Azure Machine Learningとは
Azureでサービス提供している機械学習サービスであり、自動機械学習機能やGUIやNotebookによるモデル開発をサポートしています。モデルのデプロイもワンクリックで実行可能、学習周りのアセット(データ・実験・パイプライン・モデル等)管理も充実と、機械学習のライフサイクルをEnd-to-Endに行うことが可能となっています。
デザイナー
モジュールを配置しその入出力を正しく繋ぐことで学習と評価までのパイプラインを構築できます。以下のようなイメージです。
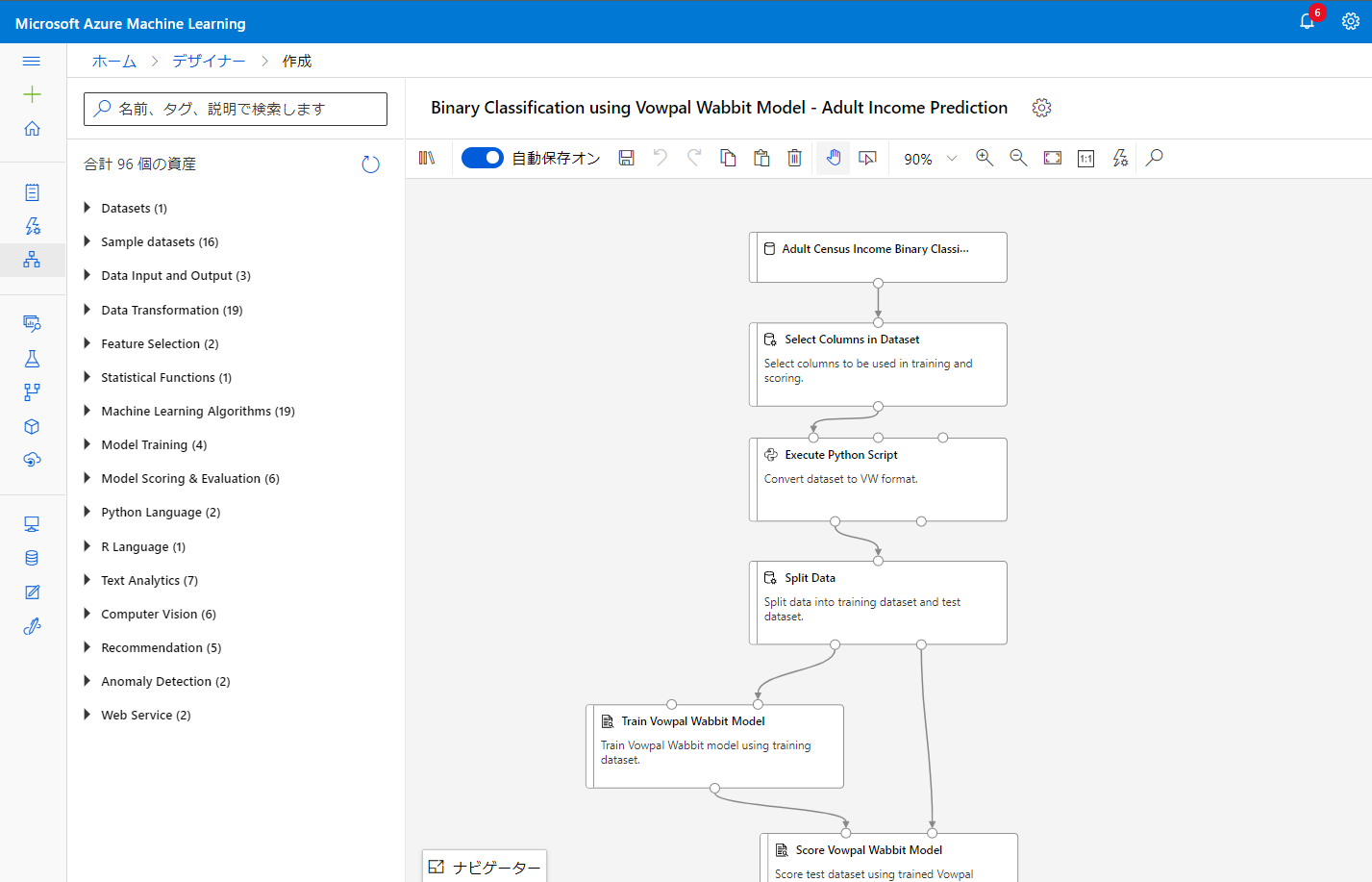
来客者数予測
来客者数予測はtoCの世界ではよく上がるテーマだと思いますのでこのシナリオに沿って実験してみます。
データ準備
小売店での来客者数予測を想定し、説明変数は日付、曜日、気候情報を用います。目的変数は来客者数ですが実際のデータは手元にないため、ランダムのサンプルデータを作成してあくまで流れの確認という意味で実験します。
気候情報には気象庁が公開しているデータを用います。データ取得用Webアプリがしっかりしていて驚きました。
個人的な理由により大阪のデータを半年ほど取得しました。
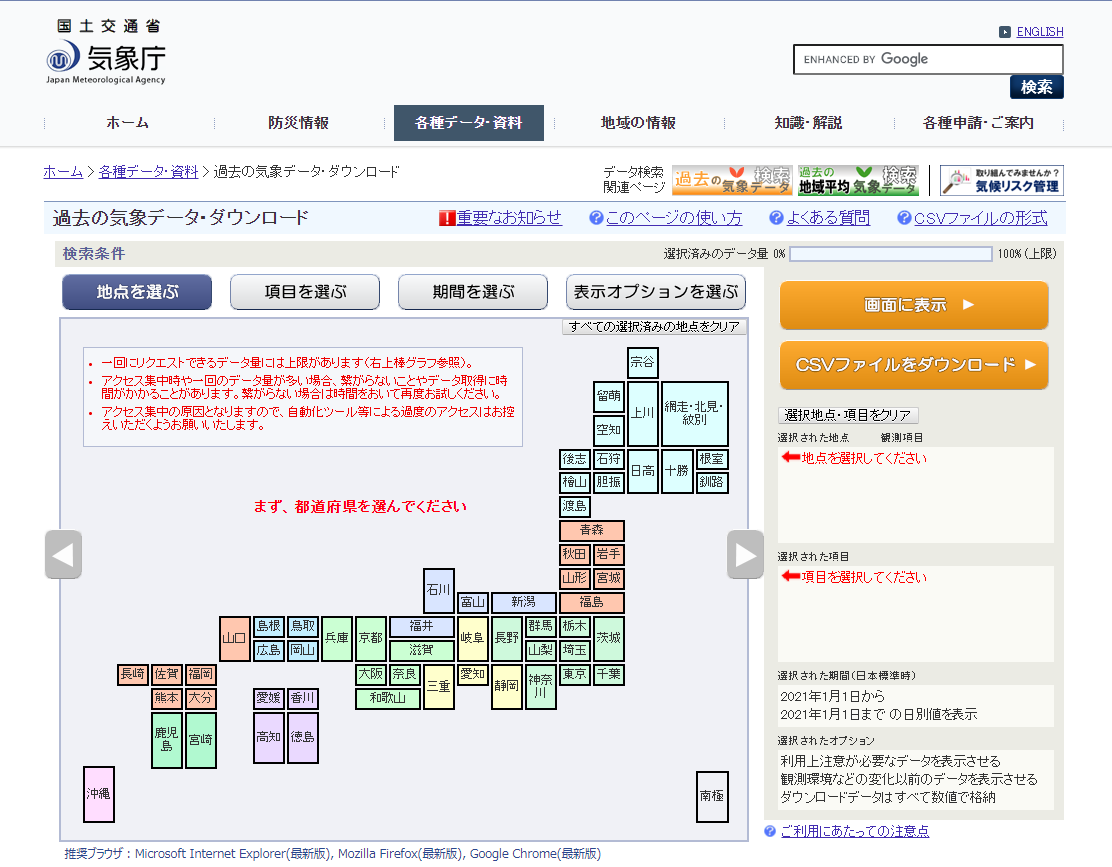
ダウンロードしたCSVファイルを開くと余分な空白行や空白列が入っていたりするため、Excel等で成型します。エンコーディングもUTF-8として再度出力します。ExcelはUTF-8 CSVで出力可能です。
もちろんこの時点では来客者数に相当するデータは入っていないのでExcel上もしくはPython等でコードを書いてランダムな数列を来客者数カラムとして追加します。私はNotebook上でPandas使って実装しました。
年月日,曜日,平均気温(℃),最高気温(℃),最低気温(℃),降水量の合計(mm),最深積雪(cm),平均雲量(10分比),来店者数
2020-10-01,木,21.9,27.7,17.7,2.0,0,4.3,497
2020-10-02,金,22.6,27.8,17.1,0.0,0,0.8,511
2020-10-03,土,23.6,27.3,19.6,0.0,0,9.0,1523
2020-10-04,日,24.1,27.4,21.7,0.0,0,9.5,116
2020-10-05,月,22.5,26.4,17.2,0.0,0,6.8,1299
2020-10-06,火,19.5,24.7,16.0,0.0,0,4.5,298
2020-10-07,水,19.4,24.3,15.6,5.0,0,7.0,1359
2020-10-08,木,16.0,16.9,15.1,42.0,0,10.0,421
2020-10-09,金,18.4,20.1,16.7,55.5,0,10.0,1196
2020-10-10,土,20.7,24.3,18.1,34.5,0,10.0,420
このデータをAzure Machine Learning上で利用するため、Azure Blob Storageにアップロードしておきます。
Azure ML
データストアとデータセット登録
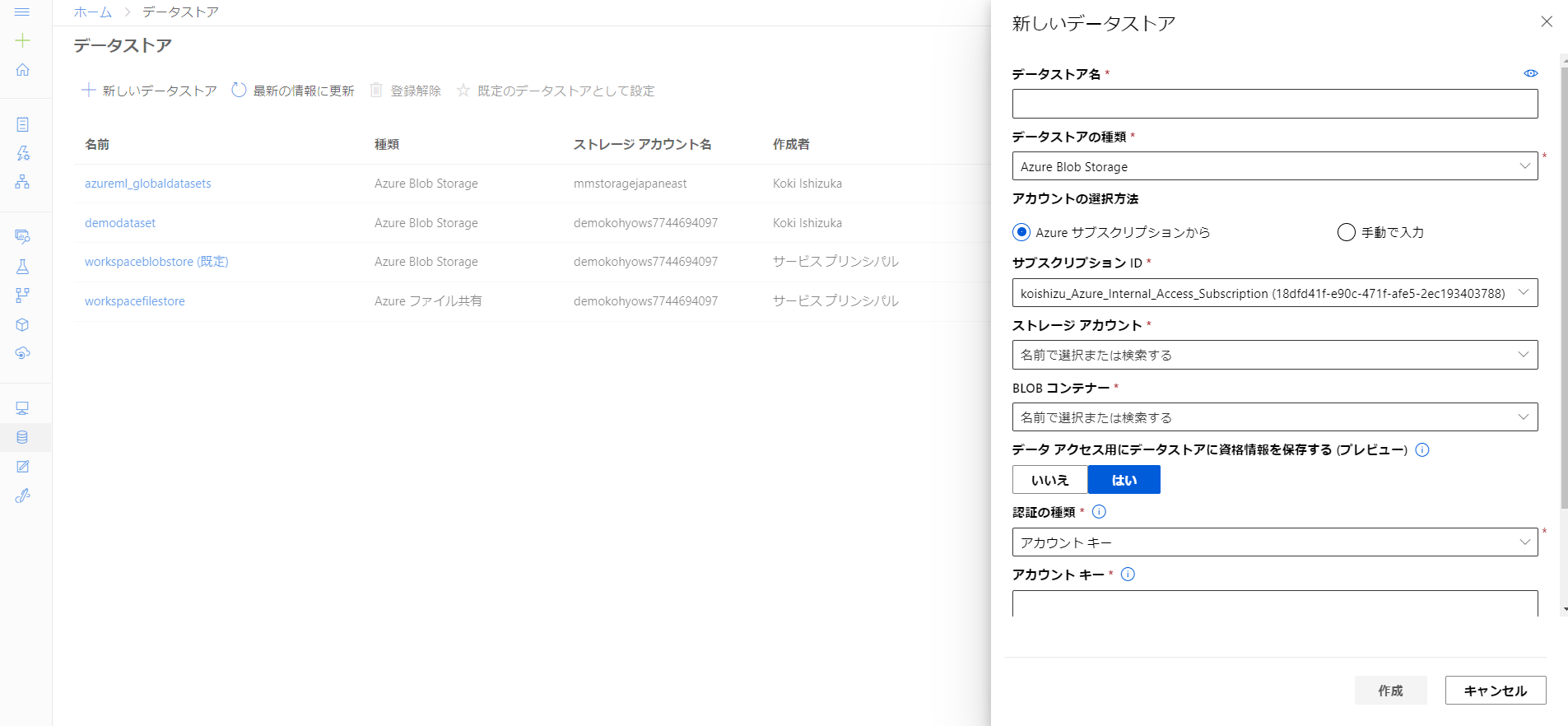
先ほどBlob StorageにアップロードしたデータをAzure ML Workspaceに登録します。データストアはBlob Storageのコンテナ単位での登録となるため、先ほどデータをアップロードしたコンテナを参照しアカウントキーを入力します。裏でKey Vaultが動いているため一度登録してしまえばこのワークスペースからはデータストアに自由にアクセスできるようになります。
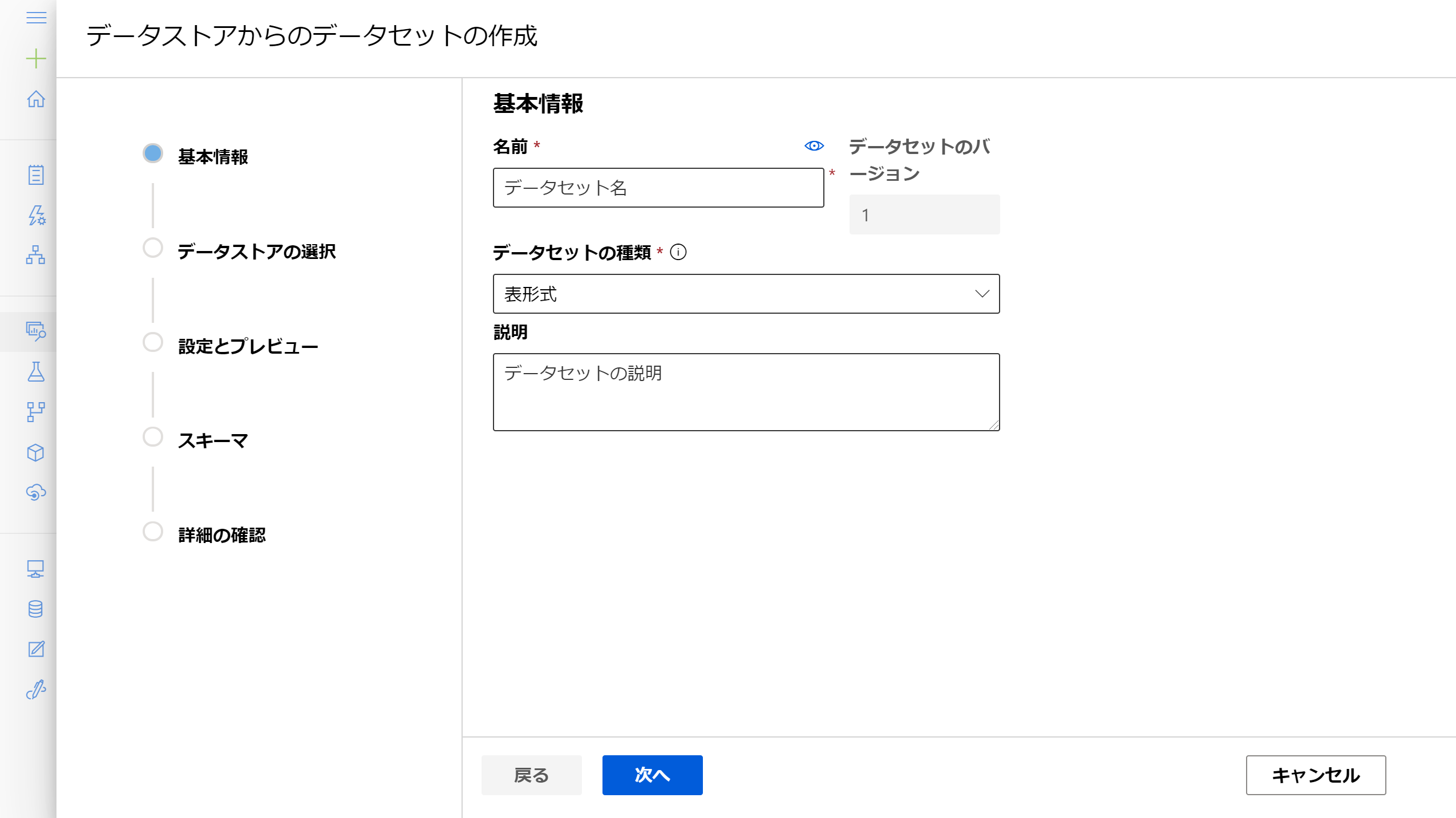
データセットのタブからコンテナ内のファイルを基にデータセットを作成します。データセットとして登録することでデータ自体のバージョン管理であったり、ワークスペース内の関連リソースからの呼び出しが楽になったりします。
デザイナーによるモデル開発
先に実際に構築したモジュールの全体像をお見せした上でそれぞれのモジュールの役割を説明します。
全体像
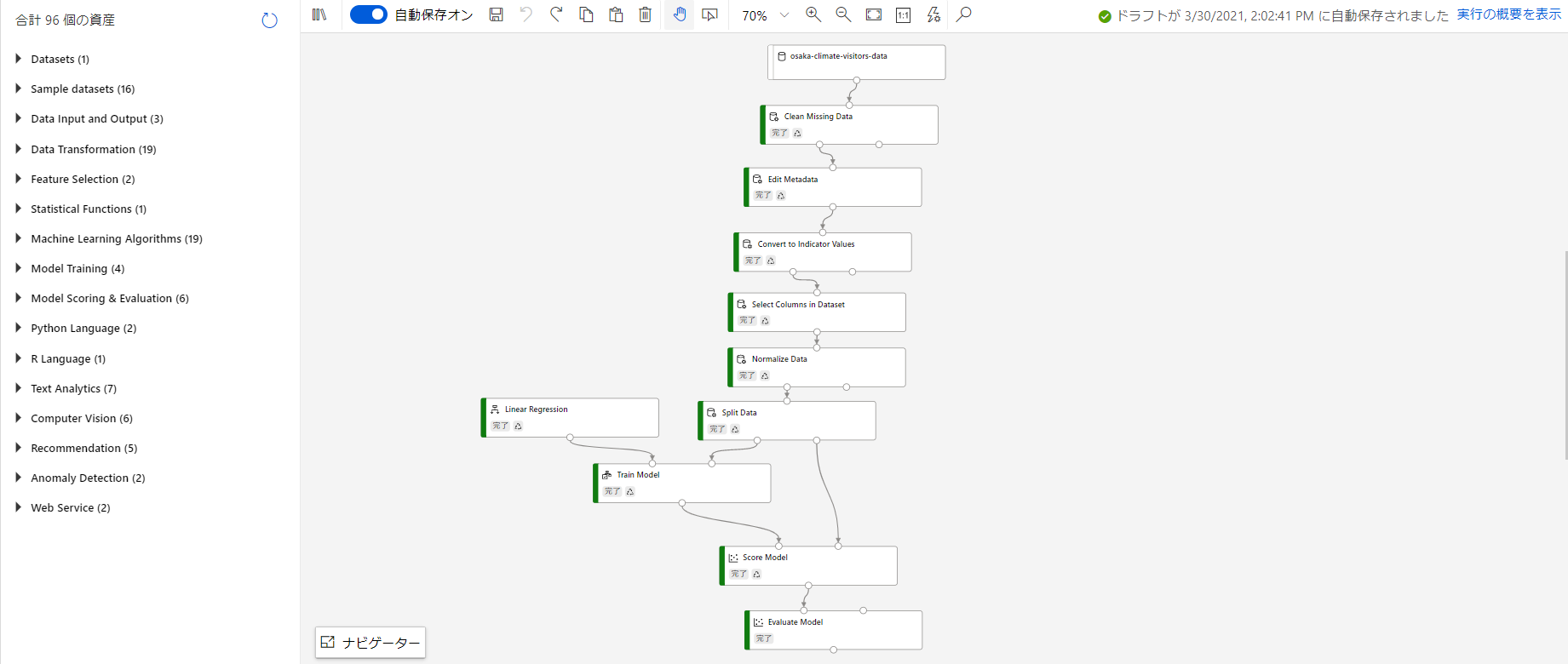
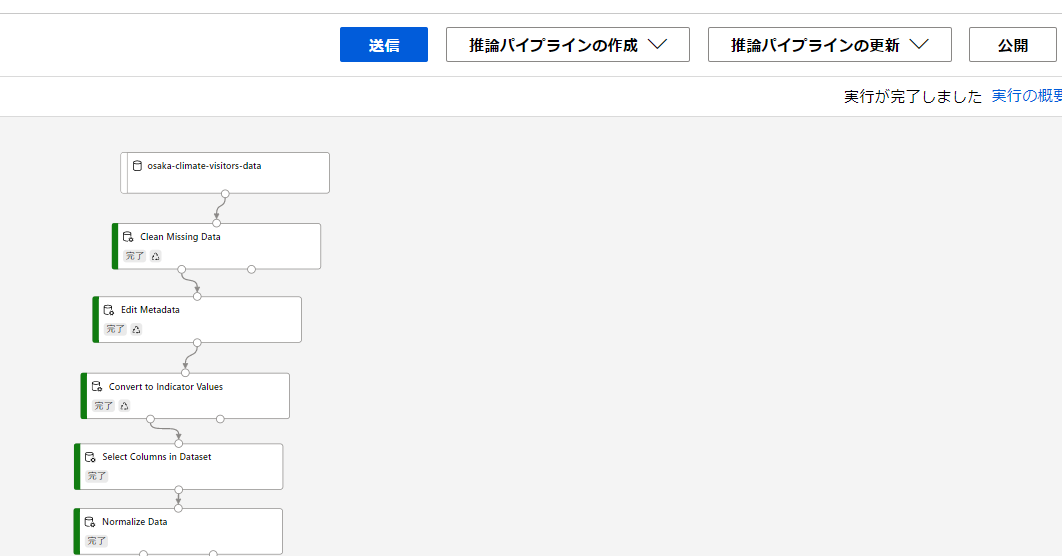
前半:データの処理
登録したデータセットを、学習に使える形に変換していきます。osaka-climate-visitors-dataがワークスペースに登録されたデータセットを意味しています。
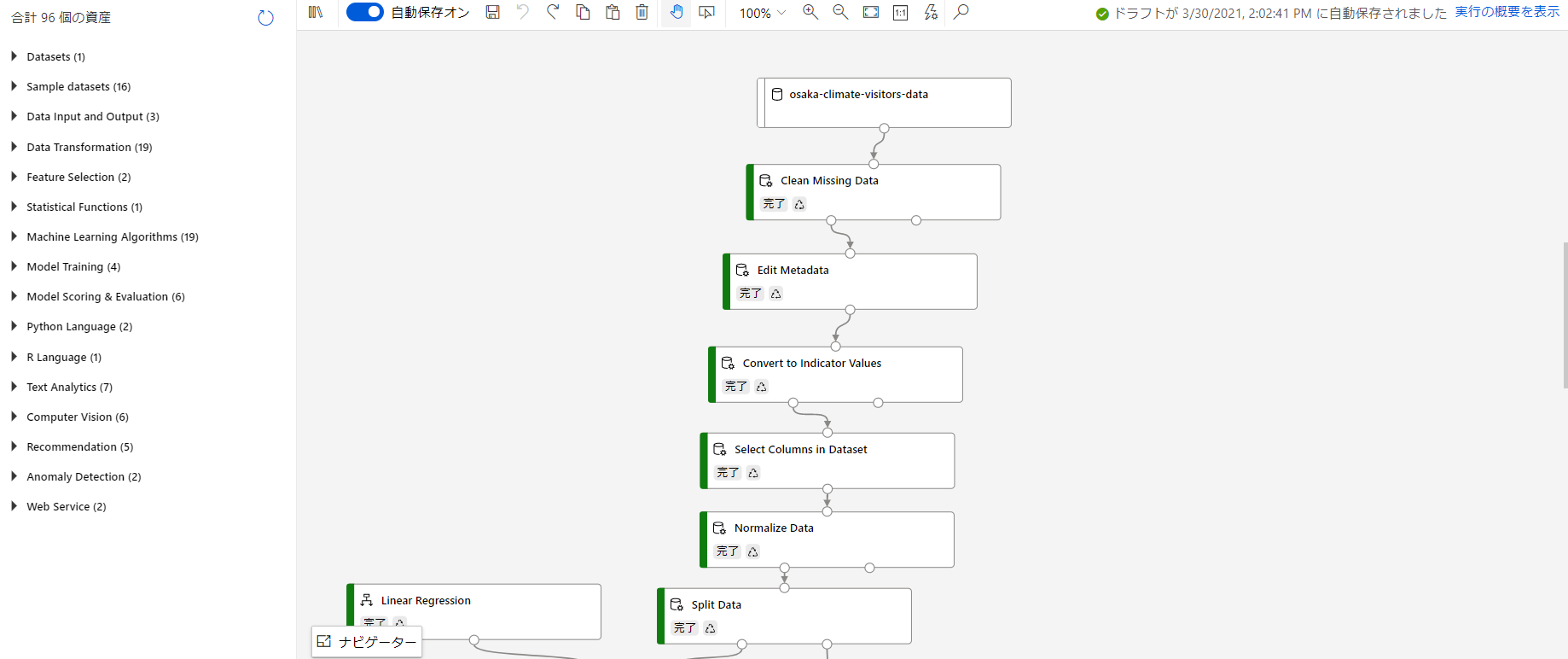
- Clean Missing Data:欠損値がある場合の処理方法を定義します。欠損のある行を削除したり、その列の平均や中央値で埋めたりできます。
- Edit Metadata:今回は曜日が変数として入力されています。これを後の処理でダミー変数化(one-hot化)するのですが、その処理がカテゴリカル変数しか受け取らないため曜日カラムがカテゴリカル変数に変換する必要があります。新たにカテゴリカル型のカラムとして追加できます。※one-hot化⇒例えば火曜日の場合:{0,0,1,0,0,0,0}になります(日曜が一番左とする)。
- Convert to Convert to Indicator Values:先程カテゴリカル変数として追加したカラムに対して、ダミー変数化の処理を行います。
- Select Columns in Dataset:学習に使用するデータの選択を行います。
- Normalize Data:カラムごとの変数の大小による影響を小さくするためにカラム内で正規化を行います。正規化の方法にもいくつか種類があります。
ここまでで学習用に使えるデータが準備できたことになります。
後半:モデルの学習
学習に関する部分はシンプルです。
※2021/04/20追記
Split Dataモジュールの前にSelect Columnsモジュールを追加してインジケータ化されていない[曜日]カラムを落としておきます。この処理で推論に[曜日]カラムが使われなくなります。
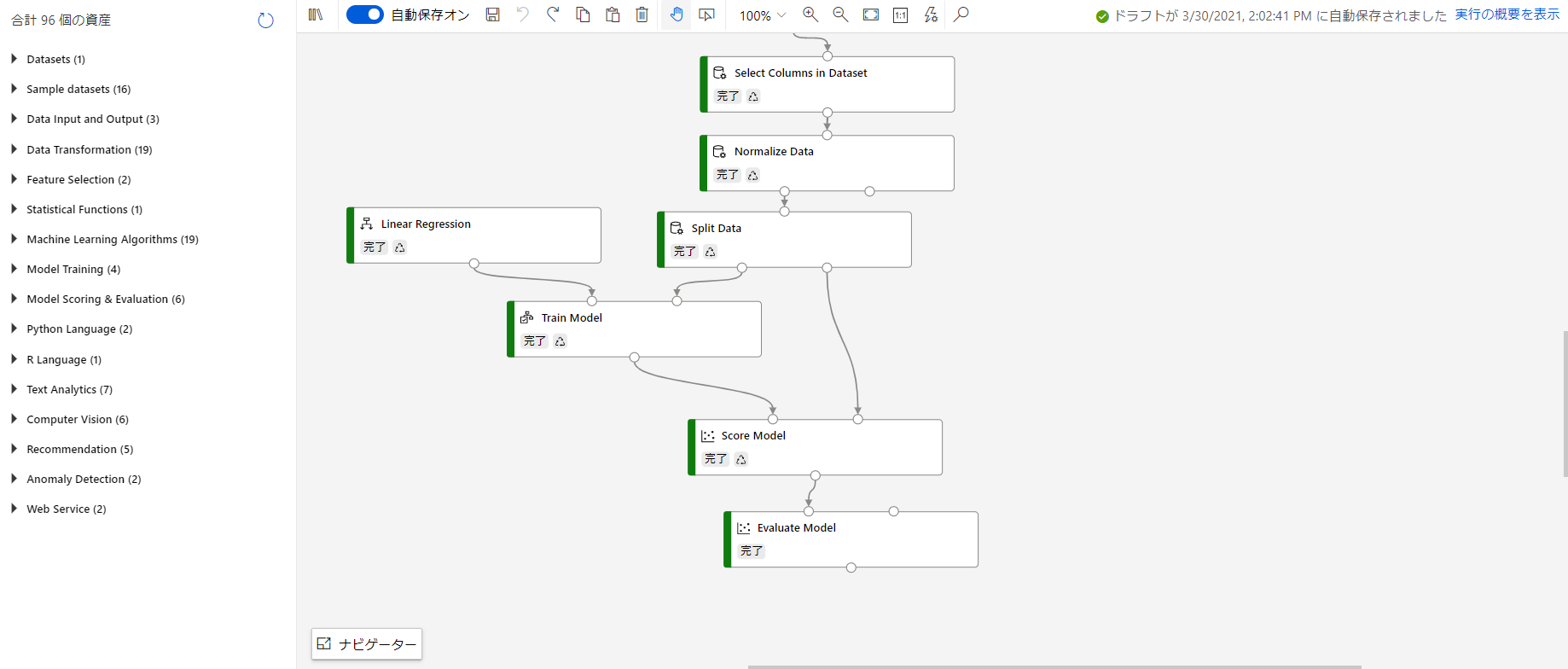
- Split Data:このモジュールによってデータを訓練データとテストデータに分割します。テストデータは学習に全く利用せず、未知のデータだと想定して学習したモデルの評価に用います。
- Linear Regression:回帰のアルゴリズムの一つです。線形回帰モデルを利用するため次のモジュールへ入力しています。
- Train Model:アルゴリズムと訓練データを受け取り、学習済モデルを出力します。ラベルの指定もここで行います。
- Score Model:テストデータを未知のデータとし、説明変数を学習済モデルへ入力して推論します。
- Evaluate Model:Score Modelの出力には推論によって得られた値と実測値の両方が含まれているため、それらの間の誤差を計算することでモデルの評価を行います。評価指標になる誤差はいくつか種類があります。
推論パイプライン構築
学習によって生成されたモデルはそのモジュールを開くと直接デプロイが可能です。しかし、このモデルは前処理済み(曜日のダミー変数化、天候データの正規化)のデータを入力として想定しているため直接デプロイしてしまうと使い物になりません。そこで推論パイプラインを作成し、推論時にデータが変換プロセスを再現できるようにする必要があります。
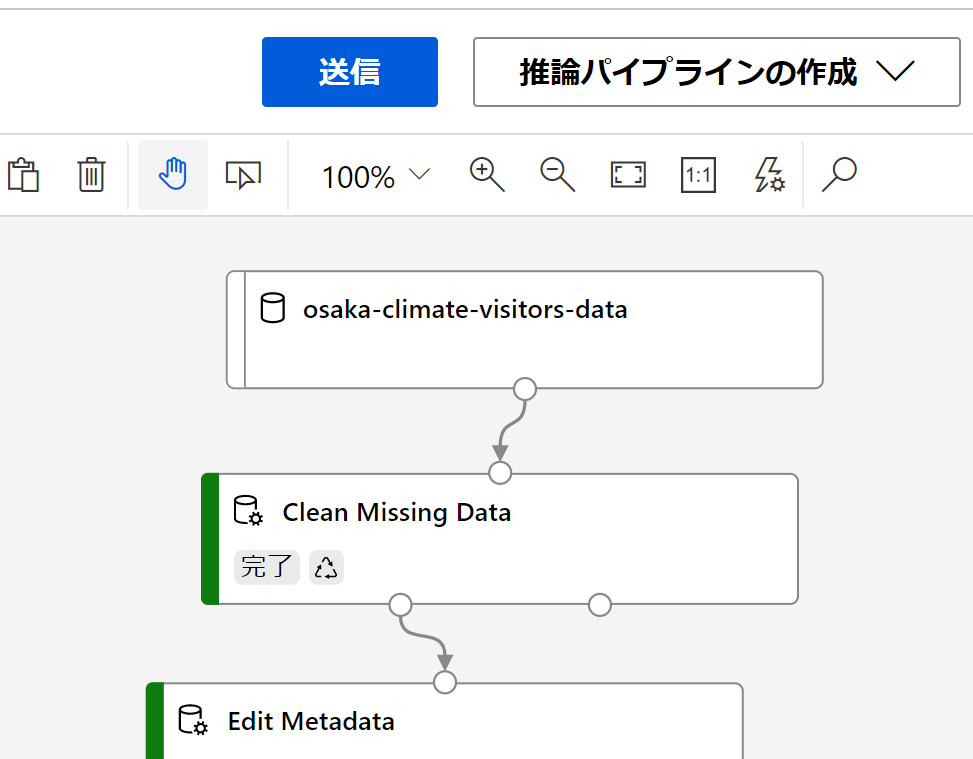
[推論パイプラインの作成]から[リアルタイム推論パイプライン]を選択します。学習パイプライン内で行ったのと同じデータ変換を含むパイプラインが生成されます。
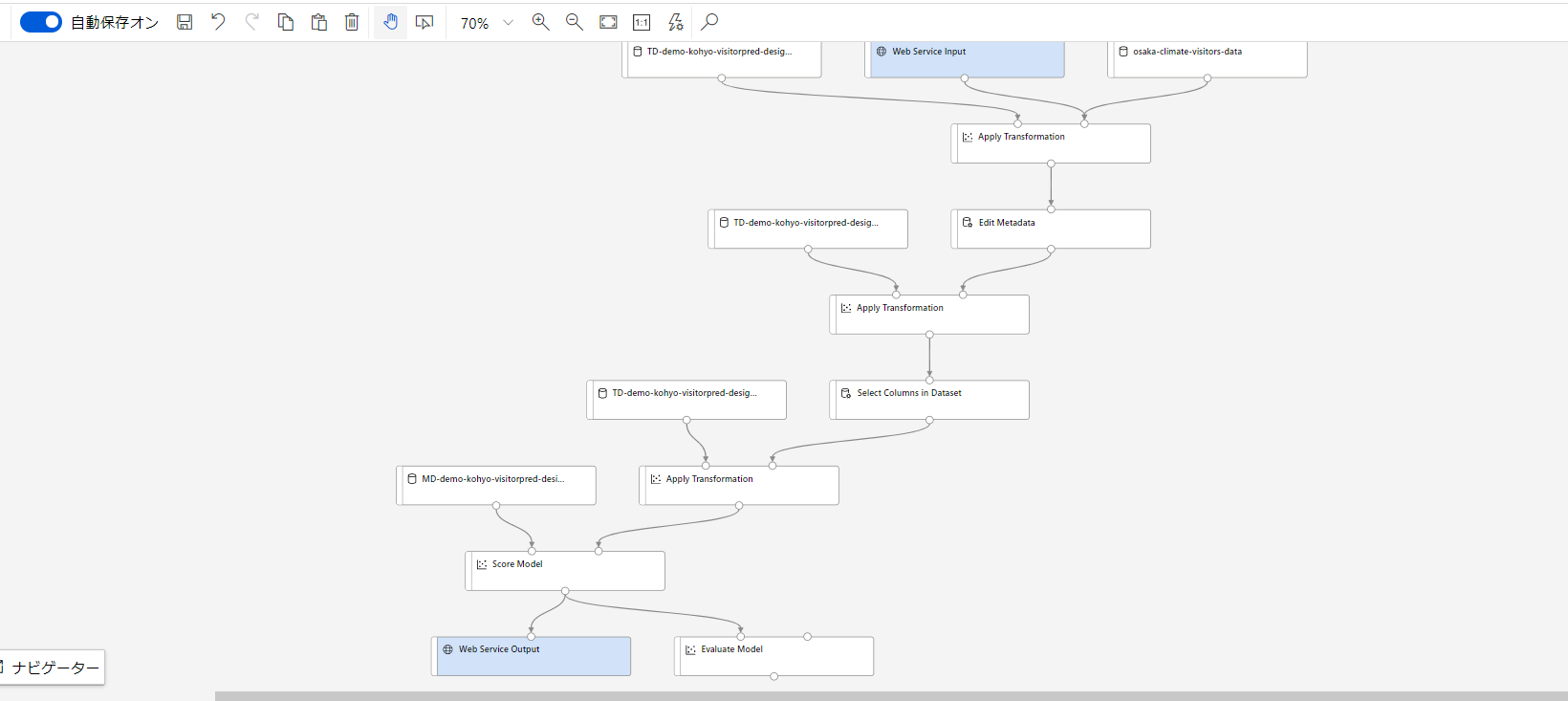
[トレーニングパイプライン]を再度回した際には[推論パイプラインの更新]を実行することによって変換処理の変更点などを反映することができます。
学習用に用いた元データと[Evaluate Model]は不要なので削除します。また、テストができるように[Enter Data Manually]を追加します。これにより、取得した加工前データを変換して学習済みモデルにインプットするまでの流れが構成されました。
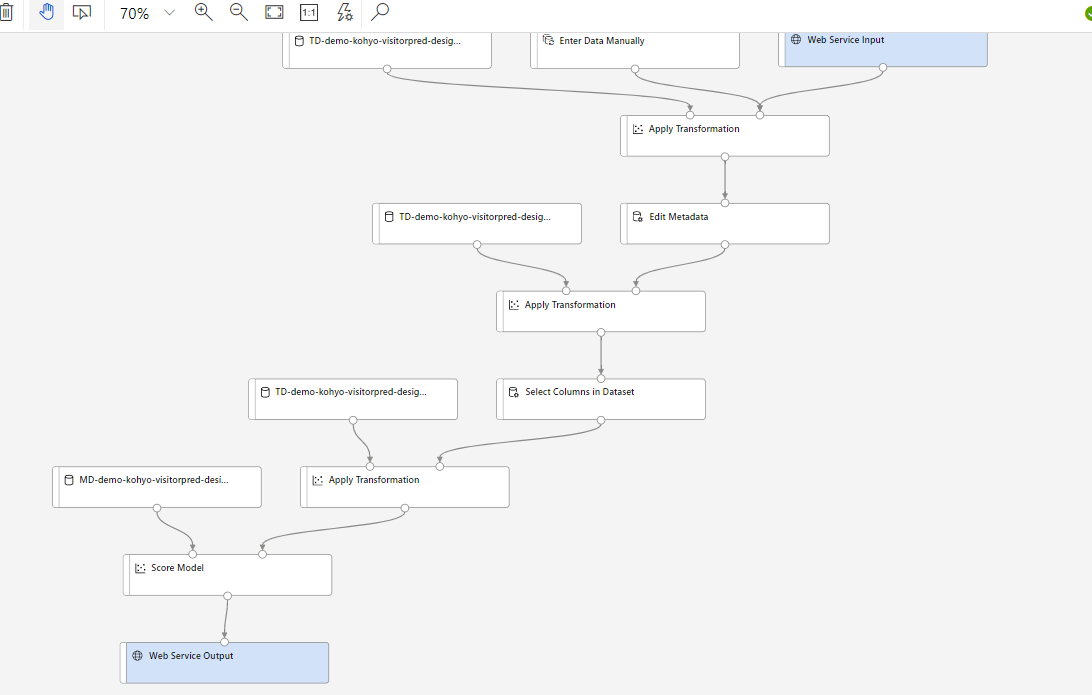
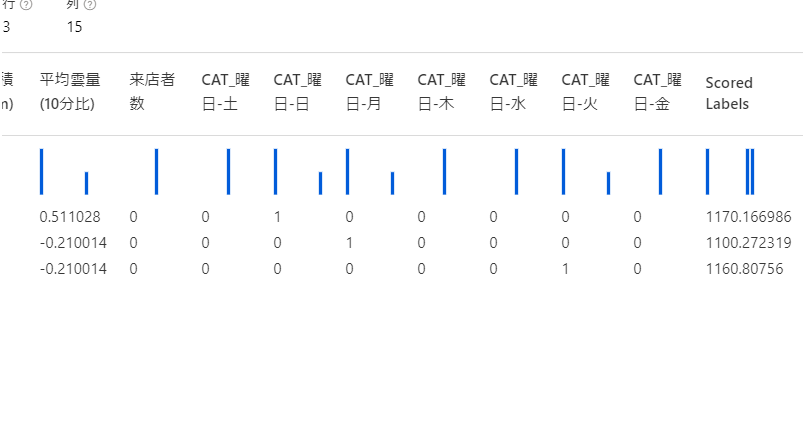
推論パイプライン検証のために手入力で動作確認。カラム名も必要ですので注意が必要です。

また、本来推論時に想定される入力にはラベル列来店者数がありませんが、トレーニングパイプラインの中で来店者数を参照している変換処理(Clean Missing Value等)があるとエラーが発生します。さらにこの参照カラムはSelect Columns in Datasetを除き推論パイプライン側から変更できません。
故に来店者数カラムを含めて入力しています。Webアプリ等からの入力になる場合は、ロジック側でエラー回避のためダミー的に来店者数を追加することになると思います。私の場合はダミーなので0で埋めています。
不自然なカラムを追加したくない場合は、リアルタイム推論パイプラインの中で来店者数カラムへの参照を削除する必要がありますが、先述の通りSelect Columns in Dataset以外は変更できないため、学習パイプライン側でそもそも目的変数への欠損値処理等を行わないように構築する必要があります。
ダミーの来店者数があったところでこれは推論には使われず、予測値はScored Labelsとして出力されるので影響はありません。
補足
データの変換処理に関してはトレーニングのパイプラインから出力されたものを流用しています。
Normalize Dataについて、学習データ内での正規化をリアルタイムに取得されたデータへどう適用されるのかに関しては、流用される正規化モジュールにパラメータが保持されており、それに基づいた式で新たなデータも正規化されるのだと思います。
例えばZscoreで正規化する場合、学習データではデータセット内の平均と分散を基に各データを変換します。
x_new = (x-x_mean)/x_std
このx_meanとx_stdを利用して新たなデータに対しても同様に変換しているという解釈です。リアルタイム推論の場合は特に学習データが十分に大きいと考えられるので(サンプルが1つ増えても平均と分散が殆ど動かない)、同じ値を基に計算してしまってよいのだと思います。
学習コンテンツ
回帰に関しては以下のMSLearnモジュールで一通り学習することが可能です。