Azure Synapse Analyticsとは
Azure Synapse は、Azure SQL Data Warehouse の進化版です
Azure Synapse は、エンタープライズ データ ウェアハウスとビッグ データ分析がまとめられた無制限の分析サービスです。サーバーレスまたはプロビジョニング済みリソースのいずれかを使用して、自分の条件でデータを自在かつ大規模にクエリすることができます。Azure Synapse では、これら 2 つの機能が 1 つのエクスペリエンスに統合され、データの取り込み、準備、管理、提供を行い、BI や機械学習でのニーズにすばやく対応することができます。
とあるように、分析のあらゆるニーズにこたえる統合的なプラットフォームです。もちろんAzure Data Factoryの機能も統合されているためパイプラインを記述することが可能です。今回行うことは基本的にADFで行うことと同じになります。
流れ
- データを所定の場所にコピー
- Databricksノートブックの実装
- 動作の確認
Step1:パイプラインへのコンポーネントの配置
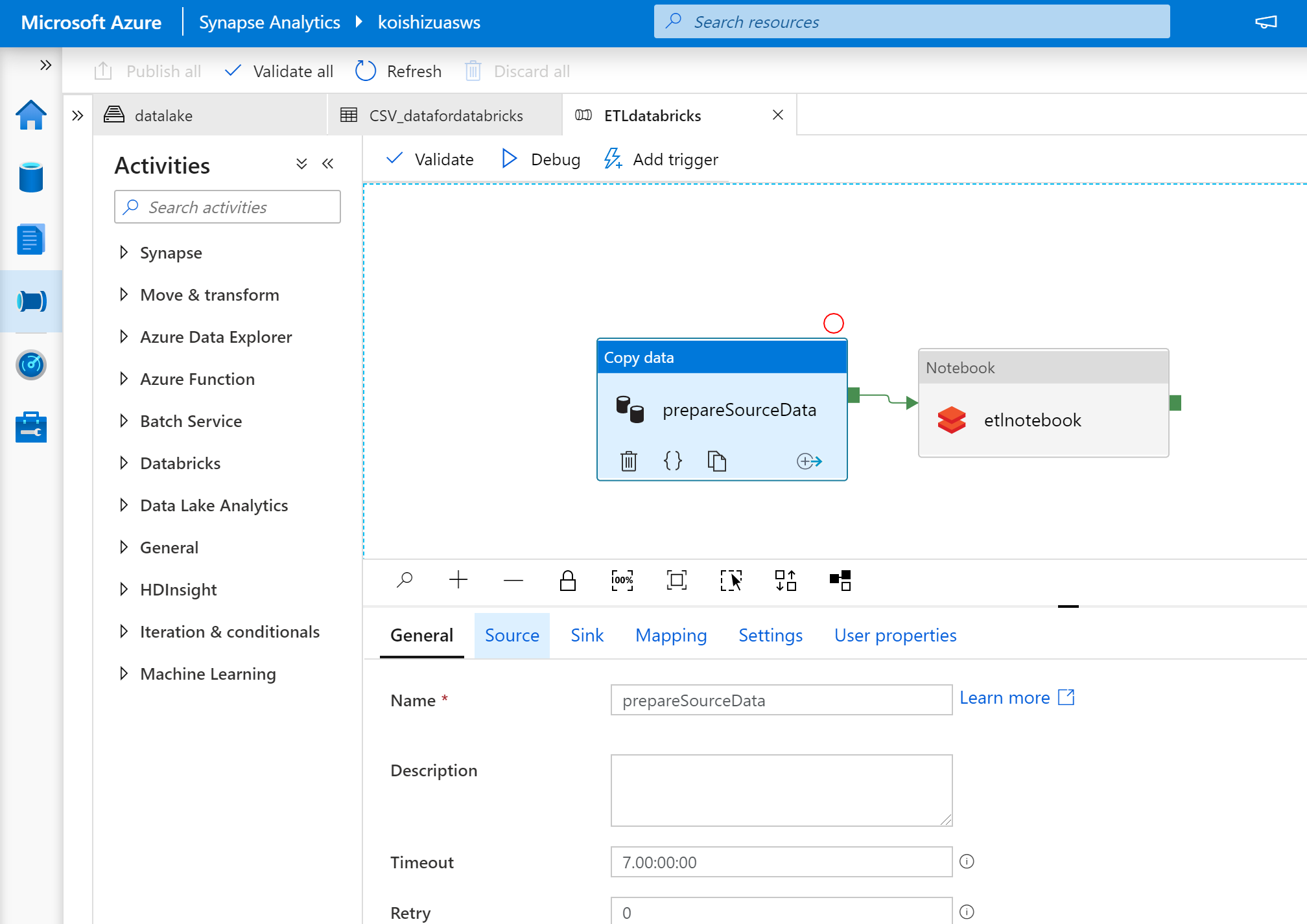
今回はCopy dataとDatabricsk notebookのコンポーネントのみを用います。
Copy dataに関しては、データソースとデータのシンク先を設定します。外部のデータソースからCSVを引っ張ってきてサブスクリプション内のStorageに保存するようなイメージです。
Databricksに関しては、以下のようなパラメータを設定します。このようにすることで、DatabricksのノートブックからStorageにアクセスするための情報をコード内に記述することなく環境変数的に実行することが可能になります。
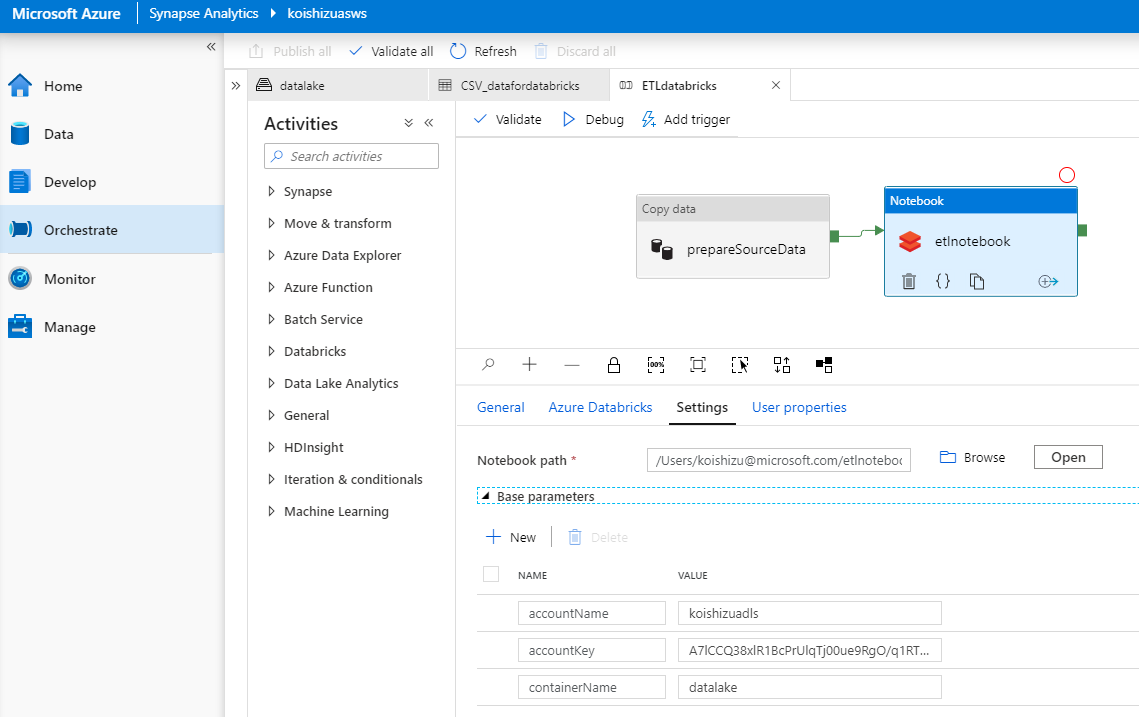
Step2:Databricks側の設定
DatabricksのNotebook内で行うことは主に4つあります。
- Storageへのアクセス情報が記載されたパラメータの取得
- Storageへの接続
- データの加工
- データの保存
パラメータの取得はdbutilsライブラリを用いることで取得が可能です。
# widgets.text("参照名","初期値","表示名")
dbutils.widgets.text("accountName","","Account Name")
dbutils.widgets.text("accountKey","","Account Key")
dbutils.widgets.text("containerName","","Container Name")
accountName = dbutils.widgets.get("accountName")
accountKey = dbutils.widgets.get("accountKey")
containerName = dbutils.widgets.get("containerName")
取得した情報からStorageへの接続に必要な情報を構成し、接続します。今回はAzure Data Lake Storage Gen2を用いるため以下のように記載します。接続先によって若干異なるのでこちらを参照ください。
- https://docs.microsoft.com/ja-jp/azure/data-explorer/kusto/api/connection-strings/storage
- https://docs.microsoft.com/ja-jp/azure/databricks/data/data-sources/azure/azure-datalake-gen2
# 接続文字列を作成
# locals()はローカル変数の辞書を返すため、%locals()として変数で渡すことで%(containerName)等が%locals()の辞書からcontainerNameを呼び出せる
connectionString = "abfss://%(containerName)s@%(accountName)s.dfs.core.windows.net/" % locals()
# connectionString = "abfss://%(containerName)s@%(accountName)s.dfs.core.windows.net/"
print(connectionString)
# Storage Accountへの接続
spark.conf.set("fs.azure.account.key." + accountName + ".dfs.core.windows.net", accountKey)
# ファイルの読み込み
df = spark.read.option("header",True).csv("%(connectionString)s/databricksdata/data.csv" %locals())
適当にデータを加工します。
etldf = df.select(df["Year"],df["Month"],df["CRSDepTime"],df["DepDelay"],df["CRSArrTime"],df["ArrDelay"],df["OriginAirportName"],df["OriginLatitude"],df["OriginLongitude"],df["DestAirportName"])
加工したデータを保存します。
etldf.write.mode("overwrite").saveAsTable("airport")
保存するとDatabricksのDataタブからTableが確認できます。

最後に、Notebookを終了してレスポンスを返す部分をdbutilsで記述します。
import json
dbutils.notebook.exit(json.dumps({
"status": "OK",
"message": "Cleaned data and created persistent table",
"tables": ["airport"]
}))
これでパイプラインの準備は整いました。
Step3:パイプラインの実行と監視
パイプラインのTrigger nowをクリックして実行します。

監視についてはSynapseは基本Monitorハブから行います。

詳細を確認したい実行に入ると以下のようなActivity毎のステータスが表示されます。

眼鏡のマークをクリックすると詳細が確認できます。

Databricksの場合はDatabrickのモニターへのリンクが提供され、どこまで実行されているか等コードベースで確認することができます。

作業は以上です。実際は手動でのTriggerではなく変更フィードやバッチ処理などが考えられると思います。Azure Synapse Studioは絶賛パブリックプレビュー中ですので遊んでみるのをお勧めします。私も分からないなりに遊んでいます笑