背景・目的
「【Databricks】Delta Live Tablesを試してみた」の続きでDLTを試してみます。
まとめ
下記にDLTの特徴を整理します。
- DLTモジュールをインポートして利用する
- DLTはノートブックのセルで対話的に実行するように設計されていない
- @dlt.table
- @dlt.tableデコレータは、関数により返されるDataFrameの結果を含むテーブルを作成するようにDLTに指示できる
- 関数定義の前に@dlt.tableデコレータを追加する
- 上流から読み取るには
- dlt.readを使用する
- 現在のDLTパイプラインで宣言されている他のデータセットからデータを読み取ることが可能
- 更新を実行前に、DLTにより自動的に解決される依存関係が作成される
概要
チュートリアル:Delta Live TablesでPythonを使用してデータパイプラインを宣言するを元に整理します。
Delta Live TablesのPython構文は、dltモジュールを通じてインポートされたデコレータ関数のセットで標準のPySparkを拡張します。
- DLTは、DLTモジュールを通じてインポートされたデコレータ関数でPySparkを拡張する
注
- Delta Live Tablesソースコードファイル内で言語を混在させることはできません。パイプラインでは、複数のノートブックや異なる言語のファイルを使用できます。
- この例のコードを使用するには、パイプラインの作成時にストレージオプションとして[Hive metastore]を選択します。この例ではDBFSからデータを読み取るため、ストレージオプションとしてUnity Catalogを使用するように構成されたパイプラインでは、この例を実行できません。
Delta Live TablesのPythonクエリーはどこで実行しますか?
ノートブックまたはPython ファイルを使用してDelta Live Tables Pythonクエリーを作成できますが、Delta Live Tablesはノートブックのセルで対話的に実行するように設計されていません。
- DLTはノートブックのセルで対話的に実行するように設計されていない
Delta Live Tablesは、多くのPythonスクリプトとは重要な点で異なります。Delta Live Tablesデータセットを作成するために、データの取り込みと変換を実行する関数を呼び出す必要はありません。代わりに、Delta Live Tablesは、パイプラインにロードされたすべてのファイル内のdltモジュールからのデコレータ関数を解釈し、データフローグラフを構築します。
- DLTを作成するために、データの取り込みとTransformを実行する関数を呼び出す必要がない
- DLTはロードされたすべてのファイル内のdltモジュールからデコレータ関数を解釈しデータフローグラフを構築する。
実践
Pythonを使用したDelta Live Tablesデータパイプラインの宣言
このチュートリアルでは、Python構文を使用して、Wikipediaクリックストリームデータを含むデータセット上でDelta Live Tablesパイプラインを宣言して、次のことを行う方法を示します:
- 生のJSONクリックストリームデータをテーブルに読み取ります。
- 生データテーブルからレコードを読み取り、Delta Live Tables Expectationsを使用して、クレンジングされたデータを含む新しいテーブルを作成します。
- クレンジングされたデータテーブルのレコードを使用して、派生データセットを作成するDelta Live Tablesクエリーを作成します。
このコードは、メダリオンアーキテクチャの簡略化された例を示しています。「メダリオンレイクハウスの建築とは?」を参照してください。
Python コードをコピーし、新しい Python ノートブックに貼り付けます。 コード例は、ノートブックの 1 つのセルまたは複数のセルに追加できます。 ノートブックを作成するためのオプションを確認するには、「 ノートブックの作成」を参照してください。
Delta Live Tablesモジュールをインポートする
すべてのDelta Live Tables Python APIは、dlt モジュールに実装されています。Pythonノートブックやファイルの先頭でdltモジュールを明示的にインポートする。
次の例は、このインポートと、pyspark.sql.functionsのインポートステートメントを示しています。
- DLTのAPIは、dltモジュールに実装している。
- Pythonのノートブックやファイルの戦闘ではdltモジュールを明示的にインポートする
import dlt
from pyspark.sql.functions import *
任意のPython文を実行する
ノートブックでは、Delta Live Tablesコードと一緒にPython変数と関数を定義できます。すべてのPythonロジックは、Delta Live Tablesがパイプライングラフを解決するときに実行されます。
次のコードは、後のステップでJSONデータファイルをロードするために使用されるテキスト変数を宣言します:
- PythonコードはDLTがパイプライングラフを解決するときに実行される
json_path = "/databricks-datasets/wikipedia-datasets/data-001/clickstream/raw-uncompressed-json/2015_2_clickstream.json"
オブジェクトストレージ内のファイルからのテーブルの作成
Delta Live Tables では、Databricks でサポートされているすべての形式からのデータの読み込みがサポートされています。 「データ形式のオプション」を参照してください。
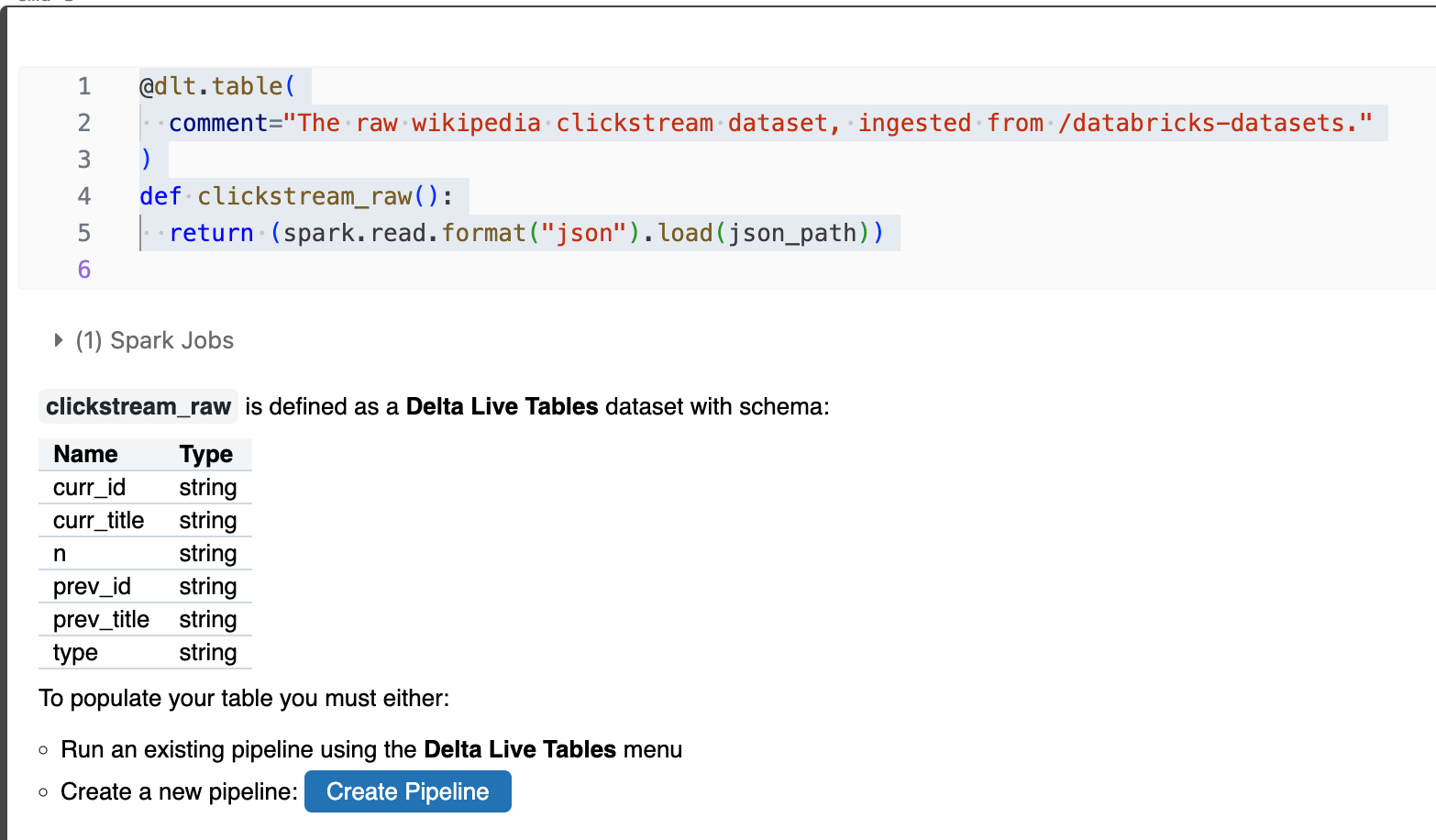
@dlt.table デコレータは、関数によって返されたDataFrameの結果を含むテーブルを作成するようにDelta Live Tablesに指示します。Delta Live Tablesに新しいテーブルを登録するには、Spark DataFrameを返すPython関数定義の前に@dlt.tableデコレータを追加します。次の例は、関数名をテーブル名として使用し、テーブルに説明的なコメントを追加する方法を示しています。
- @dlt.tableデコレータは、関数により返されるDataFrameの結果を含むテーブルを作成するようにDLTに指示できる
- 関数定義の前に@dlt.tableデコレータを追加する
@dlt.table(
comment="The raw wikipedia clickstream dataset, ingested from /databricks-datasets."
)
def clickstream_raw():
return (spark.read.format("json").load(json_path))
パイプラインの上流のデータセットからテーブルを追加する
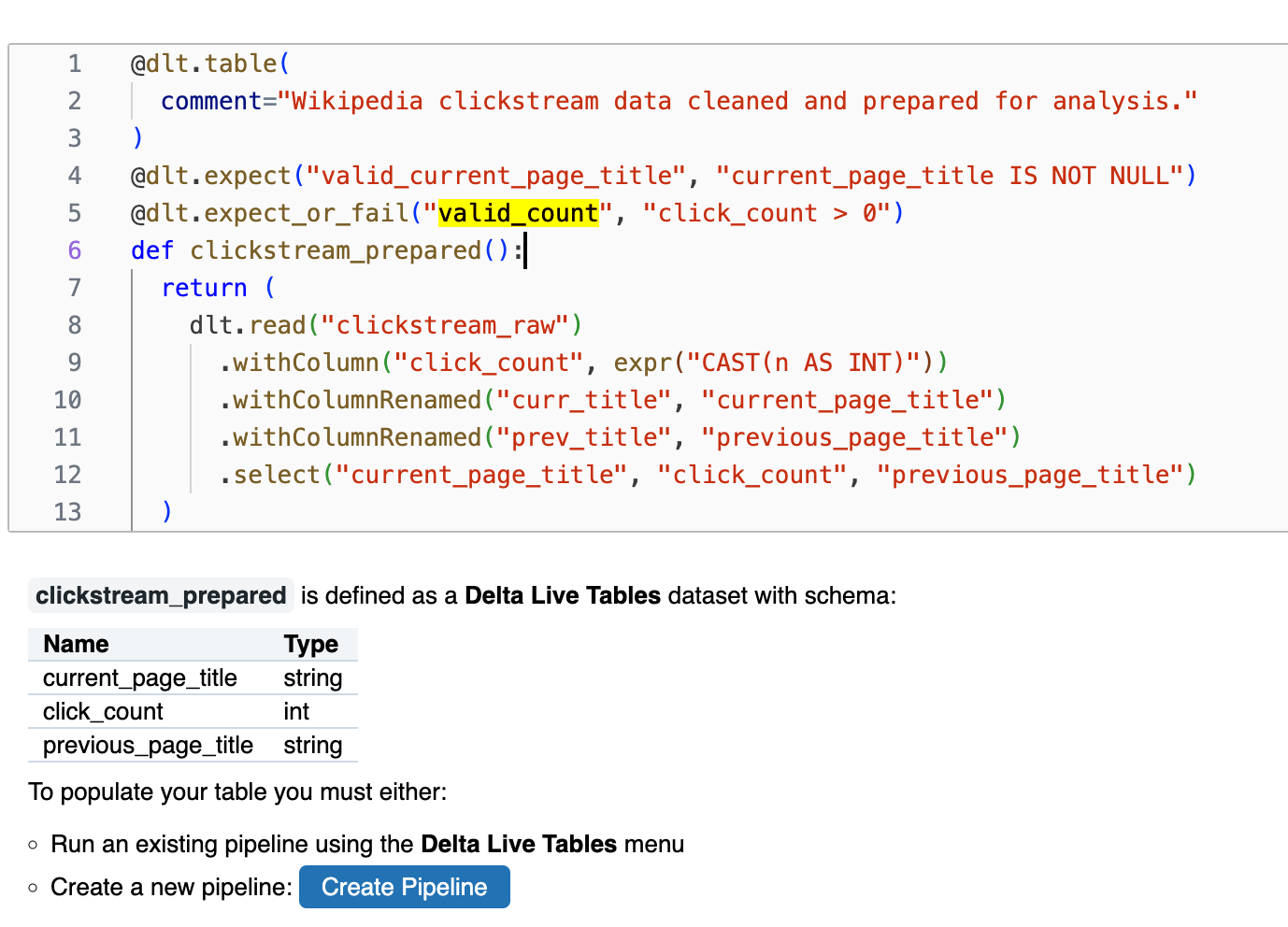
dlt.read()を使用して、現在のDelta Live Tablesパイプラインで宣言されている他のデータセットからデータを読み取ることができます。この方法で新しいテーブルを宣言すると、更新を実行する前にDelta Live Tablesによって自動的に解決される依存関係が作成されます。次のコードには、期待に基づいてデータ品質を監視および強制する例も含まれています。「Delta Live Tablesによるデータ品質の管理」を参照してください。
- dlt.readを使用し、現在のDLTパイプラインで宣言されている他のデータセットからデータを読み取ることが可能
- 更新を実行前に、DLTにより自動的に解決される依存関係が作成される
- 下記には、品質・監視を強制する例もある
@dlt.table(
comment="Wikipedia clickstream data cleaned and prepared for analysis."
)
@dlt.expect("valid_current_page_title", "current_page_title IS NOT NULL")
@dlt.expect_or_fail("valid_count", "click_count > 0")
def clickstream_prepared():
return (
dlt.read("clickstream_raw")
.withColumn("click_count", expr("CAST(n AS INT)"))
.withColumnRenamed("curr_title", "current_page_title")
.withColumnRenamed("prev_title", "previous_page_title")
.select("current_page_title", "click_count", "previous_page_title")
)
強化されたデータビューを含むテーブルを作成する
Delta Live Tablesはパイプラインの更新を一連の依存関係グラフとして処理するので、特定のビジネスロジックを含むテーブルを宣言することで、ダッシュボード、BI、分析を強化する高度に強化されたビューを宣言できます。
- ビジネスロジックを含むテーブルを宣言し、ダッシュボード、BI、分析を強化する高度なビューを宣言できる
Delta Live Tablesテーブルは、概念的には具体化されたビューに相当します。Sparkの従来のビューは、ビューがクエリーされるたびにロジックを実行しますが、Delta Live Tablesテーブルはクエリー結果の最新バージョンをデータファイルに保存します。Delta Live Tablesはパイプライン内のすべてのデータセットの更新を管理するため、具体化されたビューの待機時間要件に合わせてパイプラインの更新をスケジュールし、これらのテーブルに対するクエリーに使用可能な最新バージョンのデータが含まれていることを確認できます。
- DLTテーブルは、クエリ結果の最新バージョンをデータファイルに保存する。
- 最新バージョンのデータが含まれていることを確認できる
以下のコードで定義されたテーブルは、パイプラインの上流データから派生したマテリアライズドビューとの概念的な類似性を示しています:
@dlt.table(
comment="A table containing the top pages linking to the Apache Spark page."
)
def top_spark_referrers():
return (
dlt.read("clickstream_prepared")
.filter(expr("current_page_title == 'Apache_Spark'"))
.withColumnRenamed("previous_page_title", "referrer")
.sort(desc("click_count"))
.select("referrer", "click_count")
.limit(10)
)

考察
今回は、DLTのチュートリアルの沿って実際に動かしてみました。まだまだ特徴がわかっていないので今後も試してみます。
参考