はじめに
私たちのチームは、スマートパーキングシステムの開発に取り組んでいます。その中核機能の一つが、駐車場に入ってくる車両のナンバープレートを自動認識する機能です。
現行のナンバープレート認識モデルは、日常的な運用においては十分な精度を発揮しています。しかし、私たちは「ほぼ正確」では満足していません。ゼロエラーを目指し、さらなる精度向上に挑戦し続けています。
そのためには、より多くの、より質の高い学習データが必要です。
本記事では、私たちがどのようにして日本全国のナンバープレートデータセットを効率的に構築したのか、その技術的な取り組みについてご紹介します。
直面していた課題
地域名識別の壁
現在のモデルの精度を詳細に分析したところ、エラーの大部分が地域名(地名)の誤認識に起因していることが判明しました。
日本のナンバープレートには、登録地域を示す地名が記載されています。東京、大阪、名古屋といった大都市の地名については、十分な学習データがあるため高い精度で認識できます。しかし、地方の小規模な地域、例えば「飛騨」「庄内」「出雲」といった登録台数の少ない地域については、学習データが圧倒的に不足していたのです。
合成データの限界
当初、この問題を解決するために**合成データ(Synthetic Data)**を活用しました。フォントや配置のルールに基づいて、人工的にナンバープレート画像を生成し、学習データを増強する手法です。
一見、効率的に見えるこのアプローチですが、実験を重ねるうちに明らかな限界が見えてきました。
| データタイプ | メリット | デメリット |
|---|---|---|
| 合成データ | 大量生成が容易、コスト低 | 現実との微妙な差異が存在 |
| 実データ | 認識精度向上に直結 | 収集に時間とコストがかかる |
合成データと実データの間には、光の反射、汚れ、角度、経年劣化など、言語化しにくい「微妙な差異」が存在します。この差異こそが、モデルの精度向上を阻む原因でした。
結論:高精度を実現するには、実際のナンバープレート画像が必要である。
しかし、地方の過疎地域まで実際に赴いてデータを収集するのは、時間的にもコスト的にも現実的ではありません。
転機:ドライブ動画という宝の山
YouTubeに眠る膨大なデータ
ある日、チームメンバーの一人が興味深い発見をしました。
YouTubeには、日本全国の高速道路や一般道を走行する**車載カメラ映像(ドライブレコーダー映像)**が大量にアップロードされているのです。
これらの動画には、いくつかの特徴がありました:
- 4K高画質:多くの動画が4K解像度で撮影されており、ナンバープレートの文字が鮮明に読み取れる
- 全国網羅:北は北海道から南は沖縄まで、日本全国の道路を走行する動画が存在する
- 多様な条件:晴天、曇天、夜間、雨天など、様々な環境条件での映像が含まれる
- 大量のサンプル:1時間の動画で数百台の車両が映り込む
これは、まさに私たちが求めていた天然の高品質データセットでした。
新たな課題:人力での限界
しかし、喜びも束の間、新たな課題が浮上しました。
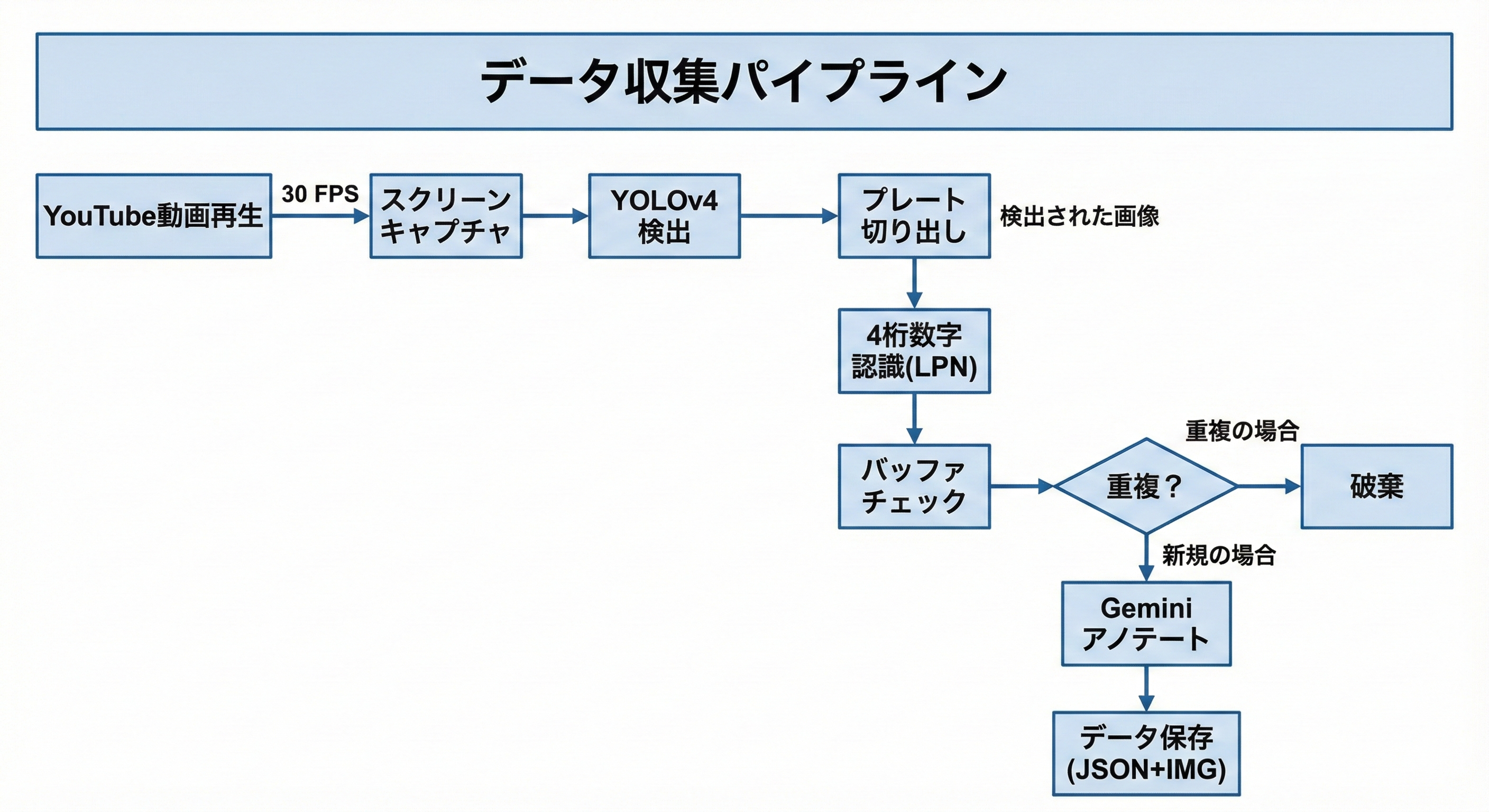
動画を視聴し、ナンバープレートが映った瞬間をキャプチャし、画像として保存し、さらにそれをアノテーション(ラベル付け)する作業を人力で行うとなると、途方もない時間と労力が必要になります。
簡単に試算してみましょう:
【人力でのデータ収集作業量の試算】
・1時間の動画視聴 → 約300枚のキャプチャ
・1枚のキャプチャ作業 → 約10秒
・1枚のアノテーション → 約30秒
・1時間の動画処理 = 300 × (10 + 30) = 12,000秒 ≒ 3.3時間
目標データ数:50,000枚
必要動画時間:約167時間
人力作業時間:約550時間(約69人日)
これでは到底、現実的なスケジュールでプロジェクトを完了することはできません。
AIの力を注入する
発想の転換:AIエージェントの構築
ここで、私たちは一つの問いを立てました。
「この作業をAIに任せることはできないか?」
データ収集の本質を分解して考えると、次のようになります:
- データの発見 = 画面上のどこにナンバープレートがあるかを検出する → 物体検出モデルで実現可能
- データの理解と整理 = ナンバープレートの内容を読み取り、規定のフォーマットで記録する → マルチモーダルLLMで実現可能
これらの要素を組み合わせれば、自動化されたデータ収集パイプラインが構築できるはずです。
私たちは、この仮説を検証するためのプロトタイプ開発に着手しました。
システムアーキテクチャ
全体構成
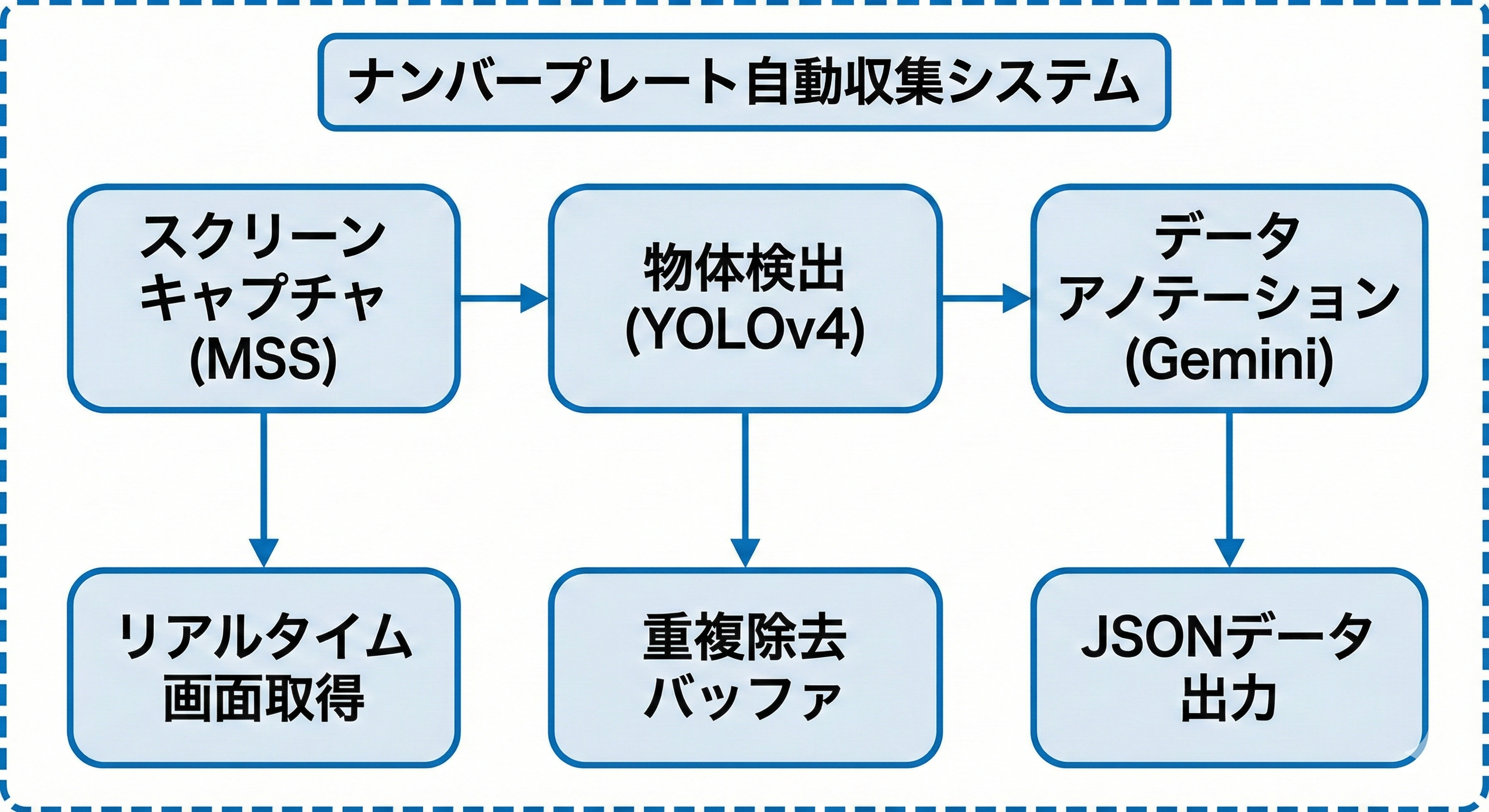
私たちが構築したシステムは、以下の3つのコンポーネントで構成されています:
ハードウェア環境
| 項目 | スペック |
|---|---|
| OS | Windows 10/11 |
| GPU | NVIDIA GeForce RTX 3090 |
| CPU | Intel Core i5-8400 |
| メモリ | 16GB DDR4 |
各コンポーネントの詳細
1. スクリーンキャプチャモジュール(MSS)
画面のリアルタイムキャプチャには、PythonのMSS(Multiple Screen Shots)ライブラリを採用しました。
MSSは、クロスプラットフォーム対応の高速スクリーンキャプチャライブラリです。OpenCVやPillowと組み合わせることで、効率的な画面監視システムを構築できます。
import mss
import cv2
import numpy as np
class ScreenCapture:
def __init__(self, monitor_region=None):
self.sct = mss.mss()
self.monitor = monitor_region or self.sct.monitors[1]
def capture_frame(self):
"""画面をキャプチャしてOpenCV形式で返す"""
screenshot = self.sct.grab(self.monitor)
frame = np.array(screenshot)
return cv2.cvtColor(frame, cv2.COLOR_BGRA2BGR)
def get_fps_optimized_stream(self, target_fps=30):
"""FPS最適化されたフレームストリームを生成"""
import time
frame_interval = 1.0 / target_fps
last_time = time.time()
while True:
current_time = time.time()
if current_time - last_time >= frame_interval:
yield self.capture_frame()
last_time = current_time
選定理由:
- PIL/Pillowと比較して約3倍の高速キャプチャが可能
- 特定領域のみのキャプチャに対応(動画再生エリアのみを効率的に取得)
- メモリ使用量が少なく、長時間稼働に適している
2. 物体検出モジュール(YOLOv4)
ナンバープレートの検出には、**YOLOv4(You Only Look Once v4)**をベースに、日本のナンバープレート検出に特化したファインチューニングを施したモデルを使用しています。
【YOLOv4モデルの性能】
検出精度(mAP@0.5):87.3%
処理速度:45 FPS(RTX 3090使用時)
検出対象:日本の自動車用ナンバープレート
このモデルの精度は「完璧」ではありませんが、データ収集の目的においては十分な性能を発揮します。多少の見逃しがあっても、連続するフレームで補完できるため、実用上の問題にはなりません。
3. 重複除去システム
動画は連続したフレームで構成されているため、同じ車両が複数のフレームにわたって検出されます。これをそのまま保存すると、データセットが重複データで溢れてしまいます。
この問題を解決するために、バッファリングによる重複除去システムを実装しました。
from collections import OrderedDict
from datetime import datetime, timedelta
class DuplicateFilter:
def __init__(self, expiry_minutes=10):
self.buffer = OrderedDict()
self.expiry_time = timedelta(minutes=expiry_minutes)
def extract_4digits(self, plate_text):
"""ナンバープレートから4桁の数字部分を抽出"""
import re
match = re.search(r'\d{4}', plate_text)
return match.group() if match else None
def is_duplicate(self, plate_text):
"""重複チェックを実行"""
self._cleanup_expired()
digits = self.extract_4digits(plate_text)
if digits is None:
return False
if digits in self.buffer:
return True
self.buffer[digits] = datetime.now()
return False
def _cleanup_expired(self):
"""期限切れエントリを削除"""
now = datetime.now()
expired_keys = [
key for key, timestamp in self.buffer.items()
if now - timestamp > self.expiry_time
]
for key in expired_keys:
del self.buffer[key]
アルゴリズムの概要:
- 既存の高精度LPN(License Plate Number)モデルで4桁の数字部分を認識
- 認識した4桁をバッファに登録(タイムスタンプ付き)
- 同じ4桁が既にバッファに存在する場合は、重複として破棄
- 10分経過したエントリは自動的に期限切れとして削除
なぜ4桁の数字なのか?
日本のナンバープレートの4桁数字部分は、同じ地域内では一意性が高く、短時間の動画内で同じ番号が2回出現する確率は極めて低いです。また、この部分は既存モデルで高精度に認識できるため、重複判定の基準として最適でした。
4. 自動アノテーションモジュール(Gemini API)
最後に、収集した画像に対して自動的にラベルを付与する必要があります。ここで活躍するのが、Google Gemini APIを活用したマルチモーダルLLMです。
プロンプトエンジニアリングのポイント:
- 役割の明確化:「日本のナンバープレート読み取りの専門家」として振る舞うよう指示
- 出力形式の厳密な定義:JSONスキーマを明示し、パース可能な形式で出力させる
- 例外処理の指示:読み取れない場合の対処法を事前に定義
- 信頼度の自己評価:AIに自身の回答への確信度を評価させる
処理フローの全体像
実装結果と成果
収集効率の劇的な向上
AIエージェントの導入により、データ収集の効率は飛躍的に向上しました。一週間15000枚画像を収集した。
地域カバレッジの拡大
特に、これまでデータが不足していた地方地域のサンプルを効率的に収集できました。
人間によるレビューの重要性
完全自動化への慎重なアプローチ
システムは理論上、人間の介入なしに動作しますが、私たちは最終段階で必ず人間によるレビューを実施しています。
その理由は以下の通りです:
- 学習データの品質保証:誤ったラベルが混入すると、モデルの性能低下を招く
- エッジケースの発見:AIが苦手とするパターンを人間が特定し、システム改善に活かす
今後の展望
AIと人間の協働
今回のプロジェクトを通じて、私たちはAIと人間の最適な協働のあり方について多くの学びを得ました。
AIは以下のことに優れています:
- 単調な繰り返し作業を疲労なく継続する
- 大量のデータを高速に処理する
- 一定のルールに基づいた判断を一貫して行う
一方、人間は以下のことに優れています:
- 例外的なケースへの柔軟な対応
- 品質の最終判断
- システム全体の設計と改善
これらの強みを活かし、**AIを「疲れ知らずの専門アシスタント」**として位置づけることで、チームの生産性を最大化できると考えています。