背景
私は、現在データエンジニアリングを生業としています。普段は、データ基盤の構築や、パフォーマンスチューニングなどビックデータに関する業務に従事しています。
ビックデータの収集や、蓄積、分析などの環境構築の経験はそこそこありますが、機械学習による予測や分類などのスキルは持ち合わせていませんでした。
今まで機械学習を避け続けてきましたが、一念発起し学ぼうと思います。
今回は、SageMakerについて調査と環境構築を通して理解を深めようと思います。
まとめ
- SageMakerは、フルマネージドな機械学習サービスで、モデルの構築・トレーニング・デプロイまでをカバーします。
- またJupyter Notebookによりデータ分析にも利用できる
- アルゴリズムは、SageMaker独自のものに加えて一般的なものも提供します。
- 機能は以下の通りです。(ドキュメントをコピペしています。)
| 機能 | 説明 | 備考 |
|---|---|---|
| SageMaker Studio | モデルの構築、トレーニング、デプロイ、分析をすべて同じアプリケーションで実行できる、統合された機械学習環境。 | |
| SageMaker Canvas | コーディング経験のない人がモデルを構築して予測できるようにする自動 ML サービス。 | |
| SageMaker Ground Truth Plus | ラベル付けアプリケーションを構築し、ラベル付け作業員を自分で管理することなく、高品質のトレーニング データセットを作成するためのターンキー データ ラベル付け機能。 | |
| SageMaker Studio Lab | オープンソースの JupyterLab に基づく環境で、お客様が AWS コンピューティング リソースにアクセスできるようにする無料のサービスです。 | |
| SageMaker Training Compiler | SageMaker が管理するスケーラブルな GPU インスタンスでディープラーニング モデルをより高速にトレーニングします。 | |
| SageMaker Studio Universal Notebook | SageMaker Studio から直接、単一アカウントおよびクロスアカウント構成で Amazon EMR クラスターを簡単に検出、接続、作成、終了、および管理します。 | |
| SageMaker Serverless Endpoints | ML モデルをホストするためのサーバーレス エンドポイント オプション。エンドポイント トラフィックに対応するために容量を自動的にスケーリングします。インスタンス タイプを選択したり、エンドポイントでスケーリング ポリシーを管理したりする必要がなくなります。 | |
| SageMaker Inference Recommender | ML モデルとワークロードを使用するための推論インスタンスのタイプと構成 (インスタンス数、コンテナー パラメーター、モデルの最適化など) に関する推奨事項を取得します。 | |
| SageMaker Model Registry | バージョニング、アーティファクトと系統の追跡、承認ワークフロー、および機械学習モデルの展開のためのクロス アカウント サポート。 | |
| SageMaker Projects | SageMaker プロジェクトを使用して、CI/CD でエンドツーエンドの ML ソリューションを作成します。 | |
| SageMaker Model Building Pipelines | SageMaker ジョブと直接統合された機械学習パイプラインを作成および管理します。 | |
| SageMaker ML Lineage Tracking | 機械学習ワークフローの系統を追跡します。 | |
| SageMaker Data Wrangler | SageMaker Studio でデータをインポート、分析、準備、特徴付けします。 Data Wrangler を機械学習ワークフローに統合して、コーディングをほとんどまたはまったく使用せずに、データの前処理と機能エンジニアリングを簡素化および合理化できます。独自の Python スクリプトと変換を追加して、データ準備ワークフローをカスタマイズすることもできます。 | |
| SageMaker Feature Store | 機能と関連するメタデータを一元的に保管して、機能を簡単に発見して再利用できるようにします。オンライン ストアとオフライン ストアの 2 種類のストアを作成できます。オンライン ストアは低レイテンシのリアルタイム推論のユース ケースに使用でき、オフライン ストアはトレーニングとバッチ推論に使用できます。 | |
| SageMaker JumpStart | 精選されたワンクリック ソリューション、サンプル ノートブック、デプロイ可能な事前トレーニング済みモデルを通じて、SageMaker の機能について学びます。モデルを微調整してデプロイすることもできます。 | |
| SageMaker Clarify | 潜在的なバイアスを検出して機械学習モデルを改善し、モデルが行う予測の説明に役立てます。 | |
| SageMaker Edge Manager | エッジ デバイスのカスタム モデルを最適化し、フリートを作成して管理し、効率的なランタイムでモデルを実行します。 | |
| Amazon Augmented AI | ML 予測の人によるレビューに必要なワークフローを構築します。 Amazon A2I は、人間によるレビューをすべての開発者に提供し、人間によるレビュー システムの構築や多数の人間によるレビュー担当者の管理に関連する差別化されていない重労働を取り除きます。 | |
| SageMaker Ground Truth | ワーカーと機械学習を使用してラベル付きデータセットを作成することにより、高品質のトレーニング データセットを作成します。 | |
| SageMaker Studio Notebooks | AWS IAM Identity Center (AWS Single Sign-On の後継) (IAM Identity Center) 統合、高速起動時間、シングルクリック共有を含む次世代の SageMaker ノートブック。 | |
| SageMaker Experiments | 実験の管理と追跡。追跡されたデータを使用して、実験を再構築し、ピアによって実施された実験を段階的に構築し、コンプライアンスと監査の検証のためにモデル系統を追跡できます。 | |
| SageMaker Debugger | トレーニング プロセス全体でトレーニング パラメータとデータを検査します。パラメータ値が大きすぎたり小さすぎたりするなど、一般的に発生するエラーを自動的に検出してユーザーに警告します。 | |
| SageMaker Autopilot | 機械学習の知識がなくても、分類モデルと回帰モデルをすばやく構築できます。 | |
| SageMaker Model Monitor | 本番環境 (エンドポイント) のモデルを監視および分析して、データのドリフトやモデル品質の偏差を検出します。 | |
| SageMaker Neo | 機械学習モデルを一度トレーニングすれば、クラウドやエッジのどこでも実行できます。 | |
| SageMaker Elastic Inference | スループットを高速化し、リアルタイムの推論を取得する際の待ち時間を短縮します。 | |
| Reinforcement Learning | エージェントがアクションの結果として受け取る長期的な報酬を最大化します。 | |
| Preprocessing | データを分析して前処理し、特徴量エンジニアリングに取り組み、モデルを評価します。 | |
| Batch Transform | データセットを前処理し、永続的なエンドポイントが必要ない場合は推論を実行し、入力レコードを推論に関連付けて結果の解釈を支援します。 |
概要
AWSドキュメントのWhat Is Amazon SageMaker?を元に整理します。
What Is Amazon SageMaker?
以下の特徴があります。
- フルマネージド。サーバ管理不要
- モデルの構築・トレーニング・デプロイできる
- Jupyterノートブックによりデータに簡単にアクセス可能
- 独自のアルゴリズムとフレームワーク、および一般的な機械学習アルゴリズムを提供
Amazon SageMaker Features
まとめに記載します。
Machine Learning with Amazon SageMaker
AWSドキュメントのMachine Learning with Amazon SageMakerを元に整理します。
-
機械学習のサイクル
- アルゴリズムとサンプルデータを使用してモデルをトレーニングを実施
- モデルをアプリケーションに統合し、リアルタイムかつ大規模な推論を生成
- 本番では、通常数百万のサンプルデータ項目から学習し、20ミリSec未満で推論を生成
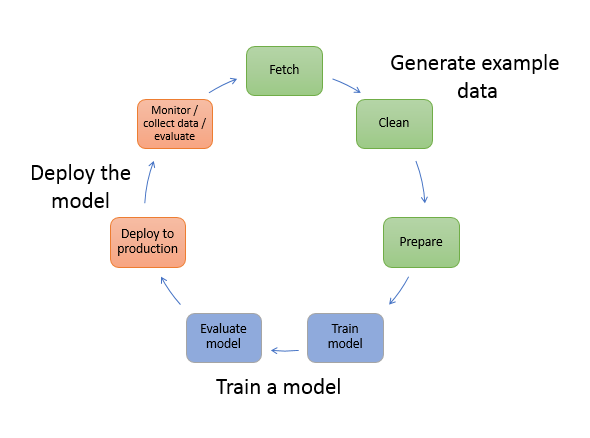
出典:AWSドキュメント (Machine Learning with Amazon SageMaker)
- 本番では、通常数百万のサンプルデータ項目から学習し、20ミリSec未満で推論を生成
-
次のアクティビティを実施する
- Generate example data
- モデルのトレーニングのためにサンプルデータを用意する。
- サイエンティストは、サンプルデータの探索と前処理に多くの時間を要する。
- 前処理は以下の操作を行う。
- Fetch the data
- 社内または公開されているデータセットを使用する
- 1つまたは複数のデータセットを1つのリポジトリにPullする
- Clean the data
- モデルのトレーニングを改善にするには、データを検査して必要に応じてクリーニングを実施する
- 例えばデータに一貫性がない場合、United States とUSが混在する場合などクリーニングにより統一する
- モデルのトレーニングを改善にするには、データを検査して必要に応じてクリーニングを実施する
- Prepare or transform the data
- パフォーマンス向上のために、追加のデータ変換を実行する場合がある。
- 例えば、属性の組み合わせを使用する
- 温度と湿度の属性を個別に使用する代わりに、組み合わせてより優れたモデルを取得できる
- 例えば、属性の組み合わせを使用する
- パフォーマンス向上のために、追加のデータ変換を実行する場合がある。
- Fetch the data
- Jupyter notebookでサンプルデータを前処理する。
- データセットをFetchし、探索、モデルトレーニング用データを準備する
- Train a model
- モデルのトレーニングと評価を含む
- Training the model
- Evaluting the model
- トレーニング時に推論の精度が許容できるか判断する。
- SageMakerでは、Boto、Pythonライブラリにより、推論のためにモデルにリクエストを送信する
- Jupyter Notebookでモデルのトレーニングと評価が行える。
- モデルのトレーニングと評価を含む
- Deploy the model
- SageMaker ホスティングサービスを使用すると、モデルを個別にデプロイしてアプリケーションコードから切り離すことができる。
- Generate example data
-
機械学習は継続的なサイクル
- モデルをデプロイ後に推論を監視し、正解データを取得し、モデルを評価しドリフトを特定する。
- ※ ground truth=正解データ
- ※ ドリフト=予期せぬ変化」によって、モデルの予測性能が時間経過とともに劣化していくことを指す。
- 新しく収集した正解データを含めるようにトレーニングデータを更新し、推論の精度を高める。
- 新しいデータセットでモデルをトレーニングする
- より多くのサンプルデータが利用可能になるにつれて、精度を高めるためにモデルの再トレーニングを続ける
- モデルをデプロイ後に推論を監視し、正解データを取得し、モデルを評価しドリフトを特定する。
Explore, Analyze, and Process Data
AWSドキュメントのExplore, Analyze, and Process Dataを元に整理します。
- データサイエンティストは、モデルのトレーニング前に探索・分析・前処理します。
- SageMaker Processingを使用すると、ジョブを実行して、データの前処理と後処理、特徴エンジニアリングの実行、SageMaker でのモデルの評価を簡単かつ大規模に行うことができます。
- SageMakerは、他の機械学習タスクと組み合わせることで完全に管理された機械学習環境の利点を提供できる。
- SageMaker Processingにより組み込みコンテナ、独自コンテナを使用してカスタムジョブを送信したりして、管理されたインフラで実行できる。
- ジョブ送信により、SageMakerはコンピューティングインスタンスを起動し、入力データを処理し分析し、完了時にリソースを開放します。
What Is Fairness and Model Explainability for Machine Learning Predictions?
AWSドキュメントのWhat Is Fairness and Model Explainability for Machine Learning Predictions?を元に整理します。
- SageMaker Clarifyは、潜在的なバイアスを検出し、モデルが行う予測の説明を支援することでMLモデルの改善を支援する
- モデルのトレーニング中、本番でのトレーニング前後のデータの様々なバイアスを特定するのに役立つ。
- バイアスや機能属性ドリフトについて本番環境で行われる推論モデルを監視する。
- 外部の規制当局に通知するために使用できるモデルガバナンスレポートを生成するのに役立つツールも提供する
- 機械学習モデルとデータ駆動型システムは、金融サービス、ヘルスケア、人事などのドメイン全体で意思決定を支援するためにますます使用されている。
- 機械学習アプリケーションは、以下を提供し、規制要件への対応、ビジネス上の意思決定の改善、データサイエンス手順へのより良い洞察の提供を支援する。
- 精度の向上
- 生産性の向上
- コスト削減
- 規制
- 多くの場合、MLモデルが特定の予測を行った理由と、トレーニング中または推論時にバイアスの影響を受けたかどうか理解することが重要
- 特にシステムの潜在的な差別的影響について懸念を表明している関係者がいる。
- ビジネス
- 規制されたドメインでは、信頼が必要
- トレーニング済みモデルの動作、展開されたモデルが予測を行う方法について信頼できる説明を提供する。
- 以下のような信頼性、安全性、コンプライアンス要件を持つ特定の業界にとって重要なる場合がある。
- 金融
- 人事
- ヘルスケア
- 自動輸送
- データサイエンス
- サイエンティストとMLエンジニアは、より優れた機能エンジニアリングを通してモデルをデバッグ及び改善するために必要な洞察を生成し、モデルがノイズの多い
- 機械学習アプリケーションは、以下を提供し、規制要件への対応、ビジネス上の意思決定の改善、データサイエンス手順へのより良い洞察の提供を支援する。
Best Practices for Evaluating Fairness and Explainability in the ML Lifecycle
- Fairness as a Process
- バイアスと公平性の概念は、アプリケーションに大きく依存する。
- バイアスを測定する属性の選択、バイアス指標の選択は以下のような考慮事項から導かれる必要がある場合がある
- 社会的
- 法律的
- その他の非技術的な考慮事項
- 主要な利害関係者間でコンセンサスを構築し、コラボレーションをじつすることは、公平性を意識したMLアプローチを実際にうまく採用するための前提になる
- Fairness and Explainability by Design in the ML Lifecycle
- 以下のMLライフサイクルの各段階で公平性、説明可能性を考慮する必要がある。
- 問題の形式
- データセットの構築
- アルゴリズムの選択
- モデルのトレーニングプロセス
- テストプロセス
- 展開
- 監視/フィードバック
- 以下のMLライフサイクルの各段階で公平性、説明可能性を考慮する必要がある。
Train a Model with Amazon SageMaker
AWSドキュメントのTrain a Model with Amazon SageMakerを元に整理します。
- SageMakerを使用してモデルをトレーニング、デプロイする方法を下記に記載します。
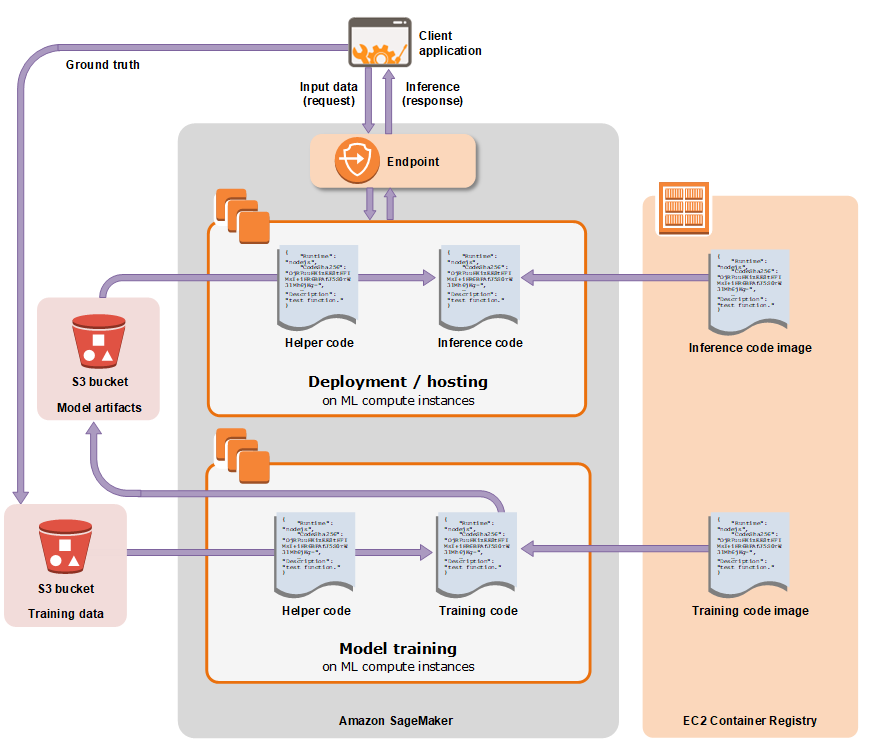
出典:AWSドキュメント(Train a Model with Amazon SageMaker) - トレーニングとデプロイの2つのコンポーネントがある
- トレーニング
- モデルをトレーニングするには、トレーニングジョブを作成する。トレーニングジョブには以下の情報が含まれる。
- トレーニングデータを保存したS3パス
- SageMakerがモデルのトレーニングに使用するコンピューティングリソース
- ジョブの出力を保存するS3パス
- トレーニングコードが保存されるECRパス
- モデルをトレーニングするには、トレーニングジョブを作成する。トレーニングジョブには以下の情報が含まれる。
- トレーニングアルゴリズムには、以下のオプションがある
- SageMakerが提供するアルゴリズムを使用する
- SageMakerでは数十の組み込みアルゴリズムを提供している。
- ニーズを満たしているのであれば、すぐに使えるのが特徴。
- SageMaker Debuggerを使用する
- TensorFlow、PyTorch、Apache MXNet学習フレームワーク、XGBoostアルゴリズムを操作する際に、SageMaker Debuggerを使用してトレーニングプロセス全体でトレーニングパラメータとデータを検査する。
- デバッガーのサンプルノートブックは、Amazon SageMaker Debuggerで入手可能
- SageMakerでApache Sparkを使用する
- SageMakerでモデルをトレーニングするためにSparkで使用できるライブラリを提供する。
- ディープラーニングフレームワークでトレーニングするカスタムコードを送信する
- モデルトレーニング用にTensorFlow、PyTorch、Apache MXNetを使用するカスタムPythonコードを送信できる
- 独自のカスタムコードを使用する
- コードをDockerイメージとしてまとめて、SageMaker CreateTrainingJobAPIを呼び出してイメージのレジストリパスを指定する。
- AWS Marketplaceからサブスクライブする
- SageMakerが提供するアルゴリズムを使用する
- トレーニングジョブを作成すると、SageMakerはMLコンピューティングインスタンスを起動し、トレーニングコードとトレーニングデータセットを使用してモデルをトレーニングします。そのためにS3バケットに結果のアーティファクトと、その他出力が保存される。
- SageMakerコンソール、APIを使用してトレーニングジョブを作成できる。
- APIを使用してトレーニングジョブを作成すると、デフォルトでMLコンピューティングインスタンスにデータセット全体をコピーする。
- トレーニング
Deploy a Model in Amazon SageMaker
AWSドキュメントのDeploy a Model in Amazon SageMakerを元に整理します。
- モデルをトレーニング後、ユースケースに応じてSageMakerを使用しデプロイし以下のいずれかの方法で予測を取得できる。
- 一度に1つの予測を行う永続的なリアルタイムエンドポイント
- SageMakerリアルタイムホスティングサービスを使用する
- トラフィックの急増の間にアイドル期間があり、コールドスタートを許容できるワークロード
- サーバレス推論を使用する
- 最大1GBの大きなペイロードサイズ、長い処理時間、ニアリアルタイムレイテンシー要件を持つリクエスト
- SageMaker非同期推論を使用する
- データセット全体の予測を取得する
- SgeMakerバッチ変換を使用する
- 一度に1つの予測を行う永続的なリアルタイムエンドポイント
- SageMakerは、リソースを管理し機械学習モデルをデプロイするときに推論パフォーマンスを最適化する機能も提供する
- 以下のようなエッジデバイスで、モデルの最適化、保護、監視、維持にはSageMaker Edge Managerを使用する
- スマートカメラ
- ロボット
- PC
- モバイルデバイス
- 以下のようなエッジデバイスで、モデルの最適化、保護、監視、維持にはSageMaker Edge Managerを使用する
Validate a Machine Learning Model
AWSドキュメントのValidate a Machine Learning Modelを元に整理します。
- モデルをトレーニングした後、モデルを評価しパフォーマンスと精度によりビジネス目標が達成できるか判断する。
- 評価には、履歴データまたはライブデータを使用できます。
- 履歴データ(オフラインテスト)
- ライブデータではなく履歴データを使用して推論のためにモデルをリクエストを送信する
- トレーニング済みモデルをアルファエンドポイントにデプロイし、履歴データを使用して推論リクエストを送信する
- Boto、SageMakerが提供するハイレベルのPythonライブラリを使用する
- ライブデータ
- 実動モデルのA/Bテストをサポートする。
- 本番バリアントは、同じ推論コードを使用して、同じSageMakerエンドポイントにデプロイされるモデル
- ライブトラフィックの一部が検証対象のモデルに送られるようにプロダクションバリアントを構成する。
- 履歴データ(オフラインテスト)
Monitoring a Model in Production
AWSドキュメントのMonitoring a Model in Productionを元に整理します。
- モデルを本番にデプロイ後、SageMaker model monitorを使用して機械学習モデルの品質をリアルタイムで継続的に監視する
- SageMaker model monitorを使用すると、データのドリフトや異常など、モデルの品質に偏差がある場合に自動アラートトリガーシステムをセットアップできる。
- CWLはモデルのステータスをモニタリングするログファイルを収集し、モデルの品質が事前に設定したしきい値に達すると通知する。
- CloudWatchは指定したS3バケットにログファイルを保存する。
Use Machine Learning Frameworks, Python, and R with Amazon SageMaker
AWSドキュメントのUse Machine Learning Frameworks, Python, and R with Amazon SageMakerを元に整理します。
- PythonとRはSageMakerノートブックカーネルででネイティブに利用できる。
実践
本ページでは、AWSドキュメントGet Started with Amazon SageMakerを参考にセットアップします。
事前準備
S3バケットの作成
SageMakerがアクセスするS3バケットを用意します。
IAMロールを作成します。
こちらを参考にIAMロールと、上記のS3バケットへのアクセスするポリシーを作成します。
Onboard to Amazon SageMaker Domain Using Quick setup
-
SageMakerトップページで左側のナビゲーションペインでコントロールパネルをクリックします。
-
高速セットアップを選択し、「送信」をクリックします。
-
ポップアップが表示されるのでVPCとサブネットを選択し完了をクリックします。
-
しばらくすると、ユーザが作成されますので、「アプリケーションを起動 > Studio」をクリックします。

-
しばらくすると、Studioが起動されます。
考察
SageMakerを調査することで、SageMakerでできることだけではなく、機械学習プロセスを学ぶことができました。
また、今回は環境のセットアップまで完了したので、次回以降、実際に手を動かし、試したいと思います。
参考