これは「TeX & LaTeX Advent Caleandar 2015」の25日目の記事です。
(24日目は golden_luckyさん です。)
TeXが“長い歴史のある”(要するに“思いきり古い”)ソフトウェアであることは皆さんご存知でしょう。現在使われているTeX実装について最初の公開版がリリースされたのは1982年1なので、それから実に30年以上の時が過ぎています。
この事実に比べるとあまり知られてないことですが、LaTeXやp(La)TeXが現れたのはTeXの歴史の非常に早い段階のことであり、つまり、LaTeXも“相当に古い”ソフトウェアなのです。TeXがアレなのに比べると、LaTeXの仕様は大体においてマトモなものですが、その古さゆえに、今から考えると不合理な方法が使われて、それがそのまま「デフォルトの設定」として現在まで続いてしまっている、という点が随所に見られます。この記事では、そんな**「(p)LaTeXのアレなデフフォルト」**を取り上げます。
その1:“min10”フォントメトリックがアレ
LaTeXの魅力は何か、に対する答えは人によって様々でしょうが、「美しい組版」がその一つであることは間違いないでしょう。特に、pLaTeX系エンジンの日本語の組版の美しさには定評があります2。
% pLaTeX 文書
\documentclass[a5paper]{jsarticle}
\begin{document}
ConTeXt(この中のXは/ks/と読む)はTeX上に構成された
文書生成システムである.
最新版の「MkIV(マーク4)」はLuaTeXエンジンのみをサポートし,
「MkII(マーク2)」はpdfTeXとXeTeXをサポートする.
(XeTeX に対して「MkIII」が計画されていたが結局作られなかった.)
「TeXマニア」を自称するなら,LaTeXばかりでなくConTeXtの
動向もチェックすべきである.
\end{document}

ですが、先ほどの素晴らしい出力結果は、実はpLaTeXのデフォルトではありません。「いやそんなはずがない、だって先のソースのプレアンブルは空っぽじゃないか」と思うかも知れませんが、実は文書クラスがjsarticleであることに大きな意味があります。jsarticleクラス(などの「jsclassesの文書クラス」)では和文フォントの設定をデフォルトから変えているのです。
これに対してjarticleクラス(などの「標準和文文書クラス」)では「デフォルトの和文フォント設定」が使われています。「デフォルトの設定がどんなものか」を見るために、jarticleの出力を調べてみましょう。
% pLaTeX 文書
\documentclass[a5j]{jarticle} % jarticle にした
\begin{document}
ConTeXt(この中のXは/ks/と読む)はTeX上に構成された
% あとは先の例と同じ

よく見ると、句読点と括弧が並んだ箇所の出力が奇妙です。(この奇妙さは句読点にコンマ・ピリオドを使った場合に顕著になります。)それに、「チェック」などの連続した小書き仮名の出力が明らかに詰まりすぎています3。
pTeXにおける「文字の組み方」を調整するパラメタ群のことを「フォントメトリック」といいます。個々のフォントメトリックには名前が付いていて、デフォルトのアレなものは「min10」、jsarticleで使われているマトモなものは「jis」と呼ばれています4。「p(La)TeXのデフォルト」であるmin10の設定が作られたのは遠い昔(20年以上前)のことなので、その設計思想がどういうものであったかは今となっては不明で、「pTeXの七不思議」の一つに数えられています5。その答えが何であるにしても、現在の標準的なpLaTeXの使用法においては、min10のフォントメトリックは決して使うべきでないとされています。
従って、pLaTeXで日本語文書を作る際には、「デフォルトのmin10」が使われないように注意すべきです。「今時jarticleなんて誰も使わないから大丈夫」と思うかもしれませんが、実は重大な罠があります。それはBeamerやpowerdot等のスライド用の文書クラスです。これらの文書クラスは元来は欧文のLaTeXのために作られたものですから、当然、pTeXの和文フォントについての設定は何も行いません。何も行わないということは、デフォルトのmin10が使われてしまうのです。

対策:minijsパッケージを使う
jsclassesバンドルのアーカイブに同梱されているminijsというパッケージを読み込むと、任意の文書クラスを用いたpLaTeX文書でフォントメトリックをjisに変えることができます。
% pLaTeX 文書
\documentclass[dvipdfmx]{beamer}
\usepackage{bxdpx-beamer}
\usepackage{pxjahyper}
\renewcommand{\kanjifamilydefault}{\gtdefault}% 和文をゴシックに
\usepackage{minijs}% min10 の呪いを破却せよ
%↑ の代わりに ↓ でもよい
%\usepackage{otf}% otf 万能!
\usetheme{Madrid}

この他に、otfパッケージを読み込むという方法もあります。otfパッケージで用いられているフォントメトリック設定はjisとほぼ同じマトモなものであるからです。この項目を初めとして、以後幾つか「和文フォントに関するアレなデフォルト」の話が続きますが、otfパッケージはその多くを解消してくれます。なので、(u)pLaTeX文書では可能な限りotfパッケージを読み込んでおくという方針にするのもいいでしょう。
その2:jarticleなどの「標準和文文書クラス」がアレ
jarticleのフォントメトリックであるmin10がアレ、という話をしましたが、実はjarticle等の「標準和文文書クラス」自体が、日本語の文書クラスとしては相当にアレです。
% pLaTeX 文書
\documentclass[a4paper]{jarticle}% jarticle はアレ!
\begin{document}
\begin{abstract}% チョット概要を書いてみる
近年,{\TeX}のアレ性への認識の共有が深まるにつれて,
{\TeX}の必要性を低減させるための技術(いわゆる「{\TeX}グッバイ」)
に対する需要が高まっている.
本研究では,Microsoft社の著名なワープロソフトである……
\end{abstract}
\end{document}

なんと、日本語文書なのに、段落下げの量が全角1文字分になっていません!6 この他にも「標準和文文書クラス」には様々な「日本語文書のレイアウトとしてはアレな点」が潜んでいます。そういうわけで、(少なくとも私の意見としては)「標準和文文書クラス」は決して使うべきではありません。
対策:とにかく別のモノを使う
jarticleなどの「標準和文文書クラス」を使うような用途においては、私は、jsarticleなどの「jsclassesの文書クラス」を使うことを推奨します。このjsclassesにも色々と批判があるようですが、それは決して「jarticleの方がよい」という意味ではない(そんな意見は聞いたことがありません)ことに注意が必要です。
その3:和文の仮想ボディがアレ
デフォルトのmin10のアレ性から脱却するために作られたjisですが、一点だけ「マトモにしたかったけど諦めた」ところがあります。それは「和文文字の高さ・深さ」です。
テキストを枠で囲む命令\fboxを使って、文字の寸法を調べてみましょう。
% pLaTeX 文書
\documentclass[a4paper]{jsarticle}
\setlength{\fboxsep}{0pt}% 枠と文字の間の隙間を無くす
\begin{document}
\fbox{A} \fbox{g} \fbox{/} \fbox{あ} \fbox{漢}
\end{document}
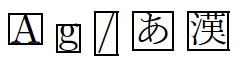
通常、和文文字の外見(ボディ)は字面によらず一定の正方形で、字面はその枠の中にバランスよく収まる、とされています。ところが、min10やjisのボディはなぜか横長の長方形で、しかも字面が上の方に寄ってしまっていて不合理です(つまり高さ・深さの値がおかしい)。このため、例えば普通にテキストの枠囲みを行ったときも、和文の場合は上下のバランスが悪くなってしまいます。(表組みでバランスがアレなのも同じ原因です。)

元々はmin10が先に述べたようなアレなボディの寸法を持っていて、jisではこれをマトモな寸法に変えたかったはずです。しかし、当時に作られていたpLaTeX文書(や文書クラス)はこのアレなmin10を“前提”にしています。仮にもし、これをマトモな寸法のフォントメトリックに変えてしまうと、行の位置が縦にズレてしまうという致命的な不具合が起こるでしょう。なので、結局単純にmin10をjisに置き換えることができず、その結果、min10のアレな組版が居座り続けるという本末転倒な事態になってしまいます。これを避けるため、jisではmin10のアレなボディの寸法が敢えて引き継がれることになって、今に至っているのです。
対策:otfパッケージを使う
otfパッケージのフォントメトリックは、jisが本来採用したかったマトモな正方形のボディをもつように設計されています。
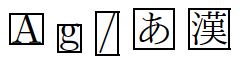
従って、otfを読み込むと先ほど述べたような「上下のバランスがアレ」問題を解消できます。

upLaTeXにしよう
このようにpLaTeXは昔のアレな点を色々と引きずっています。これに対して、後発のupLaTeXはpLaTeXと高い互換性を保ちながらも「pLaTeXのアレな点はマトモに変える」という方針で設計されています。従って、upLaTeXのデフォルトのフォントメトリックは極めてマトモです。
% upLaTeX文書
\documentclass[uplatex,a4paper]{jsarticle}
% デフォルトのフォント設定のまま!
\usepackage{color}
\definecolor{myred}{rgb}{0.85,0,0.1}
\definecolor{mypink}{rgb}{1,0.92,0.92}
\setlength{\fboxsep}{2pt}
\begin{document}
\sffamily \color{myred}
\fcolorbox{myred}{mypink}{☃謹賀新年☃}
\end{document}

upLaTeXに切り替えましょう。これでもう「pLaTeXのアレなデフォルト」に悩まされることは一切ありません!
その4:upLaTeXでBMP外の字を使うとアレ
……と言いたいところですが、実は、upLaTeXにも「アレなデフォルト」が存在したりします。(世の中うまくいかないものです……。)
ご存知の通り、upLaTeXを使うとJIS X 0208(いわゆる「JISコードの第2水準まで」)の外の文字が使えるようになります。ところが、〈𠮟〉(U+20B9F;〈叱〉の“本来の”字体7)のようなBMP外の文字8を書いてもそのままでは出力されません。(〈𠮟〉はJIS第3水準漢字なので、日本語文書の本文用に一般的に用いられるフォントではサポートされているはずで、つまりフォントの問題ではありません。)
% upLaTeX 文書
\documentclass[uplatex,a4paper]{jsarticle}
%\documentclass[a4paper]{ujarticle}% ujarticle でもダメ
\begin{document}
猫𠮟るより猫を囲え
% '𠮟'が消えてしまう!
\end{document}
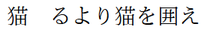
upTeXが開発された当初は、各種DVIウェアの多くが「16ビット超の文字コード」に対応していませんでした。このことによる予期せぬ不具合を避けるために、upLaTeXのデフォルト設定では敢えて「BMP外をサポートしないフォント設定」が使われているのです。
対策:otfパッケージを使う
otfパッケージのフォント設定ではBMP外の文字を(日本語フォントが対応していれば)出力できます。
% upLaTeX 文書
\documentclass[uplatex,a4paper]{jsarticle}
\usepackage{otf}% 𠮟るために必要
\begin{document}
猫𠮟るより猫を囲え
\end{document}
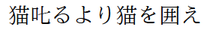
また、BXjsclsバンドルの文書クラス(bxjsarticleなど)とupLaTeXの組合せでは既定でBMP外の文字を扱えます。
% upLaTeX文書
\documentclass[uplatex,dvipdfmx,a4paper,js=standard]{bxjsarticle}
\begin{document}
猫𠮟るより猫を囲え
\end{document}
※upLaTeXで“実際に使える”文字の範囲はかなり複雑です。詳細は以下の記事を参照してください。
-
upTeX できる Unicode の話
BXjsclsのクラスでは(ii)の設定が使われます。
【追記】最新のupLaTeXでは非アレ
【追記 2019-07-11】uptex-fontsの2018年2月の改修により、upLaTeXのデフォルトの設定でもBMP外の文字が(otfのフォントの同じ程度に)サポートされるようになりました。従って、通常の使用9においては現在では「BMP外の文字」を気にする必要はなくなりました。
その5:OT1エンコーディングがアレ
和文フォントの話が続きましたが、今度は欧文フォントの話です。近年はXeTeXやLuaTeXなどの「UnicodeできるTeX」が普及しつつありますが、それ以前の欧文TeXは符号空間が8ビット、つまり一つのフォントで高々256種類の文字しか扱えませんでした。この状態で多言語・多スクリプトを扱う面倒は想像に難くないでしょう。
ところが実は、TeXが開発された当初(1980年代)は、TeXの符号空間は8ビットですらなく**「7ビット」**でした。つまり一つのフォントでは128種類の文字しか扱えなかったのです。そして、Computer Modernフォント(CMフォント)はその7ビットなTeXのために作られたものなので、128種の文字からなる「7ビットのフォント」なのです。

このCMフォントがTeXにおけるフォントの標準であり続けたため、LaTeXでもCMフォントがデフォルトになりました。1990年になってTeXの符号空間が8ビットに拡がりました。それから長い年月が経ち、今では百万文字超の空間をもつUnicodeが一般に使われるようになりました。しかし、LaTeXのデフォルトのフォントは、今なお「7ビット」のCMフォントであり続けているのです10。
CMフォントの文字コード(LaTeXでは「OT1エンコーディング」と呼ばれます)は7ビットの空間に英語の文書(でも稀に外国語の単語が出現する想定)で必要な字種を詰め込もうとしているので、色々と無理が生じてしまいます11。
-
<>|の文字は「LaTeXの特殊文字」ではないにも関わらず、普通に出力しようとすると、〈¡〉〈¿〉〈—〉に化けてしまう。数式扱い($<$など)すると出力できるが、それだと書体の設定(\slshapeによる斜体など)が適用されない12。 -
\{\}で〈{〉〈}〉が出力できるが、これも内部では数式扱いなので、やはり書体の設定が適用されない。 -
\_で〈_〉が出力できるが、実際には“文字”でなくて線を引いているだけなので、PDFの文字情報が不正になる。 - 〈é〉や〈ö〉といったアクセント付き文字は「e の上に〈´〉を印字する」のような“合成”で表すことになる。この方式だと〈ă〉とか〈ů〉とか〈ś〉とか〈ŵ〉といった“珍しい”文字でも対応できるという利点もあるが、次のような重大な欠点がある。
- PDF文書に変換した場合の文字情報が不正になる。
- (TeXの長所であるはずの)カーニング処理が効かなくなる。
- “合成”された文字は内部では単なる文字でないので、ハイフネーションの定義でアクセント文字を含めることができない。
- “合成”で出された文字は品質が劣る場合がある。
対策:T1エンコーディングを使う
現在のLaTeXでは「T1エンコーディング」という新しい8ビットのフォントエンコーディングが規定されていて、“普通の欧文”についてはこれを使うことが推奨されています。

8ビットのT1では256種の文字が使えるので、先に挙げたOT1の欠点の多くが解消されます。
- 全てのASCII文字が“素直に”サポートされるので、正しく入力する13限りは「アレなこと」が起こらない。
- アクセント付き文字の多く14が“1つの文字”としてサポートされ、普通の英字と同じ扱い(カーニング・ハイフネーション)を受けるようになる。(入力方法は従来の
\'eや\u{a}がそのまま使える。)
文書で利用するフォントエンコーディングをT1に変更する方法は非常に簡単で、次のようにfontencパッケージを読み込むだけです。原則として、ソースの他の部分を変える必要はありません15。
% フォントエンコーディングの名前をオプションで指定する
\usepackage[T1]{fontenc}
なお、デフォルトの欧文フォント(CMフォント)を使っていて、かつフォントエンコーディングをT1に変えたい、という場合はlmodernパッケージを一緒に読み込む方がよいでしょう。その理由については次の節で説明します。
\usepackage[T1]{fontenc}
\usepackage{lmodern}% Latin Modern フォントを使う
※フォントエンコーディングは「入力ファイルの文字コード」(入力エンコーディング、こちらはinputencパッケージで指定する)とは全く独立した概念です。特に、(u)pLaTeXでは純粋な8ビットの入力エンコーディング(Latin-1等)は和文の文字コードと矛盾するので使用できませんが、フォントエンコーディング(fontencパッケージ)は何の問題もなく使用できます。入力エンコーディングとフォントエンコーディングの違いについては以下の記事も参考になるでしょう。
その6:欧文フォントのサイズ指定がアレ
LaTeXの参考書を見ると、\fontsize命令を使って任意のフォントサイズを指定できると述べられています。しかしデフォルトのフォント設定で色々なサイズを指定してみても、結局、高水準のフォントサイズ命令(\small、\large、\LARGEなど)に対応するサイズのうち一番近いものに“丸めこまれて”しまいます。
% pLaTeX文書
\documentclass[a4paper]{jsarticle}
\begin{document}% サイズを自由に変えたいのだが...アレ
\fontsize{15}{15}\selectfont M% 15pt → \Largeと同じ
\fontsize{16}{16}\selectfont M% 16pt → \LARGEと同じ
\fontsize{17}{17}\selectfont M% 17pt → \LARGEと同じ
\fontsize{18}{18}\selectfont M% 18pt → \LARGEと同じ
\fontsize{19}{19}\selectfont M% 19pt → \LARGEと同じ
\fontsize{20}{20}\selectfont M% 20pt → \huge と同じ
\end{document}
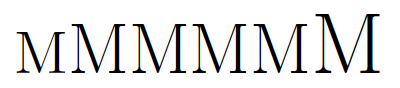
このような問題が起こるのは欧文だけで、和文のフォントは指定されたサイズがそのまま反映されます。また、欧文フォントをデフォルドから変えている場合もこの問題は起きません(下の図はnewpxtextを使用)。つまり、これも「デフォルトがアレ」な問題の一つだといえます。

デフォルトのCMフォントがアレな理由は、大昔のTeX環境におけるフォントの使われ方にその端緒があります。現在ではTeXにおいてもアウトラインフォントの利用が当たり前になりましたが、昔のフォントはビットマップ形式であり、そこではサイズごとに異なるビットマップデータを持つ必要があったのでした。従って、「あらかじめビットマップデータが用意されていない」ようなフォントサイズが指定されてしまうと、DVIウェアがレンダリングできずにエラーになってしまいます。こういう事態を避けるため、LaTeXでは幾つかのサイズの値を選び出しておいて、その特定のサイズだけが用いられる(それ以外の値が指定された場合は近い値に“丸めこまれる”)ような仕組になっているのです。もちろん、今はその必要は全くないのですが、デフォルトのCMフォントについては互換性のためそのままの仕様になっています。
対策:fix-cmパッケージを使う
fix-cmパッケージを読み込むと、CMフォントが特定のサイズに“丸めこまれる”問題を解消できます。
※[追記 2019-11-26] fix-cmパッケージは通常のパッケージとは異なり「\documentclass命令よりも前に\RequirePackageで読み込む」ことが強く推奨されているようです。
% ファイルの先頭(\documentclass より前)にコレを書く
% コレでCMフォントがマトモになる
\RequirePackage{fix-cm}
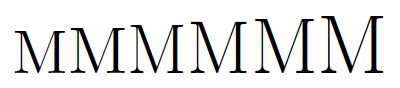
※同様の機能をもつパッケージとしてtype1cmというものもあり、こちらの方が日本ではよく知られているようです。ただしこちらは「OT1エンコーディングのCMフォント」にしか適用できません。
Latin Modernフォントを使おう
実はもっといい方法があります。最近のTeX配布にはComputer Modernフォント(CMフォント)の改良版である「Latin Modernフォント(LMフォント)」というフォントファミリが含まれています。lmodernパッケージを読み込むと欧文フォントがLMフォントに切り替わります。
% Latin Modernフォントしたい!
\usepackage{lmodern}
見た目はCMフォントと同じですが、CMフォント自体ではないので、「互換性のためアレ」な問題とは無縁です。
前の節で「OT1はアレなので欧文はT1エンコーディングにすべき」という話をしましたが、現在のTeX Liveに含まれている「T1のCMフォント」のアウトラインフォント(Type1フォント)はビットマップデータからの自動トレースで作製されたものなので品質がイマイチです。従って、“CMフォントの書体”をT1で使いたいのであれば、「T1のLMフォント」を使うことが強く推奨されます。
今の時代のLaTeXの標準の欧文フォントは「T1のLMフォント」であるといっても過言ではないと思います。
% ニュー・スタンダード!
\usepackage[T1]{fontenc}
\usepackage{lmodern}
その7:和文と欧文の総称ファミリが連動しないのでアレ
jsarticle(などのjsclassesの文書クラス)では欧文を\sffamily(サンセリフ)に切り替えると、それに連動して和文は\gtfamily(ゴシック)に変わります。
% pLaTeX文書
\documentclass[a4paper]{jsarticle}
\begin{document}
% \textsf で和文がゴシックになる
{\TeX}はアレ、\textsf{{\LaTeX}もアレ}!
\end{document}
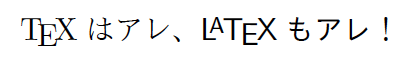
jsclassesしか使っていない人は恐らく気付いていないと思いますが、実はこの「ファミリの連動」はpLaTeXのデフォルトではありません。実際、jarticle(などの標準文書クラス)では\sffamilyを実行しても和文のファミリには影響しません。
% pLaTeX文書
\documentclass[a4paper]{jarticle}% jarticle注意
\begin{document}
% \textsf では和文は変わらない
{\TeX}はアレ、\textsf{{\LaTeX}もアレ}!
\end{document}
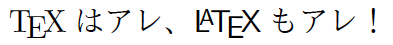
「今時jarticleなんて誰も使わないから大丈夫」と思うかもしれませんが、連動しないのがデフォルトなので、min10の話で述べたのと同様に、スライド用の文書クラスでは連動しませんし、和文用クラスでも連動しないものも多くあるでしょう。
jsarticleが採っている方法は「\sffamilyの定義を修正して和文ファミリ変更の処理も入れてしまう」というアドホックなものです。ところが、実を言うと、pLaTeXには「欧文と和文の書体を連携させる」ためのもっと正式な機構である、従属書体(relation font)という機能が存在します。これは、各々の和文のフォント(シェープまたはシリーズ)に対してそれに“対応”する欧文のフォントを「従属書体」として予め割り当てておく、というものです。そして、和文のフォントを切り替える際に前もって\userelfontという命令を実行しておくと、変更後の和文のフォントの「従属書体」が欧文に適用されます。
% pLaTeX文書
\documentclass[a4paper]{jarticle}
\begin{document}
% 由緒正しい, "従属書体"を利用したフォント指定
{\TeX}はアレ、{\userelfont\gtfamily{\LaTeX}もアレ}!
\end{document}
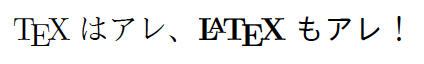
※上の結果から判るように、デフォルトの設定では「ゴシック体の中字」(gt/m)に対する従属書体は「CM Sans-Serifの中字」(cmss/m)ではなく「CM Romanの太字」(cmr/bx)となっています16。
しかし、はっきりした理由は解りませんが、この従属書体の機構は実際のpLaTeXの作業においてはほとんど利用されていないようです。恐らく、和文と欧文を連動させる設定が必要な場合には、jsclassesと同じ方法(\sffamilyを再定義する)が用いられるのが普通なのでしょう。
対策:otfパッケージを使う
「欧文の総称ファミリ命令(\rmfamilyや\sffamily)を実行すると和文ファミリも連動して変わる」という連動設定は、jsclassesのクラスに特有のものです。min10の節で述べたように、「jsclassesの設定」を他の文書クラスで使うためのパッケージがminijsです。従って、連動設定が欲しい場合はminijsパッケージを利用しましょう。
あるいは、(例によって)otfパッケージを読み込むことでも同様の連動設定が実現できます。
その8:用紙サイズの扱いがアレ
ご存知の通り、LaTeXでは文書クラスのオプション(a4paperなど)でレイアウトに用いる用紙サイズを設定します。
\documentclass[a5paper]{article}% 用紙サイズはA5
\begin{document}
{\TeX} est all\'e!
\end{docuemnt}
ところが、これをコンパイルしてできるDVIファイルをdvipdfmx(などのDVIウェア)でPDFに変換すると、設定したはずの用紙サイズが反映されません(多くの環境ではA4とレターサイズのどちらかになります)。正しい用紙サイズのPDFを得るには、なぜか、dvipdfmxの実行時に改めて用紙サイズを指定する必要があります。
latex sample
dvipdfmx -p a5 sample
確かに、専門的な印刷の行程では“印刷用データ”全体の物理的な寸法は最終的な仕上がりの紙面の寸法よりも大きくなります。実際に、TeXにおいては版面の外にトンボ(crop mark)などの印刷作業用の出力を含めることができることを知っている人もいるでしょう。そうだとしても、特に素人も使うLaTeXについては、出力の用紙サイズはレイアウト用の用紙サイズに一致させるのをデフォルトにしてもよいはずです。
この「アレなデフォルト」の根本的な原因は、DVIフォーマットの仕様に「出力用紙サイズ」という概念が存在しないことにあります。(恐らくKnuth氏は「“印刷データ”なので“用紙サイズ”なんて概念はアリエナイ」と考えたのでしょう。)DVIに「出力用紙サイズ」という概念が無い以上、TeXにもそういう設定はなく、従ってLaTeXにも当然ありませんでした。
時代が移り、TeXの出力がPostScriptやPDF(これらのフォーマットには「出力用紙サイズ」という概念があります)として扱われるようになると、さすがにこのDVIの仕様では整合できないので、DVIウェアや拡張TeXエンジン(pdfTeXなど)の拡張機能として出力用紙サイズの設定が加わりました。つまり、現在のTeXでは文書中で出力用紙サイズを設定する仕組は既にあります。しかし「後から追加された機能で常に利用できる確証がない」という事情があるため、残念なことに、LaTeXのデフォルトではレイアウト用に指定した用紙サイズを出力用紙サイズに反映させるようになっていないのです。
対策:geometryパッケージを使う
BXjsclsの文書クラス(bxjsarticleなど)のように、最近作られた文書クラスの中にはデフォルトで出力用の用紙サイズを設定するものがあります。また、jsclassesの文書クラスではpapersizeというクラスオプションを指定すると出力用の用紙サイズが設定されます。
% これでPDFを作るとA5サイズになる
\documentclass[a5paper,papersize]{jsarticle}
その他いくつかのパッケージが“副作用”として出力用紙サイズの設定を行う場合があります。しかし、文書クラスの種類などを特定しない一般の場合において、単純に出力用紙サイズ「だけ」の設定を行うのは意外と厄介です。(※現在ではこの問題は解決されています。後の節を参照。)
geometryパッケージは、その本来の目的はページレイアウトを自由に設定することですが、デフォルトの動作で出力用紙サイズをレイアウト用紙サイズと同じに設定します17。
% これでPDFを作るとA5サイズになる
\documentclass[a5paper]{article}
\usepackage[noheadfoot,top=20mm,bottom=30mm,hmargin=20mm]{geometry}
そうすると、パッケージオプションを何も書かずにgeometryパッケージを読み込めば、レイアウトは何も変更されずに出力用紙サイズの設定「だけ」が行われる、と思うかもしれません。
\documentclass[a5paper]{article}
\usepackage{geometry}% 何も設定しないよ!……のばずだが
しかしこれでは想定通りになっていません。geometryの一般的な動作として、レイアウトパラメタを適用する前に、文書クラスで与えられたレイアウト設定(の一部)を破棄してしまうからです。つまり上記の設定では文書レイアウトはarticleが定めるものではなくgeometryのデフォルトになってしまいます。
geometryパッケージが普段行うレイアウト設定を完全に抑止するにはpassというオプションを付ける必要があります。そういうわけで、出力用紙サイズの設定だけを行いたい場合は、「“pass”付きでgeometryを読み込む」のが今のところ最も妥当な方法です。何だか解りにくいですね……。
% これで出力用紙サイズの設定*だけ*ができる
\documentclass[a5paper]{article}
\usepackage[pass]{geometry}% 'pass'を付ける!
dvipdfmxの場合の注意
geometryパッケージはドライバ依存性をもちます。残念なことに、つい最近までは、geometryの仕様においては、dvipdfmx用のドライバの名前は(‘x’なしの)dvipdfmでした。従って、DVIウェアがdvipdfmxである場合は、グローバルオプションにdvipdfmxを指定していたとしても、geometryパッケージにdvipdfmオプションを付ける必要があります。何だか解りにくいですね……。
% 少し古いgeometryの場合
\documentclass[dvipdfmx,a5paper]{article}% 'dvipdfmx' があるので...
\usepackage{xcolor}% 他のパッケージはOK
\usepackage[dvipdfm,pass]{geoemtry}% しかしgeometryは 'dvipdfm' が要る
※【追記 2019-07-11】 2018年3月のgeometryの改修で、dvipdfmxのドライバオプションが使えるようになりました。従って、「dvipdfmxをグローバルオプションで指定する」場合に、geometryを特別扱いする必要がなくなりました。
% 最新のgeometryの場合
\documentclass[dvipdfmx,a5paper]{article}% 'dvipdfmx' があるので...
\usepackage{xcolor}% OK
\usepackage[pass]{geoemtry}% geometryもOK!
【追記】bxpapersizeで完全解決
【追記 2019-07-22】
2016年3月頃に、bxpapersizeパッケージという、出力用紙サイズ「だけ」を設定するパッケージが作られました。従って現在では、単純に「出力用紙サイズを設定したければbxpapersizeを使う」と覚えておけば大丈夫です。
% 最新の解決法
\documentclass[dvipdfmx,a5paper]{article}
\usepackage{bxpapersize}% これでOK!
その9:大型演算子のフォントサイズがアレ
LaTeXのデフォルトの設定では、\sumや\int等の大型演算子の数式フォントは現在のフォントサイズ設定に関わらず常に一定のサイズが適用されます(スケールしない)。従って、\normalsize以外のフォントサイズで大型演算子を含む数式を出力すると、非常にバランスが悪くなってしまいます。
\documentclass[a4paper]{article}
\usepackage[scale=0.76]{geometry}
\newcommand\sampleEq{%
\left(\int_0^\infty \frac{\sin x}{\sqrt{x}}dx\right)^2
= \sum_{k=0}^\infty \frac{(2k)!}{2^{2k}(k!)^2} \frac{1}{2k+1}
= \prod_{k=1}^\infty \frac{4k^2}{4k^2-1}
\neq \frac{\pi}{2015}}
\begin{document}
With normalsize (10\,pt):
\[ \sampleEq \]
{\Large With Large (14.4\,pt):
\[ \sampleEq \]\par}
{\footnotesize With footnotesize (8\,pt):
\[ \sampleEq \]\par}
\end{document}
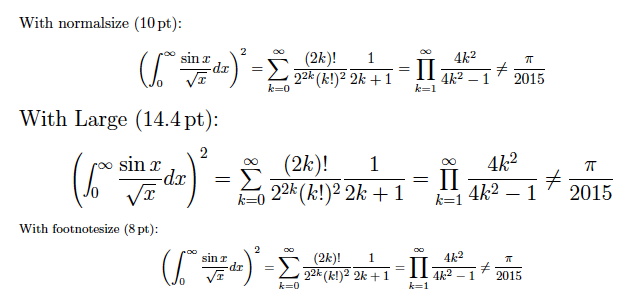
このアレな設定の理由は「CMの大型演算子のフォントは10ptで使うことを前提にして設計にされている」からだそうです。つまり、10pt以外のサイズでこのような数式を出そうとしてはいけない、ということです。(スケールしない出力の方がまだマシだ、という意図では決してありません!)
対策:exscaleパッケージを使う
そうはいっても、現実に、異なるフォントサイズで数式を組む必要はあるわけで、その場合はスケールさせる以外の選択肢は現状ではありません。
exscaleパッケージを読み込むと、大型演算子のフォントもスケールするようになります。
% 読み込むだけで OK
\usepackage{exscale}
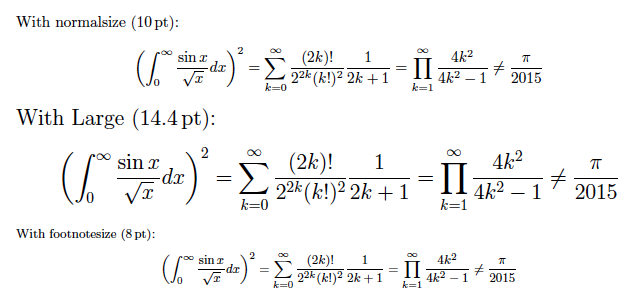
※数式フォントファミリを別のもの(newtxなど)に変えている場合は、大型演算子のフォントは最初からスケールする設定になっています。
% テキストと数式をともおに newtx 系に変える
\usepackage{newtxtext,newtxmath}
※【追記 2019-07-22】 これは後で気付いたのですが、普通にamsmathパッケージを読み込めばこの問題は解決できます。従って「マトモに数式を扱うならamsmathを使う」という原則に従っていれば大丈夫です。
その10:upTeXの和文カテゴリコードがアレ
LaTeXで日本語や英語の文書を書き続けていると、たまにハンガリー語が書きたくなる、ということは誰にでもあることでしょう。
この記事(再掲)によると、従来のUnicode非対応な欧文LaTeX(pdfLaTeXも含む)でUTF-8直接入力でハンガリー語を書くにはinputencパッケージを使えばよいのでした。
% 文字コードは UTF-8
\documentclass[a4paper]{article}
%↓これで UTF-8 できるぞ
\usepackage[utf8]{inputenc}
%↓ニュー・スタンダード!
\usepackage[T1]{fontenc}
\usepackage{lmodern}
\begin{document}
Köszi {\TeX}, és viszlát!
\end{document}
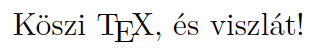
ところで、「UTF-8でアクセント付ラテン文字を入力」するという方法は、実はpLaTeXでも使うことができます(もちろんUTF-8のファイルを読むので入力漢字コードがUTF-8であることが必須)。
% pLaTeX 文書, 文字コードは UTF-8
\documentclass[a4paper]{jsarticle}
% 欧文 LaTeX のときと全く同じ設定
\usepackage[utf8]{inputenc}
\usepackage[T1]{fontenc}
\usepackage{lmodern}
\begin{document}
\section{いきなり結論}% 日本語できる!
Köszi {\TeX}, és viszlát! % ハンガリー語できる!
\end{document}

pLaTeXの和文処理は内部漢字コードがJISコード系(SJISかEUC)なので、和文文字として扱えるのはJISコード(JIS X 0208を指す、以下同様)にある文字に限られます。しかし入力はUTF-8である以上、「それ以外のUnicode文字」も含まれるはずです。それらについては、非常に粗くいうと、pLaTeXでは「欧文LaTeXと全く同様に」扱われることになっています18。幸い(?)なことにJISコードには「アクセント付ラテン文字」は全く収録されていない19ので、和文処理に“邪魔”されずにinputencの処理に回っているわけです。
ところがエンジンをupLaTeXに変えると様子が違ってきます。先の文書ソースの先頭部分を以下のように変えてupLaTeX文書を作ります。
% upLaTeX 文書, 文字コードは UTF-8
\documentclass[uplatex,a4paper]{jsarticle}
% あとは先と同じ
これをupLaTeXでコンパイルすると次のような悲惨な出力になってしまいます。

upLaTeXでは和文処理の内部文字コードがUnicodeになっていて、従って全てのUnicode文字が和文として“扱える”ことになります。ということは、アクセント付ラテン文字も和文文字(漢字と同じ扱い)として処理されてしまったのです20。これでは真っ当な出力になるはずがありません。
もちろん、upTeXエンジンの開発者はこの問題を承知していて、upTeXには各文字21を和文・欧文のどちらで扱うかを制御する機能を備えています。ところがupLaTeXのデフォルトとしては、(ASCII以外の)全てのUnicode文字を和文扱いする設定になっています。pLaTeXが“扱える文字全てを”和文扱いしているので、それに合わせたのでしょう。
対策:pxcjkcatパッケージを使う
先に述べた「和文・欧文扱いの制御」をLaTeXで行うにはpxcjkcatパッケージを利用します。パッケージの機能の詳細な説明は省略しますが、先の例のように「ラテン文字を欧文扱い」するには、prefernoncjk オプションを付けてpxcjkcatを読み込みます。
\usepackage[prefernoncjk]{pxcjkcat}
なお、pTeXエンジンには和文欧文扱いの制御の機能は存在せず、常にJISコードの範囲を和文、それ以外を欧文として扱います。アクセント付ラテン文字についてはそれでいいのですが、キリル文字・ギリシャ文字についてはこの仕様は致命的です。なぜならJISコードには(基本的な)キリル文字・ギリシャ文字が含まれているため、これらは常に和文扱いされ、inputencで扱うように設定することは不可能だからです。従って、欧文のUTF-8直接入力の処理能力についてpLaTeXとupLaTeXを比べるなら、明らかにupLaTeXの方に軍配が上がります。
% upLaTeX 文書, 文字コードは UTF-8
\documentclass[uplatex,a4paper]{jsarticle}
\usepackage[prefernoncjk]{pxcjkcat}
\usepackage[utf8]{inputenc}
\usepackage[T2A]{fontenc}
\usepackage{lmodern}
\begin{document}
\section{いきなり結論}% 日本語できる!
Спасибо {\TeX}, и до свидания! % ロシア語できる!
\end{document}

もちろん、欧文のUnicode処理周りについては、XeLaTeXやLuaLaTeXの圧倒的大勝利なのは言うまでもないですが。
【追記】最新のupLaTeXでは非アレ
【追記 2019-07-11】TeX Live 2018でのLaTeXカーネル側の「欧文のUTF-8入力をデフォルトにする」(先述の記事を参照)という改修に合わせて、upTeX側でも「upLaTeXで使われる可能性が高い一部のラテン文字」についてデフォルトで欧文扱いになるように仕様変更されました。従って現在では、先に示したハンガリー語の例についてはupLaTeXのデフォルトの設定のままで所望の結果が得られます。
% upLaTeX 文書, 文字コードは UTF-8
% *TeX Live 2018 以降*
\documentclass[uplatex,a4paper]{jsarticle}
% pxcjkcatもinputencも要らない
\usepackage[T1]{fontenc}
\usepackage{lmodern}
\begin{document}
\section{いきなり結論}% 日本語できる!
Köszi {\TeX}, és viszlát! % ハンガリー語できる!
\end{document}
その11:チョット新奇なファイル名でアレ
今の世の中では、ファイル名に“自由に名前を付けられる”(つまり当該のシステムがサポートするほぼ全ての文字列がファイル名として使える)のが当たり前になっています。しかしTeXが作られた当時のファイルシステムにおいては、ファイル名について強い制約がありました。
- 長さの制限が非常に厳しい(MS-DOSの“8.3”22が有名)
- 空白文字や(ベース名と拡張子の区切り以外の23)ドット「.」が使えない
- 異なるシステム間での運用を考慮するとASCII文字しか使えない24
このため、かなり長い間、TeXにおけるファイル名の選択はかなり制限の強いものになっていました。
- 空白文字を含められない。
例えば、foo bar.texを読み込もうとして\input foo barを実行しても、foo.texを読み込もうとする。 - (事実上)ASCII文字しか使えない。
しかし、TeXエンジンについては、最近は事情が大きく変わっています。例えば、非ASCII文字を含むファイル名についてはほとんどの場合に正しく取り扱えるようになっています。また、空白文字を含むファイル名についても " " で囲めば使えます25。
% plain TeXでの例
\input "foo bar" % 'foo bar.tex' が読み込まれる
ところが残念なことに、LaTeXの方は昔日の慣習に基づいた不合理なファイル名の制限を今でも引きずっています。
- 空白文字を含められない。
- 「.」が2つ以上あるファイル名を使うと、ファイル名の解析(ベース名と拡張子に分解する手続)が失敗する。
典型的な例としては、graphicxパッケージの\includegraphics命令で画像ファイルを挿入する場合、そのファイル名に空白文字や複数のドットが存在していると、実行が失敗してしまいます。
% pdfLaTeX 文書
\documentclass{article}
\usepackage{graphicx}
\begin{document}
\includegraphics[height=3cm]{tex are.png}% NG!
\includegraphics[height=3cm]{tex.are.png}% NG!
\end{document}
対策:grffileパッケージとか
一番最後に述べた\includegraphicsの事例については、**grffileパッケージ**を利用すればファイル名の制限が無くなります。
% pdfLaTeX 文書
\documentclass{article}
\usepackage{graphicx}
\usepackage{grffile}% 単に読み込むだけでOK
\begin{document}
\includegraphics[height=3cm]{tex are.png}% OK!
\includegraphics[height=3cm]{tex.are.png}% OK!
\end{document}
ただし、graphicxパッケージでdvipsやdvipdfmxを利用する場合には完全に対応していなくて、これらの場合は「複数ドット」は使えるようになりますが「空白文字」は相変わらず失敗してしまいます。
また、grffileは\includegraphicsが読む画像ファイルのみを対象としていて、その他の場面では特殊なファイル名が使えるようにはなりません。
【追記】PDF出力エンジンについては解決
[追記2019-11-26]
2019年10月のLaTeXのカーネルの改修により、TeXエンジンの中で閉じている処理に関してはファイル名に関する制限がほぼなくなりました。つまり、「空白」「複数ドット」「非ASCII文字」を含むファイル名がサポートされます。
TeXエンジンで閉じていない処理、例えばDVI出力の場合の画像の読込(これはDVIウェアにより処理されます)については、依然としてファイル名の制限が残っています。dvips・dvipdfmxによる画像の取込についていうと、「複数ドット」は扱えますが「空白」は扱えず、「非ASCII文字」は環境依存となります。
その12:既定の用紙サイズがアレ
これまでLaTeXについて「デフォルトの動作がアレ」な点を挙げてきましたが、ここからは少し趣向を変えて「デフォルトの決め方がアレ」という点を挙げていきたいと思います。
以前の話にあったように、LaTeXでは文書クラスのオプションで(レイアウト用の)用紙サイズを指定します。オプションということは省略可能なはずですが、省略した時のデフォルトの値は何でしょう?
正解は、「文書クラスに依存する」です。そもそも特定の用紙サイズ専用で、そのようなオプションを持たない文書クラスだってあるでしょう。一般的に使われる汎用の文書クラスに限ると、以下のようになっています。
- jarticle等の「和文標準文書クラス」→ a4paper
- jsarticle等の「新ドキュメントクラス」→ a4paper
- article等の「欧文標準文書クラス」→ letterpaper
- scrartcl等の「KOMA-Script文書クラス」→ a4paper
この「articleのデフォルトがletterpaper」というのは凶悪なトラップであると思っています。もちろん、TeXやLaTeXは米国で生まれたものなのでこの設定であるのは必然的なのでしょう。しかし自分がLaTeXを使い始めて暫くの間は「a4paper」の指定を忘れてしまって、そのままレターサイズのレイアウトのままA4の用紙に印刷してしまうという失敗を頻発していました。デフォルトの設定が文書クラスごとに異なるのは、やはり混乱の元になることは否めません。
LaTeX3(もし完成するとして)の標準文書クラスでは、「全世界で通用するデフォルト値」が想定できない以上、用紙サイズは必須指定にした方がいいかも知れませんね。
対策:そもそも既定に頼らない
不注意による事故を防ぐためにも、用紙サイズは省略せずに必ず指定する習慣をつけましょう。
\documentclass[a4paper]{jsarticle}% これで安心
その13:graphicxのドライバがアレ
graphicxパッケージや(x)colorパッケージのドライバ指定の(DVI出力モードの時の)デフォルトの値は厳密に言うと“環境依存”なのですが、最近の主要なTeX配布においてはほぼ常に「dvips」がデフォルトです。それ以外の“ドライバ依存”のあるパッケージにおいても(ドライバが決定できない場合の)デフォルト値はほとんどの場合「dvips」となっています。
\documentclass[a4paper]{jsarticle}
\usepackage{tcolorbox}
% ↑ドライバ指定が無いので 'dvips' と見なされる
特定のドライバの場合に(だけ)指定を省略できるという仕様は、LaTeXユーザ全てが、「どのパッケージがドライバ依存を持つか、そしてデフォルトの値は何か」を完全に把握しているならば好ましいといえるでしょうが、現実にはそんな理想的な状況ではありません。例えば「pLaTeX+dvipdfmxのユーザがtcolorboxパッケージをドライ指定を忘れたまま読み込む」という可能性は十分あります。その結果何が起こるかというと、LaTeXでのコンパイルは正常に終わるのにdvipdfmxで変換した結果は異常になる、おまけに、「ドライバ指定がおかしい」という警告やエラーは一切出てこないので、異常の原因が全然わからない、という(前節のものよりさらに)凶悪なトラップが発生してしまいます。
もし、(DVI出力の場合の)ドライバ指定が必須だったとしたら、忘れた場合に「ドライバ指定が無い」という非常に的確なエラーを出すことができます。こちらの方が幸せな世界だったのではないでしょうか。
対策:そもそも既定に頼らない
先の話と同じで、ドライバ指定は省略せずに必ず指定するように心がけましょう。
\documentclass[a4paper]{jsarticle}
\usepackage[dvips]{tcolorbox}% 明示的に dvips
※ドライバ依存のパッケージに関する解説記事を書く場合は、例として示す文書の中に何らかのドライバ指定を入れた方がよいと、私は思います。現在のLaTeXユーザによっては、ドライバ指定に関する話は(初級者も含めて)当然知っているはずの知識なので、少なくとも [dvips] とかの“ドライバ指定に見えるオプション”があれば、当該のパッケージがドライバ依存をもつことが理解されるはずです26。
※PDF出力を行うエンジンを使っている場合は話が別です。この場合は常に正しいエンジンが自動的に選ばれるので、ドライバ指定は特に気にする必要がなく、従って省略するのが妥当です。
なお、最近ではドライバ指定はパッケージ毎に指定するのではなく、「グローバルオプション」とする、すなわち文書クラスのオプションとして指定することが推奨されています。そうしないと想定外にデフォルト(dvips)が採用されてしまう「微妙なケース」の存在が知られているからです。
% ドライバは全部 dvipdfmx!
\documentclass[dvipdfmx,a4paper]{jsarticle}
\usepackage{color}
\usepackage{tikz,tcolorbox}
\usepackage[colorlinks]{hyperref}
※先に述べた通り、以前は「geometryパッケージ+dvipdfmxの組合せ」が例外的でした。
これを踏まえると、LaTeX文書では常にドライバオプションを文書クラスに指定する(DVI出力の場合)のが現代のベストプラクティスとして考えられるでしょう27。
その14:「例の1インチ」がアレ
ここからはまた別のタイプの“デフォルトがアレ”な話です。
文書クラスの作製をしたことのある人なら知っていると思いますが、LaTeXのページレイアウト設定のパラメタにおいて、マージン(\oddsidemargin/\evensidemargin/\topmargin)には「1インチのオフセット」があります。すなわち、これらの3つのパラメタには「実際の値から1インチを差し引いた値」を指定する必要があるのです。
% (calc を読み込んだとして)
% 左マージンを 20mm にする (奇数・偶数ページともに)
\setlength{\oddsidemargin}{20mm-1in}
\setlength{\evensidemargin}{\oddsidemargin}
% 上マージンを 30mm にする
\setlength{\topmargin}{30mm-1in}
plain TeXにおいては、マージンの設定は\hoffset/\voffsetというパラメタ(プリミティブ)で行いますが、やはりこれらのパラメタも「1インチのオフセット」を持っていて同様の注意を払う必要があります。
このような妙な仕様になっている原因は、TeXが使っている座標系(x軸は右向き、y軸は下向き)の原点が「紙面の左上隅」ではなくて「左上隅から右と下にそれぞれ1インチ移動した点」にあると定められているからです。この原点は実際にページを出力する際の“版面を表すボックス”(の左上隅)を配置する参照点のデフォルト値となっています。そして、この“版面を置く点”の座標を表すパラメタが\hoffsetと\voffsetであり、だから先に述べたような仕様になっているのです28。
ではなぜ「原点の規定」はそうなっているのでしょうか。これについては(何度か調査したことがあるのですが)全くの謎です。単に「デフォルトのマージンを1インチにしたかった」のであれば、素直に原点を左上隅にした上で\hoffset/\voffsetのデフォルト値を1インチにすれば済むはずです。だからそんな単純な理由ではないのだと考えています。
対策:geometryパッケージを使う
とはいっても、今時は、LaTeX文書でページレイアウトを変更したい場合は**geometryパッケージを用いる**のが常識になっている感じもします。
\documentclass[a4paper]{article}
% 上マージン=20mm, 左右マージン=25mm, 下マージン=30mm
\usepackage[top=20mm, hmargin=25mm, bottom=30mm]{geometry}
ここで指定する値はもちろんマージンの値そのものです。「例の1インチ」についてはgeoemtryパッケージが面倒を見てくれます。そういうわけで、普通のLaTeXユーザが「例の1インチ」を気にしないといけない時代はもう終わっているのかも知れません。
その15:レジスタが足りなくなるのがアレ(だった)
LaTeXを使っていて
! No room for a new \dimen.
というエラーに出くわしたことはないでしょうか。特に多数のパッケージを同時に読み込んでいると発生する可能性が高くなります。
このエラーは、TeXエンジンがもっているレジスタという資源が不足したことを表しています。「レジスタとは何か」に関する詳しい説明は(TeX言語な話になってしまうので)省略しますが、一般のプログラム言語における“変数”に相当するものです29。レジスタにはいくつか種類があるのですが、上の例で不足しているのは「寸法レジスタ(dimenレジスタ)」と呼ばれるものです。
元来のTeXエンジンは各種のレジスタを256個ずつ持っています。そしてLaTeXにおいては、カーネルやパッケージがそれぞれ自分が必要とする分だけレジスタを確保する、という規約になっています。ところが、LaTeXのカーネルや大規模なパッケージでは大量のレジスタを必要とします。例えば、カーネルは約100個、TikZは約50個の寸法レジスタを確保します。この感じだと大規模なパッケージを複数読み込んでいると、レジスタが256個しかなければ不足してしまうのも当然でしょう。
……いえ、違います! 最近の環境においては、このエラーが出たとしても、ほとんどの場合はまだレジスタは大量に残っています。なぜなら、今のTeXエンジンは数万個のレジスタを持っているからです。
レジスタが256個では全然足りないことは古くから把握されていて、1990年代後半に発表された「e-TeX拡張」においてはレジスタの個数は32768個に拡充されています。その後、海外ではTeXエンジンは「e-TeX拡張」をもつものに置き換えられました。日本でも、pTeXの「e-TeX拡張」である「e-pTeX」が2010年ころに開発され、今では主要な拡張TeXエンジンの全てが「e-TeX拡張」に対応しています30。つまり今のTeXエンジンはどれも32768個(以上31)のレジスタを持っているのです。
では何故「レジスタ不足」のエラーが出続けるのかというと、それはまさしく「LaTeXのアレなデフォルト」のせいなのです。ずっと以前から、LaTeXは(TeXと同様に)“仕様を凍結”して、次の方針をとっています(正確には「いました」;後の説明を参照)。
そして、e-TeX拡張の大量のレジスタについては、原則に則ってetexというパッケージでサポートされることになっています。すなわち、次のことがいえます。
LaTeXで
No room for ~のエラーが出たときの正しい解決方法は、etexパッケージを読み込むことである。
普通のLaTeXユーザにとって非常に解りにくいのは言うまでもありません。さらに悪いことに、このエラー自体は直接は“TeXレベル”の操作(レジスタの確保)に関して出ているものです。だから、このエラーメッセージをググった場合、運が悪いと、“TeXレベル”の詳細な解説が書かれたページに連れていかれる危険性が高いのです。
対策:新しいTeX配布をインストールする
幸いなことに、先に述べた“凍結”の方針は、2015年になって解除され、不具合の改善や拡張エンジンへの対応はカーネルを修正することで行われる方針に変更されました。そして2015年のLaTeXのリリースでは、それまで別パッケージとして提供されていた機能の一部がカーネルに取り込まれることになりました。その中には、etexパッケージの機能(に相当するもの)も含まれています。つまり、最新のLaTeXを使う場合には、No room for ~のエラーはもはや起こらない34ので、etexパッケージは不要なわけです。
※記事執筆当初(2015年12月)は、この項目が唯一の「アレなデフォルトが解消した」事例でした。公開以降に行われた【追記】を見てわかるように、「アレなデフォルトが解消した」事例は少しずつですが増えています。
まとめ
LaTeXに潜む「アレなデフォルト」の傾向と、その対策についての話をしました。その最後の項目では、LaTeXの“凍結解除”について述べました。
LaTeXの方針が「LaTeXのアレなデフォルトは直していく」ことに変わったのは、私は非常に好ましいことだと考えています。今後いっそうの「LaTeXのデフォルトの非アレ化」が進むことを願って、この記事を終えたいと思います。
-
「TeX」が最初に公開されたのは1978年のこと(この実装のことを「TeX78」と呼ぶ)ですが、これは一旦破棄されて改めて書き直されました。それが1982年にリリースされた「TeX82」で、この実装の改訂版が現在も使われています。 ↩
-
ここでは他のソフトと比較するため、敢えてTeX関係の“ロゴ”を使わずに出力しています。 ↩
-
この現象については、min10の実装上のバグだと推定されています。 ↩
-
これは極めて粗い(不正確な)説明ですが、「TeXレベル」の詳細な話に立ち入りたくないのでこれで済ませることとします。なお「jis」の名称は、日本語組版の標準を定めたJIS規格であるJIS X 4051に由来します。(文字コードのJIS規格のことではありません。) ↩
-
あとの6つは何かというと、私は知りません。 ↩
-
abstract環境以外に、quotation環境でも段落下げの量が奇妙です。さすがに普通の本文中の段落下げは大丈夫なのですが……。 ↩
-
「しかる」を表す漢字は〈𠮟〉であり、元来〈叱〉はこれとは別の字です。しかし現行の常用漢字表においては、〈叱〉が〈𠮟〉の意味で使われている現状を是認して、あえて〈叱〉と〈𠮟〉を同じ字種・同じ字体の別のデザインと見なしています。要するにどちらを使っても“正しい”わけです。 ↩
-
Unicodeにおいて、〈☃〉(U+2603)のような「文字コード値がU+10000未満」の文字のことを「BMPの文字」といいます。つまり、「BMP外の文字」というのは文字コード値がU+10000以上(16ビットの範囲を超える)である文字のことです。 ↩
-
改修後の仕様(およびotfを読みこんだ場合の仕様)ではBMP外の文字は「AJ1の範囲」に限ってサポートされます。「通常の使用」においてはDVIウェアのフォントマップ指定で“AJ1指定”が適用されていで、この場合、使える文字は元々AJ1の範囲に限定されているため、upTeX側の論理フォントの指定はAJ1の範囲をカバーすれば十分なわけです。フォントマップ指定で“Unicode直接指定”を利用している場合であっても、とにかく「BMP外のAJ1の範囲」がサポートされている点は同じです。 ↩
-
さらに言うと、Unicode対応のXeLaTeXやLuaLaTeXですら、デフォルトのフォントはつい最近まで「7ビット」のCMフォントのままでした。実際はこれらのエンジンではほぼ確実にfontspecパッケージが使用されて何らかの「Unicodeな」フォントが指定されるはずなので、実際上の問題はなかったのですが。【追記】2017年1月のLaTeXの改訂により、XeLaTeXとLuaLaTeXのデフォルトのエンコーディングがUnicode(TUエンコーディング)に変更されました。この場合、デフォルトのフォントが「UnicodeのLMフォント」になります。 ↩
-
もちろん、TeXが専ら「英語がメインの文書を紙に印刷する」ために用いられていた時代にはこの仕様でも問題になりませんでした。 ↩
-
OT1エンコーディングのフォントがテキストフォントに指定されている限り、先に示した表にある文字以外は「普通に文字として」は出力できないことに注意してください。ちなみに、数式出力のほうは、出したい文字(命令)によって自動的にフォントを切り替える仕組みがあるため、使える文字種の数に関する制限はずっと緩いのですが、その代わり、書体を自由に変更できません。 ↩
-
非特殊文字は全てそのまま入力できます(
<で〈<〉が出る)。LaTeXの特殊文字のうち、#$%&_{}を出力したい場合は、前に\を付けて入力する必要があります(\_で〈_〉が出る)。残りの3つの特殊文字については、\は\textbackslash、^は\textasciicircum、~は\textasciitildeという命令で入力できます。 ↩ -
結局256種類しか使えないので、〈é〉〈ö〉〈ă〉〈ů〉〈ś〉は“1つの文字”として扱われますが、T1の表の中にない〈ŵ〉はT1でも合成でしか出せません。 ↩
-
\symbol命令などのフォントエンコーディングに依存する機能を使っている場合は例外になります。なお、OT1で便宜的に〈<〉を数式扱い($<$)で書いていた場合はT1では数式扱いをやめた方(<)が好ましい、のように「変えた方が好都合」なケースはあります。 ↩ -
これは恐らく「“明朝体の太字”をゴシック体で代用する」というpLaTeXのデフォルトの設定に合わせたものなのでしょう。 ↩
-
出力用紙サイズをレイアウト用より大きくしてトンボを出力する、などの設定も可能です。 ↩
-
欧文LaTeXはUTF-8のバイト列をそのままバイト列として読み込みます。inputencはそれをTeX言語のマクロで“デコード”して書かれたUnicode文字を判読しています。これに対して、pLaTeXはJISコードにあるUnicode文字については、それを直接(和文の)“文字”として認識します。しかしJISにない文字については、もう一度それをUTF-8のバイト列に戻して欧文の入力として処理させているのです。 ↩
-
JIS X 0208においてはアクセント文字や丸数字のような「合成可能」な文字は「合成により表現できる」と理由で単独では収録されませんでした。ただし、JIS X 0208自体は合成した文字を表現する仕組を全く持たないため、結局それらの文字は表現できていません。JIS X 0208の(事実上の)拡張である新しいJIS規格のJIS X 0213では多くのアクセント文字や丸数字を収録しています。 ↩
-
従って、この出力結果の〈ö〉や〈é〉は和文フォントで出力されています。先の出力結果画像で実際に使われている日本語フォントはIPA明朝で、これらのラテン文字は半角幅を持っています。ところが、upLaTeXのデフォルトのフォントメトリックではほとんど全ての文字が全角幅をもつことが仮定されています。実際の日本語フォントの状況と齟齬を起こしているので、隙間が空いているなどの異常な出力になっているのです。そもそも日本語フォントが使われること自体が間違いなので、ここから無理やり空白を調節したとしてもマトモな出力は決して得られません。 ↩
-
和文・欧文の制御は実際には「Unicodeブロック」単位での設定になっています。ASCII文字(U+0000~U+007F)は常に欧文扱いです。 ↩
-
MS-DOSで使用可能なファイル名は「8文字以内のベース名」+「.」+「3文字以内の拡張子」でした。 ↩
-
例えば、「foo.txt」は使えますが「foo.bar.txt」は使えません。 ↩
-
この項目は現在でも当てはまりますが、ファイル名にUnicodeが使えるシステムが普及したため、その影響はかなり小さくなりました。 ↩
-
LaTeXの
\input命令は\input{ファイル名}のように使いますが、TeXのプリミティブの\inputは\input ファイル名という書式で、昔は、ファイル名は空白文字または非文字トークン(\relaxなど)が現れた時点で終結していました。今では、"~"で囲われた部分では空白文字で終結しない仕様に変わっています。 ↩ -
もちろんドライバ指定について説明するのが一番親切なのは間違いないのですが、例えば、「Beamerについて何か書くときに、毎回ドライバ指定の注意を書く」のは少し冗長な気もします。 ↩
-
この方式の難点は、ドライバ依存のパッケージが1つも読み込まれなかった場合に、ドライバオプションについて「オプションが未使用である」という警告が出てしまうことです。これを回避するために、とりあえず「graphicxパッケージは常に読み込んでおく」ことにするといいかもしれません。 ↩
-
\hoffsetと\voffsetのデフォルト値はゼロ(0pt)です。よって(“原点”の定義と合わせて考えると)デフォルトの左と上のマージン量は1インチとなります。なお、LaTeXでは何故か\hoffset/\voffsetを利用せずに(ゼロのままにして)自前で版面のボックスを(\oddsidemargin/\evensidemargin/\topmarginの値だけ)移動させる処理を行っていますが、効果としては同じです。 ↩ -
つまり、「変数に割り当てるための専用のメモリ領域」があって、それを全部使い尽くしたための「メモリ不足(OOM)」の一種と考えればよいでしょう。 ↩
-
ただしTeX配布の中に肝心の“オリジナルのTeX”が入っていないと、Knuth氏が嘆き悲しむことになるので、TeX Liveなどの主要なTeX配布では“オリジナルのTeX”も配布物に含めていて、当然これだけはe-TeX拡張に非対応です。 ↩
-
例えば、arrayパッケージはLaTeXの表組機能に関する“修正”といえるでしょう。この他、細かい不具合の修正をまとめたfixltx2eというパッケージも存在します。 ↩
-
例えば、XeTeX/LuaTeXエンジンがもつ「OpenTypeフォントのサポート」をLaTeXで使いたい場合は、fontspecパッケージを読み込むことになります。 ↩
-
もちろん、数万個のレジスタを本当に使い切ってしまった場合は除きます。 ↩