背景・目的
Databricksの特徴とアカウント開設の手順を整理したでDatabricksを始める準備は整ったので、
次は、Run your first ETL workload on Databricksにあるものを、試してみました。
まとめ
- クラスタ(コンピュート)を作成し、ノートブックにアタッチする。
- ノートブックを使用してコードを実行し、その後ジョブとして実行する事が可能
概要
Databricks の運用対応ツールを使用して、データ オーケストレーション用の最初の抽出、変換、読み込み (ETL) パイプラインを開発およびデプロイする方法を学ぶ。
Cluster
Databricks クラスターは、本番 ETL パイプライン、ストリーミング分析、アドホック分析、機械学習などのデータ エンジニアリング、データ サイエンス、データ分析ワークロードを実行するための一連のコンピューティング リソースと構成を指します。
- これらのワークロードは、ノートブック内の一連のコマンドとして、または自動化されたジョブとして実行される。
- Databricks では、汎用クラスターとジョブ クラスターを区別する。
- 汎用クラスターを使用して、インタラクティブなノートブックを使用して共同でデータを分析する。
- ジョブ クラスターを使用して、高速かつ堅牢な自動ジョブを実行する。
What Auto Loader?
What Auto Loader?を参考にまとめます。
Auto Loader は、新しいデータ ファイルがクラウド ストレージに到着すると、追加のセットアップを行わずに段階的かつ効率的に処理します。
How does Auto Loader work?
Auto Loader は、新しいデータ ファイルがクラウド ストレージに到着すると、段階的かつ効率的に処理します。
Auto Loader は、下記のファイル形式を取り込む事が可能です。
| ファイル形式 | Prefix |
|---|---|
| AWS S3 | s3:// |
| Azure Data Lake Storage Gen2(ADLS Gen2) | abfss:// |
| Google Cloud Storage (GCS) | gs:// |
| Azure Blob Storage (wasbs) | wasbs:// |
| ADLS Gen1 (adl) | adl:// |
| Databricks File System (DBFS) | dbfs:/ |
| JSON | |
| CSV | |
| PARQUET | |
| AVRO | |
| ORC | |
| TEXT | |
| BINARYFILE |
Auto Loader は、cloudFiles と呼ばれる構造化ストリーミング ソースを提供します。 クラウド ファイル ストレージ上の入力ディレクトリ パスを指定すると、cloudFiles ソースは新しいファイルが到着すると自動的に処理し、オプションでそのディレクトリ内の既存のファイルも処理します。
Auto Loader は、デルタ ライブ テーブルで Python と SQL の両方をサポートしています。
Auto Loader を使用すると、数十億のファイルを処理してテーブルを移行またはバックフィルできます。 Auto Loader は、1 時間あたり数百万のファイルのほぼリアルタイムの取り込みをサポートするように拡張します。
What is the Databricks File System (DBFS)?
What is the Databricks File System (DBFS)?を元に整理します。
Databricks ファイル システム (DBFS) は、Databricks ワークスペースにマウントされ、Databricks クラスターで使用できる分散ファイル システムです。 DBFS は、Unix のようなファイルシステム呼び出しをネイティブのクラウド ストレージ API 呼び出しにマッピングする、スケーラブルなオブジェクト ストレージ上の抽象化です。
Databricks ワークスペースは、デフォルトですべてのユーザーがアクセスできる DBFS ルート ボリュームを使用してデプロイされます。 Databricks では、運用データをこの場所に保存しないことを推奨される。
What can you do with DBFS?
DBFS は、クラウド オブジェクト ストレージ URI を相対パスにマッピングすることで利便性を提供します。
- クラウド固有の API コマンドの代わりにディレクトリとファイルのセマンティクスを使用してオブジェクト ストレージと対話できるようにします。
- クラウド オブジェクト ストレージの場所をマウントして、ストレージ資格情報を Databricks ワークスペース内のパスにマップできるようにします。
- ファイルをオブジェクト ストレージに永続化するプロセスを簡素化し、クラスターの終了時に仮想マシンと接続されたボリューム ストレージを安全に削除できるようにします。
- クラスター初期化のための init スクリプト、JAR、ライブラリ、および構成を保存するための便利な場所を提供します。
- OSS 深層学習ライブラリを使用したモデルのトレーニング中に作成されたチェックポイント ファイルの便利な場所を提供します。
Mount object storage
オブジェクト・ストレージをDBFSにマウントすると、オブジェクト・ストレージ内のオブジェクトにローカル・ファイル・システム上にあるかのようにアクセスできるようになります。 マウントにはストレージへのアクセスに必要な Hadoop 構成が保存されるため、コード内またはクラスター構成中にこれらの設定を指定する必要はありません。
What is the DBFS root?
DBFS ルートは、Databricks ワークスペースのデフォルトのストレージ場所であり、Databricks ワークスペースを含むクラウド アカウントでのワークスペース作成の一部としてプロビジョニングされます。
Databricks の一部のユーザーは、DBFS ルートを「DBFS」と呼ぶ場合があります。 DBFS はクラウド オブジェクト ストレージ内のデータと対話するために使用されるファイル システムであり、DBFS ルートはクラウド オブジェクト ストレージの場所であることを区別することが重要です。 DBFS を使用して DBFS ルートと対話しますが、これらは別個の概念であり、DBFS には DBFS ルート以外にも多くのアプリケーションがあります。
DBFS ルートには、ワークスペース内でユーザーが実行するさまざまなアクションのデフォルトとして機能する特別な場所が多数含まれています。
How does DBFS work with Unity Catalog?
Unity Catalog には、外部の場所と管理されたストレージ認証情報の概念が追加され、組織がクラウド オブジェクト ストレージ内のデータに最小限の権限でアクセスできるようにします。 Unity カタログは、管理対象テーブル用の新しいデフォルトの保存場所も提供します。 一部のセキュリティ構成では、Unity Catalog で管理されるリソースと DBFS の両方への直接アクセスが提供されます。
実践
Step 1: Create a cluster
探索的データ分析とデータ エンジニアリングを行うには、コマンドの実行に必要なコンピューティング リソースを提供するクラスターを作成します。
-
ナビゲーションペインで「クラスター」をクリックします。
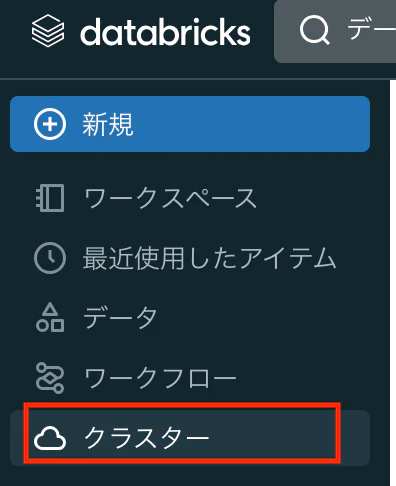
-
画面右上の、「コンピューティングを作成」をクリックします。

-
クラスタの名前をクリックし、「クラスターの作成」をクリックします。
-
しばらくすると作成されます。

Step 2: Create a Databricks notebook
対話型コードの作成と実行を開始するには、ノートブックを作成します。
-
「新規」+「ノートブック」をクリックします。
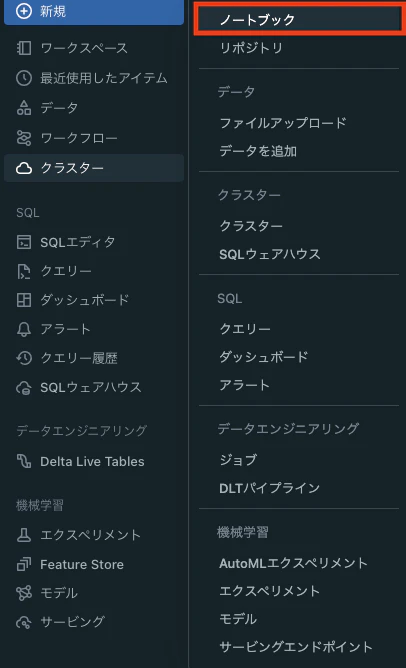
-
①ノートブックの名前を変更、②デフォルトの言語をPythonを選択します。
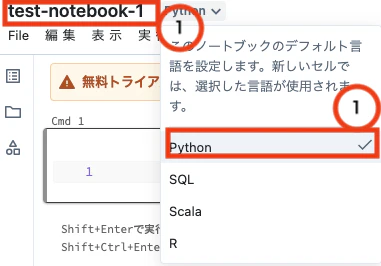
-
プルダウンから、作成したクラスタを選択し「起動」をクリックします。
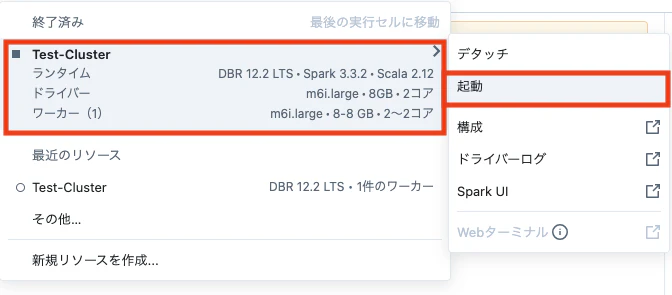
Step 3: Configure Auto Loader to ingest data to Delta Lake
Databricks では、増分データの取り込みに Auto Loader を使用と、Delta Lake でデータを保存することを推奨しています。
次の手順で、Delta Lake テーブルにデータを取り込むように Auto Loader を構成します。
-
上記で作成したノートブックを再利用します。
-
下記のコードを貼り付けて実行します。
# Import functions from pyspark.sql.functions import col, current_timestamp # Define variables used in code below file_path = "/databricks-datasets/structured-streaming/events" username = spark.sql("SELECT regexp_replace(current_user(), '[^a-zA-Z0-9]', '_')").first()[0] table_name = f"{username}_etl_quickstart" checkpoint_path = f"/tmp/{username}/_checkpoint/etl_quickstart" # Clear out data from previous demo execution spark.sql(f"DROP TABLE IF EXISTS {table_name}") dbutils.fs.rm(checkpoint_path, True) # Configure Auto Loader to ingest JSON data to a Delta table (spark.readStream .format("cloudFiles") .option("cloudFiles.format", "json") .option("cloudFiles.schemaLocation", checkpoint_path) .load(file_path) .select("*", col("_metadata.file_path").alias("source_file"), current_timestamp().alias("processing_time")) .writeStream .option("checkpointLocation", checkpoint_path) .trigger(availableNow=True) .toTable(table_name)) -
下記のクエリを実行して、データが取得できたか確認します。
df = spark.sql("select * from {0}".format(table_name)) df.printSchema() df.show() -
取得できました。

Step 4: Process and interact with data
通常のノートブックと変わらないため、省略します。
Step 5: Schedule a job
Databricks ノートブックを Databricks ジョブのタスクとして追加することで、Databricks ノートブックを運用スクリプトとして実行できます。 下記のステップで、手動でトリガーできる新しいジョブを作成します。
-
ヘッダーの右側のスケジュールをクリックします。

-
下記を入力し、「作成」をクリックします。
- Job名:任意
- スケジュール:手動
- クラスタ:作成したクラスタを指定

-
画面右上にポップアップが表示されるので、「今すぐ実行」をクリックします。

-
終わるとタイムスタンプが表示されるので、クリックしジョブの実行結果を確認します。

-
下記のように、ステータスや実行時間などがわかります。
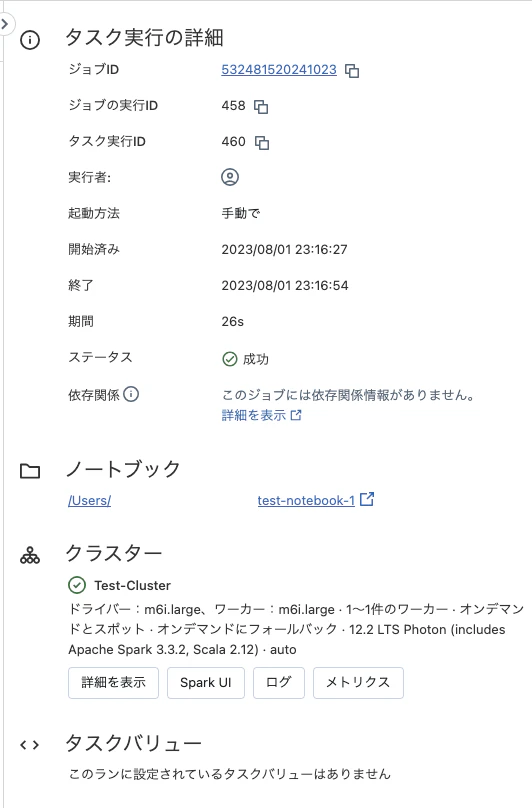
ワークフローを確認する。
上記で、ノートブックをジョブとして実行したので、ワークフローで実行結果を確認します。
-
ナビゲーションペインで、ワークフローを確認します。
-
ワークフローの画面では、ジョブの一覧が表示されます。ジョブ名をクリックします。

-
過去のジョブの実行結果が確認できます。

考察
今回は、ETLワークロードのチュートリアルを試してみました。まだまだ操作に不慣なため、理解のため引き続き試していこうと思います。
参考