背景・目的
モダンデータスタックや、Data Mesh等のワードが数年前から聞くようになったのですが暫く調べていませんでした。
このタイミングで、簡単に概要を整理しようと思います。
まとめ
- データウェアハウス、データレイクは、モノリシックで中央型のアーキテクチャ
- 運用型システムでは、分散化が進んだが、データプラットフォームでは依然として中央集権型。これにより以下の課題がある
- データ提供までのアジリティ
- 変更に対する影響範囲
- 上記の課題によりビジネス価値が既存している可能性がある。
- パラダイムシフトが必要で、データプラットフォームでもドメイン指向の考えを取り入れることにより分散化が可能。
概要
How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh をもとに整理します。
The current enterprise data platform architecture
- 現在のデータレイクは、ドメインに関係ないモノリシックで中央型のアーキテクチャである。
- 現在に至るまで以下の世代がある。
- 第1世代:
- 独自のエンタープライズDWH、BIプラットフォーム
- 少数の専門家やグループだけが理解できる何千もの維持不可能なETLジョブ、テーブル、レポートの技術的負債がある。
- 第2世代:
- ビックデータエコ知っステム
- 高度に専門化されたデータエンジニアの中央チームにより運営される長時間実行されるバッチジョブによりデータレイクが作成される
- 第3世代:
- 前世代までの根本的な特性は含む
- リアルタイムデータのストリーミング
- データ変換のバッチとストリームの統合に向けたApache Beamを使用している
- ストレージ、データパイプラインの実行エンジン、機械学習PFのクラウドベースのマネージドサービスを採用している
- 第1世代:
Architectural failure modes
上述したデータPFが持つ特性を次に記載する。
Spotify,SoundCloud,Apple iTunesなどのインターネットメディアストリーミングビジネスを例にしている。
Centralized and monolithic
- 集中型アーキテクチャは以下のことを目標にしている。
- 以下のような企業の隅々からデータを取り込むこと。
- ビジネスを実行する運用システム
- トランザクション システム
- ドメイン
- または企業の知識を増強する外部データ プロバイダー
- たとえば、メディア ストリーミング ビジネスでは、データ プラットフォームは、以下を取り込む役割を果たす。
- メディア プレーヤーのパフォーマンス
- ユーザーがプレーヤーとやり取りする方法
- 再生する曲
- フォローするアーティストなど
- ビジネスがオンボーディングしたレーベルとアーティスト
- アーティストとの金融取引
- 顧客人口統計情報などの外部市場調査データなど
- ソースデータをクレンジング、強化、変換を行い、様々な消費者のニーズに対応できる信頼できるデータにする。
- 例えば、ユーザインタラクションのクリックストリームを意味のあるセッションに変換をかけて、ユーザの行動を集約ビューに統合する。
- 様々なニーズを持つコンシューマーにデータセットを提供する。
- 分析、インサイトを求めるデータの探索、機械学習ベースの意思決定、ビジネスのパフォーマンスを要約するビジネスインテリジェンスレポートなど
- 例えば、メディアストリーミングでは、Kafkaなどの分散ログインターフェイスを介して、世界中のメディアプレーヤーに関するニアリアルタイムのエラー、品質情報を提供したり、金銭的支払い計算を促進するために再生されている特定のアーティストのレコードの静的な集計ビューを提供したりする。
- 以下のような企業の隅々からデータを取り込むこと。
- 運用システムでは、ドメイン駆動設計と境界づけられたコンテキストを運用システムに適用してきた。しかしデータプラットフォームはドメインの概念を無視してきた。ドメイン指向のデータ所有権から、ドメインにとらわれない集中型のデータ所有権に移行してきた。(最大のモノリスであるビックデータプラットフォームを作成している。)
- 集中型モデルは、多様な消費ケースが少ない単純なドメインを持つ組織では機能するが、豊富なドメイン、多数のソース、多様な消費者セットを持つ企業では機能しない。
- 集中型データPFのアーキと組織構造には、失敗につながる2つのプレッシャーポイントがある
- ユビキタスデータとソースの急増
- より多くのデータがユビキタスに利用可能になるにつれて、全てを消費し、1つのプラットフォームの制御下で1箇所で調和させる能力が低下する。
- データを一箇所に取り込むことでアジリティが低下する。
- 組織のイノベーション アジェンダと消費者の急増
- 様々なニーズにより、プラットフォーム上のユースケースが増える。これによりデータの変換数が増え続けることを意味をして、その結果ニーズを満たすための応答時間が課題になる。
- ユビキタスデータとソースの急増
Coupled pipeline decomposition
- 従来のデータPFは、処理ステージのパイプラインに分解するが、それに合わせて組織を割り当てスケールさせアジリティを高めようとしている。
- ある程度までなどは機能するが、機能の提供を遅らせる固有の制限がある。
- パイプラインのステージ間の結合が高く、独立した機能または価値を提供する。
- 運用システムでは、ドメイン単位に拡張するが、パイプラインでは全てのコンポーネントを変更する必要があり、クレンジングのための準備、ポッドキャストの再成立を表示するための集計を導入する必要がある。
Siloed and hyper-specialized ownership
- プラットフォームを構築して所有するチームをどのように構成するかに関連する。
- 組織的なサイロ化に加えて、ビックデータツールの技術的専門知識に基づいてチームに分かれてグループ化されており、多くの場合、ビジネスやドメイン知識が不足している。
- データPFエンジニアは、ソース側の機能横断型のチームがあり、コンシューマー側は部門横断的なチームが配置され、その中間に位置し、全てのソースとコンシューマー側に適切なデータを提供するために多大な努力を払っている。
The next enterprise data platform architecture
- 上記のArchitectural failure modesに対してパラダイムシフトが必要
- エンタープライズデータプラットフォームアーキテクチャは、下記の特徴がある。
- 分散ドメイン駆動型アーキテクチャ
- セルフサービスプラットフォーム
- プロダクト指向
- 運用システムでは、技術基盤を最新化するうえでプラスの影響を与えてきた。これらをデータの世界にも適用してパラダイムシフトする。
Data and distributed domain driven architecture convergence
Domain oriented data decomposition and ownership
- 運用システムでは、ドメイン指向の分解と所有系を採用しているがデータシステムでは採用されていない。
- ドメイン境界コンテキストは、データセットの所有権を設計するための非常に強力なツール
- モノリシックなデータプラットフォームを分散化するには、データの局所性と所有権に関する考え方を逆転させる必要がある。
- ドメインから一元的に所有されているデータレイク、プラットフォームにデータを流す代わりに、ドメインは簡単に利用できる方法でドメインデータセットをホスト及び提供する必要がある。
- ドメイン側でデータセットと所有権は保有し、コンシューマーは、Pullでデータを利用する。
- 従来のETLを介した取り込みからシフトする。
Source oriented domain data
- ソース指向のドメインデータ
- ドメインの概念とソースシステムは1:1ではない。
- ドメインに属するデータの一部を提供するシステムが多数ある。
- 複数あるため最終的にはまとまりのあるドメインに沿ったデータセットに集約する必要がある。
- ビジネスファクト
- ビジネスドメインイベントとして提示するのが最適
- 許可されたコンシューマーがアクセスできるタイムスタンプ付きのイベントの分散ログとして保存および提供できる。
- ソースデータドメイン
- 時間指定されたイベントに加えて、ソースドメインデータセットの簡単に使用できる履歴スナップショットも提供する必要がある
- ドメインの変更間隔を厳密に反映する時間間隔で集計される
- 時間指定されたイベントに加えて、ソースドメインデータセットの簡単に使用できる履歴スナップショットも提供する必要がある
- ソースアラインドメインデータセット
- 内部ソースシステムのデータセットから分離する必要がある
- ドメインデータセットの性質は、運用システムがジョブを実行するために使用する内部データとは大きく異なる。
- はるかに大きなボリュームを持ち、普遍の次元のある事実を表し、システムよりも頻繁に変更されない特徴がある。そのため実際の基盤となるストレージはビックデータに適したものであり、既存の運用データベース(例:OLTP)から分離されている必要がある。
- ソースドメインおデータセット
- 最も基本的なデータセット
- ビジネスの事実はそれほど頻繁に変更されないため、余り頻繁に変更されない
- これらのドメインデータセットは永続的に取得して利用できるようにすることが期待される。
- 作成時点のRawデータを厳密に表し、特定のコンシューマー向けに適合またはモデル化されていない。
- ビジネスファクト
Consumer oriented and shared domain data
- 一部のドメインは、コンシューマと密接に連携している。
- コンシューマードメインデータセットは、ソースドメインデータセットとは異なる性質を持つ。
- 特定のアクセスモデルに適合するビューと構造を集約する
- ドメイン指向データプラットフォームは、これらのコンシューマーデータセットをソースから簡単に再生成できる必要がある。
- 例
- ユーザー同士のソーシャルなつながりに基づいてレコメンデーションを提供することに焦点を当てたソーシャルレコメンデーションドメインでは、特定のニーズに合ったドメインデータセットを生成する。
- ユーザのソーシャルネットワークのグラフ表現を通じて、レコメンデーションのユースケースにも役立つが、リスナー通知ドメインにも役立つ可能性がある。
- ユーザソーシャルネットワークは、複数のコンシューマーが使用できるように共有され、新たに具体化されたドメインデータセットになる可能性がある。
- ユーザー同士のソーシャルなつながりに基づいてレコメンデーションを提供することに焦点を当てたソーシャルレコメンデーションドメインでは、特定のニーズに合ったドメインデータセットを生成する。
Distributed pipelines as domain internal implementation
- データセットの所有権は中央のプラットフォームからドメインに委任されるが、データのクレンジング、準備、集約、提供、データパイプラインは必要。
- データパイプラインは、ドメイン内で実装っされる。その結果、データパイプラインステージが各ドメインに分散される
- 例えば、ソースドメインにはドメインイベントのクレンジング、重複排除、強化を含める。これによりクレンジングのレプリケーション無しで、他のドメインがそれらをコンシュームできる。
- 各ドメインデータセットは、提供するデータの品質(適時性、エラー率など)に関するサービスレベル目標を確立する必要がある。
Data and product thinking convergence
- データの所有権とデータパイプラインの実装をビジネスドメインに分散させることは、分散されたデータセットのアクセシビリティ、使いやすさ、調和に関する重要な概念を引き起こす。
Domain data as a product
- 運用ドメインはプロダクト指向を組織に組み込んだ。
- 例
- 発見可能でわかりやすいAPIドキュメント
- APIテストサンドボックス
- 追跡された品質と採用のKPI
- 分散データプラットフォームが成功するためには、ドメインデータチームは提供するデータセットに同様の厳密さでプロダクト指向の考え方を適用する必要がある。
- データを資産とみなして、組織のデータサイエンティスト、ML、データエンジニアを顧客とみなす。
- あらゆる技術プロダクトの重要な品質は、コンシューマーを喜ばせること。ここで言うコンシューマーはMLエンジニア、データサイエンティスト。
- コンシューマに最高のユーザエクスペリエンスを提供するには、ドメインデータ製品に次の基本的な品質が必要。
- ドメインデータプロダクトには次の非基本的な品質が必要
Discoverable
- 発見可能性
- 簡単に見つけられる必要がある。
- 一般的には以下のメタ情報を含む全ての利用可能なデータプロダクトのレジストリ、データカタログを持つこと
- 所有者
- 期限
- 系統
- サンプルデータセット
- 各ドメインデータプロダクトは、簡単に見つけられるように一元化されたデータカタログに登録する必要がある
Addressable
- アドレス可能であること
- データプロダクトが発見された後、ユーザがプロダクトアクセスできるようにするためのグローバルな規則に従って、一意のアドレスを持つ必要がある。
- 組織はデータの基礎となるストレージと形式に応じて、データに異なる命名規則を採用する場合がある
- 使いやすさを目的とした場合、分散型アーキテクチャは共通の規約を策定する必要がある。
Trustworthy and truthful
- データプロダクトの所有者が、許容可能なサービスレベル目標(SLO)を提供する必要がある。
- データ生成とリネージをメタデータとして提供することで、コンシューマーはデータプロダクトとその特定のニーズに対する適合性に対する信頼性を高めることができる。
Self-describing semantics and syntax
- データのセマンティクスと構文が十分に記述されている必要がある。これによりセルフサービスでデータを提供できる
Inter-operable and governed by global standards
- 分散データアーキテクチャにおける主な懸念の一つとしては、複数ドメインに共通のドメインが登場する。(例えば顧客など)
- そのために、ドメイン間の同一IDアクセスが必要になる。。これにより結合ができる。
- そのためには、ドメイン横断で、合意された統合可能なIDを降ることや、一位のグローバルフェデレーションエンティティIDを使用するなどがある
Secure and governed by a global access control
- 分散型ドメイン指向データプロダクトでは、アクセス制御がより細かい粒度で適用される。
- ここのデータセット製品に対してアクセス時にアクセス制御ポリシーを適用する。
- SSOと、アクセス制御ポリシー定義を使用することでアクセス制御を実装するのに便利。
Domain data cross-functional teams
- データプロダクトの所有者は、データプロダクトの成功基準とビジネスに合わせたKPIを定義する必要がある。
- 例)データプロダクトのコンシューマーがデータプロダクトを発見して正常に使用するまでのリードタイム等
- ドメインの内部のデータパイプラインを構築して運用するにはデータエンジニアが必要。
Data and self-serve platform design convergence
- データ所有権をドメインに分散する際の主な懸念事項としては、各ドメインでデータパイプラインのテクノロジースタックとインフラを運用するために必要な労力とスキルセットが重複すること。
- ドメインにとらわれないインフラ機能を収集してデータインフラに抽出することでパイプラインエンジン、ストレージ、ストリーミングインフラを設定する労力を重複させる必要がなくなる。データインフラチームはドメインがデータ製品を取得、処理、保存、提供するために必要な技術を所有し、提供することができる。
- プラットフォームとして構築するポイント
- ドメインの固有の概念、ビジネスロジックを含めない
- プラットフォームがすべての基礎となる複雑さを隠蔽し、データインフラコンポーネントを提供すること
- セルフサービスデータインフラの成功基準は、インフラ上で新しいデータ製品を作成するためのリードタイムを短縮すること
- これにより、データ製品を実装するために必要な自動化につながる。
- プラットフォームとしてのセルフサービスデータインフラが、ユーザに提供する機能のリスト例は以下の通り
- Scalable polyglot big data storage
- Encryption for data at rest and in motion
- Data product versioning
- Data product schema
- Data product de-identification
- Unified data access control and logging
- Data pipeline implementation and orchestration
- Data product discovery, catalog registration and publishing
- Data governance and standardization
- Data product lineage
- Data product monitoring/alerting/log
- Data product quality metrics (collection and sharing)
- In memory data caching
- Federated identity management
- Compute and data locality
The paradigm shift towards a data mesh
- データメッシュプラットフォームは、分散型データアーキテクチャ。相互運用性のための集中型ガバナンスと標準化のもとにある。
- 共有、調和されたセルフサービスデータとインフラによって実現される。
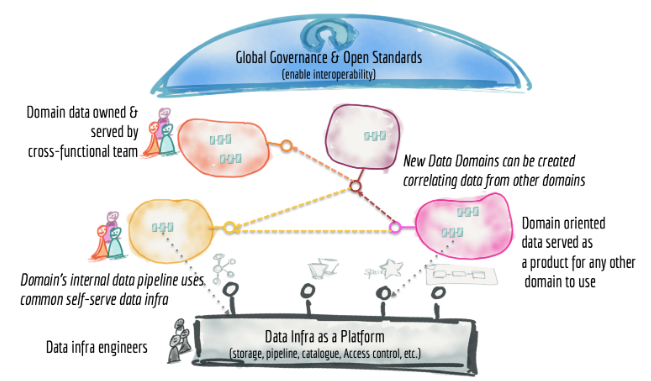
出典:Figure 12: Data mesh architecture from 30,000 foot view - 元のデータを保持する分散ログとストレージは、プロダクトとして様々なアドレス指定可能な不変なデータセットからの探索に利用できるため、データレイクが必要ない可能性は非常に高い。
- ラベル付などさらなる調査するために、データの元の形式に変更を加える必要がある場合、そのような必要があるドメインは独自のデータレイクまたはデータハブを作成する可能性がある。
- データレイクは、アーキテクチャ全体の中心ではなく、普遍データを探索や分析用途に利用できるようにするなど、データレイクの原則の一部をソース指向の内部実装または共有データインフラの一部としてデータレイクツールを引き続き使用する。
- パライダイムシフトは、新しい言語を伴う一連の新しい管理原則が必要
- serving over ingesting
- discovering and using over extracting and loading
- Publishing events as streams over flowing data around via centralized pipelines
- Ecosystem of data products over centralized data platform
考察
- ドメイン指向に基づき、各ドメイン内にデータエンジニアリングを導入することは理解できたが、複数ドメインからコンシュームするにはどうすればよいか。また、データカタログやデータリネージはどのようなものを利用するのが良いのか。具体的な実装する方法が気になったので引き続き調査したい。
参考