し「Add channel」をクリックします。
-
追加されました。
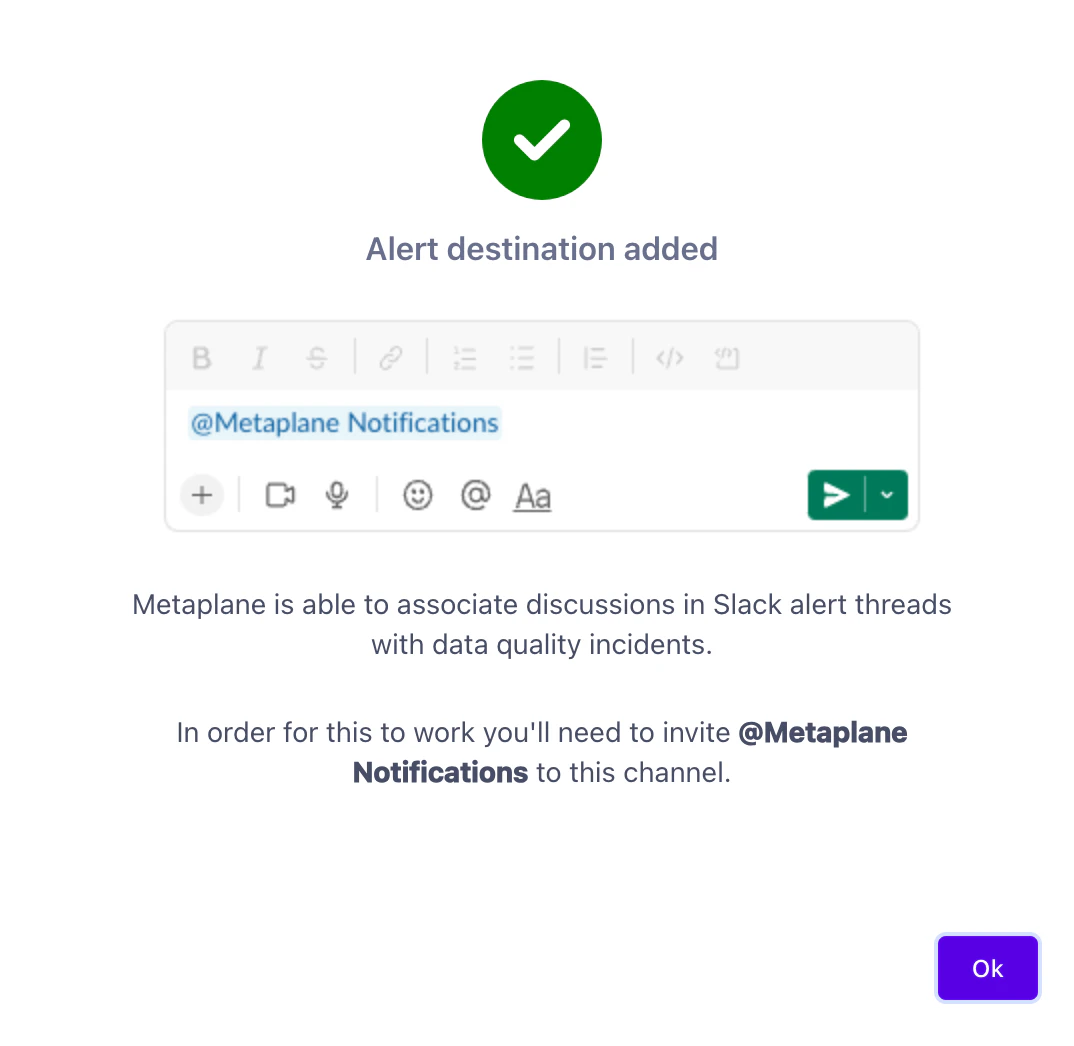
-
Slackにもメッセージが届きました。

考察
Metaplaneは比較的使いやすく、機能が豊富でした。今後も試してみたいと思います。
参考