背景・目的
最近、Delta Live Table(DLT)にふれる機会が増えてきたので、特徴を整理し簡単に試してみます。
まとめ
下記の特徴があります。
- DLTは、下記を管理します。
- タスクオーケストレーション
- クラスタ管理
- 監視
- データ品質
- エラー処理
- DLTデータセットは、下記を保持するビューです。
- ストリーミングテーブル
- マテビュー
- 宣言クエリの結果
- ストリーミング
- ストリーミング、またはインクリメンタルデータ処理が行えるDeltaテーブル
- 各行を一回だけ処理して、増大するデータセットを処理する
- データの鮮度と低レイテンシーを必要とするパイプラインに最適。
- 追加専用データソース用
- マテリアライズドビュー
- 結果が事前計算されているビュー
- パイプラインの更新スケジュールに従って更新される。
- マテビューは、あらゆる変更を処理できる
- パイプラインの更新の都度、クエリ結果が再計算されるため、上流のデータセットの変更が反映される
- DLTでは、マテビューをDeltaテーブルとして実装する
- 更新の効率的な運用に関連する複雑さを抽象化する。
- ビュー
- ソースデータセットからクエリされた結果を計算する
- DLTはビューをカタログに公開しない。定義されたパイプライン内のみ参照することができる
- データ品質制約を強制、ダウンストリームクエリを駆動するデータセットを変換する用途
概要
Delta Live Tablesとは?をもとに整理します。
Delta Live Tables:信頼性が高く、保守可能で、テスト可能なデータ処理パイプラインを構築するためのフレームワーク。データに対して実行する変換を定義すると、Delta Live Tablesがタスクオーケストレーション、クラスター管理、監視、データ品質、エラー処理を管理します。
- DLTは、下記を管理する。
- タスクオーケストレーション
- クラスタ管理
- 監視
- データ品質
- エラー処理
一連の個別のApache Sparkタスクを使用してデータパイプラインを定義する代わりに、システムが作成して最新の状態に保つ必要があるストリーミングテーブルとマテリアライズドビューを定義します。Delta Live Tablesは、各処理ステップで定義したクエリーに基づいてデータがどのように変換されるかを管理します。Delta Live Tablesの期待値を使用してデータ品質を強制することもできます。これにより、期待されるデータ品質を定義し、その期待値を満たさないレコードの処理方法を指定できます。
- パイプラインの定義の代わりにストリーミングテーブルと、マテリアライズドビューを定義する。
Delta Live Tablesデータセットとは?
Delta Live Tablesデータセットは、ストリーミングテーブル、マテリアライズドビュー、および宣言クエリーの結果として維持されるビューです。
- DLTデータセットは、下記を保持するビュー
- ストリーミングテーブル
- マテビュー
- 宣言クエリの結果
次のテーブルは、各データセットがどのように処理されるかを示しています:
| データセットのタイプ | 定義されたクエリーによってレコードが処理される方法とは? |
|---|---|
| ストリーミングテーブル | 各レコードは一度だけ処理されます。これは、追加専用のソースを前提としています。 |
| マテリアライズドビュー | レコードは必要に応じて処理され、現在のデータ状態の正確な結果が返されます。マテリアライズドビューは、更新、削除、または集計を行うデータソースと、変更データキャプチャ処理(CDC)に使用する必要があります。 |
| ビュー | レコードは、ビューがクエリーされるたびに処理されます。パブリックデータセットに公開すべきではない中間変換やデータ品質チェックにはビューを使用します。 |
ストリーミングテーブル
ストリーミングテーブルは、ストリーミングまたは増分データ処理の追加サポートを備えたDeltaテーブルです。ストリーミングテーブルを使用すると、各行を1回だけ処理して、増大するデータセットを処理できます。ほとんどのデータセットは時間の経過とともに継続的に増加するため、ストリーミングテーブルはほとんどの取り込みワークロードに適しています。ストリーミングテーブルは、データの鮮度と低遅延を必要とするパイプラインに最適です。ストリーミングテーブルは、新しいデータが到着するたびに結果を増分計算して、更新のたびにすべてのソースデータを完全に再計算する必要がなく、結果を最新の状態に保つことができるため、大規模な変換にも役立ちます。ストリーミングテーブルは、追加専用のデータソース用に設計されています。
- ストリーミング、またはインクリメンタルデータ処理が行えるDeltaテーブル
- 各行を一回だけ処理して、増大するデータセットを処理する
- データの鮮度と低レイテンシーを必要とするパイプラインに最適。
- 追加専用データソース用
マテリアライズドビュー
マテリアライズドビュー(またはライブテーブル)は、結果が事前計算されているビューです。マテリアライズドビューは、それが含まれるパイプラインの更新スケジュールに従って更新されます。マテリアライズドビューは、入力のあらゆる変更を処理できるため、強力です。パイプラインが更新されるたびに、クエリー結果が再計算され、コンプライアンス、修正、集計、または一般的なCDCによって発生した可能性のある上流のデータセットの変更が反映されます。Delta Live TablesはマテリアライズドビューをDeltaテーブルとして実装しますが、更新の効率的な適用に関連する複雑さを抽象化して、ユーザーがクエリーの作成に集中できるようにします。
- 結果が事前計算されているビュー
- パイプラインの更新スケジュールに従って更新される。
- マテビューは、あらゆる変更を処理できる
- パイプラインの更新の都度、クエリ結果が再計算されるため、上流のデータセットの変更が反映される
- DLTでは、マテビューをDeltaテーブルとして実装する
- 更新の効率的な運用に関連する複雑さを抽象化する。
ビュー
Databricksのすべてのビューは、ソースデータセットからクエリーされた結果を計算します。Delta Live Tablesはビューをカタログに公開しないため、ビューは定義されたパイプライン内でのみ参照することができます。ビューは、エンドユーザーやシステムに公開されるべきでない中間クエリーとして有用です。Databricksは、データ品質制約を強制したり、複数のダウンストリームクエリーを駆動するデータセットを変換して充実させるためにビューを使用することを推奨しています。
- ソースデータセットからクエリされた結果を計算する
- DLTはビューをカタログに公開しない。定義されたパイプライン内のみ参照することができる
- データ品質制約を強制、ダウンストリームクエリを駆動するデータセットを変換する用途
Delta Live Tablesパイプラインとは?
パイプラインは、Delta Live Tablesでデータ処理ワークフローを構成および実行するために使用されるメインユニットです。
パイプラインには、PythonまたはSQLソースファイルで宣言されたマテリアライズドビューとストリーミングテーブルが含まれています。Delta Live Tablesは、これらのテーブル間の依存関係を推測し、更新が正しい順序で行われることを保証します。Delta Live Tablesは、データセットごとに現在の状態と望ましい状態を比較し、効率的な処理方法を使用してデータセットの作成または更新を進めます。
- パイプラインは、DLTでデータ処理ワークフローを構成及び実行するために使用するために使用するメインユニット
- 下記が含まれている
- Python、SQLで宣言されたマテビュー
- ストリーミングテーブル
- 更新が正しい順序で行われることを保証する
- DLTは、はデータセットごとに現在の状態と望ましい状態を比較し、効率的な処理方法を使用してデータセットの作成又は更新する
Delta Live Tablesパイプラインの設定は、次の2つの大きなカテゴリに分類されます。
- Delta Live Tables構文を使用してデータセットを宣言するノートブックまたはファイル(ソースコードまたはライブラリと呼ばれます)のコレクションを定義する構成。
- パイプラインのインフラストラクチャ、更新の処理方法、ワークスペースへのテーブルの保存方法を制御する設定。
- DLT構文を使用し、データセットを宣言するノートブックまたはファイル
- パイプラインのインフラ、更新の処理方法、ワークスペースへのテーブルの保存方法を制御する
ほとんどの構成はオプションですが、特に運用パイプラインを構成する場合は、注意が必要です。これらには以下が含まれます:
- パイプラインの外部でデータを利用できるようにするには、Hive metastoreに公開するターゲットスキーマ、またはUnity Catalogに公開するターゲットカタログとターゲットスキーマを宣言する必要があります。
- データアクセス許可は、実行に使用されるクラスターを通じて構成されます。データソースとターゲットとなるストレージの場所(指定されている場合)に対して適切なアクセス許可がクラスターに構成されていることを確認してください。
- パイプラインの外部でデータを利用するには、下記が必要
- Hive metastore
- Unity Catalog
- データアクセス許可は、実行に使用されるクラスタを通じて構成される
- データソースとターゲットとなるストレージのロケーションに対して適切なアクセス許可がクラスタに構成されていること
パイプライン更新とは?
パイプラインはインフラストラクチャをデプロイし、更新の開始時にデータの状態を再計算します。更新プログラムは、次の処理を行います:
- 正しい構成でクラスターを開始します。
- 定義されているすべてのテーブルとビューを検出し、無効な列名、欠落している依存関係、構文エラーなどの分析エラーがないかチェックします。
- 使用可能な最新のデータでテーブルとビューを作成または更新します。
Delta Live Tablesによるデータの取り込み
Delta Live Tablesは、Databricksで利用可能な全てのデータソースをサポートしています。
Databricksでは、ほとんどの取り込みユースケースでストリーミングテーブルを使用することをお勧めします。クラウドオブジェクトストレージに到着するファイルの場合、DatabricksはAuto Loaderを推奨します。Delta Live Tablesを使用して、ほとんどのメッセージバスからデータを直接取り込むことができます。
- DLTはDatabricksで利用可能なすべてのデータソースをサポートしている
- 取り込みユースケースで、ストリーミングテーブルを推奨
- クラウドオブジェクトストレージに到着するファイルの場合、Auto Loaderを推奨
- DLTを使用して、ほとんどのメッセージバスからデータを直接取り込むことができる
データ品質の監視と実施
期待値を使って、データセットの内容に関するデータ品質管理を指定することができます。従来のデータベースにおけるCHECK制約が、制約に不合格となったレコードの追加を阻止するのとは異なり、期待値はデータ品質要件に不合格となったデータを処理する際の柔軟性を提供します。この柔軟性により、乱雑であることが予想されるデータや、厳格な品質要件を満たさなければならないデータを処理し、保存することができます。Delta Live Tablesでデータ品質を管理するを参照してください。
- 期待値を使って、データセットの内容に関するデータ品質管理を指定することが可能
- 不合格になったデータを処理する際の柔軟性を提供する
Delta Live TablesとDelta Lakeにはどのような関係がありますか?
Delta Live Tablesは、Delta Lakeの機能を拡張します。Delta Live Tablesによって作成および管理されるテーブルはDeltaテーブルであるため、Delta Lakeによって提供されるのと同じ保証と機能が備えられています。
- DLTは、Delta Lakeの機能を拡張する
Delta Live Tablesによって実行されるメンテナンスタスク
Delta Live Tables は、テーブルが更新されてから 24 時間以内にメンテナンスタスクを実行します。 メンテナンスにより、古いバージョンのテーブルを削除することで、クエリーのパフォーマンスを向上させ、コストを削減できます。 デフォルトでは、システムは完全な 最適化 操作を実行してから VACUUM を実行します。 テーブルの OPTIMIZE を無効にするには、テーブルの テーブル プロパティ で pipelines.autoOptimize.managed = false を設定します。メンテナンス タスクは、メンテナンス タスクがスケジュールされる前の 24 時間以内にパイプラインの更新が実行された場合にのみ実行されます。
- テーブルが更新されてから、24H以内にメンテナンスタスクを実行される。
- 古いバージョンのテーブルを削除し、クエリのパフォーマンスを向上させる
- デフォルトでは、システムは最適化してからVACCMを実行する
制限事項
次の制限が適用されます:
- Delta Live Tablesによって作成および更新されるテーブルはすべてDeltaテーブルである。
- Delta Live Tablesテーブルは1回だけ定義できます。つまり、すべてのDelta Live Tablesパイプラインで1つのオペレーションのターゲットにのみ設定できる。
- ID 列は、 APPLY CHANGES INTO のターゲットであるテーブルではサポートされず、具体化されたビューの更新中に再計算される可能性があります。 このため、Databricks では、ストリーミング テーブルで ID 列のみを使用することをお勧めします Delta Live Tables。 Delta Lakeでの ID 列の使用を参照してください。
- Databricksワークスペースは、パイプラインの同時更新が100件に制限されている。
- DLTにより作成されるテーブルはDeltaテーブル
- DLTテーブルは一回だけ定義できる。
- すべてのDLTパイプラインで1つのオペレーションのターゲットにのみ設定できる
- ID列は、APPLY CHANGES INTOターゲットであるテーブルではサポートされない
- パイプラインの同時更新は100件
実践
チュートリアル:Delta Live TablesでPythonを使用してデータパイプラインを宣言する
- Databricksにワークスペースにログインします。
- ナビゲーションペインで「Workspace」をクリックします。
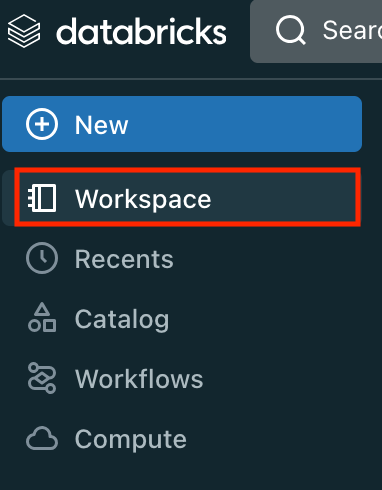
- 「Add」を選択し、「Notebook」をクリックします。
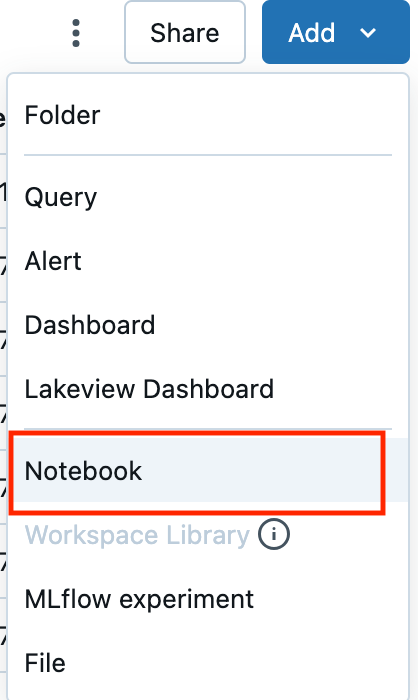
Delta Live Tablesモジュールをインポートする
Delta Live Tables Python APIは、dlt モジュールに実装されています。
- 明示的にインポートします。
import dlt from pyspark.sql.functions import *
オブジェクトストレージ内のファイルからのテーブルの作成
Delta Live Tables では、Databricks でサポートされているすべての形式からのデータの読み込みがサポートされています。
@dlt.table デコレータは、関数によって返されたDataFrameの結果を含むテーブルを作成するようにDelta Live Tablesに指示します。Delta Live Tablesに新しいテーブルを登録するには、Spark DataFrameを返すPython関数定義の前に@dlt.tableデコレータを追加します。次の例は、関数名をテーブル名として使用し、テーブルに説明的なコメントを追加する方法を示しています。
- オブジェクトストレージ内のファイルから読む
json_path = "/databricks-datasets/wikipedia-datasets/data-001/clickstream/raw-uncompressed-json/2015_2_clickstream.json" @dlt.table( comment="load test.json" ) def load_raw(): return (spark.read.format("json").load(json_path))
パイプラインの上流のデータセットからテーブルを追加する
dlt.read()を使用して、現在のDelta Live Tablesパイプラインで宣言されている他のデータセットからデータを読み取ることができます。この方法で新しいテーブルを宣言すると、更新を実行する前にDelta Live Tablesによって自動的に解決される依存関係が作成されます。次のコードには、期待に基づいてデータ品質を監視および強制する例も含まれています。「Delta Live Tablesによるデータ品質の管理」を参照してください。
-
dlt.readを使用すると、DLTパイプラインで宣言された他のデータセットからデータを読み取ることができる
- dlt.expectは、無効な記録を保持する
- dlt.expect_or_failは、無効なレコードで失敗する
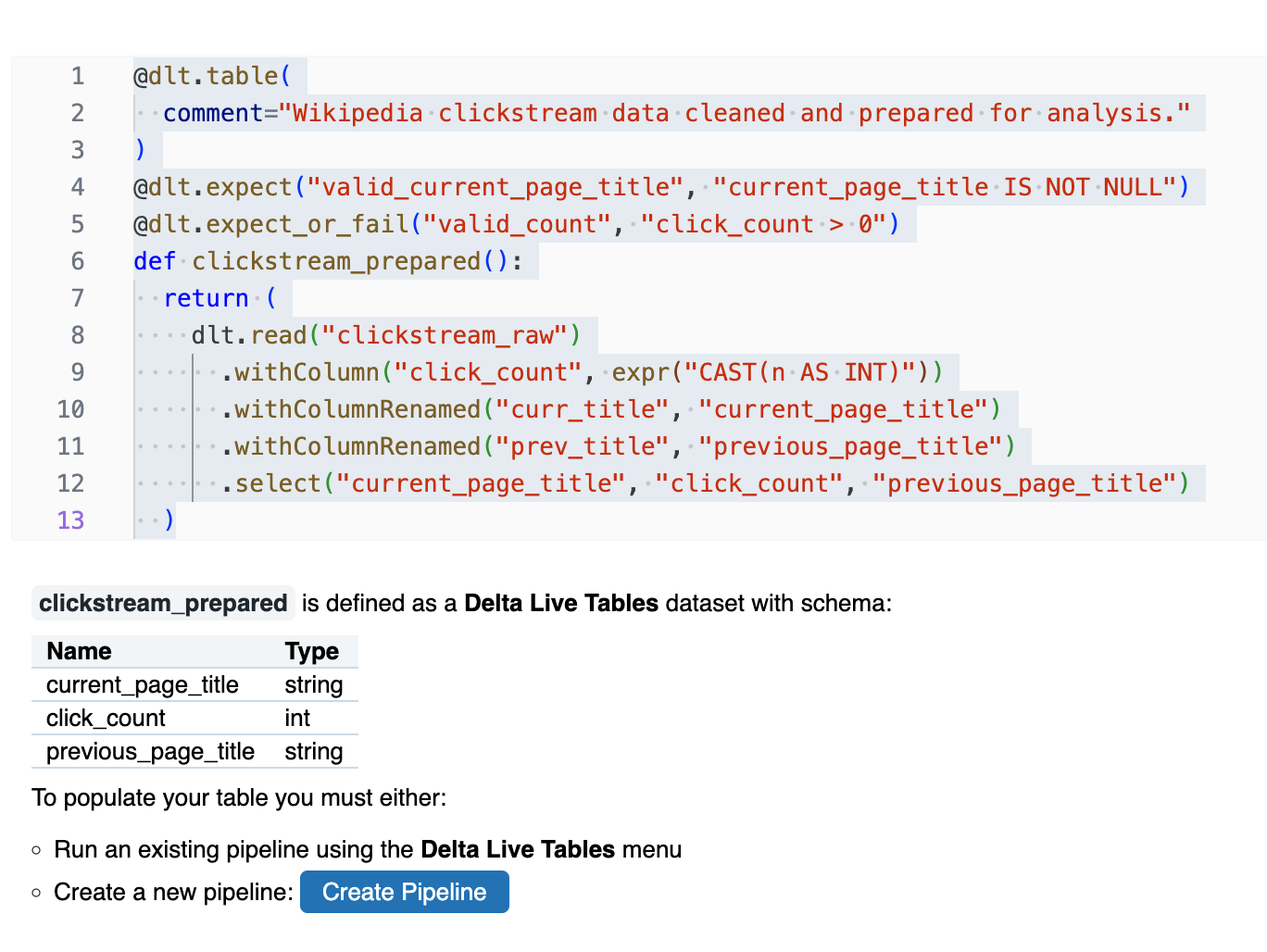
@dlt.table( comment="Wikipedia clickstream data cleaned and prepared for analysis." ) @dlt.expect("valid_current_page_title", "current_page_title IS NOT NULL") @dlt.expect_or_fail("valid_count", "click_count > 0") def clickstream_prepared(): return ( dlt.read("clickstream_raw") .withColumn("click_count", expr("CAST(n AS INT)")) .withColumnRenamed("curr_title", "current_page_title") .withColumnRenamed("prev_title", "previous_page_title") .select("current_page_title", "click_count", "previous_page_title") ) ```
強化されたデータビューを含むテーブルを作成する
Delta Live Tablesはパイプラインの更新を一連の依存関係グラフとして処理するので、特定のビジネスロジックを含むテーブルを宣言することで、ダッシュボード、BI、分析を強化する高度に強化されたビューを宣言できます。
- DLTは、パイプラインの更新を一連の依存関係グラフとして処理する。
Delta Live Tablesテーブルは、概念的には具体化されたビューに相当します。Sparkの従来のビューは、ビューがクエリーされるたびにロジックを実行しますが、Delta Live Tablesテーブルはクエリー結果の最新バージョンをデータファイルに保存します。Delta Live Tablesはパイプライン内のすべてのデータセットの更新を管理するため、具体化されたビューの待機時間要件に合わせてパイプラインの更新をスケジュールし、これらのテーブルに対するクエリーに使用可能な最新バージョンのデータが含まれていることを確認できます。
-
DLTは、ビューに該当する。
-
クエリ結果の最新バージョンをデータファイルに保存する。
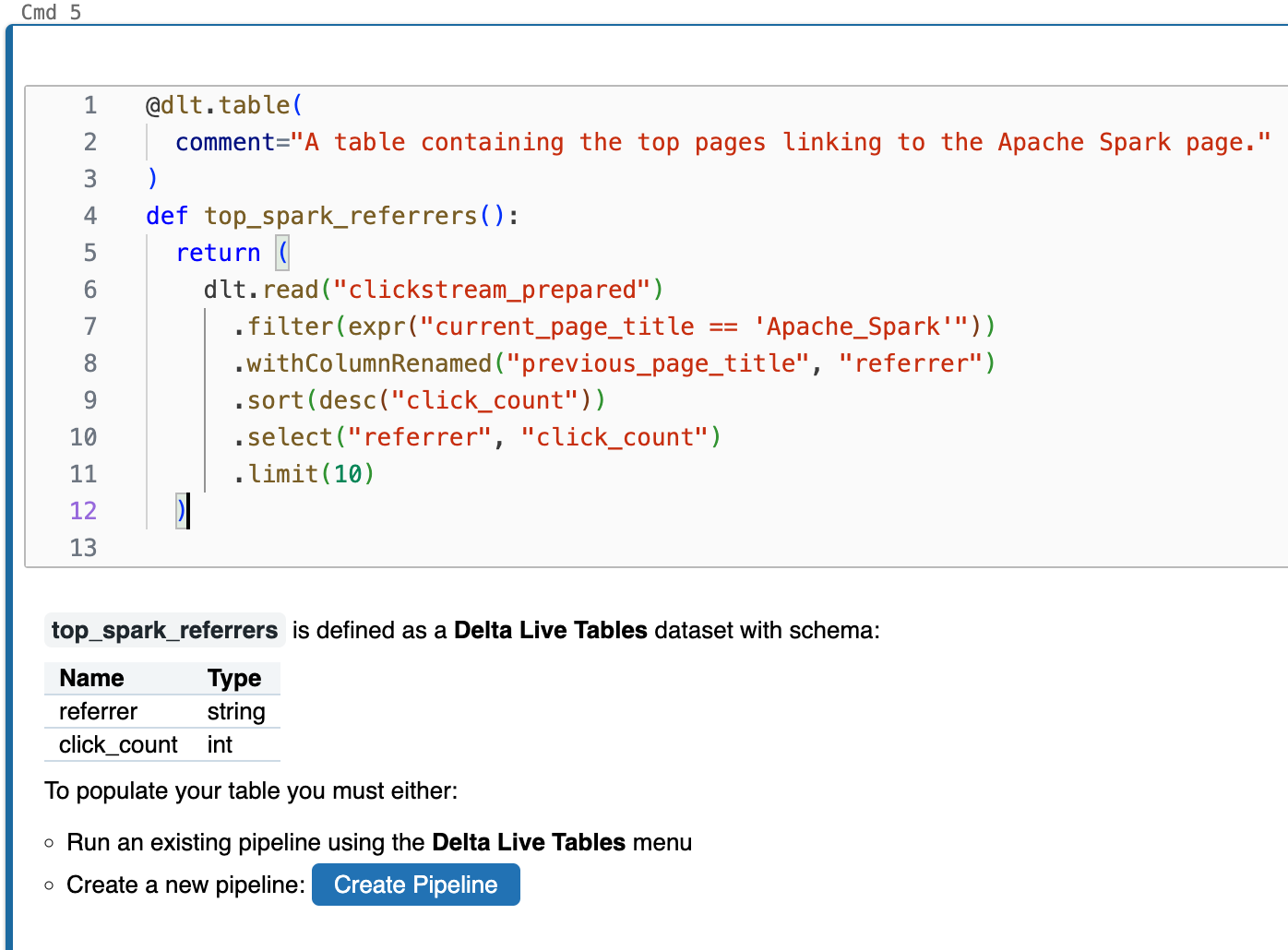
@dlt.table( comment="A table containing the top pages linking to the Apache Spark page." ) def top_spark_referrers(): return ( dlt.read("clickstream_prepared") .filter(expr("current_page_title == 'Apache_Spark'")) .withColumnRenamed("previous_page_title", "referrer") .sort(desc("click_count")) .select("referrer", "click_count") .limit(10) )
考察
dltについて、簡単に試してみました。
今まで私が書いてきた、Sparkコードとは異なり、関数で定義した名前(これがテーブル?)を組み合わせて作っていくのはシンプルでわかりやすく良いですね。
これからDLTの沼にハマるべく、もっと試してみます。
参考