背景・目的
- Redshiftのクエリエディタv2を試した結果を整理する。
内容
概要
クエリエディタv2とは
公式ページには、以下のように記載されている。
結果をグラフで視覚化し、チーム内の他のユーザーとクエリを共有することで共同作業を行うことができます。クエリエディタ v2 は、以前のクエリエディタに変わるエディタです。
つまり、以下の機能があるらしい。
- グラフ
- クエリの共有
手順
- 公式ページを参考に以下の手順を試す。
- AWS アカウントの設定
- クエリエディタ v2 の操作
- クエリの作成と実行
- データレイクのクエリ
- クエリ結果の視覚化
- チームとしての共同作業と共有
1.AWSアカウントの設定
- RedshiftマネコンのサイドバーからQuery editor v2をクリックすると新しいタブに表示される。
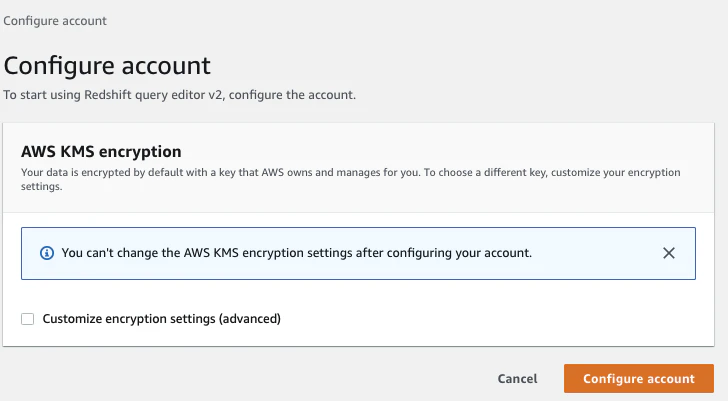
- 最初に、クエリエディタv2のリソースを暗号化するためのKMSキーの設定を行う。
なお、デフォルトではAWS管理のKMSが利用されるが、チェックボックスの「Customize encryption settings(advanced)」を選択することで顧客管理のKMSも選択が可能である。
ここでは、AWS管理のKMSするため、Configure accountをクリックする。
2.クエリエディタv2の操作
- 最初に画面を開くとダークモードの画面が表示される。
- なお、左下の月のマークをクリックすることで、ダークモードとライトモードの切り替えが可能になる。
- 個人的には、ライトモードが見やすいので、以降はライトモードで作業する。
■ダークモード
■ライトモード
データベースの作成
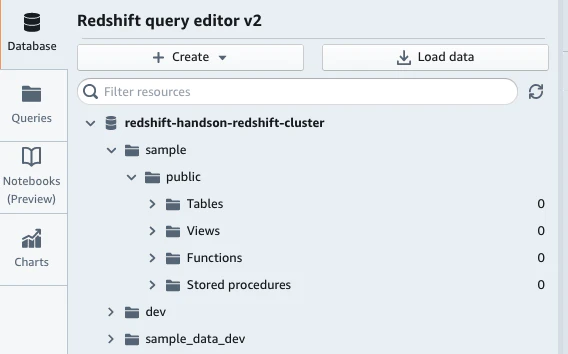
- サイドバーのDatabaseを選択するとクラスターの一覧が表示される。
- クラスタ>データベース>スキーマのツリー構造で確認が可能である。
■ Databaseを選択
- データベースの作成には、クエリエディタ上でCreate databaseを実行することで作成は可能だが、GUIでも可能になっている。
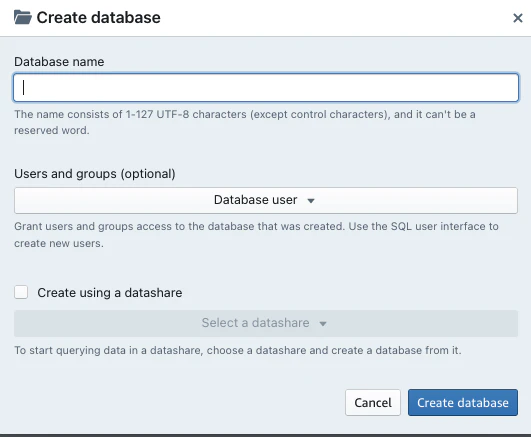
- 左上のCreate>Databaseを選択するとウィンドウが開くので、データベース名とユーザを選択して「Create database」を選択する。
■ create database
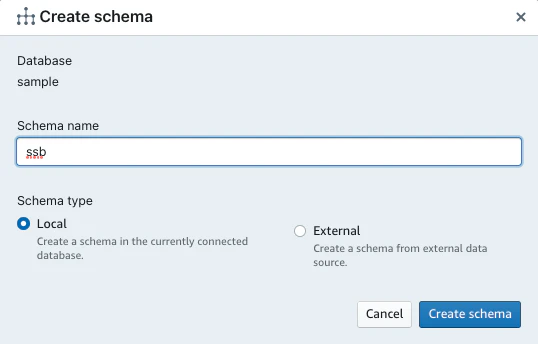
スキーマの作成
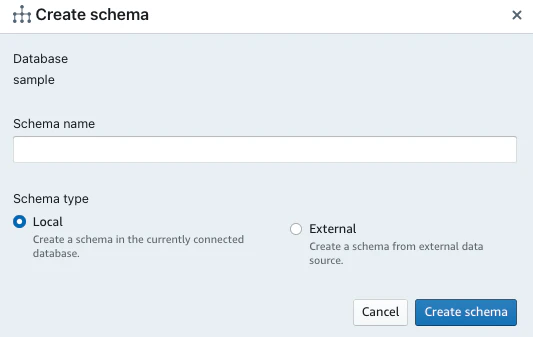
- 左上のCreate>Schemaを選択し、Schema nameを入力し、「Create schema」を選択する。
テーブルの作成
■ Create table
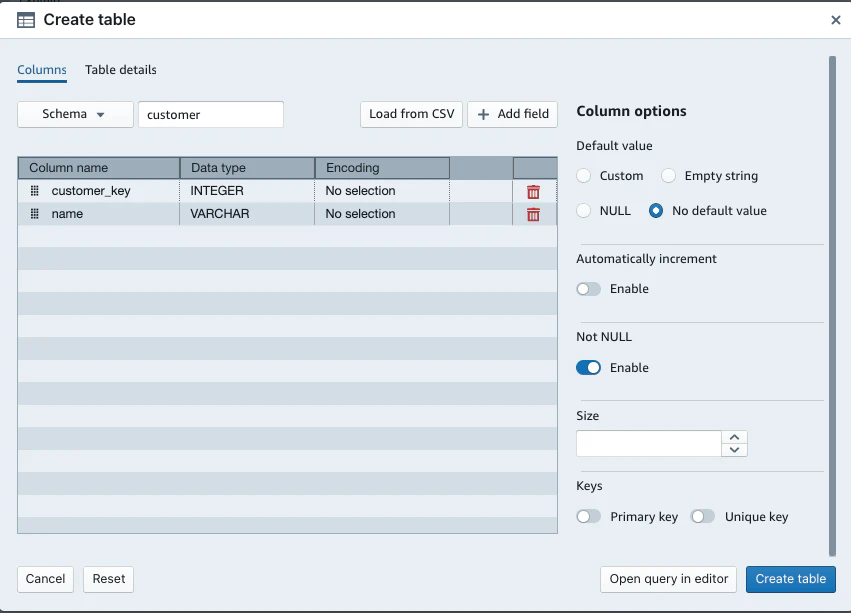
- CSVをロードしテーブルを作成することもできるが、ここではGUIからテーブルを作成する。
- 左上のCreate>Tableを選択し、以下を入力し、「Create table」を選択する。
- Schemaを選択
- Table名を入力
- Column name、Data typeを選択
3.クエリの作成と実行
データのダウンロードとアップロード
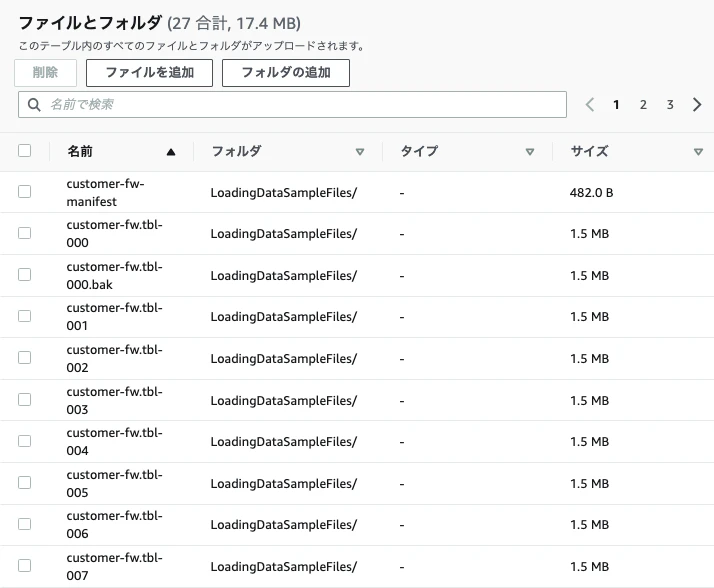
- ステップ 2: データファイルをダウンロードするからファイルをダウンロードし、自分のアカウントのS3にファイルをアップロードすする。
■ S3へアップロード
スキーマとテーブルを作成する。
- ステップ 4: サンプルテーブルを作成するを参考に、スキーマとテーブルを作成する。
- スキーマとテーブルは以下の通り
- スキーマ:ssb(スタースキーマベンチマーク)
- テーブル
- cascade
- supplier
- customer
- dwdate
- lineorder
■ ssbスキーマの作成
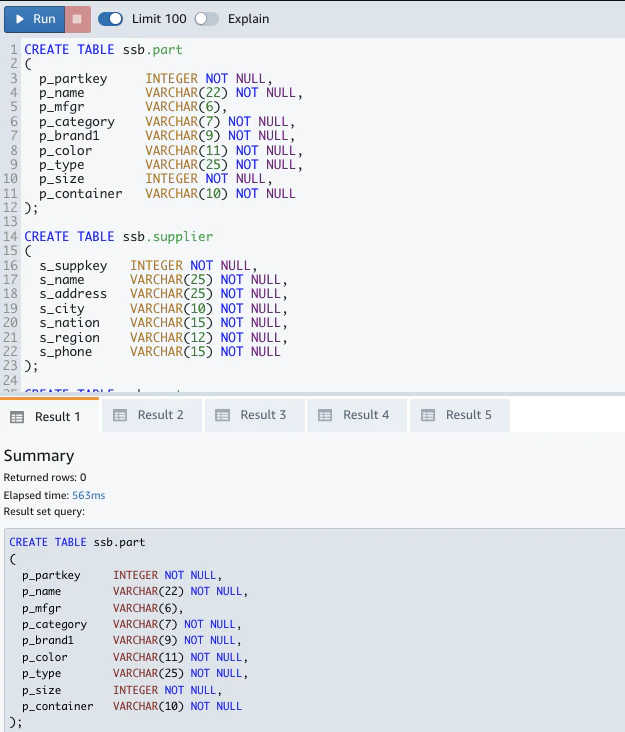
- 以下のクエリを実行しテーブルを作成する。
CREATE TABLE ssb.part
(
p_partkey INTEGER NOT NULL,
p_name VARCHAR(22) NOT NULL,
p_mfgr VARCHAR(6),
p_category VARCHAR(7) NOT NULL,
p_brand1 VARCHAR(9) NOT NULL,
p_color VARCHAR(11) NOT NULL,
p_type VARCHAR(25) NOT NULL,
p_size INTEGER NOT NULL,
p_container VARCHAR(10) NOT NULL
);
CREATE TABLE ssb.supplier
(
s_suppkey INTEGER NOT NULL,
s_name VARCHAR(25) NOT NULL,
s_address VARCHAR(25) NOT NULL,
s_city VARCHAR(10) NOT NULL,
s_nation VARCHAR(15) NOT NULL,
s_region VARCHAR(12) NOT NULL,
s_phone VARCHAR(15) NOT NULL
);
CREATE TABLE ssb.customer
(
c_custkey INTEGER NOT NULL,
c_name VARCHAR(25) NOT NULL,
c_address VARCHAR(25) NOT NULL,
c_city VARCHAR(10) NOT NULL,
c_nation VARCHAR(15) NOT NULL,
c_region VARCHAR(12) NOT NULL,
c_phone VARCHAR(15) NOT NULL,
c_mktsegment VARCHAR(10) NOT NULL
);
CREATE TABLE ssb.dwdate
(
d_datekey INTEGER NOT NULL,
d_date VARCHAR(19) NOT NULL,
d_dayofweek VARCHAR(10) NOT NULL,
d_month VARCHAR(10) NOT NULL,
d_year INTEGER NOT NULL,
d_yearmonthnum INTEGER NOT NULL,
d_yearmonth VARCHAR(8) NOT NULL,
d_daynuminweek INTEGER NOT NULL,
d_daynuminmonth INTEGER NOT NULL,
d_daynuminyear INTEGER NOT NULL,
d_monthnuminyear INTEGER NOT NULL,
d_weeknuminyear INTEGER NOT NULL,
d_sellingseason VARCHAR(13) NOT NULL,
d_lastdayinweekfl VARCHAR(1) NOT NULL,
d_lastdayinmonthfl VARCHAR(1) NOT NULL,
d_holidayfl VARCHAR(1) NOT NULL,
d_weekdayfl VARCHAR(1) NOT NULL
);
CREATE TABLE ssb.lineorder
(
lo_orderkey INTEGER NOT NULL,
lo_linenumber INTEGER NOT NULL,
lo_custkey INTEGER NOT NULL,
lo_partkey INTEGER NOT NULL,
lo_suppkey INTEGER NOT NULL,
lo_orderdate INTEGER NOT NULL,
lo_orderpriority VARCHAR(15) NOT NULL,
lo_shippriority VARCHAR(1) NOT NULL,
lo_quantity INTEGER NOT NULL,
lo_extendedprice INTEGER NOT NULL,
lo_ordertotalprice INTEGER NOT NULL,
lo_discount INTEGER NOT NULL,
lo_revenue INTEGER NOT NULL,
lo_supplycost INTEGER NOT NULL,
lo_tax INTEGER NOT NULL,
lo_commitdate INTEGER NOT NULL,
lo_shipmode VARCHAR(10) NOT NULL
);
■ テーブルの作成結果
- クエリはカンマ区切りで、連続で実行される。
- 結果は、Result1〜5タブに表示される。
COPYコマンドを実行する。
- S3からCOPYするためのIAMロールを作成する。
- S3のListBucket と GetObjectの権限が必要になる。
- COPYコマンドの構文は以下の通り
- S3のファイルはプレフィックスを指定した場合、複数ファイルを並列でロード可能。
COPY table_name [ column_list ] FROM data_source CREDENTIALS access_credentials [options]
- COPYコマンドのサンプルは以下の通り
copy table from 's3://<your-bucket-name>/load/key_prefix'
credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>'
options;
- COPY失敗時に、調査するクエリ。
select query, substring(filename,22,25) as filename,line_number as line,
substring(colname,0,12) as column, type, position as pos, substring(raw_line,0,30) as line_text,
substring(raw_field_value,0,15) as field_text,
substring(err_reason,0,45) as reason
from stl_load_errors
order by query desc
limit 10;
- MANIFESTを利用したロードサンプル
copy customer from 's3://<your-bucket-name>/load/customer-fw-manifest'
credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>'
fixedwidth 'c_custkey:10, c_name:25, c_address:25, c_city:10, c_nation:15, c_region :12, c_phone:15,c_mktsegment:10'
maxerror 10
acceptinvchars as '^'
manifest;
- MANIFESTは、以下のように、S3パスを書く。
- ※は、自分のバケットを置き換える。
{
"entries": [
{"url":"s3://<my-bucket>/LoadingDataSampleFiles/customer-fw.tbl-000"},
{"url":"s3://<my-bucket>/LoadingDataSampleFiles/customer-fw.tbl-001"},
{"url":"s3://<my-bucket>/LoadingDataSampleFiles/customer-fw.tbl-002"},
{"url":"s3://<my-bucket>/LoadingDataSampleFiles/customer-fw.tbl-003"},
{"url":"s3://<my-bucket>/LoadingDataSampleFiles/customer-fw.tbl-004"},
{"url":"s3://<my-bucket>/LoadingDataSampleFiles/customer-fw.tbl-005"},
{"url":"s3://<my-bucket>/LoadingDataSampleFiles/customer-fw.tbl-006"},
{"url":"s3://<my-bucket>/LoadingDataSampleFiles/customer-fw.tbl-007"}
]
}
– 別のリージョンからロードする。
- 事前にIAMポリシーに以下のバケットを設定しておく。
- us-east-1→ap-northeast-1で30秒弱かかった。
copy supplier from 's3://awssampledbuswest2/ssbgz/supplier.tbl'
credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>'
delimiter '|'
gzip
region 'us-west-1';
- SingleとMultiのファイルロードの違いを確認する。ほぼ同一件数で、並列処理するか否かで1m近く変わった。
- 実行前にIAMロールを変更しておく。
- Singleの結果(14,996,590件で、1m 14.2s。)
copy lineorder from 's3://awssampledb/load/lo/lineorder-single.tbl'
credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>'
gzip
compupdate off
region 'us-east-1';
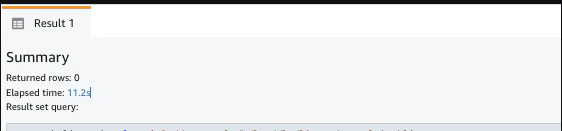
- Multiの結果(14,997,610件で、11.2s。)
copy lineorder from 's3://awssampledb/load/lo/lineorder-multi.tbl'
credentials 'aws_iam_role=arn:aws:iam::<aws-account-id>:role/<role-name>'
gzip
compupdate off
region 'us-east-1';

データベースにバキューム操作を実行し、分析する
- バキューム操作によって、削除された行から領域を回復し、ソート順序を復元する。
- ANALYZE コマンドは統計メタデータを更新し、クエリオプティマイザがさらに正確なクエリプランを生成できる。
vacuum;
analyze;
-
vacuumの結果。(7.6s)
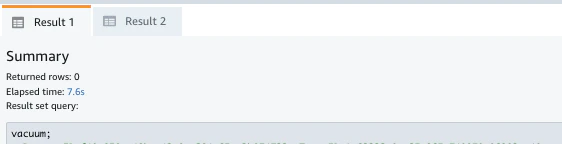
-
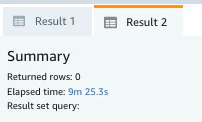
analyzeの結果。(9m 25.3s)
4.データレイクのクエリ
- 割愛
5. クエリ結果の視覚化
- クエリを実行し、右下のChartを有効化するとグラフを選択できる。(以下は、パイチャートの例)

-
画像をダウンロードするには、PNGかJPEGを選択しExportする。
-
Save chartをクリックすることで保存も可能。
-
保存した結果は、Chartsで確認可能。
6. チームとしての共同作業と共有
- クエリエディタの右上のSaveにより保存が可能。
- 保存したクエリは、Queriesで確認可能。
参考
https://docs.aws.amazon.com/ja_jp/redshift/latest/mgmt/query-editor-v2-team.html
https://docs.aws.amazon.com/ja_jp/redshift/latest/dg/tutorial-loading-data.html