背景・目的
こちらの記事で整理したSageMakerについて、更に利用して感触を確かめてみたいと思います。
本記事ではGet Started with Amazon SageMaker Notebook Instancesを元に整理・実践します。
概要
SageMaker Python SDKを使用した機械学習
- SageMakerノートブックでインスタンスでMLモデルをトレーニング、検証、デプロイ、評価するにはSageMaker Python SDK(以降、SDKと書きます。)を使用する。
- SDKでは、Boto3とSageMaker APIを抽象化する。
- これにより、以下のサービスの統合とオーケストレートが可能になる。
| サービス | 用途 | |
|---|---|---|
| S3 | データとモデルアーティファクトを保存する | |
| ECR | MLモデルをインポート、提供する | |
| EC2 | トレーニング、推論する |
- 以下に対応できるSageMakerの機能も利用できる
- データラベリング
- データの前処理
- モデルトレーニング
- モデルのデプロイ
- 予測パフォーマンスの評価
- 本番におけるモデルの品質のモニタリング
実践
チュートリアルに基づき試します。
- 以下について学習する。
- SageMaker セッションと自動的にペアリングされたデフォルトの Amazon S3 バケットにデータセットを保存する方法
- ML モデルのトレーニングジョブを Amazon EC2 に送信する方法
- ホスティングまたはバッチ推論で予測用にトレーニングされたモデルを Amazon EC2 を介してデプロイする方法
- チュートリアル概要
- SageMaker 組み込みモデルプールから XGBoost モデルをトレーニングする詳細な ML フローの紹介。
- 米国成人国勢調査データセットを使用し、個人収入の予測に関するトレーニング済み SageMaker XGBoost モデルのパフォーマンスを評価。
ステップ 1: Amazon SageMaker ノートブックインスタンスを作成する
-
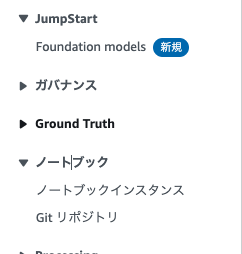
ノートブックインスタンスクリックします。
-
ノートブックインスタンスの作成をクリックします。
-
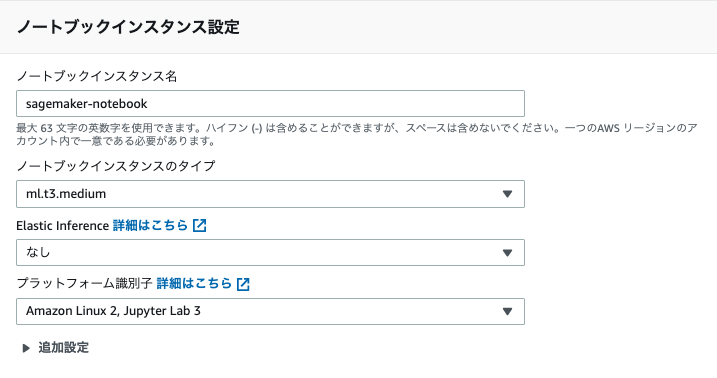
以下を入力しノートブックインスタンスの入力をクリックします。
- ノートブックインスタンス名
- インスタンスタイプ
- Platform Identifier
- IAMロール
-
しばらくするとステータスがInServiceになります。これにより、インスタンスが起動し、5GBのEBSがアタッチされています。また、インスタンスには、Jupyterノートブックサーバ、AWS SDK、一連のAnacondaライブラリが入っている。

ステップ 2: Jupyter ノートブックを作成する
-
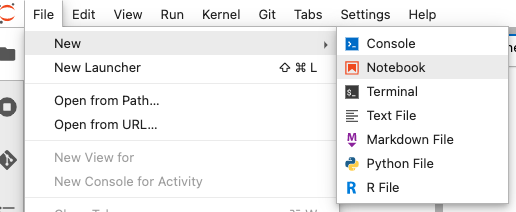
JupyterLabを開くをクリックします。

-
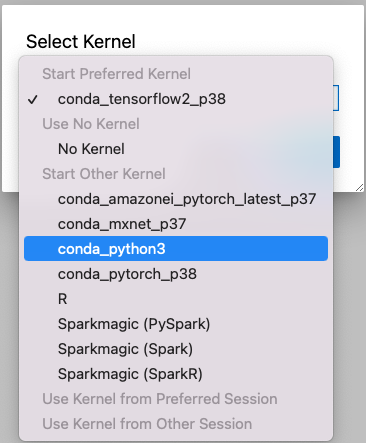
ノートブックを作成します。Select Kernelでは、conda_python3を選択します。
-
Sage Notebook As・・でノートブック名を変更します。
ステップ 3: データセットをダウンロード、調査、変換する
- SHAP (SHapley Additive exPlanations) ライブラリを使用して、ノートブックインスタンスにデータセットを読み込み、データセットの確認、変換、S3へのアップロードを行う。
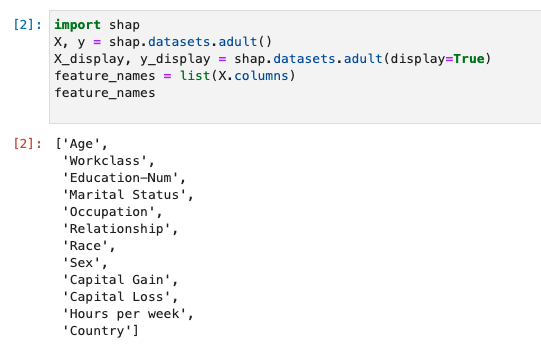
SHAP を使用して成人国勢調査データセットを読み込む
- SHAPライブラリを使用して、成人国勢調査データセットを読み込む。
# SHAPライブラリをインポート
import shap
# SHAPのデータセットにある成人国勢調査データセットを読み込む
X, y = shap.datasets.adult()
X_display, y_display = shap.datasets.adult(display=True)
feature_names = list(X.columns)
feature_names
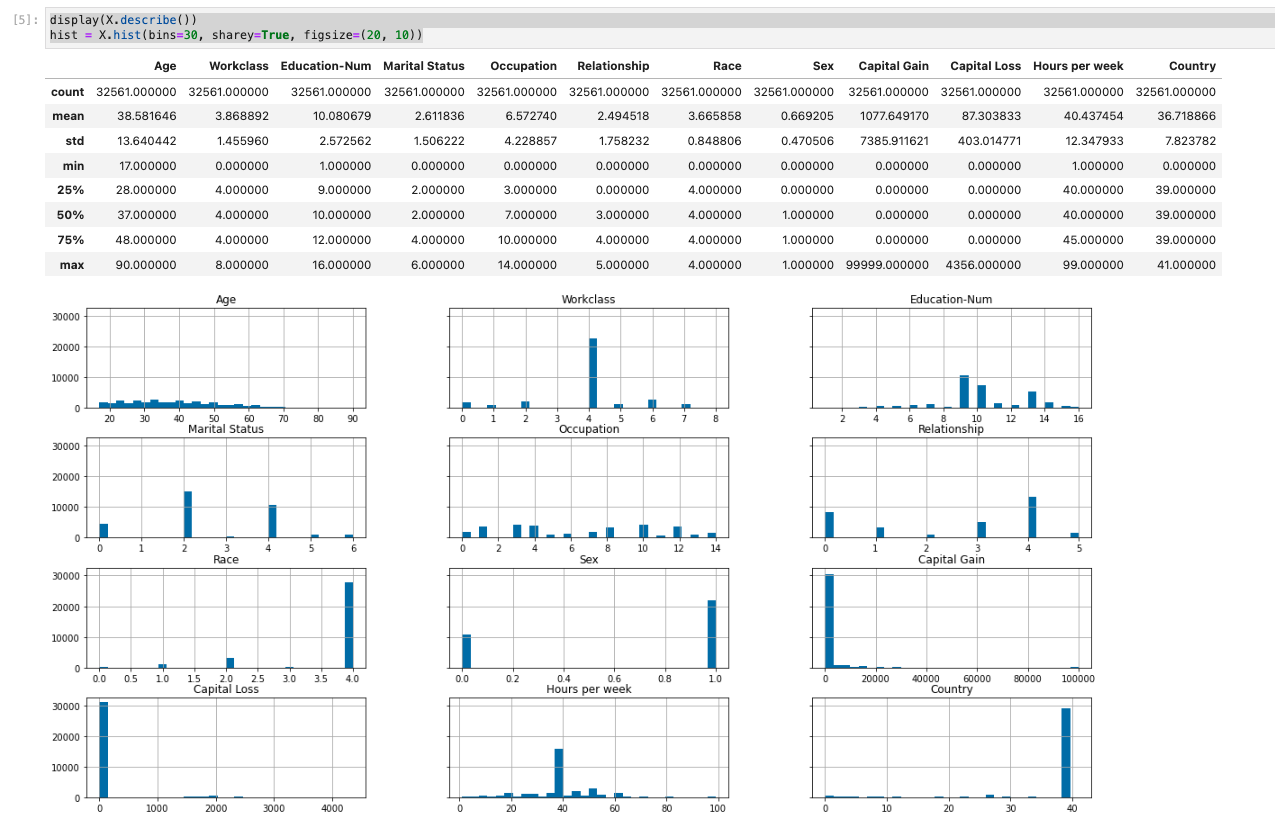
データセットの概要
- データセットの統計概要と数値特徴のヒストグラムが表示される。
display(X.describe())
hist = X.hist(bins=30, sharey=True, figsize=(20, 10))
データセットをトレーニング、検証、テストデータセットに分割する
- Sklearn を使用して、データセットをトレーニングセットとテストセットに分割する。
- トレーニングセットはモデルのトレーニングに使用
- テストセットは最終的なトレーニング済みモデルのパフォーマンスを評価するために使用
- データセットは、固定ランダムシード (データセットの 80% がトレーニングセット、20% がテストセット) でランダムにソートされる。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
X_train_display = X_display.loc[X_train.index]
- さらにトレーニングセットを分割する
- 75%をトレーニングセット
- 残り(25%)は検証セット
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.25, random_state=1)
X_train_display = X_display.loc[X_train.index]
X_val_display = X_display.loc[X_val.index]
- pandas パッケージを使用して、数値特徴と実際のラベルを連結し、各データセットを明示的に整列させる。
import pandas as pd
train = pd.concat([pd.Series(y_train, index=X_train.index,
name='Income>50K', dtype=int), X_train], axis=1)
validation = pd.concat([pd.Series(y_val, index=X_val.index,
name='Income>50K', dtype=int), X_val], axis=1)
test = pd.concat([pd.Series(y_test, index=X_test.index,
name='Income>50K', dtype=int), X_test], axis=1)
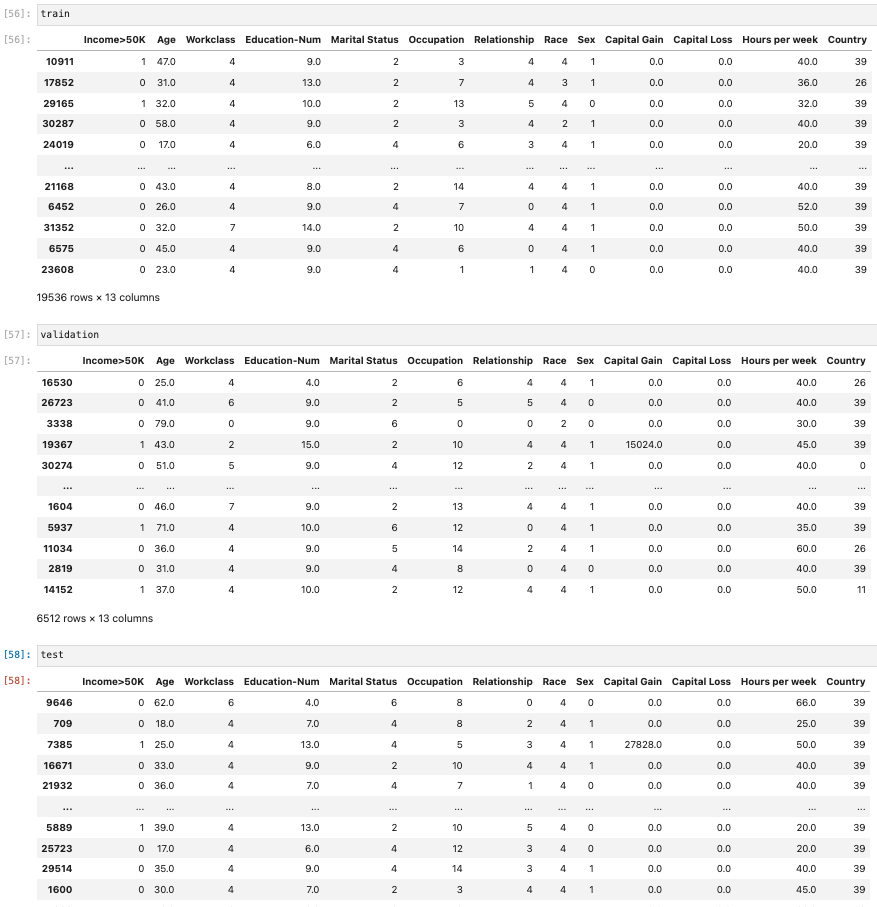
- 各データセットを表示する。
- train
- validation
- test
トレーニングデータセットと検証データセットを CSV ファイルに変換する
- train と validation のデータフレームオブジェクトを CSV ファイルに変換し、XGBoost アルゴリズムの入力ファイル形式に合わせる。
train.to_csv('train.csv', index=False, header=False)
validation.to_csv('validation.csv', index=False, header=False)
データセットを Amazon S3 にアップロードする
- SageMaker と Boto3 を使用して、トレーニングデータセットと検証データセットをS3にアップロードする
- S3バケット内のデータセットは、EC2のコンピューティングに最適化されたSageMakerインスタンスによってトレーニングに使用される。
- 以下を実行する
- 現在の SageMaker セッションのデフォルトの S3 バケット URI を設定
- 新しい demo-sagemaker-xgboost-adult-income-prediction フォルダを選択
- トレーニングデータセットと検証データセットを data サブフォルダにアップロード
import sagemaker, boto3, os
bucket = sagemaker.Session().default_bucket()
prefix = "demo-sagemaker-xgboost-adult-income-prediction"
boto3.Session().resource('s3').Bucket(bucket).Object(
os.path.join(prefix, 'data/train.csv')).upload_file('train.csv')
boto3.Session().resource('s3').Bucket(bucket).Object(
os.path.join(prefix, 'data/validation.csv')).upload_file('validation.csv')
- デフォルトのS3バケットは以下の通り
bucket
===
sagemaker-{リージョン}-{アカウントID}
- CSVファイルがS3にアップされたか、AWS CLIで確認する
! aws s3 ls {bucket}/{prefix}/data --recursive

ステップ 4: モデルをトレーニングする
- SDKは、以下を行う。
- フレームワーク推定器と汎用推定器を提供
- SageMakerのトレーニング機能やECR、EC2、S3などのAWSインフラにアクセス
- 機械学習 (ML) のライフサイクルをオーケストレートしながらモデルをトレーニング
トレーニングアルゴリズムを選択する
通常、データセットに適切なアルゴリズムを選択するには、さまざまなモデルを評価して、データに最適なモデルを見つける必要がある。
簡単に作業できるように、ここでは、モデルの事前評価を行わずに SageMakerの組み込みのXGBoostアルゴリズムを使用する。
トレーニングジョブを作成して実行する
- 使用するモデルが見つかったら、トレーニング用の SageMaker 推定器を構築する。
- このチュートリアルでは、SageMaker 汎用推定器に XGBoost 組み込みアルゴリズムを使用する。
モデルトレーニングジョブを実行するには
-
SageMaker SDKをインポートし、現在のSageMakerセッションから基本情報を取得し始める。
import sagemaker region = sagemaker.Session().boto_region_name print("AWS Region: {}".format(region)) role = sagemaker.get_execution_role() print("RoleArn: {}".format(role)) === AWS Region: XXXXX RoleArn: arn:aws:iam::XXXXXX:role/SageMakerCustomRole -
sagemaker.estimator.Estimatorクラスを使用して XGBoost推定器を作成する。
大規模な深層学習モデルの分散トレーニングを実行する場合、データの並列処理またはモデルの並列処理には SageMaker Distributed を使用する。
例:畳み込みニューラルネットワーク (CNN) 、自然言語処理 (NLP) モデル等:
- 以下のサンプルコードではXGBoost推定機の名前がxgb_modelになっている。
- 設定値は以下の通り。
- image_uri:トレーニングコンテナのイメージURI
- instance_countとinstance_type:モデルのトレーニングに使用されるEC2のインスタンスタイプと数
- ml.m4.xlargeインスタンス
- volume_size:アタッチするEBSのサイズ(GB)
- output_path:SageMakerがモデルアーティファクトとトレーニング結果を保存するS3パス
- sagemaker_session:SageMaker APIやトレーニングジョブで使用されるその他のAWSサービスとのやり取りを管理する
- rules:Sageデバッガー組み込みルールのリストを指定する。
- create_xgboost_reportルールによりトレーニングの進行状況と結果に関するインサイトを提供するXGBoostレポート(詳細)が作成される。
from sagemaker.debugger import Rule, rule_configs from sagemaker.session import TrainingInput s3_output_location='s3://{}/{}/{}'.format(bucket, prefix, 'xgboost_model') container=sagemaker.image_uris.retrieve("xgboost", region, "1.2-1") print(container) xgb_model=sagemaker.estimator.Estimator( image_uri=container, role=role, instance_count=1, instance_type='ml.m4.xlarge', volume_size=5, output_path=s3_output_location, sagemaker_session=sagemaker.Session(), rules=[Rule.sagemaker(rule_configs.create_xgboost_report())] ) -
推定器のset_hyperparameterを呼び出し、XGBoost アルゴリズムのハイパーパラメータ値を設定する。XGBoostのハイパーパラメータの説明はこちら。
SageMakerハイパーパラメータ最適化機能を使用してハイパーパラメータを調整することも可能。詳細はこちらを参照。
:
xgb_model.set_hyperparameters( max_depth = 5, eta = 0.2, gamma = 4, min_child_weight = 6, subsample = 0.7, objective = "binary:logistic", num_round = 1000 ) -
TrainingInput クラスを使用して、トレーニング用のデータ入力フローを設定する。
- S3にアップロードしたトレーニングデータセットと検証データセットを使用するためのTrainingInputオブジェクトを設定している
from sagemaker.session import TrainingInput train_input = TrainingInput( "s3://{}/{}/{}".format(bucket, prefix, "data/train.csv"), content_type="csv" ) validation_input = TrainingInput( "s3://{}/{}/{}".format(bucket, prefix, "data/validation.csv"), content_type="csv" ) -
モデルのトレーニングの開始には、推定器のfitメソッドをトレーニングデータセットと検証データセットを呼び出す。
- wait=Trueに設定することで、fitメソッドで進捗状況をログに表示し、トレーニングが完了するまで待機状態になる。
- トレーニングは最大10分かかる場合がある。
- トレーニングジョブが終わってからXGBoostトレーニングレポートと、SageMakerデバッガーにより生成されたプロファイルレポートをダウンロードできる。
- XGBoostトレーニングレポートでは、以下のようなトレーニングの進行状況と結果に関するインサイトが提供される。
- イテレーションに対する損失関数
- 特徴量の重要度
- 混同行列
- 精度曲線
- トレーニングのその他の統計結果
xgb_model.fit({"train": train_input, "validation": validation_input}, wait=True)
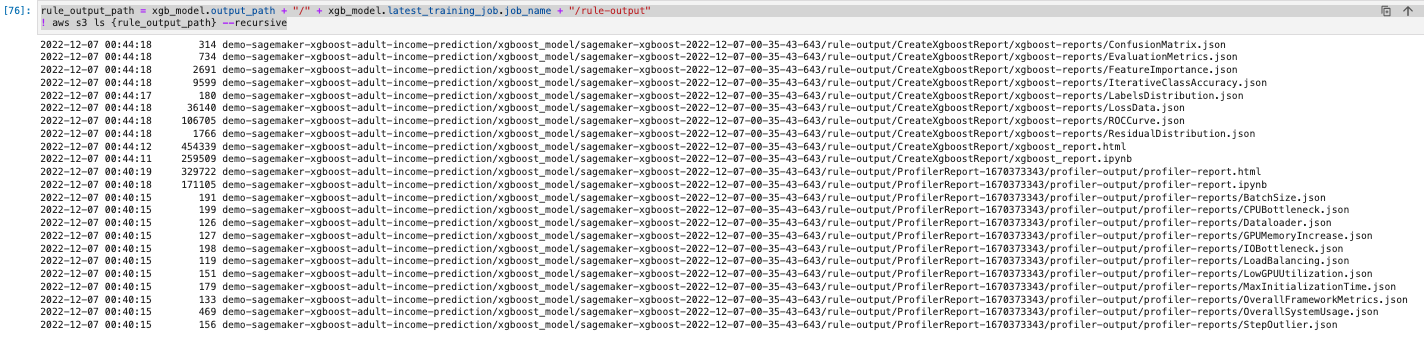
- レポートの存在を確認する
rule_output_path = xgb_model.output_path + "/" + xgb_model.latest_training_job.job_name + "/rule-output" ! aws s3 ls {rule_output_path} --recursive
-
Debugger XGBoost トレーニングレポートとプロファイリングレポートを現在のワークスペースにダウンロードする。
! aws s3 cp {rule_output_path} ./ --recursive -
以下のIPython スクリプトを実行し、XGBoost トレーニングレポートのファイルリンクを取得。
from IPython.display import FileLink, FileLinks display("Click link below to view the XGBoost Training report", FileLink("CreateXgboostReport/xgboost_report.html"))
-
以下のIPython スクリプトは、EC2 インスタンスのリソース使用率、システムボトルネックの検出結果、Python オペレーションプロファイリング結果の概要と詳細を示す Debugger プロファイリングレポートのファイルリンクを返す。
profiler_report_name = [rule["RuleConfigurationName"] for rule in xgb_model.latest_training_job.rule_job_summary() if "Profiler" in rule["RuleConfigurationName"]][0] profiler_report_name display("Click link below to view the profiler report", FileLink(profiler_report_name+"/profiler-output/profiler-report.html"))
-
SageMakerはモデルアーティファクトをS3に保存する。モデルアーティファクトの場所を確認するには、以下のコードを実行することで確認できる。
xgb_model.model_data
ステップ 5: モデルを Amazon EC2 にデプロイする
- 予測を取得するには、SageMaker を使用して Amazon EC2 にモデルをデプロイする。
SageMaker ホスティングサービスにモデルをデプロイする
- SageMaker を使用して Amazon EC2 経由でモデルをホストするには、でトレーニングしたモデルを xgb_model 推定器の deploy メソッドを呼び出してデプロイする。
- deploy メソッドを呼び出すときに、エンドポイントをホストするのに使用する EC2 ML インスタンスの数とタイプを指定する。
- deploy メソッドはデプロイ可能なモデルを作成し、SageMaker ホスティングサービスエンドポイントを設定し、モデルをホストするエンドポイントを起動します。
- パラメータの説明は、以下のとおりです。
- initial_instance_count: モデルをデプロイするインスタンス数
- instance_type: デプロイされたモデルを操作するインスタンスのタイプ
- serializer: さまざまな形式 (NumPy 配列、リスト、ファイル、バッファ) の入力データを CSV 形式の文字列にシリアル化する。
import sagemaker
from sagemaker.serializers import CSVSerializer
xgb_predictor=xgb_model.deploy(
initial_instance_count=1,
instance_type='ml.t2.medium',
serializer=CSVSerializer()
)
- 以下のコマンドにより、エンドポイント名が返される。
- エンドポイント名は、sagemaker-xgboost-YYYY-MM-DD-HH-MM-SS-SSSになる。
- エンドポイントは、MLインスタンスでアクティブなままとなるため、後でシャットダウンしない限り、いつでも瞬時に予測を行うことができる。
- このエンドポイント名をコピーして保存しておけば、再利用して、SageMaker Studio または SageMaker ノートブックインスタンスの他の場所でリアルタイム予測を行うことが可能。
xgb_predictor.endpoint_name
ステップ 6: モデルを評価する
- SageMaker でモデルをトレーニングしてデプロイしたので、新しいデータに対して正確な予測が生成されるようにモデルを評価する。
- 評価には、ステップ3で作成したテストデータセットを使用する。
SageMaker ホスティングサービスにデプロイしたモデルを評価する
- モデルを評価して本番環境で使用するには、テストデータセットを使用してエンドポイントを呼び出し、取得した推論によって、達成する目標精度が返されるかどうかを確認する。
-
次の関数を設定して、テストセットの各行を予測します。
- 下記のサンプルコードでは、rows 引数で、一度に予測する行の数を指定します。この値を変更すると、インスタンスのハードウェアリソースを利用するバッチ推論を実行できる。
import numpy as np def predict(data, rows=1000): split_array = np.array_split(data, int(data.shape[0] / float(rows) + 1)) predictions = '' for array in split_array: predictions = ','.join([predictions, xgb_predictor.predict(array).decode('utf-8')]) return np.fromstring(predictions[1:], sep=',') -
下記のコードを実行して、テストデータセットの予測を行い、ヒストグラムをプロットする。
- 実際の値の 0 列目を除外し、テストデータセットの特徴列のみを取得する必要がある。
import matplotlib.pyplot as plt predictions=predict(test.to_numpy()[:,1:]) plt.hist(predictions) plt.show()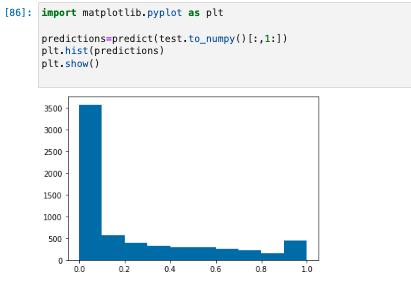
-
予測値は浮動小数点タイプ
- 浮動小数点値に基づいて True または False を決定するには、カットオフ値を設定する必要がある。
- 下記のサンプルコードに示すように、Scikit-learn ライブラリを使用すると、0.5 のカットオフを使用した出力混同メトリクスと分類レポートが返される。
import sklearn cutoff=0.5 print(sklearn.metrics.confusion_matrix(test.iloc[:, 0], np.where(predictions > cutoff, 1, 0))) print(sklearn.metrics.classification_report(test.iloc[:, 0], np.where(predictions > cutoff, 1, 0)))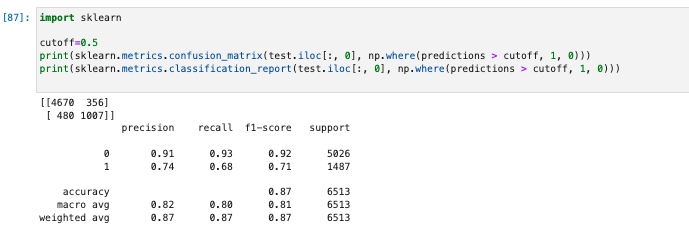
-
特定のテストセットで最適なカットオフを求めるには、ロジスティック回帰の対数損失関数を計算する。
- 対数損失関数は、Ground Truth ラベルの予測確率を返すロジスティックモデルの負の対数尤度として定義される。
- 下記のサンプルコードは、対数損失値を数値順かつ反復的に計算します
- ここで y は実際のラベルであり、p は対応するテストサンプルの確率推定値です。この場合、対数損失とカットオフのグラフが返される
import matplotlib.pyplot as plt cutoffs = np.arange(0.01, 1, 0.01) log_loss = [] for c in cutoffs: log_loss.append( sklearn.metrics.log_loss(test.iloc[:, 0], np.where(predictions > c, 1, 0)) ) plt.figure(figsize=(15,10)) plt.plot(cutoffs, log_loss) plt.xlabel("Cutoff") plt.ylabel("Log loss") plt.show()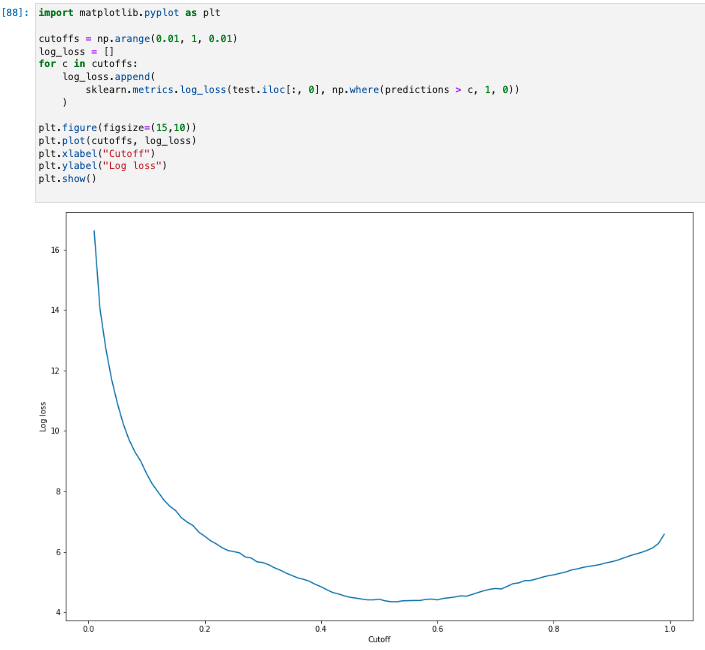
-
NumPy argmin と min の関数を使用して、誤差曲線の最小点を求める。
print( 'Log loss is minimized at a cutoff of ', cutoffs[np.argmin(log_loss)], ', and the log loss value at the minimum is ', np.min(log_loss) )
ステップ 7: クリーンアップする
-
エンドポイントを削除する。

-
エンドポイント設定を削除する。

1.モデルを削除します。

- ノートブックインスタンスを停止し、削除します。


考察
SageMakerを使った、モデルのトレーニング〜デプロイまでの流れがなんとなく理解できました。引き続き使い倒していこうと思います。
参考