背景・目的
以前、Lake Formationについて整理しましたが、今回はハンズオンで実際に設定し挙動などを確認します。
まとめ
下記に特徴をまとめます。
| 特徴 | 説明 |
|---|---|
| DataLakeAdmins | データレイク管理者 Lake Formation では、データレイクの権限管理を行うために「Data lake administrator」という特別な管理者ロールが必要 下記の操作が可能 ・ Data Catalog のデータベース・テーブルの作成・削除 ・S3 ロケーションの登録 ・他のユーザー/ロールへの Lake Formation 権限の付与・取り消し ・Lake Formation の設定変更 |
| CreateDatabaseDefaultPermissions / CreateTableDefaultPermissions | 新しく作られた DB やテーブルに自動で付与されるデフォルト権限 IAM_ALLOWED_PRINCIPALSが入っていると、IAM ポリシーだけでアクセスできてしまう(Lake Formation の権限管理がバイパスされる) |
| CROSS_ACCOUNT_VERSION | クロスアカウント共有のバージョン |
| AllowExternalDataFiltering | 外部エンジンからのデータフィルタリング許可 |
| AthenaからOTF へのクエリ | Delta Lake のネイティブテーブル読み取りは Athena エンジン v3 からのサポート。(Iceberg と Hudi は v2 でも一部対応していた) |
| Lake Formation の権限チェック | OTF テーブルに対する Lake Formation の権限適用(テーブル・カラム・行・セルレベル)は、Athena が v3 で OTF を正しく扱えることが前提になる |
| AthenaでのLF経由の流れ | 1. ユーザーが Athena にクエリを投げる 2. Athena は Data Catalog からテーブル情報を取得 3. Athena は「このテーブルは Lake Formation に登録されているか?」を確認 4. 登録されている → Athena は Lake Formation に GetDataAccess を呼ぶ 5. Lake Formation は「このユーザーに SELECT 権限があるか?」をチェック 6. 権限あり → Lake Formation が RegisterRole の一時クレデンシャルを Athena に返す 7. Athena はその一時クレデンシャルで S3 からデータを取得 |
概要
AWS Lake Formation: 仕組み
下記を基に整理します。
AWS Lake Formation には、Amazon S3 内の基盤データを持つデータベース、テーブル、列などのデータカタログリソースへのアクセスを許可または取り消すためのリレーショナルデータベース管理システム (RDBMS) アクセス許可モデルが用意されています。管理が簡単な Lake Formation 許可は、複雑な Amazon S3 バケットポリシーや対応する IAM ポリシーに取って代わるものです。
- Lake Fomation(LF)は、S3内の基盤データを持つDB,テーブル等のアクセス許可・取り消すためのアクセス許可モデルが用意されている
Lake Formation 許可管理ワークフロー
Lake Formation は、Lake Formation に登録されている Amazon S3 データストアやメタデータオブジェクトに対してクエリを実行するために、分析エンジンと統合します。以下の図は、Lake Formation における許可管理の仕組みを示しています。
- LFはS3やメタデータオブジェクトに対してクエリを実行する分析エンジンと統合している
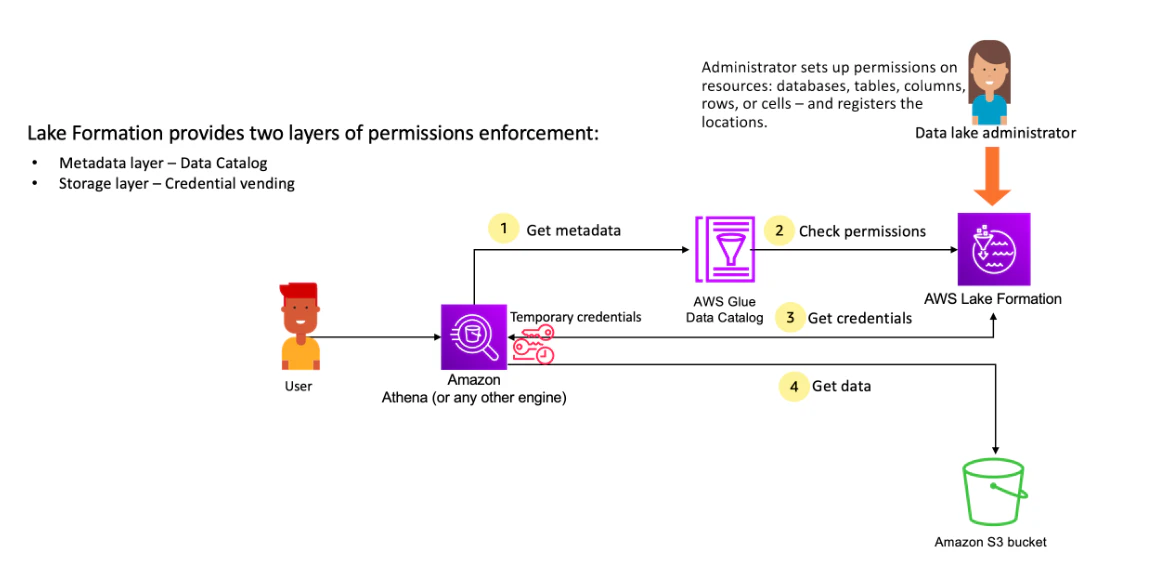
※Lake Formation 許可管理ワークフローから抜粋
Lake Formation 許可管理の手順の概要
Lake Formation がデータレイク内のデータに対するアクセス制御を提供する前に、データレイク管理者または管理権限を持つユーザーが、Lake Formation の権限を使用して Data Catalog テーブルへのアクセスを許可または拒否する個々の Data Catalog テーブルのユーザーポリシーを設定します。
- LFの権限管理を使うには、事前に管理者が「誰がどのテーブルにアクセスできるか」を設定しておく
次に、データレイク管理者または管理者から委任されたユーザーのいずれかが、Data Catalog データベースとテーブルに対するユーザーに Lake Formation 許可を付与し、テーブルの Amazon S3 ロケーションを Lake Formation に登録します。
1.メタデータの取得 — プリンシパル (ユーザー) が Amazon Athena、AWS Glue、Amazon EMR、Amazon Redshift Spectrumなどの統合分析エンジンにクエリまたは ETL スクリプトを送信します。統合分析エンジンは、要求されているテーブルを識別し、メタデータのリクエストを Data Catalog に送信します。
2.許可の確認 — Data Catalog は Lake Formation でユーザーのアクセス許可を確認し、ユーザーがテーブルにアクセスする権限を持っている場合は、ユーザーが表示できるメタデータをエンジンに返します。
3.認証情報の取得 — Data Catalog は、テーブルが Lake Formation によって管理されているかどうかをエンジンに知らせます。基盤となるデータが Lake Formation に登録されている場合、分析エンジンは Lake Formation に一時的なアクセスを許可してデータアクセスを提供するように要求します。
4.データの取得 — ユーザーがテーブルへのアクセスを許可されている場合、Lake Formation は統合分析エンジンへの一時的なアクセスを提供します。一時的なアクセスを使用して、分析エンジンは Amazon S3 からデータを取得し、列、行、またはセルのフィルタリングなど、必要なフィルタリングを実行します。エンジンはジョブの実行を終了すると、結果をユーザーに返します。このプロセスは、認証情報の供給と呼ばれます。
テーブルが Lake Formation によって管理されていない場合、分析エンジンからの 2 回目の呼び出しは Amazon S3 に対して直接行われます。関係する Amazon S3 バケットポリシーと IAM ユーザーポリシーのデータアクセスが評価されます。
- ユーザーが分析エンジンにクエリを投げる → エンジンが Data Catalog にメタデータを要求
- Data Catalog が Lake Formation に権限チェック → 許可されたメタデータのみ返す
- Data Catalog がエンジンに「Lake Formation 管理下か」を通知 → 管理下ならエンジンが一時クレデンシャルを要求
- Lake Formation が一時クレデンシャルを返す → エンジンがそれで S3 からデータ取得し、列・行・セルレベルのフィルタリングを実行
実践
AWS Lake Formationを使って、オープンテーブルフォーマット(Apache Iceberg、Apache Hudi、Delta Lake)のテーブルに対するきめ細かいアクセス制御を設定し、Amazon Athenaでクエリするまで試します。
使用するAWSサービス
利用するAWSサービスは下記のとおりです。
- Lake Formation — データレイクの権限管理
- Glue — データカタログ、ETLジョブ(テーブル作成)
- S3 — データ格納先
- Athena — SQLクエリ実行
- CloudFormation — 環境の一括構築
登場するロール
| ロール | 役割 |
|---|---|
| IAM管理者 | IAMユーザー・ロール・S3バケットの作成 |
| データレイク管理者 | Data Catalogへのアクセス、DB作成、Lake Formation権限の付与 |
| ビジネスアナリスト | Athenaでデータレイクにクエリを実行 |
実施ステップ
- 事前準備 — データレイク管理者の設定、Data Catalog設定変更、Athenaエンジンv3確認
- 環境構築 — CloudFormationテンプレートでS3バケット、Glue DB・ジョブ、IAMロール、分析ユーザーを一括作成
- Icebergテーブル — Glueジョブでテーブル作成 → S3ロケーション登録 → 権限付与 → Athenaクエリ
- ※Hudi/Delta Lake は Iceberg と同一手順のため省略
- Hudiテーブル — 同上
- Delta Lakeテーブル — 同上
- クリーンアップ — スタック削除、ロケーション登録解除
事前準備
データレイク管理者の設定
データレイク管理者を設定します。
1.まずはじめに、Lake Formation の「データレイク全体の設定」を下記のコマンドで確認します
aws lakeformation get-data-lake-settings --region ap-northeast-1
2.データレイク管理者が未設定とわかりました
{
"DataLakeSettings": {
"DataLakeAdmins": [],
"ReadOnlyAdmins": [],
"CreateDatabaseDefaultPermissions": [
{
"Principal": {
"DataLakePrincipalIdentifier": "IAM_ALLOWED_PRINCIPALS"
},
"Permissions": ["ALL"]
}
],
"CreateTableDefaultPermissions": [
{
"Principal": {
"DataLakePrincipalIdentifier": "IAM_ALLOWED_PRINCIPALS"
},
"Permissions": ["ALL"]
}
],
"Parameters": {
"CROSS_ACCOUNT_VERSION": "4",
"SET_CONTEXT": "TRUE"
},
"TrustedResourceOwners": [],
"AllowExternalDataFiltering": false,
"ExternalDataFilteringAllowList": []
}
}
DataLakePrincipalIdentifierにはご自身の環境の管理者ロール ARN を指定してください。本記事では検証用のrole/admin` を使用しています。
3.現在、DataLakeAdminsが登録されていないので、設定します
aws lakeformation put-data-lake-settings --region ap-northeast-1 \
--data-lake-settings '{
"DataLakeAdmins": [
{
"DataLakePrincipalIdentifier": "arn:aws:iam::<アカウントID>:role/admin"
}
],
"CreateDatabaseDefaultPermissions": [
{
"Principal": {
"DataLakePrincipalIdentifier": "IAM_ALLOWED_PRINCIPALS"
},
"Permissions": ["ALL"]
}
],
"CreateTableDefaultPermissions": [
{
"Principal": {
"DataLakePrincipalIdentifier": "IAM_ALLOWED_PRINCIPALS"
},
"Permissions": ["ALL"]
}
],
"Parameters": {
"CROSS_ACCOUNT_VERSION": "4",
"SET_CONTEXT": "TRUE"
}
}'
IAM_ALLOWED_PRINCIPALSの設定
デフォルトでは、Data Catalog に新しく作成されるデータベースやテーブルに対して IAM_ALLOWED_PRINCIPALS が自動付与されます。
この設定が有効だと、IAM ポリシーさえあれば Lake Formation の権限チェックをバイパスしてデータにアクセスできてしまいます。
DataLakePrincipalIdentifierにはご自身の環境の管理者ロール ARN を指定してください。本記事では検証用のrole/admin` を使用しています。
Lake Formation による細かいアクセス制御を有効にするため、このデフォルト権限を解除します。
1.下記のコマンドで設定します
aws lakeformation put-data-lake-settings --region ap-northeast-1 \
--data-lake-settings '{
"DataLakeAdmins": [
{
"DataLakePrincipalIdentifier": "arn:aws:iam::<アカウントID>:role/admin"
}
],
"CreateDatabaseDefaultPermissions": [],
"CreateTableDefaultPermissions": [],
"Parameters": {
"CROSS_ACCOUNT_VERSION": "4",
"SET_CONTEXT": "TRUE"
}
}'
2.ここまでの設定を確認します。下記が確認できました
- DataLakeAdmins
- 未設定 → role/admin
- CreateDatabaseDefaultPermissions
- IAM_ALLOWED_PRINCIPALS → 未設定
- CreateTableDefaultPermissions
- IAM_ALLOWED_PRINCIPALS → 未設定
aws lakeformation get-data-lake-settings --region ap-northeast-1
{
"DataLakeSettings": {
"DataLakeAdmins": [
{
"DataLakePrincipalIdentifier": "arn:aws:iam::<アカウントID>:role/admin"
}
],
"ReadOnlyAdmins": [],
"CreateDatabaseDefaultPermissions": [],
"CreateTableDefaultPermissions": [],
"Parameters": {
"CROSS_ACCOUNT_VERSION": "4",
"SET_CONTEXT": "TRUE"
},
"AllowExternalDataFiltering": false,
"ExternalDataFilteringAllowList": []
}
}
Athena エンジンの設定
テーブル(特に Delta Lake のネイティブテーブル)のクエリには Athena エンジン v3 以上が必要です。Lake Formation による権限チェックもこのエンジンバージョンが前提となるため、primary ワークグループの設定を確認します。
1.下記のコマンドでAthenaエンジンのバージョンを確認します
aws athena get-work-group --work-group primary --region ap-northeast-1
2.Primaryワークグループのバージョンは3でした
{
"WorkGroup": {
"Name": "primary",
"State": "ENABLED",
"Configuration": {
"EngineVersion": {
"SelectedEngineVersion": "AUTO",
"EffectiveEngineVersion": "Athena engine version 3"
}
}
}
}
環境構築
CloudFormation テンプレートを使って、チュートリアルに必要なリソースを一括作成します。リソースは下記の通り
- S3 バケット
- Glue データベース・ジョブ
- IAM ロール・ユーザー
- Lambda 関数など
※テンプレートは AWS が公開している lf-public S3 バケットのものを YAML に変換・多少加工して使用しています。
1.テンプレートを作成します
Description: CloudFormation template to create AWS Lake Formation Transactional DataLake
Tutorial Resources
Mappings:
GlueScriptLocation:
iceberg:
SourceBucket: lf-public
Prefix: scripts/
Objects: native-iceberg-create.py
hudi:
SourceBucket: lf-public
Prefix: scripts/
Objects: native-hudi-create.py
delta:
SourceBucket: lf-public
Prefix: scripts/
Objects: native-delta-create.py
Resources:
LFIcebergGlueDatabase:
Type: AWS::Glue::Database
Properties:
CatalogId:
Ref: AWS::AccountId
DatabaseInput:
Name: lficebergdb
Description: Transactional Database
CreateTableDefaultPermissions: []
・・・・
2.デプロイします
aws cloudformation create-stack --stack-name lf-otf-tutorial --template-body "file://・・・・/templates/lfotfsetup.yaml" --capabilities CAPABILITY_NAMED_IAM --region ap-northeast-1
{
"StackId": "arn:aws:cloudformation:ap-northeast-1:<アカウントID>:stack/lf-otf-tutorial/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx"
}
作成後の確認
S3バケット
1.S3バケットを確認します
aws s3api list-buckets \
--query "Buckets[?contains(Name, 'lf-otf')]"
[
{
"Name": "lf-otf-datalake-<アカウントID>",
"CreationDate": "2026-04-11T09:03:25+00:00",
"BucketArn": "arn:aws:s3:::lf-otf-datalake-<アカウントID>"
},
{
"Name": "lf-otf-tutorial-<アカウントID>",
"CreationDate": "2026-04-11T09:03:25+00:00",
"BucketArn": "arn:aws:s3:::lf-otf-tutorial-<アカウントID>"
}
]
Glueデータベース
1.Glueデータベースを確認します
aws glue get-databases \
--query "DatabaseList[?starts_with(Name, 'lf')]" \
--region ap-northeast-1
[
{
"Name": "lfdeltadb",
"Description": "Transactional Database",
"CreateTime": "2026-04-11T18:03:23+09:00",
"CreateTableDefaultPermissions": [],
"CatalogId": "<アカウントID>"
},
{
"Name": "lfhudidb",
"Description": "Transactional Database",
"CreateTime": "2026-04-11T18:03:23+09:00",
"CreateTableDefaultPermissions": [],
"CatalogId": "<アカウントID>"
},
{
"Name": "lficebergdb",
"Description": "Transactional Database",
"CreateTime": "2026-04-11T18:03:23+09:00",
"CreateTableDefaultPermissions": [],
"CatalogId": "<アカウントID>"
}
]
Glueジョブ
- Glueジョブを確認します
aws glue get-jobs \
--query "Jobs[?starts_with(Name, 'native-')].[Name,Role,GlueVersion]" \
--region ap-northeast-1
[
[
"native-delta-create",
"LF-OTF-GlueServiceRole",
"4.0"
],
[
"native-hudi-create",
"LF-OTF-GlueServiceRole",
"3.0"
],
[
"native-iceberg-create",
"LF-OTF-GlueServiceRole",
"3.0"
]
]
IAMロール・ユーザ
IAMロール・ユーザを確認します
Glueジョブの実行ロール
- Glueジョブの実行ロールを確認します
aws iam get-role --role-name LF-OTF-GlueServiceRole \
--query "Role.{RoleName:RoleName,Arn:Arn}"
{
"RoleName": "LF-OTF-GlueServiceRole",
"Arn": "arn:aws:iam::<アカウントID>:role/LF-OTF-GlueServiceRole"
}
- Iceberg/Hudi/Delta Lake のテーブルを作成する際に、Glue がこのロールで S3 へのデータ書き込みと DataCatalog へのテーブル登録を行う
- Lake Formation の GetDataAccess 権限を持ち、Lake Formation 管理下のデータにアクセスできる
- Cfn テンプレート内で Data lake administrator にも追加されている
S3ロケーションをLake Formation に登録する際に使うロール
- ロールを確認します
aws iam get-role --role-name LF-OTF-RegisterRole \
--query "Role.{RoleName:RoleName,Arn:Arn}"
{
"RoleName": "LF-OTF-RegisterRole",
"Arn": "arn:aws:iam::<アカウントID>:role/LF-OTF-RegisterRole"
}
- Lake Formation がこのロールを引き受けて S3 バケットにアクセスする
- 登録後、Lake Formation はこのロールの権限を使ってデータへのアクセスを仲介(credential vending)する
- (ユーザーが直接 S3 にアクセスするのではなく、Lake Formation がこのロール経由でアクセスを制御する。)
ビジネスアナリスト役の IAM ユーザー
- ロールを確認します
aws iam get-user --user-name lf-consumer-analystuser \
--query "User.{UserName:UserName,Arn:Arn}"
{
"UserName": "lf-consumer-analystuser",
"Arn": "arn:aws:iam::<アカウントID>:user/lf-consumer-analystuser"
}
- Athena でクエリを実行する側
- Lake Formation の権限が付与されるまではテーブルにアクセスできない
- チュートリアルでは、管理者がこのユーザーに SELECT 権限を付与した後、このユーザーでログインして Athena クエリが通ることを確認する
Icebergテーブルの設定
Glue ジョブで Iceberg テーブルを作成し、Lake Formation で権限管理を設定します。
具体的には、S3 ロケーションを Lake Formation に登録してデータアクセスを Lake Formation 経由に切り替え、分析ユーザーに SELECT 権限を付与した上で、Athena からクエリが通ることを確認します。
メタストアの設定
設定前
1.下記のコマンドで現在の状態を確認します
aws glue get-job \
--job-name native-iceberg-create \
--region ap-northeast-1 \
--query "Job.{Name:Name,Role:Role,GlueVersion:GlueVersion,DefaultArguments:DefaultArguments}"
2.結果を確認します。--enable-data-catalogが含まれていません
{
"Name": "native-iceberg-create",
"Role": "LF-OTF-GlueServiceRole",
"GlueVersion": "3.0",
"DefaultArguments": {
"--job-bookmark-option": "job-bookmark-enable",
"--target_db": "lficebergdb",
"--datalake-formats": "iceberg",
"--target_bucket": "lf-otf-datalake-<アカウントID>",
"--conf": "spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions"
}
}
ジョブの設定
1.Glue Data Catalog をメタストアとして使用する設定をジョブに設定します
aws glue update-job \
--job-name native-iceberg-create \
--region ap-northeast-1 \
--job-update '{
"Role": "LF-OTF-GlueServiceRole",
"Command": {
"Name": "glueetl",
"ScriptLocation": "s3://lf-otf-tutorial-<アカウントID>/scripts/native-iceberg-create.py",
"PythonVersion": "3"
},
"DefaultArguments": {
"--job-bookmark-option": "job-bookmark-enable",
"--target_db": "lficebergdb",
"--datalake-formats": "iceberg",
"--target_bucket": "lf-otf-datalake-<アカウントID>",
"--conf": "spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions",
"--enable-data-catalog": "true"
},
"GlueVersion": "3.0",
"WorkerType": "G.1X",
"NumberOfWorkers": 4,
"MaxRetries": 0,
"ExecutionProperty": {
"MaxConcurrentRuns": 2
}
}'
{
"JobName": "native-iceberg-create"
}
2.ジョブの設定を確認します。"--enable-data-catalog": "true",が含まれていました
aws glue get-job \
--job-name native-iceberg-create \
--region ap-northeast-1 \
--query "Job.DefaultArguments"
---
{
"--job-bookmark-option": "job-bookmark-enable",
"--enable-data-catalog": "true",
"--target_db": "lficebergdb",
"--datalake-formats": "iceberg",
"--target_bucket": "lf-otf-datalake-<アカウントID>",
"--conf": "spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions"
}
ジョブの実行
1.ジョブを実行します
aws glue start-job-run \
--job-name native-iceberg-create \
--region ap-northeast-1
---
{
"JobRunId": "jr_XXXXXXXXXXXXXXXX"
}
2.ジョブの実行結果を確認します。正常終了しました。この時点でIcebergテーブルとデータが登録されました
aws glue get-job-runs \
--job-name native-iceberg-create \
--region ap-northeast-1 \
--query "JobRuns[0].{Id:Id,StartedOn:StartedOn,CompletedOn:CompletedOn,JobRunState:JobRunState,ExecutionTime:ExecutionTime}"
---
{
"Id": "jr_XXXXXXXXXXXXXXXX",
"StartedOn": "2026-04-11T18:39:27+09:00",
"CompletedOn": "2026-04-11T18:40:51+09:00",
"JobRunState": "SUCCEEDED",
"ExecutionTime": 74
}
設定後
1.Data Catalogにテーブルが登録されました
aws glue get-table \
--database-name lficebergdb \
--name product \
--region ap-northeast-1 \
--query "Table.{Name:Name,DatabaseName:DatabaseName,StorageDescriptor:StorageDescriptor.{Location:Location},Parameters:Parameters}"
---
{
"Name": "product",
"DatabaseName": "lficebergdb",
"StorageDescriptor": {
"Location": "s3://lf-otf-datalake-<アカウントID>/transactionaldata/native-iceberg/lficebergdb.db/product"
},
"Parameters": {
"metadata_location": "s3://lf-otf-datalake-<アカウントID>/transactionaldata/native-iceberg/lficebergdb.db/product/metadata/00000-xxxxx.metadata.json",
"table_type": "ICEBERG"
}
}
S3 のパスを Lake Formation の管理下に登録
登録前は、S3 のデータへのアクセスは IAM ポリシーで直接制御されます。
登録後は、Lake Formation がアクセスを仲介するようになり、ユーザーが直接 S3 にアクセスするのではなく、Lake Formation が LF-OTF-RegisterRole を使って代わりにアクセスします
これにより、Lake Formation の GRANT/REVOKE でテーブル・カラム・行単位のアクセス制御が効くようになります。登録しないと、分析エンジン経由のアクセスも IAM ポリシーで直接評価され、Lake Formation の権限管理が適用されません。
- 下記のコマンドでS3パスを登録します
aws lakeformation register-resource \
--resource-arn arn:aws:s3:::lf-otf-datalake-<アカウントID> \
--use-service-linked-role false \
--role-arn arn:aws:iam::<アカウントID>:role/LF-OTF-RegisterRole \
--region ap-northeast-1
2.結果を確認します
aws lakeformation list-resources --region ap-northeast-1
{
"ResourceInfoList": [
{
"ResourceArn": "arn:aws:s3:::lf-otf-datalake-XXXXXXX",
"RoleArn": "arn:aws:iam::<アカウントID>:role/LF-OTF-RegisterRole",
"LastModified": "2026-04-12T09:14:22.965000+09:00",
"HybridAccessEnabled": false,
"VerificationStatus": "NOT_VERIFIED"
}
]
}
VerificationStatus: NOT_VERIFIED` は登録直後の正常な状態です。実際にデータアクセスが発生すると検証が行われます。
分析ユーザへのSELECT権限付与
1.lf-consumer-analystuser に lficebergdb.product テーブルの SELECT 権限を付与します
aws lakeformation grant-permissions \
--principal '{"DataLakePrincipalIdentifier": "arn:aws:iam::<アカウントID>:user/lf-consumer-analystuser"}' \
--resource '{"Table": {"DatabaseName": "lficebergdb", "Name": "product"}}' \
--permissions '["SELECT"]' \
--region ap-northeast-1
2.登録されました。lf-consumer-analystuserにSELECTのみになりました
aws lakeformation list-permissions \
--resource-type TABLE \
--resource '{"Table": {"DatabaseName": "lficebergdb", "Name": "product"}}' \
--region ap-northeast-1
---
{
"PrincipalResourcePermissions": [
{
"Principal": {
"DataLakePrincipalIdentifier": "arn:aws:iam::<アカウントID>:user/lf-consumer-analystuser"
},
"Resource": {
"TableWithColumns": {
"DatabaseName": "lficebergdb",
"Name": "product",
"ColumnWildcard": {}
}
},
"Permissions": ["SELECT"],
"PermissionsWithGrantOption": [],
"LastUpdated": "2026-04-12T09:17:32.365000+09:00",
"LastUpdatedBy": "arn:aws:iam::<アカウントID>:role/admin"
},
{
"Principal": {
"DataLakePrincipalIdentifier": "arn:aws:iam::<アカウントID>:role/LF-OTF-GlueServiceRole"
},
"Resource": {
"Table": {
"DatabaseName": "lficebergdb",
"Name": "product"
}
},
"Permissions": ["ALL", "ALTER", "DELETE", "DESCRIBE", "DROP", "INSERT"],
"PermissionsWithGrantOption": ["ALL", "ALTER", "DELETE", "DESCRIBE", "DROP", "INSERT"]
},
{
"Principal": {
"DataLakePrincipalIdentifier": "arn:aws:iam::<アカウントID>:role/LF-OTF-GlueServiceRole"
},
"Resource": {
"TableWithColumns": {
"DatabaseName": "lficebergdb",
"Name": "product",
"ColumnWildcard": {}
}
},
"Permissions": ["SELECT"],
"PermissionsWithGrantOption": ["SELECT"]
}
]
}
Athena で Iceberg テーブルにクエリ
Admin権限でクエリ(失敗)
Admin権限では、Select権限がついてないので最初は失敗します。
1.adminロールでクエリします
aws athena start-query-execution \
--query-string 'SELECT * FROM lficebergdb.product' \
--work-group primary \
--result-configuration '{"OutputLocation": "s3://lf-otf-tutorial-<アカウントID>/athena-results/"}' \
--region ap-northeast-1
2.実行結果を確認します。AccessDeniedExceptionが返されました
aws athena get-query-execution \
--query-execution-id XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXX \
--region ap-northeast-1
---
{
"State": "FAILED",
"StateChangeReason": "Insufficient permissions to execute the query. Principal does not have any privilege on specified resource ",
"SubmissionDateTime": "2026-04-12T09:23:11.734000+09:00",
"CompletionDateTime": "2026-04-12T09:24:31.888000+09:00",
"AthenaError": {
"ErrorCategory": 2,
"ErrorType": 1500,
"Retryable": false,
"ErrorMessage": "com.amazonaws.services.lakeformation.model.AccessDeniedException: Principal does not have any privilege on specified resource (Service: AWSLakeFormation; Status Code: 400; Error Code: AccessDeniedException; Request ID: 5c6dee7a-2068-4175-95a6-f1f3df5cd364; Proxy: null)"
}
}
Admin権限でクエリ(成功)
1.adminロールにLake Formation権限を付与します(adminは、Data Lake AdministoratorだがSELECT権限が必要)
aws lakeformation grant-permissions \
--principal '{"DataLakePrincipalIdentifier": "arn:aws:iam::<アカウントID>:role/admin"}' \
--resource '{"Table": {"DatabaseName": "lficebergdb", "Name": "product"}}' \
--permissions '["SELECT"]' \
--region ap-northeast-1
2.SELECTします
aws athena start-query-execution \
--query-string 'SELECT * FROM lficebergdb.product' \
--work-group primary \
--result-configuration '{"OutputLocation": "s3://lf-otf-tutorial-<アカウントID>/athena-results/"}' \
--region ap-northeast-1
---
{
"QueryExecutionId": "XXXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXX"
}
3.結果を確認します
aws athena get-query-execution \
--query-execution-id XXXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXX \
--region ap-northeast-1 \
--query 'QueryExecution.Status'
4.結果を取得します
aws athena get-query-results \
--query-execution-id XXXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXX \
--region ap-northeast-1
---
{
"ResultSet": {
"Rows": [
{
"Data": [
{
"VarCharValue": "product_id"
},
・・・・
4.上記の結果をまとめました
| product_id | product_name | price | category | updated_at |
|---|---|---|---|---|
| 00001 | Heater | 250 | Electronics | 1.775900... |
| 00002 | Thermostat | 400 | Electronics | 1.775900... |
| 00003 | Television | 600 | Electronics | 1.775900... |
| 00004 | Blender | 100 | Electronics | 1.775900... |
| 00005 | USB charger | 50 | Electronics | 1.775900... |
クリーンアップ
- Lake Formation の S3 ロケーション登録解除
- Lake Formation の権限取り消し(admin + analystuser の SELECT)
- S3 バケットの中身を空にする(2つ)
- CloudFormation スタック削除
- Data lake administrator の設定を解除(put-data-lake-settings で DataLakeAdmins を空に戻す) ← 追加
- IAM_ALLOWED_PRINCIPALS のデフォルト権限を元に戻す(必要に応じて) ← 追加
考察
- Data lake administrator は管理権限(権限の付与・取り消し等)のみで、テーブルデータへの SELECT は別途必要。RDS で GRANT 権限を持つ管理者が自分にも SELECT を付与しないとデータを読めないのと同じ構造
- Lake Formation 対応サービスは AWS 自社開発のもの(Athena、Redshift Spectrum、EMR、Glue)に限られ、サードパーティツールや自前アプリからは効かない
- register-resource しないと、分析エンジン経由のアクセスも IAM ポリシーで直接評価され、Lake Formation の権限管理が適用されない
参考