背景・目的
以前の【Databricks】【初心者】DLTのチュートリアルを試してみたの続きで、Delta Live Tables(以降、DLTという。)について試してみます。
まとめ
- 上位のパイプラインからデータセットにアクセスするには下記の方法がある
- dlt.read
- spark.table
- spark.sql
概要
Delta Live Tables Python language referenceをもとに整理します。
制限事項
Delta Live Tables Pythonインターフェイスには次の制限があります:
- Python table関数とview関数はDataFrameを返す必要があります。DataFrameを操作する一部の関数はDataFrameを返さないため、使用しないでください。DataFrame変換は完全なデータフローグラフが解決された後に実行されるため、このような操作を使用すると、意図しない副作用が発生する可能性があります。これらの操作には、collect()、count()、toPandas()、save()、saveAsTable()などの関数が含まれます。ただし、このコードはグラフの初期化フェーズ中に1回実行されるため、これらの関数をtableまたはview関数定義の外に含めることができます。
- pivot()関数はサポートされていません。Sparkのpivotオペレーションでは、出力のスキーマを計算するために入力データの積極的な読み込みが必要です。この機能は、Delta Live Tablesではサポートされていません。
- table関数、view関数はDataFrameを返す
- DataFrameのうち、一部の関数はDataFrameを返さないので使用しない
- Transformは遅延評価により、想定外の動作になる可能性がある
- pivot関数はサポートされてない
dlt Pythonモジュールをインポートする
Delta Live TablesのPython関数は、dltモジュールで定義されています。Python APIを使用して実装されたパイプラインは、このモジュールをインポートする必要があります:
- dlgのPython関数は、dltモジュールで定義されている
- このモジュールをインポートする必要がある
import dlt
Delta Live Tablesマテリアライズドビューまたはストリーミングテーブルを作成する
Pythonでは、Delta Live Tablesは、定義クエリーに基づいてデータセットをマテリアライズドビューとして更新するかストリーミングテーブルとして更新するかを決定します。@tableデコレータは、マテリアライズドビューとストリーミングテーブルの両方を定義するために使用されます。
- DLTは、定義したクエリに基づきMviewかストリーミングテーブルとして更新するかを決定する
- @tableデコレーダーは、Mviewとストリーミングテーブルの両方を定義するために使用される
Pythonでマテリアライズドビューを定義するには、データソースに対して静的読み取りを実行するクエリーに@tableを適用します。ストリーミングテーブルを定義するには、データソースに対してストリーミング読み取りを実行するクエリーに@tableを適用します。どちらのデータセットタイプも、次のように同じ構文仕様を持っています:
- Mviewを定義するにはデータソースに対して静的読み取りを実行するクエリに@tableを適用する
- ストリーミングを定義するには、データソースに対してストリーミング読み取りを実行するクエリに@tableを適用する
import dlt
@dlt.table(
name="<name>",
comment="<comment>",
spark_conf={"<key>" : "<value", "<key" : "<value>"},
table_properties={"<key>" : "<value>", "<key>" : "<value>"},
path="<storage-location-path>",
partition_cols=["<partition-column>", "<partition-column>"],
schema="schema-definition",
temporary=False)
@dlt.expect
@dlt.expect_or_fail
@dlt.expect_or_drop
@dlt.expect_all
@dlt.expect_all_or_drop
@dlt.expect_all_or_fail
def <function-name>():
return (<query>)
実践
例:テーブルとビューを定義する
Pythonでテーブルまたはビューを定義するには、@dlt.viewまたは@dlt.tableデコレータを関数に適用します。関数名またはnameパラメーターを使用して、テーブルまたはビューの名前を割り当てることができます。次の例では、2つの異なるデータセットを定義しています。JSONファイルを入力ソースとして受け取るtaxi_rawというビューと、入力としてtaxi_rawビューを受け取るfiltered_dataというテーブルです:
- @dlt.viewまたは@dlt.tableデコレータを関数に適用しテーブルやビューを定義する
import dlt
@dlt.view
def taxi_raw():
return spark.read.format("json").load("/databricks-datasets/nyctaxi/sample/json/")
# Use the function name as the table name
#@dlt.table
#def filtered_data():
# return dlt.read("taxi_raw")
# Use the name parameter as the table name
@dlt.table(
name="filtered_data")
def create_filtered_data():
return dlt.read("taxi_raw")
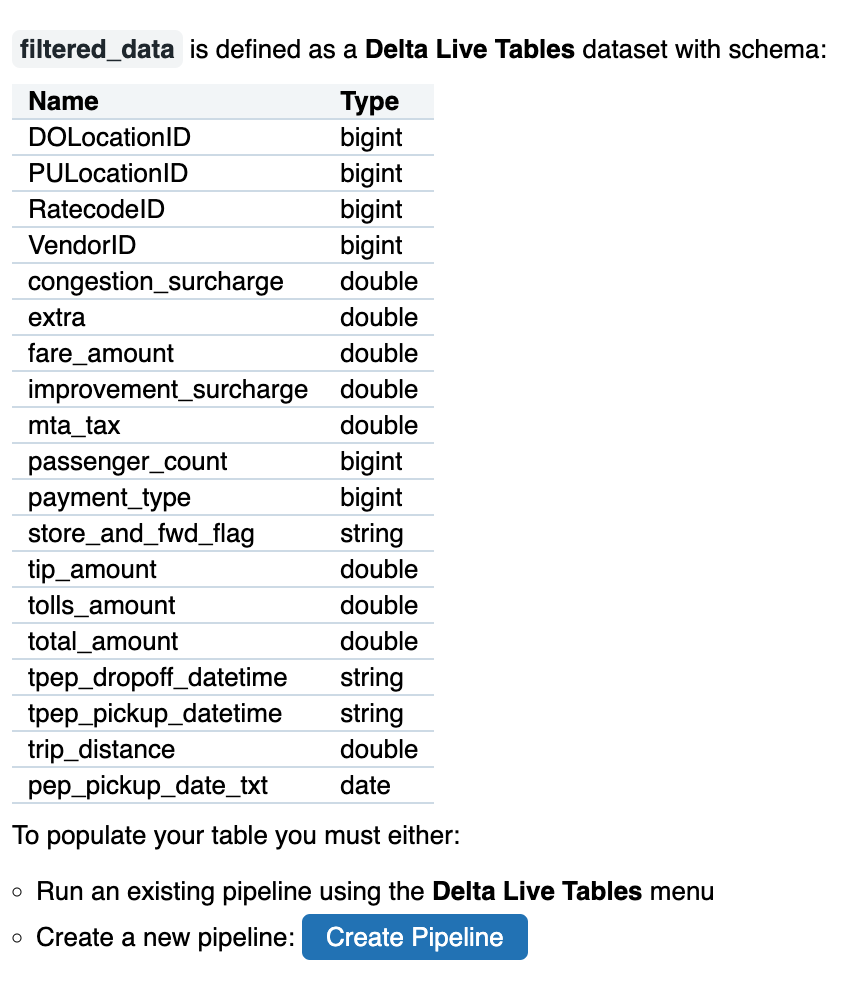
例:同じパイプラインで定義されたデータセットにアクセスする
外部データソースからの読み取りに加えて、Delta Live Tables read()関数を使用して、同じパイプラインで定義されているデータセットにアクセスできます。次の例は、read()関数を使用してcustomers_filteredデータセットを作成する方法を示しています:
- 外部データソースから読み取りに加えてDLTのread関数を使用して、同じパイプラインで定義されているデータセットにアクセス可能
-
まずは上記と同じdlt.readで試します。
@dlt.table def nyctaxi_raw(): return spark.read.format("json").load("/databricks-datasets/nyctaxi/sample/json/") @dlt.table def dlt_read(): return dlt.read("customers_raw")
spark.table()関数を使用して、同じパイプラインで定義されたデータセットにアクセスすることもできます。spark.table()関数を使用してパイプラインで定義されたデータセットにアクセスするときは、LIVE関数の引数でデータセット名の前にキーワードを追加します:
- sparkのtable関数を使用することで上記と同じことができる。
- LIVE関数の引数にデータセットキーワードを指定する
-
次にspark.table関数により読み込みます。
@dlt.table def nyctaxi_raw2(): return spark.read.format("json").load("/databricks-datasets/nyctaxi/sample/json/") @dlt.table def nyctaxi_raw3(): return spark.table("LIVE.nyctaxi_raw2")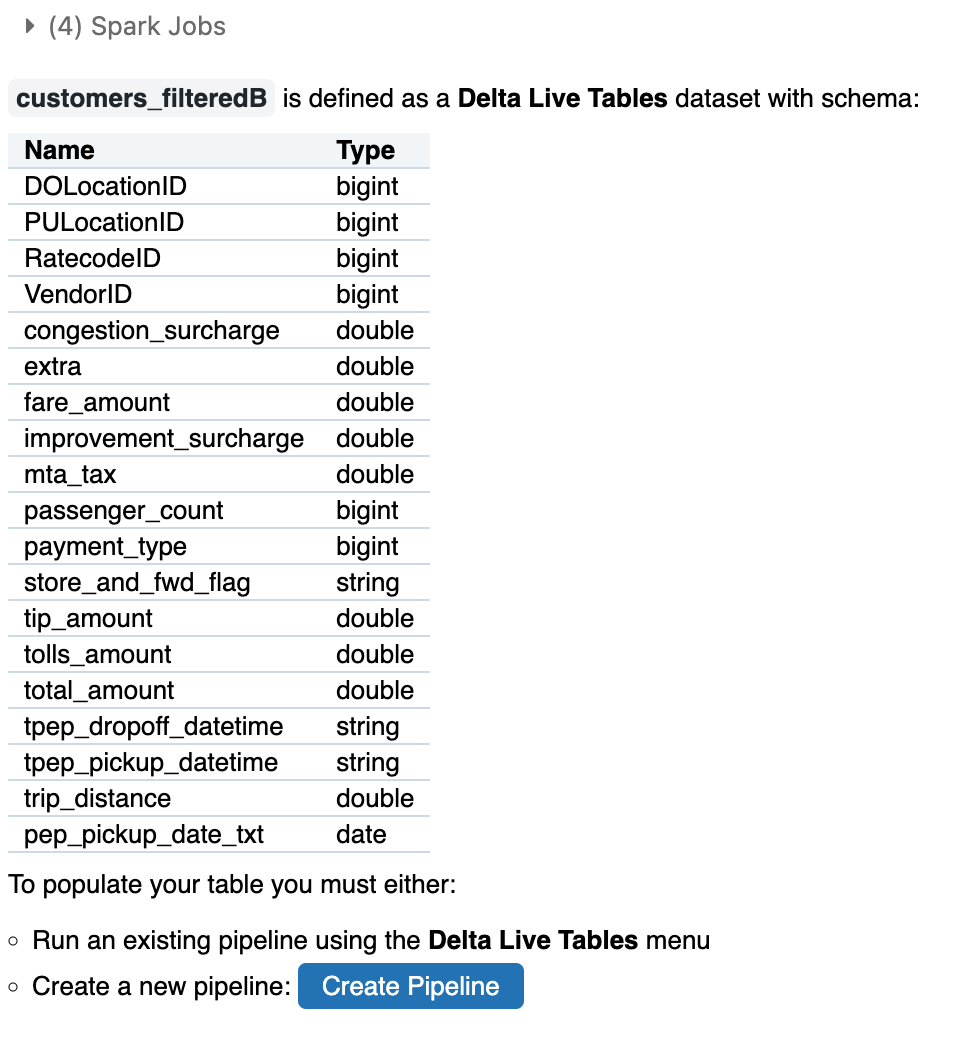
例:Unity Catalog テーブルからのバッチ インジェスト
Unity Catalog を使用するように構成されたパイプラインは、以下からデータを読み取ることができます。
- Unity Catalog マネージドテーブルと外部テーブル、ビュー、具体化されたビュー、ストリーミングテーブルがあります。
- テーブルとビューHive metastore 。
- Auto Loader cloud_files() 機能を使用して Unity Catalog 外部から読み取ります。
- Apache Kafka と Amazon Kinesis。
-
事前にUnityCatalogで作成したテーブルを確認します。
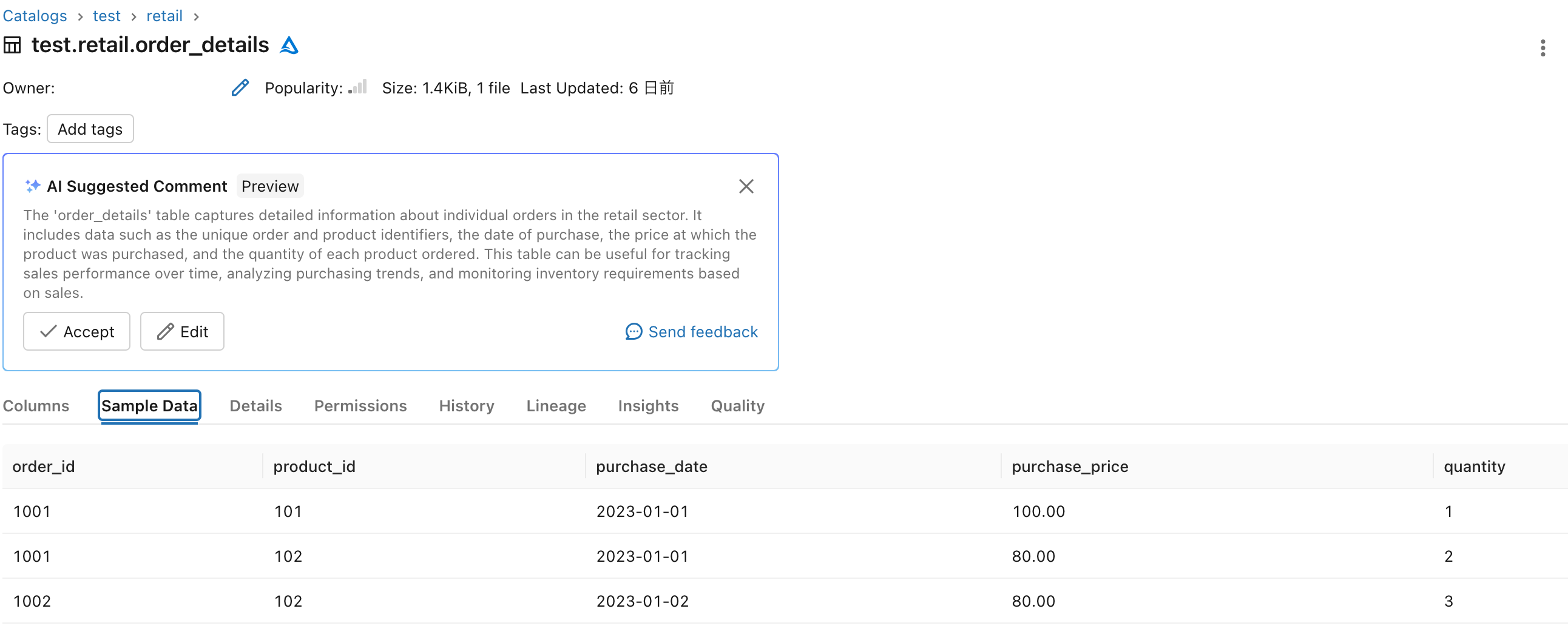
-
下記のコードを実行します。読み込めました。
import dlt @dlt.table def table_name(): df = spark.table("test.retail.order_details") df.printSchema() df.show() return df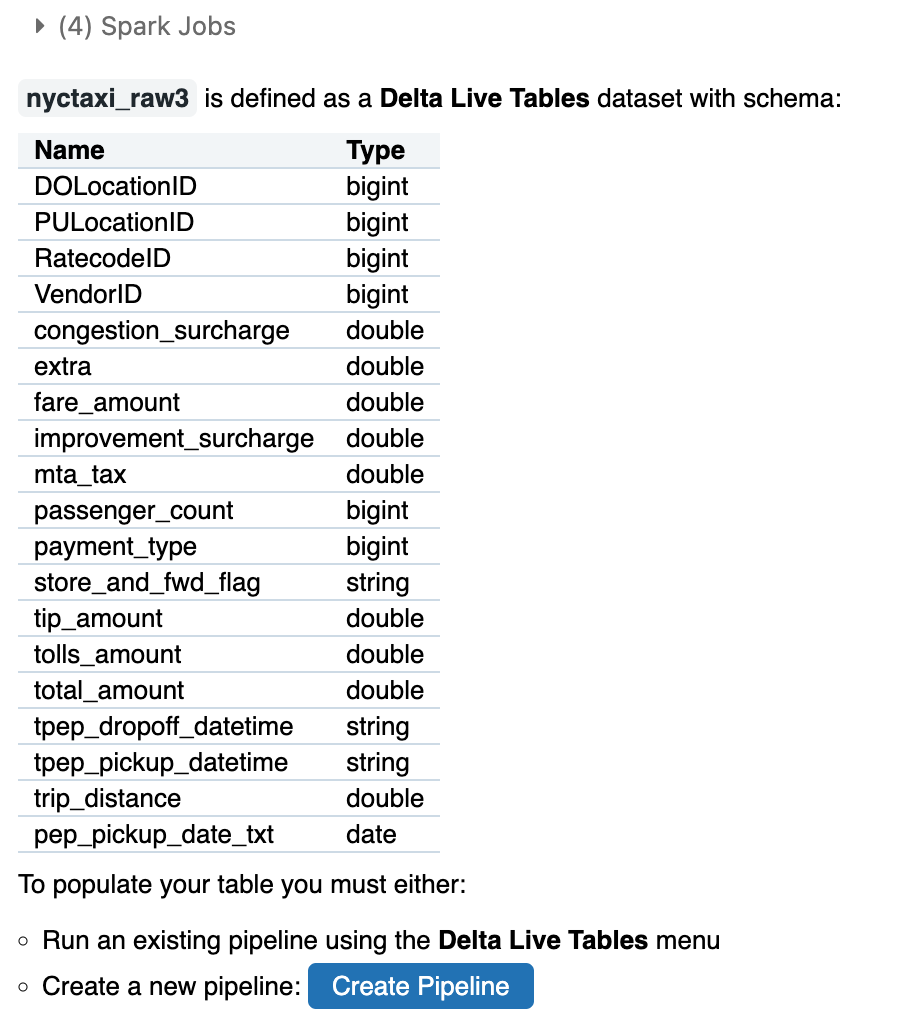
例:spark.sqlを使ってデータセットにアクセスする
クエリー関数でspark.sql式を使用してデータセットを返すこともできます。内部データセットから読み取るには、データセット名の前にLIVE.を追加します:
-
spark.sqlを使って読み込むこともできる
-
内部データセットから読み込むときにLIVEを使用する
@dlt.table def nyctaxi_sql(): return spark.sql("SELECT * FROM LIVE.nyctaxi_raw3")
例: 1 回限りのデータ バックフィルを実行する
次の例では、クエリーを実行して、ヒストリカルデータをストリーミングテーブルに追加します。
注
バックフィルクエリーがスケジュールされたベースまたは継続的に実行されるパイプラインの一部である場合に、真の 1 回限りのバックフィルを確保するには、パイプラインを一度実行した後にクエリーを削除します。 新しいデータがバックフィル ディレクトリに到着した場合に追加するには、クエリーをそのままにしておきます。
考察
今回は、ドキュメントに基づいてDelta Live Tables(DLT)について試してみました。次回はパイプラインの実行を試してみます。
参考