LaTeX において「UTF-8で文字を直接入力する」機能を提供する、inputencパッケージの紹介です。
[2018-06-20追記] TeX Live2018から、欧文(pdf)LaTeXの既定の入力文字コードがUTF-8に変更されました。従って、過去との互換性が必要な場合を除いてinputencを自分で読み込む必要は無くなりましたが、一方で、この記事の後半で述べられている、「Unicode文字の出力方法」に関する知識は引き続き役に立つでしょう。
inputencパッケージしない話
……というと、「あれっ?」と思う人もいるでしょう。LaTeXでUTF-8を使うのにパッケージなんか要ったかな?
もちろん、TeXエンジンによっては、エンジン自体がUTF-8を解釈できる場合もあり、その場合はinputencパッケージを使う必要はありません。具体的には次のようなケースです。
-
XeLaTeX/LuaLaTeXは既定で入力にUTF-8が使えます。そして事実上、それしか使えません。
※この場合、inputencパッケージは絶対に読み込んではいけません。
※ただし、実際にUTF-8での入力を活かそうとすると、Unicode対応フォントに切り替える必要があるので、実際にはfontspecパッケージが必須です。
例1:Unicode対応のLaTeXでのUTF-8入力% XeLaTeX文書, UTF-8 \documentclass[a4paper]{article} % フォントを"Linux Libertine"に切り替える. \usepackage{fontspec} \setmainfont{Linux Libertine O} \begin{document} % "フォントにある文字"なら何でもOK! Ευχαριστώ {\TeX}, et до свидания! \end{document}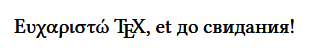
-
(u)pLaTeXの和文の文字コードは起動時のオプション
-kanjiで指定します。UTF-8にする場合は-kanji=utf8です。(upLaTeXではUTF-8が既定です。)例2:upLaTeXでの和文のUTF-8入力% upLaTeX文書, UTF-8 \documentclass[a4paper,uplatex]{jsarticle} \begin{document} ありがとう {\TeX}、そして ピㇼカノ パイェ ヤン! \end{document}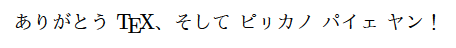
逆にいうと、これら以外の次のような場合には、TeX Live 2017以前のLaTeXではUTF-8での入力は既定では対応していませんでした。
- 従来の欧文のLaTeX(pdfLaTeXを含む)を使用する場合。
- (u)pLaTeXで欧文の文字を入力する場合。
このような場合について、ASCIIにない欧文文字をUTF-8で入力する機能を提供するのがinputencパッケージです。この記事では、欧文LaTeX(pdfLaTeX)においてUTF-8入力を行う方法を解説します。
補足:新しいLaTeXではUTF-8入力が既定になった
[2018-06-20追記]
2018-04-01版のLaTeX(TeX Live 2018)において、欧文(pdf)LaTeXの既定の入力文字コードがUTF-8に変更されました。
- TeX Live 2018 注目ポイントまとめ (1) (Acetaminophen’s diary)
実際には、このUTF-8対応の処置は「inputencを予め読み込む」ことで実現されています。従って、「inputencパッケージを\usepackageする必要がなくなった」という一点を除いて、本記事の内容はそのまま通用します。
(u)pLaTeXユーザのために補足しておく
(u)pLaTeXでの欧文のUTF-8入力については、基本的なところは欧文LaTeXと同じで、inputencを利用することになる(従って本記事の内容が通用する)のですが、その他に(u)pLaTeXに特有の設定が色々と必要になります。これについては以下に挙げる記事を参照してください。
- upLaTeX でアクセント付きのラテン文字などがうまく出力されないときの対処法(Colorless Green Ideas)
- 『その10:upTeXの和文カテゴリコードがアレ』 ― LaTeX の「アレなデフォルト」 傾向と対策 (Qiita)
inputencしてみる話
inputencの最も基本的な使い方は、次のようにオプションに文字コード(入力エンコーディング1)の名前を指定してパッケージを読み込むことです。これで以降の入力が指定の文字コードで解釈されます。
\usepackage[文字コード名]{inputenc}
UTF-8を表す文字コード名はutf8なので、次のようになります。(他にlatin1(Latin-1)、koi8-r(KOI8-R)、ansinew(CP1252) 等の8ビットコードが指定できます。)
\usepackage[utf8]{inputenc}
% pdfLaTeX文書, UTF-8
\documentclass[a4paper]{article}
\usepackage[utf8]{inputenc}
\begin{document}
Köszi {\TeX}, és viszlát!
\end{document}
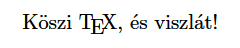
[2018-06-20追記]なお、TeX Live 2018以降では、予め\usepackage[utf8]{inputenc}を実行した状態が既定になるため、inputencの読込は不要になります。ただし、従来通りinputencを読み込むことも可能なので、古いTeXシステムとの互換性が必要な場合はそうしておくといいでしょう。
% pdfLaTeX文書, UTF-8
\documentclass[a4paper]{article}
% inputencの読込は不要
\begin{document}
Köszi {\TeX}, és viszlát!
\end{document}
※この記事の以降の例も、TeX Live 2018以降ではinputencの読込は不要です。
基本的に、inputencについての必要な知識はこれだけです。簡単でしたね。めでたしめでたし。
……となればいいのですが、残念ながらこれだけでは話は済みません。LaTeXでは文字の“入力”と“出力”の設定を別に取り扱っているからです。
inputencは“入力できるだけ”
よく知られている通り、先の例のような「アクセント付のラテン文字」は、アクセント命令を使うことで「ASCII文字だけで」入力することも可能です。
% pdfLaTeX文書, UTF-8
\documentclass[a4paper]{article}
\usepackage[utf8]{inputenc}
\begin{document}
K\"oszi {\TeX}, \'es viszl\'at!
\end{document}
実は、inputencがやっていることは、öのような非ASCII文字を\"oのような“LaTeXの標準的な入力”2に変換しているだけです。
ö → \"o; é → \'e; ß → \ss;
従って、例3(UTF-8直接入力)と例4(ASCII入力)は全く同じ出力を行います。
ところで、実際にLaTeXで非英語の欧文の文書を表したことがある人なら気づいたと思いますが、例4には問題があります。これではフォントエンコーディングが既定のOT1のままなので、〈ö〉のようなアクセント付文字が「合成」になってしまって、その結果、PDF中のテキスト情報が不正になる等の“不具合”が起こります。これを解消するには、フォントエンコーディングをT1に変える必要があったのでした。
\usepackage[T1]{fontenc}% OT1→T1に変更
\usepackage{lmodern}% T1にするなら当然Latin Modern
※詳細については以下の記事を参照してください。
そして、UTF-8入力とASCII入力は出力については全く同じなので、例3についても同じ対処が必要になります。
% pdfLaTeX文書, UTF-8
\documentclass[a4paper]{article}
\usepackage[utf8]{inputenc}
\usepackage[T1]{fontenc}
\usepackage{lmodern}
\begin{document}
Köszi {\TeX}, és viszlát!
\par% ↑↓出力は全く同じ
K\"oszi {\TeX}, \'es viszl\'at!
\end{document}
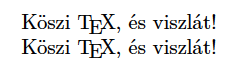
とにかく、UTF-8入力とASCII入力は出力に関しては等価であることに注意してください。
出力に関しては等価なので、もしある特定の設定の下で、ある文字がASCII入力で出力できないならば、同じ設定下で、その文字はUTF-8入力でも出力できません。例えば、既定の設定でいきなりキリル文字を出力しようとしても失敗します。
% pdfLaTeX文書, UTF-8
\documentclass[a4paper]{article}
\usepackage[utf8]{inputenc}
% キリル文字の"出力"の設定がない
\begin{document}
До свидания!! %エラー
\end{document}
この文書をコンパイルすると、「文字〈Д〉が利用できない」という旨のinputencのエラーが表示されます。
! Package inputenc Error: Unicode char \u8:Д not set up for use with LaTeX.
これを解決するには、文字が現れる箇所で有効なフォントエンコーディングがその文字が利用可能なもの(〈Д〉の場合はT2A等)になっている必要があります。
% pdfLaTeX文書, UTF-8
\documentclass[a4paper]{article}
\usepackage[utf8]{inputenc}
\usepackage[T2A]{fontenc}
\begin{document}
До свидания!! %OK
\end{document}

要するに、inputencのutf8入力エンコーディングが実際に役に立つのは“出力できる”文字、つまりLaTeXのフォントエンコーディングの機構だけで処理できるものに限られます。現状で該当するのは、ラテン文字・ギリシャ文字・キリル文字の各用字系とtextcompの記号などです。それ以外の用字系を旧来の欧文LaTeXで扱うには専用のパッケージ(例えばアラビア文字ならArabTeX等)が必要で、その場合の「UTF-8直接入力」への対応はそのパッケージの責任となります。
ギリシャ文字についての注意
utf8入力エンコーディングにギリシャ文字(LGRフォントエンコーディング)が対応したのは割と最近のことで、TeX Liveだと2013以降です。(greek-inputencおよびgreek-fontencというパッケージが当該の機能を提供しています。)
% pdfLaTeX文書, UTF-8
\documentclass[a4paper]{article}
\usepackage[utf8]{inputenc}
\usepackage[LGR,T1]{fontenc}% T1を"既定"にする
\usepackage{lmodern}% ※注
% LGRのままラテン文字(ASCII)を書くとギリシャ文字(ASCII翻字)に
% 化けてしまうので, ギリシャ語の部分だけLGRにする
%% \myGrk{テキスト} : LGRに切り替えて出力.
\newcommand\myGrk[1]{{\fontencoding{LGR}\selectfont#1}}
\begin{document}
\myGrk{Ευχαριστώ} {\TeX}, és viszlát!
\end{document}

※Latin Modernフォントはその名前の通りラテン文字のみを含んでいるため、当然LGRには対応していません。しかし、割と新しいTeXシステムでは、lm*ファミリのままLGRに変更すると自動的にcm*ファミリに振り替えられます。
それより古いTeX Liveの場合、および他のTeXシステムでgreek-inputenc等が標準で含まれていない場合は、以下の何れかの対策を講じる必要があります。
-
TeX Live 2012の場合は、fontencでLGRを宣言する代わりにtextalphaパッケージを読み込むと、UTF-8直接入力ができるようになります。
\usepackage{textalpha} -
CTANからgreek-inputencとgreek-fontencの両パッケージを入手してインストールします3。これでTeX Live 2013以降と同じ機能が使えます。
-
utf8の代わりに「utf8x」という特殊な入力エンコーディングを利用するという方法もあります。(ucsというパッケージが必要です。)
例9:utf8xの使用例% pdfLaTeX文書, UTF-8 % ucsパッケージが必要 \documentclass[a4paper]{article} \usepackage[utf8x]{inputenc} \usepackage[LGR,T1]{fontenc}% T1を"既定"にする % もし'T1/lmr/...'が無いというフォントのエラーが出る場合は % lmodern の使用を諦める(ラテン文字がcm-superになる) \usepackage{lmodern} \newcommand\myGrk[1]{{\fontencoding{LGR}\selectfont#1}} \begin{document} \myGrk{Ευχαριστώ} {\TeX}, és viszlát! \end{document}ただし、この“utf8x”の実装コードはかなり複雑で、そのため、幾つかのパッケージと共存できないことが知られています。できる限りutf8で済ませる方が好ましいでしょう。
“文字の知識”を自分で追加する
既に述べたように、UTF-8入力を利用しても、現在有効なフォントエンコーディングにない文字はそもそも出せません。しかしLaTeXの場合、アクセント合成ができるので、「アクセント付のラテン文字」程度であれば、とにかく“それに見える”ものを出力することはできます。(PDFのテキスト情報は潰れてしまいますが。)例えば、文字〈ḥ〉(下ドット付h)であれば、\d{h}で出力できます。
Dhanyav\=ada\d{h}
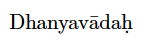
残念ながら、utf8入力エンコーディングは基本的に「フォントエンコーディングにある文字」を入力するための機構なので、このような「合成で出力する文字」の知識まではもっていません。つまり、ḥを直接書いてそれを\d{h}に変換させることは既定ではできないのです。
しかし、ユーザが自分で“文字の知識”を追加することができます。このための便利な命令がnewunicodecharパッケージが提供する\newunicodechar命令です。この命令は次のように使います。
\newunicodechar{文字}{その文字を出すためのLaTeXコード}
次の例では、この\newunicodechar命令で〈ā〉や〈ḥ〉の定義を与えることでUTF-8の直接入力を実現しています4。
% pdfLaTeX文書, UTF-8
\documentclass[a4paper]{article}
\usepackage[utf8]{inputenc}
\usepackage[T1]{fontenc}
\usepackage{lmodern}
% "T1にない"文字を使いたい
\usepackage{newunicodechar}
\newunicodechar{ā}{\=a} % U+0101 latin small letter a with macron
\newunicodechar{ḥ}{\d{h}} % U+1E25 latin small letter h with dot below
\begin{document}
Dhanyavādaḥ {\TeX}, punaḥ milāmaḥ.
\end{document}
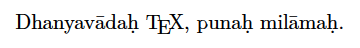
なお、\newunicodecharで定義するものは記号でもよいので、例えばシンボルフォントに含まれる文字をUnicode文字に結び付けて使うこともできます。
% pdfLaTeX文書, UTF-8
\documentclass[a4paper]{article}
\usepackage[utf8]{inputenc}
\usepackage[T1]{fontenc}
\usepackage{lmodern}
\usepackage{wasysym}% \smiley の出処
\usepackage{newunicodechar}
\newunicodechar{☺}{\smiley}% U+263A white smiling face
\begin{document}
\begin{center}
egy idióta vagy
\par\large
☺\quad ☺\quad ☺
\end{center}
\end{document}
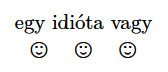
※newunicodecharパッケージはTeX Liveだと2011以降に含まれます。TeX配布に含まれていない場合は自分でインストールしてください。代替案として、inputenc(のutf8エンコーディング)自身が提供している \DeclareUnicodeCharacter という命令を用いることもできます。この命令は第1引数に定義する文字のUnicode値の16進数をとります。
\DeclareUnicodeCharacter{263A}{\smiley}% ☺ = U+263A
\DeclareUnicodeCharacter{1E25}{\d{h}}% ḥ = U+1E25
まとめ
inputencパッケージを使うと旧来の欧文LaTeX(pdfLaTeX)においてUTF-8で文字を“入力”できます。ただし、実際に非英語文字を“出力”するためにはfontencパッケージも必要です。
-
この意味の「文字コード」はLaTeXの用語で「入力エンコーディング」(input encoding)といいます。パッケージ名のinputencはこの用語に由来します。 ↩
-
“LaTeXの標準的な入力”のことをLaTeX用語で「LICR(LaTeX internal character representation)」といいます。 ↩
-
ただしこの際に注意点があります。インストールの作業を行った直後は、
lgrenc.defというファイルが元からシステムにあるもの(恐らく$TEXMF/tex/generic/babel/greek/にある)と新たにgreek-fontencから導入されたものの2つがある状態になります。このうち「TeXから見える方」が後者である必要があります。多くのシステムでは実際に後者が優先されるのですが、前者が優先されるシステムも存在します。mktexlsr実行後にkpsewhich lgrenc.defを実行して「自分が入れた方のパス」が出ることを確認してください。もし上手くいかない場合は、既存の方のlgrenc.defを削除するという強硬策を採る必要があります。 ↩ -
なお、2017年1月のLaTeXの改訂において、T1に含まれない(合成により出力される)ラテン文字の一部について、標準で文字の定義が与えられるようになりました。例えば〈ā〉は標準で直接入力が可能です。(〈ḥ〉は不可。) ↩